一种智能话筒控制方法及系统与流程
本发明属于音频处理技术领域,尤其涉及到一种智能话筒控制方法及系统。
背景技术:
由于每个人的嗓音各不相同,也是人与人之间一个很大的区别。模仿别人的声音,也能带来很大的乐趣。但是由于不同人的嗓音条件不一样,往往很难对别人的声音进行模仿,训练声音模仿时也需要大量的时间,同时需要很多的技巧,往往难以成功。现有的变声设备比较机械,往往只能变声成固定的声音,不够生动灵活。
技术实现要素:
本发明要解决的技术问题在于,针对现有技术方案的上述缺陷,提供一种对用户的嗓音条件进行分析,与变声对象的嗓音条件进行对比,调节智能话筒的功能参数,实现灵活变声的智能话筒控制方法及系统。
本发明解决其技术问题所采用的技术方案是:一种智能话筒控制方法,包括以下步骤:
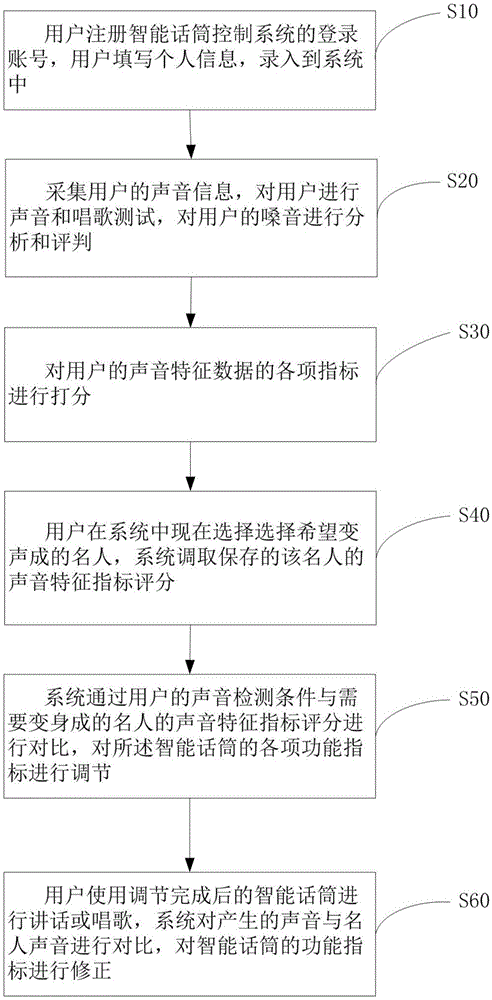
用户注册智能话筒控制系统的登录账号,用户填写个人信息,录入到系统中;
采集用户的声音信息,对用户进行声音和唱歌测试,对用户的嗓音进行分析和评判;
对用户的声音特征数据的各项指标进行打分;
用户在系统中现在选择选择希望变声成的名人,系统调取保存的该名人的声音特征指标评分;
系统通过用户的声音检测条件与需要变身成的名人的声音特征指标评分进行对比,对所述智能话筒的各项功能指标进行调节;
用户使用调节完成后的智能话筒进行讲话或唱歌,系统对产生的声音与名人声音进行对比,对智能话筒的功能指标进行修正。
其中,所述的采集用户的声音信息,对用户进行声音和唱歌测试,对用户的嗓音进行分析和评判,包括:
选择系统中的声音测试模块,对提供的测试段落,用自己的嗓音进行阅读;
选择系统中的声音测试模块,用户通过演唱高音测试歌曲、中音测试歌曲、低音测试歌曲,系统搜集用户的唱歌测试声音进行分析,对用户的音域进行评分;
对用户的音色和音调进行分析和保存。
其中,所述的用户在系统中现在选择选择希望变声成名人,系统调取保存的该名人的声音特征指标评分,包括:
在系统中搜索该名人的名字,查看数据库中是否记录有该名人的音频分析资料;
若有,调取该名人的音频资料,在系统中选定该名人作为变声对象;
若系统中没有该名人的音频资料,联网进行下载;
用户在系统中输入希望变声成的语音资料,系统进行识别。
其中,所述的系统通过用户的声音检测条件与需要变身成的名人的声音特征指标评分进行对比,对所述智能话筒的各项功能指标进行调节,包括:
在系统中设置有各项与声音相关的参数指标;
检测声音资料时,对声音资料的进行分析,对应各项参数指标进行打分;
获取希望变声成的人的声音参数数据后,结合用户本身的声音数据信息,系统通过计算对所述智能话筒的各项功能指标进行调节。
其中,所述的用户使用调节完成后的智能话筒进行讲话或唱歌,系统对产生的声音与名人声音进行对比,对智能话筒的功能指标进行修正,包括:
所述智能话筒的各项功能指标进行调节完成后,采集用户使用调节后的智能话筒进行变声的声音信息;
对变声的声音信息进行数据分析,与之前采集的变声对象的原声进行数据对比,判断数据误差;
数据误差大于设定范围时,对智能话筒的功能指标参数进行调节。
一种智能话筒控制系统,包括处理器,还包括与处理器电性连接的信息采集模块、搜索模块、声音检测模块、数据分析模块、调节模块和存储模块;所述信息采集模块用于采集用户的身份信息,建立用户的登录账号,记录用户的声音参数;所述搜索模块用于通过检索关联词在系统中搜索需要变声成的对象;所述声音检测模块用于检测音频信号的各项指标参数;所述数据分析模块用于将用户的音频信号与变声对象的音频信号进行对比分析,进行参数比较;所述调节模块用于根据所属数据分析模块的分析结果,在处理器控制下对智能话筒的功能性参数进行调节;所述存储模块用于存储可在所述处理器上运行的计算机程序,所述计算机程序被所述处理器执行时实现以上任一项所述的智能话筒控制方法。
其中,还包括信息传送模块,所述信息传送与处理器电信连接,用于用户将音频信息传送到网络端。
本发明的有益效果为:本发明的一种智能话筒控制方法及系统,检测用户的嗓音情况,对嗓音情况进行分析,对用户的声音各项指标进行评分。用户在系统中搜索希望变声的对象,系统分析变声对象的声音参数信息,与用户的声音参数进行对比。根据声音数据分析的结果,对智能话筒的功能参数进行调节,实现灵活准确的变声。
附图说明
图1为本发明智能话筒控制方法的流程实施例示意图;
图2为本发明步骤s20的详细流程实施例示意图;
图3为本发明步骤s40的详细流程实施例示意图;
图4为本发明步骤s50的详细流程实施例示意图;
图5为本发明步骤s60的详细流程实施例示意图;
图6为本发明智能话筒控制系统结构框图实施例示意图。
附图中:1.信息采集模块、2.搜索模块、3.声音检测模块、4.处理器、5.数据分析模块、6.调节模块、7.存储模块、8.信息传送模块。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明的一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
各个实施例之间的技术方案可以相互结合,但是必须是以本领域普通技术人员能够实现为基础,当技术方案的结合出现相互矛盾或无法实现时应当认为这种技术方案的结合不存在,也不在本发明要求的保护范围之内。
参照图1,在本实施例中,一种智能话筒控制方法,包括以下步骤:
s10:用户注册智能话筒控制系统的登录账号,用户填写个人信息,录入到系统中;
s20:采集用户的声音信息,对用户进行声音和唱歌测试,对用户的嗓音进行分析和评判;
s30:对用户的声音特征数据的各项指标进行打分;
s40:用户在系统中现在选择选择希望变声成的名人,系统调取保存的该名人的声音特征指标评分;
s50:系统通过用户的声音检测条件与需要变身成的名人的声音特征指标评分进行对比,对所述智能话筒的各项功能指标进行调节;
s60:用户使用调节完成后的智能话筒进行讲话或唱歌,系统对产生的声音与名人声音进行对比,对智能话筒的功能指标进行修正。
具体地,用户使用本发明的智能话筒前,系统通过手机或电脑端对智能话筒控制系统进行账号注册,填写用户的个人信息,包括用户的联系方式,用户的性别和年龄。用户完成注册登录到系统中之后,对于首次登陆的用户,对用户进行声音检测,获取用户的声音数据信息。用户进入系统中的声音检测界面,开始声音的检测和搜集。系统按照设定的声音检测程序,播放一段标准的预留语音片段,用户进行语音片段的复读,系统对用户的声音进行采集。对用户的声音特征参数进行分析,对用户的各项声音特征指标进行评分,记录到系统中。用户在系统中搜索希望变声的对象,系统中记录有各种名人的声音指标数据库,包括歌曲、影视明星和卡通人物。用户可以通过人物名字在系统的搜索界面进行搜索,搜索到需要搜索的变声对象后,系统调取该变声对象的声音特征参数。系统将变声对象的声音特征参数与用户的声音特征参数进行对比,计算出用户要达到变声对象的声音效果,需要对智能话筒进行的调节功能参数数据。系统对智能话筒的功能参数数据进行调节,满足用户的变声要求。调节完成后,用户使用智能话筒进行变声后的检测,系统采集用户变声后的声音,对声音数据进行分析,与变声对象的声音数据进行对比,分析本次变声的效果。
参照图2,进一步地,在本实施例中,所述的步骤s20采集用户的声音信息,对用户进行声音和唱歌测试,对用户的嗓音进行分析和评判,包括:
s21:选择系统中的声音测试模块,对提供的测试段落,用自己的嗓音进行阅读;
s22:选择系统中的声音测试模块,用户通过演唱高音测试歌曲、中音测试歌曲、低音测试歌曲,系统搜集用户的唱歌测试声音进行分析,对用户的音域进行评分;
s23:对用户的音色和音调进行分析和保存。
用户选择系统中的声音测试界面后,按照系统的指示进行声音测试。系统中会设置有不同的测试选项,包括说话声音测试和唱歌声音测试。用户通过对系统提供的测试语音和歌曲片段进行复读,实现声音的采集,系统对用户的声音进行分析,计算出用户的各项声音参数,保存到系统中。
参照图3,进一步地,在本实施例中,所述的步骤s40用户在系统中现在选择选择希望变声成名人,系统调取保存的该名人的声音特征指标评分,包括:
s41:在系统中搜索该名人的名字,查看数据库中是否记录有该名人的音频分析资料;
s42:若有,调取该名人的音频资料,在系统中选定该名人作为变声对象;
s43:若系统中没有该名人的音频资料,联网进行下载;
s44:用户在系统中输入希望变声成的语音资料,系统进行识别。
用户选择希望变声的对象时,通过人名进行搜索,通常搜索的对象为有一定名气的人物。若系统中未搜索到该人名,通过联网进行网络端的搜索。也可以通过传送需要变声对象的声音资料到系统中,供系统分析和读取声音参数,进行变声。
参照图4,进一步地,在本实施例中,所述的步骤s50系统通过用户的声音检测条件与需要变身成的名人的声音特征指标评分进行对比,对所述智能话筒的各项功能指标进行调节,包括:
s51:在系统中设置有各项与声音相关的参数指标;
s52:检测声音资料时,对声音资料的进行分析,对应各项参数指标进行打分;
s53:获取希望变声成的人的声音参数数据后,结合用户本身的声音数据信息,系统通过计算对所述智能话筒的各项功能指标进行调节。
系统检测声音时,设定了各项声音指标,用户对每个人的声音进行标准性的分析。根据每个人讲话时的音色、音调、频率等的不同,进行声音检测。对不同的声音指标进行打分,用数据将用户的声音特征进行具体的评判。
参照图5,进一步地,在本实施例中,所述的步骤s60用户使用调节完成后的智能话筒进行讲话或唱歌,系统对产生的声音与名人声音进行对比,对智能话筒的功能指标进行修正,包括:
s61:所述智能话筒的各项功能指标进行调节完成后,采集用户使用调节后的智能话筒进行变声的声音信息;
s62:对变声的声音信息进行数据分析,与之前采集的变声对象的原声进行数据对比,判断数据误差;
s63:数据误差大于设定范围时,对智能话筒的功能指标参数进行调节。
智能话筒进行功能参数调节后,为检验变声效果。对变声后的用户声音进行采集和检验,与变声对象的声音数据进行对比,判断各项数据指标是否在设定的误差范围内,对于设定误差范围内的指标,对与之相对应的话筒的功能性指标进行调节。
参照图6,在本实施例中,一种智能话筒控制系统,包括处理器4,还包括与处理器4电性连接的信息采集模块1、搜索模块2、声音检测模块3、数据分析模块5、调节模块6和存储模块7;所述信息采集模块1用于采集用户的身份信息,建立用户的登录账号,记录用户的声音参数;所述搜索模块2用于通过检索关联词在系统中搜索需要变声成的对象;所述声音检测模块3用于检测音频信号的各项指标参数;所述数据分析模块5用于将用户的音频信号与变声对象的音频信号进行对比分析,进行参数比较;所述调节模块6用于根据所属数据分析模块5的分析结果,在处理器4控制下对智能话筒的功能性参数进行调节;所述存储模块7用于存储可在所述处理器4上运行的计算机程序,所述计算机程序被所述处理器4执行时实现以上任一项所述的智能话筒控制方法。
其中,还包括信息传送模块8,所述信息传送与处理器4电信连接,用于用户将音频信息传送到网络端。
本发明的一种智能话筒控制方法及系统,检测用户的嗓音情况,对嗓音情况进行分析,对用户的声音各项指标进行评分。用户在系统中搜索希望变声的对象,系统分析变声对象的声音参数信息,与用户的声音参数进行对比。根据声音数据分析的结果,对智能话筒的功能参数进行调节,实现灵活准确的变声。
以上内容仅为本发明的较佳实施例,对于本领域的普通技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改变之处,本说明书内容不应理解为对本发明的限制。
- 还没有人留言评论。精彩留言会获得点赞!