包括用于影响处理算法的语音可懂度估计器的听力装置的制作方法
本申请涉及听力装置如助听器领域,尤其涉及表示声音的电信号根据用户的需要进行处理。
背景技术:
ep3057335a1公开了双耳听力系统,其中左和右听力装置的音频信号的处理根据处理后信号的(双耳)语音可懂度测量进行控制。us20050141737a1公开了包括语音优化模块的助听器,其适于为相应频带信号选择表示增益水平的增益向量,用于基于频带信号和增益向量计算语音可懂度指数,及用于通过迭代地改变增益向量而优化增益向量,计算相应的语音可懂度指数并选择使语音可懂度指数最大化的向量。
技术实现要素:
助听器的主要任务是在给定情形下增加听力受损用户对其周围声场中的语音内容的可懂度。通过将多个处理算法应用于一个或多个电输入信号(如通过一个或多个传声器传递)而追求该目标。前述处理算法的例子为用于压缩放大、降噪(包括空间滤波(波束形成))、反馈减少、去混响等的算法。
一方面,本发明涉及,在电输入信号已遭受前述处理时(例如在将一个或多个特定处理算法应用于电输入信号之后),对来自一个或多个传感器(例如声音输入变换器,例如传声器,及非必须地、另外地,其它类型的传感器)的电输入信号的处理针对语音内容的用户可懂度进行优化。针对语音可懂度进行优化考虑a)用户的听觉能力(如受损)与b)电输入信号在被呈现给用户之前遭受的具体处理算法如降噪(包括波束形成)的相互作用及c)可接受的用户语音可懂度(si,如si测量,如反映被理解的话语的百分比估计量)目标。
“来自一个或多个传感器的电输入信号”一般可源自同样类型的传感器(如声音传感器)或源自不同类型的传感器如声音传感器、图像传感器等的组合。通常,“一个或多个传感器”包括至少一个声音传感器,例如声音输入变换器如传声器。
本发明的实施适合正常听力的人,例如用于在困难听音情形下增强听力。
听力装置如助听器
一方面,本申请提供一种听力装置如助听器,其适于由用户佩戴并适于从用户环境接收声音并提高所述声音中的语音的用户可懂度,所述声音中的语音的用户可懂度通过所述声音在当前时间点t的语音可懂度测量i确定。所述听力装置包括a)用于提供多个电输入信号y的输入单元,每一电输入信号表示用户环境中的所述声音;及b)用于根据一个或多个处理算法的可配置参数设置θ处理所述多个电输入信号的信号处理器,当处理算法应用于所述多个电输入信号y时,信号处理器根据其提供处理后信号yp(θ),所述信号处理器配置成提供合成信号yres。所述听力装置还可包括c)控制器,配置成根据下述因素控制所述信号处理器提供当前时间点t的合成信号yres:
-确定用户的听力情况的参数集φ;
-所述电输入信号y,或者从所述电输入信号提取的特性;
-针对至少一所述电输入信号y,所述语音可懂度测量i的当前值i(y);
-所述语音可懂度测量的期望值ides;
-所述一个或多个处理算法的第一参数设置θ1;
-基于所述第一参数设置θ1的第一处理后信号yp(θ1)的所述语音可懂度测量i的当前值i(yp(θ1));及
-所述一个或多个处理算法的第二参数设置θ’,当应用于所述多个电输入信号y时,其提供展现所述语音可懂度测量的所述期望值ides的第二处理后信号yp(θ’)。
从而可提高语音可懂度。
在给定时间点t,如果至少一(未处理的)电输入信号y的语音可懂度测量i的当前值i(y)大于语音可懂度测量的期望值ides,可采取一个或多个行动(例如通过控制器控制)。行动例如可以是跳过(绕开)所涉及的处理算法并将合成信号yres(t)提供为展现i(y(t))>ides的至少一电输入信号y(t)。
在本说明书中,术语“从所述电输入信号提取的特性”包括从电输入信号提取的一个或多个参数,例如噪声协方差矩阵cv和/或有噪声信号y的协方差矩阵cy、与调制有关的参数如调制指数等。噪声协方差矩阵cv可在听力装置使用之前预先确定,或者在使用期间确定(如自适应更新)。语音可懂度测量可基于预定的函数关系,例如输入信号的信噪比的函数。
控制器可被配置成,如果多个电输入信号y和第一处理后信号yp(θ1)的语音可懂度测量i的当前值i(y)和i(yp(θ1))均小于所述期望值ides,控制所述处理器使得当前时间点t的合成信号yres等于可选信号ysel。
在实施例中,控制器被配置成,如果第一处理后信号yp(θ1)的语音可懂度测量i的当前值i(yp(θ1))小于或等于语音可懂度测量的期望值ides,控制所述处理器使得当前时间点t的合成信号yres等于基于所述第一参数设置θ1的所述第一处理后信号yp(θ1)。换言之,可选信号ysel等于第一处理后信号yp(θ1)(例如提供估计的目标信号的最大(但非最佳)snr)。在实施例中,可选信号ysel等于电输入信号y之一,例如衰减后版本,例如包括该输入信号目前低于正常标准的标示。在实施例中,可选信号根据语音可懂度测量i的第一阈值ith进行选择,其中ith小于ides。在实施例中,当ith<i(yp(θ1)<ides时,ysel=yp(θ1)。在实施例中,可选信号ysel等于或包含指明当前输入信号太有噪声的信息信号yinf以提供可接受的目标信号语音可懂度。在实施例中,当i(yp(θ1)<ith时,ysel=yinf。
控制器可被配置成,如果第一处理后信号yp(θ1)的语音可懂度测量i的当前值i(yp(θ1))大于语音可懂度测量的期望值ides,控制所述处理器使得当前时间点t的合成信号yres等于展现语音可懂度测量的期望值ides的第二优化的处理后信号yp(θ’)。
在实施例中,控制器被配置成,如果a)i(y)小于期望值ides及b)i(yp(θ1))大于语音可懂度测量i的期望值ides,使得合成信号yres等于第二处理后信号yp(θ’)。在实施例中,控制器被配置成在第二处理后信号yp(θ’)展现语音可懂度测量的期望值ides的约束条件下确定第二参数设置θ’。
在实施例中,第一参数设置θ1是默认设置。第一参数设置θ1可以是使第一处理后信号yp(θ1)的信噪比(snr)或语音可懂度测量i最大化的设置。在实施例中,第二(优化的)参数设置θ’由一个或多个处理算法用于处理多个电输入信号并提供第二(优化的)处理后信号yp(θ’)(为用户产生期望的语音可懂度水平,如语音可懂度测量的期望值ides反映的)。snr可优选在时频框架中确定,例如每tf单元,例如参见图3b。在实施例中,语音可懂度测量i是信噪比的单调函数。在实施例中,语音可懂度测量i在其中频带随频率增加而具有增加的宽度的方案中确定,例如根据对数方案,例如三分之一倍频带的形式,或者使用欧勃(erb)标度(人听觉系统的逼近带宽)。
一个或多个处理算法可包括单通道降噪算法。单通道降噪算法可配置成接收单一电信号(例如来自(可能全向)传声器的信号,或者空间滤波的信号(例如来自波束形成器滤波单元))。
输入单元可被配置成提供多个电输入信号yi,i=1,…,m,每一电输入信号表示用户环境中的声音,其中一个或多个处理算法包括波束形成器算法,用于接收所述多个电输入信号或者多个电输入信号的处理后版本并提供空间滤波的波束成形信号,波束形成器算法通过波束形成器设置进行控制,及其中一个或多个处理算法的第一参数设置θ1包括第一波束形成器设置,及其中一个或多个处理算法的第二参数设置θ’包括第二波束形成器设置。
第一波束形成器设置例如基于多个电输入信号及例如来自一个或多个传感器(例如包括话音活动检测器)的一个或多个控制信号进行确定,而不特别考虑当前波束成形信号的语音可懂度测量的值。第一参数设置θ1可构成或包括使(第一)波束成形信号的(目标)信噪比(snr)最大化的波束形成器设置。
在实施例中,听力装置包括存储器,其中存储语音可懂度测量的期望值ides。在实施例中,所述语音可懂度测量的期望值ides为平均值(例如跨大量的人(如>10)求平均),例如以经验为主确定,或者为估计值。期望的语音可懂度值ides可针对听力装置用户特别确定或选择。语音可懂度测量的期望值ides可以是用户特有值,例如预先确定,例如在听力装置使用之前测量或估计。在实施例中,听力装置包括存储器,其中存储用户期望的语音可懂度值(例如可懂话语的百分比,如95%)ides。
在实施例中,控制器被配置成目标在于确定第二优化的参数设置θ’以为用户提供所述期望的语音可懂度值ides。术语“目标在于”表明前述期望的语音可懂度值ides可能不总是可实现(例如由于差的听音条件(如低snr)、听力装置中不足够可用的增益、反馈啸声等中的一个或多个引起)。
输入单元可被配置成按时频表示提供多个电输入信号yr(k’,m),r=1,…,m,其中m为电输入信号的数量,k’为频率指数,m为时间指数。在实施例中,输入单元包括多个输入变换器如传声器,每一输入变换器提供所述电输入信号yr(n)之一,其中n表示时间。在实施例中,输入单元包括多个时域到时频域转换单元,如分析滤波器组,如短时傅里叶变换(stft)单元,用于将时域电输入信号yr(n)转换为时频域(子频带)电输入信号yr(k’,m)。在实施例中,电输入信号的数量为1。在实施例中,电输入信号的数量大于或等于2,例如大于或等于3或4。
听力装置如控制器可被配置成从多个传感器接收另外的电输入信号并根据其影响处理器的控制。在实施例中,多个传感器包括下述之一或多个:外部声音传感器、图像传感器如照相机(例如朝向当前目标讲话者的面部(嘴巴),例如用于提供关于目标信号的备选(不随snr而变的)信息,例如用于话音活动检测)、脑电波传感器(例如用于确定用户当前感兴趣的声源)、运动传感器(例如用于提供头部定向以指明目标信号的到达方向(doa)的头部跟踪器)、eog传感器(例如用于确定目标信号的doa,或者指明最可能的多个doa)。在实施例中,控制器被配置成对来自传感器如图像传感器的输入给予更高的权重,当前表观snr或语音可懂度的估计量越小。在困难声学情形下,读唇(例如基于图像传感器)例如可被逐渐依赖。
控制器被配置成使得合成信号yres的语音可懂度测量i(yres)小于或等于期望值ides,除非多个电输入信号中的一个或多个的语音可懂度测量i(y)的值大于期望值ides。在后一情形下,控制器被配置成保持这样的语音可懂度测量i(y),而不试图通过应用一个或多个处理算法进一步提高它。在该情形下,控制器被配置成绕开一个或多个处理算法,并将展现i(y)>ides的输入信号y之一提供为合成信号yres。在该情形下,合成信号因而未被所涉及的一个或多个处理算法处理(但可能被一个或多个其它处理算法处理)。
在实施例中,语音可懂度测量i为目标信号-噪声比的测量,其中目标信号表示包含用户当前打算听的语音的信号,噪声表示用户环境中的所述声音中的所有其它声音分量。
听力装置可适应用户的听力情况,例如补偿用户的听力受损。用户的听力情况可通过参数集φ确定。参数集φ例如可确定用户的(随频率而变的)听觉阈(或它们与正常听力的偏差,例如反映在听力图中)。在实施例中,“一个或多个处理算法”之一被配置成补偿用户的听力损失。在实施例中,压缩放大算法(用于使输入信号适应用户需要)形成“一个或多个处理算法”的一部分。
控制器可被配置成确定语音可懂度测量i的估计量,其在以第二频率分辨率k确定第二优化的参数设置θ’(k’,m)时使用,第二频率分辨率k低于用于确定第一参数设置θ1(k’,m)(第一处理后信号yp(θ1)基于该第一参数设置)的第一频率分辨率k’。在实施例中,处理的第一部分(例如使用第一处理设置θ1(k’,m)处理电输入信号)以第一频率指数k’表示的第一频率分辨率应用在各个频带中,及处理的第二部分(例如处理后信号的语音可懂度测量i(k,m,θ,φ)的确定,用于将第一参数设置θ1(k’,m)修改为优化的参数设置θ’(k’,m))以第二频率指数k表示的第二(不同的,如更低的)频率分辨率应用在各个频带中(例如参见图3b)。
在实施例中,听力装置构成或包括助听器。
在实施例中,听力装置如信号处理器适于提供随频率而变的增益和/或随电平而变的压缩和/或一个或多个频率范围到一个或多个其它频率范围的移频(具有或没有频率压缩)以补偿用户的听力受损。
在实施例中,听力装置包括输出单元,用于基于处理后的电输入信号提供由用户感知为声学信号的刺激。在实施例中,输出单元包括耳蜗植入物的多个电极或者骨导助听器的振动器。在实施例中,输出单元包括输出变换器。在实施例中,输出变换器包括用于将刺激作为声信号提供给用户的接收器(扬声器)。在实施例中,输出变换器包括用于将刺激作为颅骨的机械振动提供给用户的振动器(例如在附着到骨头的或骨锚式助听器中)。
听力装置包括用于提供表示声音的电输入信号的输入单元。在实施例中,输入单元包括用于将输入声音转换为电输入信号的输入变换器如传声器。在实施例中,输入单元包括用于接收包括声音的无线信号并提供表示所述声音的电输入信号的无线接收器。
在实施例中,听力装置包括定向传声器系统,其适于对来自环境的声音进行空间滤波从而增强佩戴听力装置的用户的局部环境中的多个声源之中的目标声源。在实施例中,定向系统适于检测(如自适应检测)传声器信号的特定部分源自哪一方向。这可以例如现有技术中描述的多种不同方式实现。在助听器中,传声器阵列波束形成器通常用于空间上衰减背景噪声源。许多波束形成器变型可在文献中找到。最小方差无失真响应(mvdr)波束形成器广泛用在传声器阵列信号处理中。理想地,mvdr波束形成器保持来自目标方向(也称为视向)的信号不变,而最大程度地衰减来自其它方向的声音信号。广义旁瓣抵消器(gsc)结构是mvdr波束形成器的等同表示,其相较原始形式的直接实施提供计算和数字表示优点。
在实施例中,听力装置包括用于从另一装置如从娱乐设备(例如电视机)、通信装置、无线传声器或另一听力装置接收直接电输入信号的天线和收发器电路(如无线接收器)。在实施例中,直接电输入信号表示或包括音频信号和/或控制信号和/或信息信号。在实施例中,听力装置包括用于对所接收的直接电输入进行解调的解调电路,以提供表示音频信号和/或控制信号的直接电输入信号,例如用于设置听力装置的运行参数(如音量)和/或处理参数。总的来说,听力装置的天线及收发器电路建立的无线链路可以是任何类型。在实施例中,无线链路在两个装置之间建立,例如在娱乐设备(如tv)与听力装置之间,或者在两个听力装置之间,例如经第三中间装置(如处理装置,例如遥控装置、智能电话等)。在实施例中,无线链路在功率约束条件下使用,例如由于听力装置是或包括便携式(通常电池驱动的)装置。在实施例中,无线链路为基于近场通信的链路,例如基于发射器部分和接收器部分的天线线圈之间的感应耦合的感应链路。在另一实施例中,无线链路基于远场电磁辐射。优选地,听力装置和其它装置之间的通信基于高于100khz的频率下的某类调制。优选地,用于在听力装置和另一装置之间建立通信链路的频率低于70ghz,例如位于从50mhz到70ghz的范围中,例如高于300mhz,例如在高于300mhz的ism范围中,例如在900mhz范围中或在2.4ghz范围中或在5.8ghz范围中或在60ghz范围中(ism=工业、科学和医学,这样的标准化范围例如由国际电信联盟itu定义)。在实施例中,无线链路基于标准化或专用技术。在实施例中,无线链路基于蓝牙技术(如蓝牙低功率技术)。
在实施例中,助听器为便携装置,如包括本机能源如电池例如可再充电电池的装置例如助听器。
在实施例中,听力装置包括输入单元(如输入变换器,例如传声器或传声器系统和/或直接电输入(如无线接收器))和输出单元如输出变换器之间的正向或信号通路。在实施例中,信号处理器位于该正向通路中。在实施例中,信号处理器适于根据用户的特定需要提供随频率而变的增益。在实施例中,听力装置包括具有用于分析输入信号(如确定电平、调制、信号类型、声反馈估计量等)的功能件的分析通路。在实施例中,分析通路和/或信号通路的部分或所有信号处理在频域进行。在实施例中,分析通路和/或信号通路的部分或所有信号处理在时域进行。
在实施例中,表示声信号的模拟电信号在模数(ad)转换过程中转换为数字音频信号,其中模拟信号以预定采样频率或采样速率fs进行采样,fs例如在从8khz到48khz的范围中(适应应用的特定需要)以在离散的时间点tn(或n)提供数字样本xn(或x[n]),每一音频样本通过预定的nb比特表示声信号在tn时的值,nb例如在从1到48比特的范围中如24比特。每一音频样本因此使用nb比特量化(导致音频样本的2nb个不同的可能的值)。数字样本x具有1/fs的时间长度,如50μs,对于fs=20khz。在实施例中,多个音频样本按时间帧安排。在实施例中,一时间帧包括64个或128个音频数据样本。根据实际应用可使用其它帧长度。
在实施例中,听力装置包括模数(ad)转换器以按预定的采样速率如20khz对模拟输入(例如来自输入变换器如传声器)进行数字化。在实施例中,听力装置包括数模(da)转换器以将数字信号转换为模拟输出信号,例如用于经输出变换器呈现给用户。
在实施例中,听力装置如传声器单元和/或收发器单元包括用于提供输入信号的时频表示的tf转换单元。在实施例中,时频表示包括所涉及信号在特定时间和频率范围的相应复值或实值的阵列或映射。在实施例中,tf转换单元包括用于对(时变)输入信号进行滤波并提供多个(时变)输出信号的滤波器组,每一输出信号包括截然不同的输入信号频率范围。在实施例中,tf转换单元包括用于将时变输入信号转换为(时-)频域中的(时变)信号的傅里叶变换单元。在实施例中,听力装置考虑的、从最小频率fmin到最大频率fmax的频率范围包括从20hz到20khz的典型人听频范围的一部分,例如从20hz到12khz的范围的一部分。通常,采样率fs大于或等于最大频率fmax的两倍,即fs≥2fmax。在实施例中,听力装置的正向通路和/或分析通路的信号拆分为ni个(例如均匀宽度的)频带,其中ni例如大于5,如大于10,如大于50,如大于100,如大于500,至少其部分个别进行处理。在实施例中,助听器适于在np个不同频道处理正向和/或分析通路的信号(np≤ni)。频道可以宽度一致或不一致(如宽度随频率增加)、重叠或不重叠。
在实施例中,听力装置包括多个检测器,其配置成提供与听力装置的当前网络环境(如当前声环境)有关、和/或与佩戴听力装置的用户的当前状态有关、和/或与听力装置的当前状态或运行模式有关的状态信号。作为备选或另外,一个或多个检测器可形成与听力装置(如无线)通信的外部装置的一部分。外部装置例如可包括另一听力装置、遥控器、音频传输装置、电话(如智能电话)、外部传感器等。
在实施例中,多个检测器中的一个或多个对全带信号起作用(时域)。在实施例中,多个检测器中的一个或多个对频带拆分的信号起作用((时-)频域),例如在有限的多个频带中。
在实施例中,多个检测器包括用于估计正向通路的信号的当前电平的电平检测器。在实施例中,预定判据包括正向通路的信号的当前电平是否高于或低于给定(l-)阈值。在实施例中,电平检测器作用于全频带信号(时域)。在实施例中,电平检测器作用于频带拆分信号((时-)频域)。
在特定实施例中,听力装置包括话音检测器(vd),用于估计输入信号(在特定时间点)是否(或者以何种概率)包括话音信号。在本说明书中,话音信号包括来自人类的语音信号。其还可包括由人类语音系统产生的其它形式的发声(如唱歌)。在实施例中,话音检测器单元适于将用户当前的声环境分类为“话音”或“无话音”环境。这具有下述优点:包括用户环境中的人发声(如语音)的电传声器信号的时间段可被识别,因而与仅(或主要)包括其它声源(如人工产生的噪声)的时间段分离。在实施例中,话音检测器适于将用户自己的话音也检测为“话音”。作为备选,话音检测器适于从“话音”的检测排除用户自己的话音。
在实施例中,听力装置包括自我话音检测器,用于估计特定输入声音(如话音,如语音)是否(或以何种概率)源自系统用户的话音。在实施例中,听力装置的传声器系统适于能够在用户自己的话音及另一人的话音之间进行区分及可能与无话音声音区分。
在实施例中,听力装置包括用于估计当前语言的语言检测器或者配置成从另一装置例如从遥控装置、从智能电话或类似装置接收当前语言的信息。估计的语音可懂度可取决于使用的语言是听者的出生地语言还是第二语言。因此,所需的降噪量可取决于语言。
在实施例中,多个检测器包括运动检测器,例如加速度传感器。在实施例中,运动检测器配置成检测用户面部肌肉和/或骨头的例如因语音或咀嚼(如颌部运动)引起的运动并提供标示该运动的检测器信号。
在实施例中,听力装置包括分类单元,配置成基于来自(至少部分)检测器的输入信号及可能其它输入对当前情形进行分类。在本说明书中,“当前情形”由下面的一个或多个定义:
a)物理环境(如包括当前电磁环境,例如出现计划或未计划由听力装置接收的电磁信号(包括音频和/或控制信号),或者当前环境不同于声学的其它性质);
b)当前声学情形(输入电平、反馈等);
c)用户的当前模式或状态(运动、温度、认知负荷等);
d)听力装置和/或与听力装置通信的另一装置的当前模式或状态(所选程序、自上次用户交互之后消逝的时间等)。
在实施例中,听力装置包括声学(和/或机械)反馈抑制系统。在实施例中,听力装置还包括用于所涉及应用的其它适宜功能,如压缩、降噪等。
在实施例中,听力装置是或包括助听器。在实施例中,助听器是或包括听力仪器,例如适于位于用户耳朵处或者完全或部分位于耳道中或者适于完全或部分植入在用户头部中的听力仪器。在实施例中,听力装置是或包括头戴式耳机、耳麦或主动耳朵保护装置。
应用
一方面,提供如上所述的、“具体实施方式”部分中详细描述的和权利要求中限定的助听器的应用。在实施例中,提供在包括一个或多个助听器(如听力仪器)或头戴式耳机的系统中的应用,例如在免提电话系统、远程会议系统、广播系统、卡拉ok系统、教室放大系统等中的用途。
方法
一方面,本申请进一步提供听力装置的运行方法,所述听力装置适于由用户佩戴并提高声音中的语音的用户可懂度。所述方法包括:
-从用户环境接收包括语音的声音;
-提供用于估计用户在当前时间点t理解所述声音中的语音的能力的语音可懂度测量i;
-提供多个电输入信号,每一电输入信号表示用户环境中的所述声音;
-根据一个或多个处理算法的可配置参数设置θ处理所述多个电输入信号,并提供合成信号yres。
所述方法还可包括
-通过根据下述因素提供当前时间点t的合成信号yres而控制所述处理:
--确定用户的听力情况的参数集φ;
--所述多个电输入信号y,或者从所述电输入信号提取的特性;
--针对至少一所述电输入信号y,所述语音可懂度测量i的当前值i(y);
--所述语音可懂度测量的期望值ides;
--所述一个或多个处理算法的第一参数设置θ1;
--基于所述第一参数设置θ1的第一处理后信号yp(θ1)的所述语音可懂度测量i的当前值i(yp(θ1));及
--所述一个或多个处理算法的第二参数设置θ’,当应用于所述多个电输入信号y时,其提供展现所述语音可懂度测量的所述期望值ides的第二处理后信号yp(θ’)。
当由对应的过程适当代替时,上面描述的、“具体实施方式”中详细描述的或权利要求中限定的装置的部分或所有结构特征可与本发明方法的实施结合,反之亦然。方法的实施具有与对应装置一样的优点。
所述方法随时间重复,例如根据预定方案,例如定期,例如每时刻m,例如正向通路的信号的每时间帧。在实施例中,所述方法每第n个时间帧重复,,例如每n=10个时间帧或者每n=100个时间帧。在实施例中,n根据电输入信号和/或一个或多个传感器信号(例如指明用户的当前声学环境、和/或听力装置的运行模式,例如电池状态指示)自适应确定。
在实施例中,第一参数设置θ1为使第一处理后信号yp(θ1)的信噪比(snr)和/或所述语音可懂度测量i最大化的设置。
所述方法可包括:按时频表示y(k’,m)提供所述多个电输入信号y,其中k’和m分别为频率和时间指数。
所述方法可包括:提供语音可懂度测量i(t)包括在每一时频瓦(k,m)估计表观snr,snr(k,m,φ)。语音可懂度测量i(t)可以是snr的函数f(·),例如基于时频瓦级。所述函数f(·)可通过将snr估计量snr(k,m)映射到预测的可懂度i(k,m)的神经网络建模。在实施例中,i=f(snr(k,m,φ,θ)),例如:
其中m0表示当前时间点,及m’表示考虑的包含语音的时间帧的数量(例如对应于最近的音节或词语或整个句子),及其中
在实施例中,所述方法包括:提供当前时间点t的合成信号yres包括:
-如果所述电输入信号y之一的所述语音可懂度测量i的当前值i(y)大于或等于所述期望值ides,设定yres等于所述电输入信号y之一;及
-如果所述电输入信号y的所述语音可懂度测量i的当前值i(y)小于所述期望值ides,及第一处理后信号的当前值i(yp(θ1))大于所述语音可懂度测量i的期望值ides,
--在第二处理后信号yp(θ’)展现所述语音可懂度测量的期望值ides的约束条件下确定所述第二参数设置θ’;
--设定yres等于所述第二处理后信号yp(θ’)。
一个或多个处理算法可包括单通道降噪算法和/或多输入波束形成器滤波算法。电输入信号y的数量可大于1,例如2个以上。在实施例中,所述波束形成器滤波算法包括mvdr算法。
所述方法可包括第二参数设置θ’在使所述电输入信号y的变化最小化的约束条件下确定。在电输入信号(例如未处理的输入信号)的snr对应于超出期望的语音可懂度值ides的语音可懂度测量i的情形下,一个或多个处理算法应不被应用于电输入信号。“使输入信号的变化最小化”例如可意为对信号执行尽可能小的处理。“使所述多个电输入信号的变化最小化”例如可使用距离测量如欧几里得(euclidian)距离进行评估,例如应用于波形,例如在时域或时频表示。
所述方法可包括,表观snr遵循最大似然程序进行估计。
所述方法可包括,第二参数设置θ’以比用于确定语音可懂度的估计量i的第二频率分辨率k精细的第一频率分辨率k’进行估计。
计算机可读介质
本发明进一步提供保存包括程序代码的计算机程序的有形计算机可读介质,当计算机程序在数据处理系统上运行时,使得数据处理系统执行上面描述的、“具体实施方式”中详细描述的及权利要求中限定的方法的至少部分(如大部分或所有)步骤。
作为例子但非限制,前述有形计算机可读介质可包括ram、rom、eeprom、cd-rom或其他光盘存储器、磁盘存储器或其他磁性存储装置,或者可用于执行或保存指令或数据结构形式的所需程序代码并可由计算机访问的任何其他介质。如在此使用的,盘包括压缩磁盘(cd)、激光盘、光盘、数字多用途盘(dvd)、软盘及蓝光盘,其中这些盘通常磁性地复制数据,同时这些盘可用激光光学地复制数据。上述盘的组合也应包括在计算机可读介质的范围内。除保存在有形介质上之外,计算机程序也可经传输介质如有线或无线链路或网络如因特网进行传输并载入数据处理系统从而在不同于有形介质的位置处运行。
计算机程序
此外,本申请提供包括指令的计算机程序(产品),当该程序由计算机运行时,导致计算机执行上面描述的、“具体实施方式”中详细描述的及权利要求中限定的方法(的步骤)。
数据处理系统
一方面,本发明进一步提供数据处理系统,包括处理器和程序代码,程序代码使得处理器执行上面描述的、“具体实施方式”中详细描述的及权利要求中限定的方法的至少部分(如大部分或所有)步骤。
听力系统
另一方面,听力系统包括上面描述的、“具体实施方式”中详细描述的及权利要求中限定的助听器,此外还提供辅助装置。
在实施例中,听力系统适于在助听器与辅助装置之间建立通信链路以使得信息(如控制和状态信号,可能音频信号)可进行交换或者从一装置转发给另一装置。
在实施例中,听力系统包括辅助装置,例如遥控器、智能电话、或者其它便携或可穿戴电子设备如智能手表等。
在实施例中,辅助装置是或包括遥控器,用于控制助听器的功能和运行。在实施例中,遥控器的功能实施在智能电话中,该智能电话可能运行使能经智能电话控制音频处理装置的功能的app(助听器包括适当的到智能电话的无线接口,例如基于蓝牙或一些其它标准化或专有方案)。
在实施例中,辅助装置是或包括音频网关设备,其适于(例如从娱乐装置如tv或音乐播放器、从电话设备如移动电话或者从计算机如pc)接收多个音频信号并适于选择和/或组合所接收的音频信号中的适当信号(或信号组合)以传给助听器。
在实施例中,辅助装置是或包括另一助听器。在实施例中,听力系统包括适于实施双耳听力系统如双耳助听器系统的两个助听器。
在实施例中,双耳降噪(比较并协调听力系统的两个助听器之间的降噪)仅在单耳波束形成器(各个助听器的波束形成器)未提供足够的帮助量(例如不能提供等于ides的语音可懂度测量)的情形下被使能。同样,耳朵之间传输的数据量取决于估计的语音可懂度(因而可被减少)。
app
另一方面,本发明还提供称为app的非短暂应用。app包括可执行指令,其配置成在辅助装置上运行以实施用于上面描述的、“具体实施方式”中详细描述的及权利要求中限定的助听器或听力系统的用户接口。在实施例中,该app配置成在移动电话如智能电话或另一使能与所述助听器或听力系统通信的便携装置上运行。
定义
在本说明书中,“听力装置”指适于改善、增强和/或保护用户的听觉能力的装置如助听器例如听力仪器或有源耳朵保护装置或其它音频处理装置,其通过从用户环境接收声信号、产生对应的音频信号、可能修改该音频信号、及将可能已修改的音频信号作为可听见的信号提供给用户的至少一只耳朵而实现。“听力装置”还指适于以电子方式接收音频信号、可能修改该音频信号、及将可能已修改的音频信号作为听得见的信号提供给用户的至少一只耳朵的装置如头戴式耳机或耳麦。听得见的信号例如可以下述形式提供:辐射到用户外耳内的声信号、作为机械振动通过用户头部的骨结构和/或通过中耳的部分传到用户内耳的声信号、及直接或间接传到用户耳蜗神经的电信号。
听力装置可构造成以任何已知的方式进行佩戴,如作为佩戴在耳后的单元(具有将辐射的声信号导入耳道内的管或者具有安排成靠近耳道或位于耳道中的输出变换器如扬声器)、作为整个或部分安排在耳廓和/或耳道中的单元、作为连到植入在颅骨内的固定结构的单元如振动器、或作为可连接的或者整个或部分植入的单元等。听力装置可包括单一单元或几个彼此电子通信的单元。扬声器可连同听力装置的其它部件一起设置在壳体中,或者其本身可以是外部单元(可能与柔性引导元件如圆顶状元件组合)。
更一般地,听力装置包括用于从用户环境接收声信号并提供对应的输入音频信号的输入变换器和/或以电子方式(即有线或无线)接收输入音频信号的接收器、用于处理输入音频信号的(通常可配置的)信号处理电路(如信号处理器,例如包括可配置(可编程)的处理器,例如数字信号处理器)、及用于根据处理后的音频信号将听得见的信号提供给用户的输出单元。信号处理器可适于在时域或者在多个频带处理输入信号。在一些听力装置中,放大器和/或压缩器可构成信号处理电路。信号处理电路通常包括一个或多个(集成或单独的)存储元件,用于执行程序和/或用于保存在处理中使用(或可能使用)的参数和/或用于保存适合听力装置功能的信息和/或用于保存例如结合到用户的接口和/或到编程装置的接口使用的信息(如处理后的信息,例如由信号处理电路提供)。在一些听力装置中,输出单元可包括输出变换器,例如用于提供空传声信号的扬声器或用于提供结构或液体传播的声信号的振动器。在一些听力装置中,输出单元可包括一个或多个用于提供电信号的输出电极(例如用于电刺激耳蜗神经的多电极阵列)。
在一些听力装置中,振动器可适于经皮或由皮将结构传播的声信号传给颅骨。在一些听力装置中,振动器可植入在中耳和/或内耳中。在一些听力装置中,振动器可适于将结构传播的声信号提供给中耳骨和/或耳蜗。在一些听力装置中,振动器可适于例如通过卵圆窗将液体传播的声信号提供到耳蜗液体。在一些听力装置中,输出电极可植入在耳蜗中或植入在颅骨内侧上,并可适于将电信号提供给耳蜗的毛细胞、一个或多个听觉神经、听觉脑干、听觉中脑、听觉皮层和/或大脑皮层的其它部分。
听力装置如助听器可适应特定用户的需要如听力受损。听力装置的可配置的信号处理电路可适于施加输入信号的随频率和电平而变的压缩放大。定制的随频率和电平而变的增益(放大或压缩)可在验配过程中通过验配系统基于用户的听力数据如听力图使用验配基本原理(例如适应语音)确定。随频率和电平而变的增益例如可体现在处理参数中,例如经到编程装置(验配系统)的接口上传到听力装置,并由听力装置的可配置的信号处理电路执行的处理算法使用。
“听力系统”指包括一个或两个听力装置的系统。“双耳听力系统”指包括两个听力装置并适于协同地向用户的两只耳朵提供听得见的信号的系统。听力系统或双耳听力系统还可包括一个或多个“辅助装置”,其与听力装置通信并影响和/或受益于听力装置的功能。辅助装置例如可以是遥控器、音频网关设备、移动电话(如智能电话)或音乐播放器。听力装置、听力系统或双耳听力系统例如可用于补偿听力受损人员的听觉能力损失、增强或保护正常听力人员的听觉能力和/或将电子音频信号传给人。听力装置或听力系统例如可形成广播系统、主动耳朵保护系统、免提电话系统、汽车音频系统、娱乐(如卡拉ok)系统、远程会议系统、教室放大系统等的一部分或者与其交互。
本发明的实施例如可用在助听器系统或其它便携音频处理系统应用中。
附图说明
本发明的各个方面将从下面结合附图进行的详细描述得以最佳地理解。为清晰起见,这些附图均为示意性及简化的图,它们只给出了对于理解本发明所必要的细节,而省略其他细节。在整个说明书中,同样的附图标记用于同样或对应的部分。每一方面的各个特征可与其他方面的任何或所有特征组合。这些及其他方面、特征和/或技术效果将从下面的图示明显看出并结合其阐明,其中:
图1a示出了根据本发明的助听器的实施例,其包括单一输入变换器。
图1b示出了根据本发明实施例的用于提供合成信号的控制器的运行流程图。
图2示出了根据本发明的助听器的实施例,其包括多个输入变换器及包括用于对电输入信号进行空间滤波的波束形成器。
图3a在上部示意性地示出了表示声音的模拟电(时域)输入信号、该模拟信号的数字采样,及在下部示出了分别将样本安排在非重叠和重叠时间帧中的两个不同方案。
图3b示意性地将图3a的电输入信号的时频表示示为时频瓦(k’,m)的图,其中k’和m分别为频率和时间指数。
图4a示出了助听器的第一实施例的框图,其示出了在根据本发明的助听器的信号的时频处理中使用“双分辨率”。
图4b示出了助听器的第二实施例的框图,其示出了在根据本发明的助听器的信号的时频处理中使用“双分辨率”。
图5示出了根据本发明第一实施例的助听器运行方法的流程图。
图6示出了根据本发明第二实施例的助听器运行方法的流程图。
通过下面给出的详细描述,本发明进一步的适用范围将显而易见。然而,应当理解,在详细描述和具体例子表明本发明优选实施例的同时,它们仅为说明目的给出。对于本领域技术人员来说,基于下面的详细描述,本发明的其它实施方式将显而易见。
具体实施方式
下面结合附图提出的具体描述用作多种不同配置的描述。具体描述包括用于提供多个不同概念的彻底理解的具体细节。然而,对本领域技术人员显而易见的是,这些概念可在没有这些具体细节的情形下实施。装置和方法的几个方面通过多个不同的块、功能单元、模块、元件、电路、步骤、处理、算法等(统称为“元素”)进行描述。根据特定应用、设计限制或其他原因,这些元素可使用电子硬件、计算机程序或其任何组合实施。
电子硬件可包括微处理器、微控制器、数字信号处理器(dsp)、现场可编程门阵列(fpga)、可编程逻辑器件(pld)、选通逻辑、分立硬件电路、及配置成执行本说明书中描述的多个不同功能的其它适当硬件。计算机程序应广义地解释为指令、指令集、代码、代码段、程序代码、程序、子程序、软件模块、应用、软件应用、软件包、例程、子例程、对象、可执行、执行线程、程序、函数等,无论是称为软件、固件、中间件、微码、硬件描述语言还是其他名称。
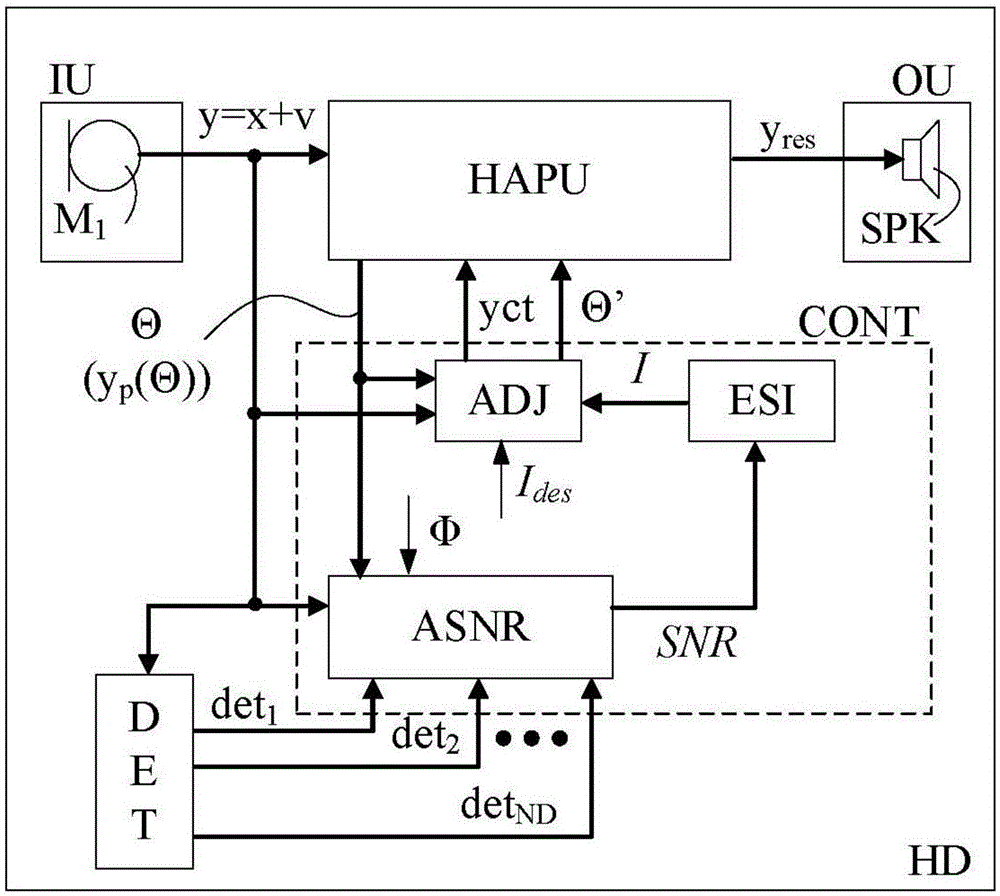
图1a示出了根据本发明的助听器的实施例,其包括单一输入变换器。图1a示出了适于由用户佩戴的助听器(hd)(例如佩戴在用户耳朵处或耳朵中,或者完全或部分植入在用户头部中)。助听器适于从用户环境接收包括语音的声音。助听器可适应用户的听力情况,例如配置成补偿用户的听力受损,及适于提高用户对声音中的语音的可懂度。用户的听力情况例如通过参数φ(或参数集,例如包括多个参数和/或数据,例如代表用户的听觉阈,或者确定用户的相较于正常平均值的随频率而变的听力损失的听力图)确定。用户对声音中的语言的可懂度的估计量例如通过语音可懂度模型确定,例如体现在给定(如当前)时间点t的声音的语音可懂度测量i(t)中(例如语音可懂度指数,例如如美国国家标准委员会(ansi)标准ansi/asas3.5-1997例如r2017)[5]中确定的,或者stoi可懂度测量[11])。
助听器hd包括用于提供多个(在此为一个)电输入信号y的输入单元iu,每一电输入信号表示用户环境中的声音。助听器hd还包括可配置的信号处理器hapu,用于根据一个或多个处理算法的可配置的参数设置θ处理电输入信号并提供合成(优选优化的如处理后)信号yres。助听器hd包括输出单元ou,用于提供表示(合成)处理后信号并可由用户感知为声音的刺激。输入单元iu、信号处理器hapu和输出单元ou在工作时连接并形成助听器的正向通路的一部分。在图1a的实施例中,输入单元iu包括传声器m1形式的单一输入(声音)变换器。输入单元例如还可包括用于将电输入信号y提供为数字样本流(例如具有fs=20khz或更高的采样频率)的模数转换器,和/或用于按时频表示y(k’,m)提供电输入信号y的分析滤波器组,k’和m分别为频率和时间指数。电输入信号y可不损失一般性地表达为目标信号分量x和噪声信号分量v的和。电输入信号y(在图1a中记为y=x+v)被假定(至少在某些时间段)包含目标(语音)信号(在此记为x)与其它信号(称为噪声,在此记为v)的混合。来自信号处理器的(合成)可能处理后的信号yres例如可表示当前目标信号的估计量,或者这样的信号的计划呈现给用户的某些部分(例如被适当滤波或放大或衰减以匹配用户当前的需要)。在图1a的实施例中,输出单元ou包括输出变换器,在此为扬声器spk,用于将合成信号yres转换为声学信号。输出单元ou例如还可包括合成滤波器组,用于将来自多个子频带信号的合成信号yres的时频表示转换为单一时域信号。输出单元ou例如还可包括数模转换器,用于将数字样本流转换为模拟信号。
助听器hd还包括控制器cont(参见图1a中的虚线框),配置成根据多个输入和预定判据控制所述处理器提供合成信号yres(在给定时间点)。输入包括a)电输入信号y的语音可懂度测量i(y);b)基于一个或多个处理算法的第一参数设置θ1(例如在时频单元级提供最大可懂度i和/或信噪比snr的参数设置θ1)的第一处理后信号yp(θ1)的语音可懂度测量i(yp(θ1))。所述输入还包括c)语音可懂度测量的期望值ides(例如存储在存储器中,例如可经用户接口配置);d)标示用户的听力情况(例如反映正常听力或听力受损)的参数集φ。受预定判据(i(y)<ides和i(yp(θ1)>ides)支配,合成信号yres(在给定时间点)根据e)一个或多个处理算法的、在第二处理后信号yp(θ’)的语音可懂度测量i(yp(θ’))等于期望值ides的约束条件下确定的第二(优化的)参数设置θ’进行确定。听力装置如控制器被配置成在第二处理后信号yp(θ’)展现语音可懂度测量i的期望值ides的约束条件下确定第二参数设置θ’。第二参数设置θ’可通过多种方法确定,例如可能的值之中的穷尽搜索,例如基于已知对语音可懂度重要的特定频带的系统变化(例如使用迭代方法),和/或用另外的约束条件优化,或者使用语音可懂度测量的特定性质,例如其信噪比的单调依存性,或者使用统计方法、迭代等。
在图1a的实施例中,控制器cont包括snr估计单元asnr,用于基于(未处理的)电输入信号y或者基于使用一个或多个处理算法的特定参数设置θ处理(例如随后的步骤中确定的,或者并行,如果两个独立的asnr算法在手边)后的信号yp估计表观snr,snr(k’,m,φ)。snr估计单元asnr接收关于用户的听觉能力(听力情况)2听力受损的信息,例如通过听力图反映,参见输入参数φ。(未处理的)电输入信号y可由输入单元iu提供。基于第一参数设置θ1的第一处理后信号yp(θ1)例如可由信号处理器提供并用作snr估计单元asnr的输入。在实施例中,基于第二参数设置θ’的第二处理后信号yp(θ’)由信号处理器提供并用作snr估计单元asnr的输入以检查其语音可懂度测量i(yp(θ’))是否满足实质上等于ides的判据。控制器cont还包括语音可懂度估计器esi,用于分别基于相应输入信号的表观snr即snr(k’,m,φ)、snr(k’,m,θ1,φ)和snr(k’,m,θ’,φ)估计当前电输入信号y及处理后信号yp如第一和第二处理后信号(yp(θ1),yp(θ’))的用户可懂度的估计量i。语音可懂度的估计例如以比snr和参数设置(θ1,θ’)的估计低的频率分辨率进行。语音可懂度估计器esi可包括分析滤波器组(或者用于将多个子频带k’合并为更小数量k的频带求和单元,例如参见图3b),用于以适当数量和大小的频带提供输入信号,例如将频率范围分布到三分之一倍频带。控制器cont还包括调整单元adj,用于提供控制处理器hapu的合成信号yres的控制信号yct。受特定判据支配,调整单元配置成调整参数设置θ以提供第二(优选优化的)参数设置θ’,如果实际上可实现,其提供将作为合成信号yres呈现给用户的第二处理后信号yp(θ’)的期望的语音可懂度ides。所述特定判据可以是i(y)≤ides及i(yp(θ1))≥ides。优化的(第二)参数设置θ’可取决于用户的估计的可懂度i和/或当前的处理后信号(yp(θ))的表观snr,及期望的语音可懂度测量ides(例如存储在助听器的存储器中)。优化的(第二)参数设置θ’由信号处理器hapu的一个或多个处理算法用于处理电输入信号y,及提供(第二、优化的)处理后信号yp(θ’)(如果可能,为用户产生期望水平的语音可懂度(ides))。在实施例中,呈现给用户的合成信号yres等于优化的第二处理后信号yp(θ’)或者等于其进一步处理后的版本。
图1a中所示助听器的实施例还包括检测器单元det,其包括(或连接到)多个(nd个)(内部或外部)传感器,每一传感器提供相应的检测器信号det1,det2,…,detnd。控制器cont配置成从检测器单元det接收检测器信号并根据检测器信号影响处理器hapu的控制。检测器单元det接收电输入信号y,但可另外或者作为备选地接收来自其它源的信号。一个或多个检测器信号可基于电输入信号y的分析。一个或多个检测器可独立于(或者不直接依赖于)电输入信号y,例如提供光学信号、脑电波信号、眼睛凝视信号等,其包含关于环境中的信号如目标信号的信息,例如其定时或其空间起点等,或者噪声信号(例如分布或特定位置)。来自检测器单元det的检测器信号由多个传感器(检测器)提供,例如图像传感器,例如照相机(例如朝向当前目标讲话者的面部(嘴巴),例如用于提供关于目标信号的备选(不随snr而变的)信息,例如话音活动检测)、脑电波传感器、运动传感器(例如用于提供标示目标信号的到达方向(doa)的头部定向的头部跟踪器)、eog传感器(例如用于确定目标信号的doa,或者指明最可能的多个doa)。
在图1a的实施例中,输入单元iu被示为仅提供一个电输入信号y。一般地,多个(m个)电输入信号y=y1,…,ym可被提供(例如如图2中所示)。在实施例中,m=2或3。
图1b示出了根据本发明实施例的用于根据语音可懂度测量i(例如“语音可懂度指数”[5])提供合成信号yres的控制器(参见图1a中的cont)的运行流程图。
图1b中所示控制器cont的实施例被配置成,在i(y)小于语音可懂度测量i的期望值ides及i(yp(θ1))大于该期望值ides时,使得合成信号yres等于第二处理后信号yp(θ’)(基于优化的参数设置θ’)。所述控制器cont还被配置成,在第二处理后信号yp(θ’)展现语音可懂度测量的期望值ides的约束条件下确定第二参数设置θ’。这在下面进一步详细阐述。
一个或多个处理后或未处理的信号的语音可懂度测量在连续的时间点t进行确定,如图1b中的单元或处理步骤“t=t+1”所示。连续的时间点例如可以是相应信号的每相继的时间帧(通过时间帧指数m确定)。作为备选,连续的时间点可指更低的比率,例如每第10个时间帧。
控制器被配置成,在所涉及的电输入信号y(在图2中例如假定为y1)的语音可懂度测量i的当前值i(y)大于或等于语音可懂度测量i的期望值ides时,使得当前时间点t的合成信号yres等于电输入信号y之一(参见相应的单元或处理步骤,“确定i(y(t))”、“i(y(t))≥ides?”、及在后者为真时(分支“是”),单元或处理步骤“跳过处理算法。设定yres(t)=y(t)”,及将时间推进到下一时间指数“t=t+1”)。
在“i(y(t))≥ides?”为假(分支“否”)时,即如果多个电输入信号y的语音可懂度测量i小于期望值ides,控制器还被配置成根据预定判据控制处理器提供当前时间点t的合成信号yres。预定判据与基于所涉及处理算法的第一参数设置θ1的第一处理后信号yp(θ1)的特性有关,例如使snr或可懂度测量最大化的参数设置。例如,如果第一处理后信号yp(θ1)的语音可懂度测量i的当前值i(yp(θ1))小于或等于语音可懂度测量i的期望值ides(参见相应单元或处理步骤,“确定i(yp(θ1,t))”、“i(yp(θ1,t))≤ides?”(即分支“是”),换言之,如果处理算法不能足够补偿输入信号中的噪声,单元或处理步骤“选择适当的信号ysel。设定yres(t)=ysel(t)’”,例如根据预定判据,例如根据ides–i(yp(θ1,t))的差的大小,并使时间推进到下一时间指数“t=t+1”)。可选信号ysel例如可包括或者可以是向用户指明目标信号质量差(及很难理解)的信息信号。控制器例如可被配置成控制处理器使得(可选信号ysel因而及)当前时间点t的合成信号yres等于电输入信号y之一,或者等于第一处理后信号yp(θ1),例如被衰减和/或与信息信号(例如参见图2中的yinf)叠加。
在“i(yp(θ1,t))≤ides?”为假(分支“否”)时,即如果处理后信号yp(θ1,t)的语音可懂度测量i大于期望值ides,控制器还被配置成在第二处理后信号yp(θ’)展现语音可懂度测量的期望值ides的约束条件下确定处理算法的第二参数设置θ’,及控制处理器使得当前时间点t的合成信号yres等于第二优化的处理后信号yp(θ’)(参见相应的单元或处理步骤,“找到θ’、使得i(yp(θ’,t)=ides。设定yres=yp(θ’,t)’”并使时间推进到下一时间帧“t=t+1”)。
第一参数设置θ1例如可以是使第一处理后信号yp(θ1)的信噪比(snr)和/或语音可懂度测量i最大化的设置。第二(优化的)参数设置θ’例如是(在由一个或多个处理算法应用于处理多个电输入信号时)提供第二(优化的)处理后信号yp(θ’)的设置,其为用户产生期望的语音可懂度水平,如语音可懂度测量的期望值ides反映的。
一个或多个处理算法例如可由单通道降噪算法构成或者包括单通道降噪算法。单通道降噪算法配置成接收单一电信号,例如来自(可能全向)传声器的信号,或者空间滤波的信号,例如来自波束形成器滤波单元。作为备选或另外,一个或多个处理算法可由波束形成器算法构成或者包括波束形成器算法,其用于接收多个电输入信号或者多个电输入信号的处理后版本并提供空间滤波的波束成形信号。控制器cont配置成使用特定波束形成器设置控制波束形成器算法。第一参数设置θ1包括第一波束形成器设置,及第二参数设置θ’包括第二(优化的)波束形成器设置。第一波束形成器设置例如基于多个电输入信号及例如来自一个或多个传感器(例如包括话音活动检测器)的一个或多个控制信号进行确定,而不特别考虑当前波束成形信号的语音可懂度测量的值。第一参数设置θ1可构成或包括使(第一)波束成形信号的(目标)信噪比(snr)最大化的波束形成器设置。
例子:波束形成
在下面,通过波束形成(空间滤波)算法说明该问题。
波束形成/空间滤波技术对在声学富有挑战性的环境中提高助听器用户的语音可懂度提供最有效率的方法。然而,尽管波束形成器在许多情形下有益,但它们在其它情形下具有负面副作用。这些副作用包括:
a)导致响度损失的过度抑制:在一些情形下,波束形成器/降噪系统“太有效”并去除比必要更多的噪声。这具有终端用户体验到响度损失的负面副作用:声音电平简单地变得太低。除了不能理解目标语音信号之外,简单地由于听不见,用户还体验到对听觉场景缺乏“连通性”,因为噪声源不是仅被降低电平,而是被完全消除。
b)双耳波束形成系统空间线索失真:在采用双耳波束形成系统的情形下,即传声器信号可从一个助听器传到另一助听器及波束形成在接收助听器中执行时,众所周知,波束形成处理可引入空间线索失真。具体地,如果采用双耳最小方差无失真响应(mvdr)波束形成器,众所周知,背景噪声的空间线索被畸变使得它们变成与目标声音的空间线索一样。换言之,在波束形成器输出中,噪声听起来就像源自目标源的方向一样(如果实际的噪声源远离目标源,这令人混淆)。在实施例中,双耳降噪仅在各个(单耳)波束形成器未提供足够的帮助量(例如语音可懂度)时被启用。藉此,在耳朵之间的传输的数据量取决于估计的语音可懂度(并可在量上进行限制因而降低双耳助听器系统的功耗)。
在下面,我们使用术语“波束形成”覆盖其中多个传感器信号(传声器或其它)被(线性或其它方式)组合以形成比输入信号具有更符合需要的性质的增强信号的任何处理。我们还将可互换地使用术语“波束形成”和“降噪”。
已知上面的问题涉及降噪量与副作用量之间的权衡。
例如,对于具有单一点目标信号源和单一点类噪声源声学情形,最大降噪波束形成器能够通过将空间零放在其方向而实质上消除噪声源。因此,噪声被最大程度地去除,但终端用户体验到响度损失和对声学世界的“连通性”损失,因为点噪声源不是仅被抑制到例如允许容易的语音理解的水平,而是被完全消除。
类似地,对于在各向同性(扩散)噪声场中具有点目标源的双耳波束形成配置,最小方差无失真响应(mvdr)双耳波束形成器将非常明显地降低噪声电平,但处理后的噪声的空间线索在该处理中被修改。具体地,在原始噪声听上去就像源自所有方向的同时,在波束形成之后体验到的噪声听上去就像源自单一方向即目标方向。
对这些问题提出的解决方案在于最大降噪对于语音理解是不必要的过度行为的观察。即使才施加较温和的降噪方案,终端用户可能已能够没有困难地理解目标语音,该温和的降噪方案引起比上面描述的少得多的副作用。具体地,在具有目标点源和附加点噪声源的例子中,将点噪声源抑制6db就足以实现实质上100%的语音可懂度,而无需完全消除点噪声源。所提出的解决方案的想法是使波束形成器自动找到该合乎需要的权衡并应用6db的降噪(对于该情形),而不是消除噪声源。此外,在一般信噪比已经足够高从而用户能没有问题地理解语音的情形下,所提出的波束形成器将自动检测到该情况,且不应用空间滤波。
总之,对前述问题的解决方案是(自动)找到适当的权衡,即导致可接受的语音可懂度但不过度进行噪声抑制的波束形成器设置。
为了开发自动确定实现足够的语音可懂度所必要的空间滤波/降噪量的算法,需要判断将呈现给用户的信号的可懂度的方法。为此,所提出的解决方案依赖于非常一般的假设,即(可能听力受损的)听者所体验的语音可懂度i是信号的有关时频瓦中的信噪比snr(k,m,φ,θ)的某一函数f()。参数k、m分别指频率和时间。变量θ表示波束形成器设置(或者一般地“处理算法的处理参数”),例如用于线性组合传声器信号的波束形成器权重w。显然,波束形成器的输出信号的snr为波束形成器设置的函数。参数表示φ所涉及个体的听觉能力的模型/表征。具体地,φ可表示听力图,即用户的听力损失,在预先指定的频率下测得。作为备选,其可表示作为时间和频率的函数的听觉阈,例如通过听觉模型估计。snr被定义为φ的函数的事实预期可能的听力损失可被建模为附加噪声源(除了任何声学噪声之外),其也使可懂度降级。因此,我们通常将量snr(k,m,φ,θ)称为表观snr[5]。
因此,我们具有
i=f(snr(k,m,φ,θ))
一般地,函数f()随每一时频瓦中的snr(snr(k,m,φ,θ))单调递增。
该表达的众所周知的特殊情形是扩展语音可懂度指数(esii)[10],其可被近似为(参见[2]):
其中
在实施例中,处理的第一部分(例如处理电输入信号以提供第一波束形成器设置θ(k’,m))以第一频率指数k’表示的第一频率分辨率应用于各个频带,及处理的第二部分(例如确定语音可懂度测量i以用在将第一波束形成器设置θ(k’,m)修改为优化的波束形成器设置θ’(k’,m)中,这提供期望的语音可懂度ides)以第二频率指数k表示的第二(不同的,例如更低的)频率分辨率应用于各个频带(例如参见图3)。第一和/或第二频率指数可以均匀或不均匀,例如跨频率呈对数地分布。第二频率分辨率k例如可基于三分之一倍频带。
基本想法是基于下述观察:
1)到达预先指定的助听器传声器的信号的每一时频瓦中的snrsnr(k,m,φ)可被估计,例如使用[6]中概述的方法。我们已找到对波束形成器参数集θ的依存性,因为该snr在参考传声器处确定,在任何波束形成(或其它处理)应用于信号之前。
2)snr(k,m,φ)因助听器中的信号处理例如每一子频带k中的独立波束形成引起的增加也可被估计[6]。换言之,到达听者耳膜的信号的(表观)snrsnr(k,m,φ,θ)可被估计。
3)对应于特定符合特定用户需要的(最小)语音可懂度百分比的i值的估计量可在助听器的验配过程期间获得。
4)在运行时间,导致期望的i但尽可能小的改变传入信号的、助听器信号处理的特定设置例如波束形成器设置可在助听器中确定和应用。
如果碰巧未处理的信号(电输入信号)的表观snr超过期望的语音可懂度值ides,则将不应用波束形成。
下面为上面描述的基本想法的特定实施例。
首先,我们借助于例子概述怎样针对给定波束形成器设置计算snr(k,m,φ,θ)(部分1)。为能够清楚地阐释该想法,我们使用简单的示例波束形成器。该示例波束形成器的输出为最小方差无失真响应(mvdr)波束形成器的输出与在预定参考传声器处观察到的有噪声信号的线性组合。线性组合系数控制示例波束形成器的“进攻性”。应强调的是,该示例波束形成器仅用作例子。所提出的想法更具一般性并可应用于其它波束形成器结构和应用于波束形成器与单传声器降噪系统的组合,及应用于其它处理算法等。
其次,我们概述怎样找到波束形成器设置θ,其实现预先指定的、期望的可懂度水平,而不必过度抑制信号(部分2)。如同前面一样,该描述使用部分1中介绍的示例波束形成器的元件。然而,如图前面一样,基本想法可应用于更一般的设置,包括其它类型的波束形成器、单传声器降噪系统等。
1.snr作为波束形成器设置的函数-例子
在该部分,我们借助于例子概述怎样针对给定波束形成器设置计算snr(k,m,φ)。
假定m个传声器的助听器系统在有噪声环境中运行。具体地,假定第r个传声器信号由下式给出:
yr(n)=xr(n)+vr(n),r=1,...m,
其中yr(n)、xr(n)和vr(n)分别指在第r个传声器处观察到的有噪声信号、纯净目标信号和噪声信号。假定每一传声器信号被通过某一分析滤波器组,导致滤波器组信号y(k,m)=[y1(k,m)…ym(k,m)]t,其中k和m分别为子频带指数和时间指数,及上标t指转置。我们以类似的方式定义向量x(k,m)=[x1(k,m)…xm(k,m)]t和v(k,m)=[v1(k,m)…vm(k,m)]t。
为了该例子,假定我们将把线性波束形成器w(k,m)=[w1(k,m)…wm(k,m)]t应用于有噪声观察结果y(k,m)=[y1(k,m)…ym(k,m)]t以形成增强的输出:
d'(k,m)=[d'1(k,m)…d'm(k,m)]指从目标源到每一传声器的声学传递函数,及
d(k,m)=[d'1(k,m)/d'i(k,m)…d'm(k,m)/d'i(k,m)]
指到第i个(参考)传声器的相对声学传递函数[1]。此外,
cv(k,m)=e[v(k,m)v(k,m)h]
指噪声的互功率谱密度矩阵。为了后面方便,我们按照[6]对cv(k,m)进行分解:
cv(k,m)=λv(k,m)γv(k,m),
其中λv(k,m)为参考传声器(第i个传声器)处的噪声的功率谱密度,及γv(k,m)为噪声协方差矩阵,被归一化使得元素(i,i)等于1,参见[6]。
使用这些定义,我们已能进一步详细说明我们的示例波束形成器。假定我们的示例波束形成器w(k,m)为下面的形式:
w(k,m,αk,m)=αk,mwmvdr(k,m)+(1-αk,m)ei
其中
指最小方差无失真响应波束形成器的权重向量,及向量
ei=[0...1...0]
其中1位于指数i处(对应于参考传声器),及0≤αk,m≤1为权衡参数,其确定波束形成器的“进攻性”。代替该例子中提出的、mvdr波束形成器(wmvdr)与全向波束形成器(ei)的线性组合,作为备选,波束形成器的进攻性例如可通过不同集合的波束形成器权重(wz,z=1,…,nz,其中nz为不同进攻性程度的波束形成器的数量)确定。对于αk,m=1,w(k,m)与mvdr波束形成器同样(即可用在该例子中的最具“进攻性”的波束形成器),而对于αk,m=0,w(k,m)不应用任何空间滤波,使得波束形成器的输出与参考传声器处的信号同样(例如对应于来自全向传声器的电输入信号)。
使用该示例波束形成器系统,我们能找到波束形成器设置(在该例子中为αk,m)与合成snr(k,m,φ,θ)之间的联系。在此,我们已引入另外的参数θ,其表示波束形成器系统的参数集,即θ={αk,m},以明确地指明合成snr为波束形成器设置的函数。
为估计snr(k,m,φ,θ),可应用下面的程序(下面我们应用特定最大似然估计量,显然存在许多其它选择)。
1)计算到达预定参考传声器的目标语音信号的功率谱密度
2)计算到达预定参考传声器的噪声分量的功率谱密度
3)计算参考传声器处的snr的估计量
其中ε≥0是为避免负的snr估计量(和/或数值问题)引入的标量。
4)计算波束形成器的输出处的语音功率谱密度的估计量
5)计算波束形成器的输出处的噪声功率谱密度的估计量
6)为考虑用户的听觉阈t(k,m),通过修改噪声功率谱密度估计量
或者
7)计算波束形成器的输出处的表观snr的估计量
2.怎样找到实现预先指定的、期望的可懂度水平但不被过度抑制信号的波束形成器设置。例子
现在概述找到实现期望的语音可懂度水平的合乎需要的波束形成器设置θ的程序。原则上,搜索这些设置可被分为下面的三种情形:
i)期望的语音可懂度水平可被实现(或者被超过)而没有任何波束形成;
ii)最具进攻性的一组波束形成器不足以实现期望的语音可懂度;及
iii)存在导致期望的语音可懂度水平的一个或多个波束形成器设置。在该情形下,(在导致期望的可懂度的设置之中)选择波束形成器设置,其优化其它判据,例如原始信号的最小修改、最小的总噪声功率降低(例如以保持对声学环境的察觉)、保持波束图的空间最小值方向的设置等,如我们的在2017年3月31日提交到欧洲专利局的、名称为“ahearingdevicecomprisingabeamformerfilteringunit”的未决欧洲专利申请17164221.8中描述的。
假定反映期望的语音可懂度水平的值idesired可获得。例如,该值已在由听觉病矫治专家验配助听器系统时建立。则所提出的方法可概述如下。
1)
a)针对不存在波束形成系统的情形(对于上面的例子,该情形通过θ={ak,m=0}描述)计算snr(k,m,φ,θ);
b)计算合成的、估计的语音可懂度i=f(snr(k,m,φ,θ));
c)如果i≥idesired,未处理的信号已经足够可理解,波束形成系统将保持不存在。否则,进行到下面的步骤2。
2)
a)针对波束形成系统处于最具进攻性的设置的情形(对于上面的例子,该情形通过θ={ak,m=1}描述)计算snr(k,m,φ,θ);
b)计算合成的、估计的语音可懂度i=f(snr(k,m,φ,θ));
c)如果i≤idesired,即使对于最大程度处理的信号,期望的可懂度不能实现。呈现给用户的信号可以是最大程度处理的信号(但可使用反映知道该信号不具有足够的可懂度的其它选择:例如其可被决定以避免进攻性波束形成器设置并选择“较温和的”设置)。如果最大程度处理的信号导致高于必要的可懂度,i>idesired,进行到下面的步骤3。
3)
a)确定实现i=idesired的(可能多个)参数设置θ,其最低程度地处理传入信号,例如最低程度地降低波束形成器输出处的总噪声功率的波束形成器设置,或者导致最大的总信号响度的波束形成器设置,最佳地保持波束图的空间最小值的方向和值的波束形成器设置等(几个这样的次要要求可以预见)。例如,这可通过引入karush-kuhntucker条件(参见[4]中的243页)并确定满足这些条件的波束形成器参数设置实现,例如参见[2,3]。
图2示出了根据本发明的助听器的实施例,其包括多个输入变换器及包括用于对电输入信号yr进行空间滤波的波束形成器bf。图2中的助听器hd实施例包括与图1a、1b的实施例一样的功能元件,即:
a)用于接收包括声音的多个电输入信号、处理所述输入信号及传递合成信号以呈现给用户的正向通路,该正向通路包括a1)输入单元iu;a2)信号处理器hapu;及a3)输出单元ou;及
b)分析和控制部分,包括b1)检测器单元det;及b2)控制单元cont。
这些元件的一般功能已结合图1a、1b进行描述。图2实施例相较于图1a、1b实施例的差异在下面概述。
输入单元iu包括多个(≥2)传声器m1,…,mm,每一传声器提供电输入信号yr,r=1,…,m,每一电输入信号表示助听器(或者佩戴助听器的用户)环境中的声音。输入单元iu例如可包括模数转换器和时域到频域转换器(如滤波器组),只要对处理算法及其分析和控制适当。
信号处理器hapu配置成执行一个或多个处理算法。信号处理器hapu包括波束形成器滤波单元bf并被配置成执行波束形成器算法。波束形成器滤波单元bf从输入单元iu接收多个电输入信号yr,r=1,…,m或其处理后版本,并配置成提供空间滤波的波束成形信号ybf。波束形成器算法因而及波束成形信号受波束形成器参数设置θ控制。波束形成器算法的默认的第一参数设置θ1例如基于多个电输入信号yr,r=1,…,m,非必须地,及例如来自一个或多个传感器(例如包括话音活动检测器)的一个或多个控制信号det1,det2,…,detnd进行确定,以使波束成形信号ybf的信噪比最大化,特别考虑或不特别考虑当前波束成形信号ybf的语音可懂度测量i的值。第一参数设置θ1和/或基于其的波束成形信号ybf(θ1)被连同至少一(在此为全部)电输入信号yr,r=1,…,m一起馈给控制单元cont。基于第一参数设置θ1(及用户的听力情况,例如反映受损,φ)的波束成形信号ybf(θ)的可懂度的估计量i(ybf(θ))由语音可懂度估计器esi(参见图1a)提供并馈给调整单元adj(参见图1a)以(根据预定判据,如果可能,参见图1b及其描述)调整(优化)参数设置θ从而提供能实现呈现给用户的处理后信号yres的期望的语音可懂度ides的第二参数设置θ’。控制器例如调整单元adj(参见图1a)将下述接收为输入:a)多个电输入信号yr,r=1,…,m;b)多个电输入信号yr中的至少一个的估计的语音可懂度i(yr);c)第一参数设置θ1,和/或基于其的波束成形信号ybf(θ1);d)期望的语音可懂度ides;及e)基于第一参数设置θ1的波束成形信号ybf(θ1)的估计的语音可懂度i(ybf(θ1))。基于这些输入(a,b,c,d),控制器提供第二参数设置θ’,其被馈给波束形成器滤波单元bf并应用于电输入信号yr,r=1,…,m以在其基础上(在上面讨论的条件下)提供优化的波束成形信号ybf(θ’)。
图2实施例的信号处理器hapu还包括单通道降噪单元sc-nr(也称为“后滤波器”),用于进一步衰减空间滤波的信号ybf(θ)的有噪声部分并提供进一步降噪的信号ybf-nr(θ)。单通道降噪单元sc-nr接收控制信号nrc,例如配置成控制空间滤波的信号ybf(θ)的哪些部分适合进行衰减(噪声)及哪些部分应保持不变(目标)以实现i(ybf(θ’))=ides。控制信号nrc例如可基于一个或多个检测器信号det1,det2,…,detnd或者受其影响,例如指明不存在语音的时频单元的检测器信号,和/或来自目标消除波束形成器(也称为“阻塞矩阵”),例如参见ep2701145a1。
图2实施例的信号处理器hapu还包括(另外的)处理单元fp,用于提供降噪后信号ybf-nr(θ)的进一步处理。这样的进一步处理例如可包括一个或多个去相关测量(例如小的频移)以降低为补偿用户听力受损的反馈、电平压缩的风险。(进一步)处理的信号yres被提供为信号处理器hapu的输出并馈给输出单元ou以作为用户当前感兴趣的目标信号的估计量呈现给用户。(进一步)处理的信号yref被(非必须地)馈给控制单元,例如以使能检查(及非必须地确保)语音可懂度测量i(yres)反映期望的语音可懂度值ides,例如作为确定第二优化的参数设置θ’的迭代程序的一部分。在实施例中,信号处理器配置成基于估计的语音可懂度i控制所述另外的处理单元fp的处理算法,因为听力损失补偿也形成恢复可懂度的一部分。换言之,另外的处理单元的一个或多个处理算法(如压缩放大)可被包括在根据本发明的方案中。
图2实施例的信号处理器hapu还包括信息单元inf,配置成提供信息信号yinf,其例如可包含线索或讲话信号以将目标信号的估计的可懂度的当前状态通知给用户,例如预期可懂度差。信号处理器hapu可被配置成在合成信号中包括信息信号,例如将其加到电输入信号之一或者提供语音可懂度的最佳估计量的处理后信号(或者单独呈现信息信号,例如根据估计的语音可懂度的当前值,如本发明中提出的)。
可受益于所提出的方案的处理算法的例子
如上面例子中描述的,波束形成(如单耳波束形成)为使用本发明的处理优化方案的重要候选算法。第一参数设置θ及优化的参数设置θ’(通过所提出的方案导致)通常包括随频率和时间而变的波束形成器权重w(k,m)。
另一处理算法为双耳波束形成,其中左和右助听器的波束形成器权重wl和wr根据本发明例如根据本方案进行优化:
wl=αk,mwl,mvdr+(1-αk,m)el
wr=αk,mwr,mvdr+(1-αk,m)er
其中wl,mvdr和wr,mvdr分别指左和右助听器的最小方差无失真响应波束形成器的权重向量,及向量el和er具有下面的形式
ex,i=[0...1...0]
其中x=l,r,及1位于指数i处(对应于参考传声器),及其中0≤αk,m≤1为权衡参数,其确定波束形成器的“进攻性”。
又一处理算法为单通道降噪,其中相应参数设置(θ,θ’)将包括应用于例如波束成形信号的每一时频瓦的权重gk’,m,其中频率指数k’具有比(例如语音可懂度估计量i的,例如参见图3b)频率指数k精细的分辨率以能够基于时频瓦修改snr。
图3a示意性地示出了样本中的时变模拟信号y(t)(振幅-时间)及其数字化y(n),这些样本安排在多个时间帧中,每一时间帧包括ns个样本。图3a示出了模拟电信号(实线曲线y(t)),例如表示来自传声器的声输入信号,其在模数(ad)转换过程中转换为数字音频信号(数字电输入信号),在模数转换过程中,模拟信号以预定采样频率或速率fs进行采样,fs例如在从8khz到40khz的范围中(适应应用的特定需要),以在离散时间点n提供数字样本y(n),如从时间轴延伸的在其与所述曲线重合的端点(几乎)处具有实心点的垂直线所示(取决于数字表示中的比特数nb),表示在对应的不同时间点n的数字样本值。每一(音频)样本y(n)表示通过预定数量(nb)的比特表示声信号在时间n(或tn)的值,nb例如在从1到48比特的范围中,例如24比特。每一音频样本因而使用nb个比特量化(导致音频样本的2nb个不同的可能值)。
在模数(ad)过程中,数字样本y(n)具有1/fs的时间长度,例如对于fs=20khz,该时间长度为50μs。多个(音频)样本ns例如安排在时间帧中,如图3a下部示意性图示的,其中各个(在此均匀间隔的)样本按时间帧分组(1,2,…,ns)。同样如图3a的下部图示的,时间帧可连续地安排成非重叠(时间帧1,2,…,m,…,nm)或重叠(在此为50%,时间帧1,2,…,m,…,nmo),其中m为时间帧指数。在实施例中,一时间帧包括64个音频数据样本。根据实际应用,也可使用其它帧长度。
图3b示意性地将图3a的(数字化)电输入信号y(n)的时频表示示为时频瓦(tile)(k’,m)的图,其中k’和m分别为频率指数和时间指数。该时频表示包括信号的对应复值或实值在特定时间和频率范围的阵列或映射。该时频表示例如可以是将时变输入信号y(n)转换为时频域的(时变)信号y(k’,m)的傅里叶变换的结果。在实施例中,傅里叶变换包括离散傅里叶变换算法(dft),例如短时傅里叶变换算法(stft)。典型助听器考虑的从最小频率fmin到最大频率fmax的频率范围包括从20hz到20khz的典型人听频范围的一部分,如从20hz到12khz的范围的一部分。在图3b中,信号y(n)的时频表示y(k’,m)包括信号的量值和/或相位在指数(k’,m)确定的多个dft窗口(或瓦)中的复值,其中k’=1,….,k’表示k’个频率值(参见图3b中的纵向k’轴),及m=1,….,nm(或nmo)表示nm(或nmo)个时间帧(参见图3b中的水平m轴)。时间帧由特定时间指数m和对应的k’个dft窗口确定(参见图3b中的时间帧m的指示)。时间帧m表示信号y在时间m的频谱。包括所涉及信号的(实或)复值y(k’,m)的dft窗口或瓦(k’,m)在图3b中通过时频图中对应场的阴影图示。频率指数k’的每一值对应于频率范围δfk’,如图3b中通过纵向频率轴f指明。时间指数m的每一值表示时间帧。连续时间指数跨越的时间δtm取决于时间帧的长度及相邻时间帧之间的重叠程度(参见图3b中的水平t轴)。
在图3b的最左边的轴中,定义具有子频带指数k=1,2,…,k的k个(非均匀)子频带,每一子频带包括一个或多个dft窗口(参见图3b中的纵向子频带k轴)。第k个子频带(由图3b的右部的子频带k指明)包括多个dft窗口(或瓦)。特定时频单元(k,m)由特定时间指数m和多个dft窗口指数定义,如图3b中通过对应dft窗口(或瓦)周围的粗框架指明。特定时频单元(k,m)包含第k个子频带信号y(k,m)在时间m的复值或实值。在实施例中,子频带为三分之一倍频带。
两个频率指数标度k和k’表示两种不同水平的频率分辨率(第一较高的(指数k’)和第二较低的(指数k)频率分辨率)。两个频率标度例如可用于处理器或控制器的不同部分中的处理。在实施例中,控制器(图1、2中的cont)配置成确定用于估计语音可懂度测量i的信噪比snr,其用于将处理设置θ(k’,m)修改为优化的处理设置θ’(k’,m),其以比用于确定语音可懂度测量i(k,m)的第二频率分辨率(指数k)精细的第一频率分辨率(指数k’)提供期望的语音可懂度ides,这通常在三分之一倍频带中估计。
图4a示出了听力装置的框图,其示出了在听力装置的信号的时频处理中“双分辨率”的频率指数(分别记为k’和k,k’=1,…,k’,及k=1,…,k,其中k’>k)的示例性使用。听力装置hd如助听器包括包含传声器m1(在此为单一传声器)的输入单元iu,其提供(数字化的)时域电输入信号y(n),其中n为时间指数(例如样本指数)。多个声音输入yr,r=1,…,m可被提供,取决于处理算法p(θ),例如波束形成算法(例如参见图2)。听力装置包括分析滤波器组fba,例如包括用于将时域信号y(n)转换为k’个子频带信号y(k’,m)的短时傅里叶变换(stft)算法。在图4a的实施例中,用于处理输入信号的正向通路包括三个并行通路,其从分析滤波器组fba反馈到选择或混合单元sel-mix以在k’子频带提供合成信号yres。正向通路的信号处理器hapu(参见虚线框)包括第一和第二处理单元p(θ)(其分别表示以第一和第二参数设置θ1和θ’运行的处理算法p)、选择或混合单元sel-mix、信息单元inf和另外的处理单元fp。正向通路还包括合成滤波器组fbs,用于将k’个进一步处理的所得子频带信号y’res转换为对应的时域信号y’res(n),及包括输出单元ou,在此包括用于将进一步处理的合成信号y’res(n)转换为用于呈现给用户的声音信号的扬声器spk。
图4a中的信号通路的第一(上部)信号通路包括在k’频带中提供第一处理后信号yp(k’,m,θ1)的处理算法p(θ),其源自具有第一参数设置θ1(参见输入θ1)的处理算法p(θ)应用于多个电输入信号y(k’,m)(在此为一个电输入信号)。第一参数设置θ1例如通过增益g(k’,m,θ1)表示,针对每一时频指数(k’,m)(k’=1,…,k’)展现(可能复数)增益值g;换言之,
yp(k’,m,θ1)=y(k’,m)*g(k’,m,θ1)
图4a中的信号通路的第二(中间)信号通路包括在k’频带中提供第一处理后信号yp(k’,m,θ’)的处理算法p(θ),其源自具有第二(优化的)参数设置θ’(参见来自控制器cont的输入θ’)的处理算法p(θ)应用于多个电输入信号y(k’,m)(在此为一个电输入信号)。第二参数设置θ’例如通过增益g(k’,m,θ’)表示,针对每一时频指数(k’,m)(k’=1,…,k’)展现(可能复数)增益值g;换言之,
yp(k’,m,θ’)=y(k’,m)*g(k’,m,θ’)
给定参数设置θ(包括各个g(k’,m,θ)=gθ(k’,m))因而在每一时频单元(k’,m)中进行计算,参见图3b中的阴影矩形。对应的语音可懂度测量i(θ)可以较低的频率分辨率k进行确定。在图3b的例子中,语音可懂度测量i(θ)在时频单元(k,m)中具有一个值(由图3b中的实线框标示),而参数设置θ在同一(实线)时频单元(k,m)中具有四个值gθ(k’,m)。从而参数设置θ(增益gθ(k’,m))可以精细步长进行调整以提供展现期望的语音可懂度估计量ides的第二参数设置θ’(增益gθ’(k’,m))。
图4a中的正向通路的第三(下部)信号通路将电输入信号y(k’,m)k’个频带从分析滤波器组fba馈给选择或混合单元。
包括两个分开的分析通路及包括调整单元adj的控制器cont(参见虚线框)将第二(优化的)参数设置θ’提供给处理器hapu。每一分析通路包括“频带求和”单元bs,用于将k’个子频带转换为k个子频带(由k’->k标示),因而按k个频带提供相应的输入信号(tf单元(k,m))。每一分析通路还包括语音可懂度估计器esi,用于提供所涉及输入信号中的语音(在k个子频带中)的用户可懂度的估计量i。第一(图4a中最左边的)分析通路提供电输入信号y(k,m)的用户可懂度的估计量i(y(k,m)),及第二(最右边的)分析通路提供第一处理后的电输入信号yp(θ1(k,m))的用户可懂度的估计量i(yp(k,m))。基于电输入信号y(k,m)和第一处理后的电输入信号yp(θ1(k,m))中的语音的用户可懂度i的估计量,及基于期望的用户语音可懂度ides,可能及基于表示用户听力情况φ的参数集,调整单元adj确定馈给信号处理器hapu的控制信号yct,并控制器控制来自信号处理器的选择或混合单元sel-mix的合成信号yres。第二(优化的)参数设置θ’及合成信号(受控制信号yct控制)根据本发明进行确定,例如在迭代程序中,例如参见图1b或6。控制信号yct从控制器cont的调整单元adj馈给选择或混合单元sel-mix及信息单元inf。
信息单元inf(例如形成信号处理器hapu的一部分)提供信息信号yinf(或作为时域信号,或作为时频域(子频带)信号yinf),其配置成向用户指明目前声学情形关于估计的语音可懂度i的状态,尤其(或者仅仅)在可懂度被估计欠佳时(例如低于期望的语音可懂度测量ides,或者低于(第一)阈值ith)。信息信号可包含讲出的消息(例如存储在听力装置的存储器中或者从算法产生)。
另外的处理单元fp提供合成信号yres(k’,m)的进一步处理并在k’个子频带中提供进一步处理的信号y’res(k’,m)。进一步处理例如可包括将随频率和/或电平而变的增益(或衰减)g(k’,m)应用于合成信号yres(k’,m)以根据用户的听力情况φ补偿用户的听力受损(或者进一步补偿正常听力用户的困难听音情形)。
图4b示出了听力装置如助听器的第二实施例的框图,其示出了在根据本发明的助听器的信号的时频处理中使用“双分辨率”。图4b的实施例与图4a的实施例类似,但还包括以比正向通路的处理算法低的频率分辨率k(k个频带,在此假定在三分之一倍频带中,以模仿人听觉系统)使用snr的估计量(参见单元snr),语音可懂度测量i的估计的更具体的标示。
来自内部或外部传感器(如语音(话音)活动检测器,和/或其它如光检测器或生物传感器)的另外的输入未在图4a和4b中标示,但其当然可用于进一步提高听力装置的性能,如图1a中所指明的。
图5示出了根据本发明第一实施例的助听器运行方法的流程图。所述助听器适于由用户佩戴。所述方法包括:
s1,从用户环境接收包括语音的声音;
s2,提供用于估计用户在当前时间点t理解所述声音中的语音的能力的语音可懂度测量i;
s3,提供多个电输入信号,每一电输入信号表示用户环境中的所述声音;
s4,根据一个或多个处理算法的可配置参数设置θ处理所述多个电输入信号,并提供合成信号yres;
s5,通过根据下述因素提供当前时间点t的合成信号yres而控制所述处理:
-确定用户的听力情况的参数集φ;
-所述多个电输入信号y;
-针对至少一所述电输入信号y,所述语音可懂度测量i的当前值i(y);
-所述语音可懂度测量的期望值ides;
-所述一个或多个处理算法的第一参数设置θ1;
-基于所述第一参数设置θ1的第一处理后信号yp(θ1)的所述语音可懂度测量i的当前值i(yp(θ1));及
-所述一个或多个处理算法的第二参数设置θ’,当应用于所述多个电输入信号y时,其提供展现所述语音可懂度测量的所述期望值ides的第二处理后信号yp(θ’)。
图6示出了根据本发明第二实施例的助听器运行方法的流程图。图6示出了根据本发明实施例的包括多输入波束形成器并提供合成信号yres的助听器的运行方法的流程图。该方法在给定时间点t包括下述处理:
a1,针对参考传声器处接收的电输入信号yref确定snr;
a2,确定未处理的电输入信号yref的用户语音可懂度i的测量i(yref);
a3,如果i(yref)>ides,其中ides为语音可懂度测量i的期望值,设定yres=yref,及不应用处理算法;
否则,
b1,确定用于最大snr波束形成器(如mvdr波束形成器)的波束形成器滤波权重w(mx1)(~第一参数设置θ1):
其中
(波束成形信号(~处理后信号yp(θ1)=yp(w)),表示用户当前感兴趣的目标(语音)信号s的估计量
b2,确定最大snr波束形成器的输出snr(处理后信号yp(θ1))
其中
b3,确定估计的语音可懂度
其中f’(·)表示函数关系。
b4,如果imax-snr(=i(yp(θ1))≤ides(图6中的通路“是”),其中为语音可懂度测量i的期望值ides,设定yres=ysel,其中ysel为可选信号,例如等于未处理的输入信号yref或者等于第一处理后信号yres=yp(θ1),或者等于它们之一与指明可懂度情形困难的信息信号yinf的组合。
c1,如果imax-snr(=i(yp(θ1))≥ides(图6中的通路“否”),确定使得i(yp(θ’))=ides的波束形成器滤波系数(第二参数设置θ’,滤波权重w)。第二参数设置θ’可通过多种方法确定,例如可能值之中的穷尽搜索,和/或具有另外的约束条件,例如使用统计方法,例如利用i为snr的单调函数。
c2,设定yres=yp(θ’)。
优选地,参数设置θ’(k’,m)以比语音可懂度测量i(k,m)精细的频率分辨率k’进行确定。
当由对应的过程适当代替时,上面描述的、“具体实施方式”中详细描述的及权利要求中限定的装置的结构特征可与本发明方法的步骤结合。
除非明确指出,在此所用的单数形式“一”、“该”的含义均包括复数形式(即具有“至少一”的意思)。应当进一步理解,说明书中使用的术语“具有”、“包括”和/或“包含”表明存在所述的特征、整数、步骤、操作、元件和/或部件,但不排除存在或增加一个或多个其他特征、整数、步骤、操作、元件、部件和/或其组合。应当理解,除非明确指出,当元件被称为“连接”或“耦合”到另一元件时,可以是直接连接或耦合到其他元件,也可以存在中间插入元件。如在此所用的术语“和/或”包括一个或多个列举的相关项目的任何及所有组合。除非明确指出,在此公开的任何方法的步骤不必须精确按所公开的顺序执行。
应意识到,本说明书中提及“一实施例”或“实施例”或“方面”或者“可”包括的特征意为结合该实施例描述的特定特征、结构或特性包括在本发明的至少一实施方式中。此外,特定特征、结构或特性可在本发明的一个或多个实施方式中适当组合。提供前面的描述是为了使本领域技术人员能够实施在此描述的各个方面。各种修改对本领域技术人员将显而易见,及在此定义的一般原理可应用于其他方面。
权利要求不限于在此所示的各个方面,而是包含与权利要求语言一致的全部范围,其中除非明确指出,以单数形式提及的元件不意指“一个及只有一个”,而是指“一个或多个”。除非明确指出,术语“一些”指一个或多个。
因而,本发明的范围应依据权利要求进行判断。
参考文献
[1]s.gannot,d.burshtein,ande.weinstein,“signalenhancementusingbeamformingandnonstationaritywithapplicationstospeech,”ieeetrans.signalprocessing,vol.49,no.8,pp.1614—1426,aug.2001.
[2]c.h.taal,j.jensenanda.leijon,“onoptimallinearfilteringofspeechfornear-endlisteningenhancement,”ieeesignalprocessingletters,vol.20,no.3,pp.225-228,march2013.
[3]r.c.hendriks,j.b.crespo,j.jensen,andc.h.taal,“optimalnear-endspeechintelligibilityimprovementincorporatingadditivenoiseandlatereverberationunderanapproximationoftheshort-timesii,”ieeetrans.audio,speech,languageprocess.,vol.23,no.5,pp.851-862,2015.
[4]s.boydandl.vandenberghe,“convexoptimization,”cambridgeuniversitypress,2004.
[5]“americannationalstandardmethodsforthecalculationofthespeechintelligibilityindex,“ansis3.5-1997,amer.nat.stand.inst.
[6]j.jensenandm.s.pedersen,“analysisofbeamformerdirectedsingle-channelnoisereductionsystemforhearingaidapplications,”proc.int.conf.acoust.,speech,signalprocessing,pp.5728-5732,april2015.
[7]ep3057335a1(oticon)17.08.2016
[8]us20050141737a1(widex)30-06-2005
[9]ep2701145a1(oticon)26-02-2014
[10]koenraads.rhebergen,niekj.versfeld,wouter.a.dreschler),and,extendedspeechintelligibilityindexforthepredictionofthespeechreceptionthresholdinfluctuatingnoise,thejournaloftheacousticalsocietyofamerica,vol.120,pp.3988-3997(2006)
[11]ceesh.taal;richardc.hendriks;richardheusdens;jesperjensen,ashort-timeobjectiveintelligibilitymeasurefortime-frequencyweightednoisyspeech,acousticsspeechandsignalprocessing(icassp),2010ieeeinternationalconferenceon.
- 还没有人留言评论。精彩留言会获得点赞!