一种基于规则树检索的防火墙数据包匹配算法的制作方法
本发明涉及信息安全技术领域,尤其是一种基于规则树检索的防火墙数据包匹配算法。
背景技术:
在信息化时代,组织与个人在每时每刻都产生大量数据以及需求,并通过网络交互传输。这其中又隐藏了大量的恶意信息。防火墙作为保障网络安全的重要手段和设施,起着不可或缺的作用。防火墙设备的核心工作原理之一,就是根据预设或习得的规则,对过往数据包进行检查匹配并处理。这其中,通信数据匹配性能成为影响防火墙网络吞吐能力与响应速度的关键。高性能的数据包匹配策略与算法对优化防火墙设备网络性能具有重大意义。
传统的防火墙规则匹配算法具有各种不完善的地方。
比如linux的netfilter防火墙框架,对规则的匹配是简单的顺序匹配,具有线性时间复杂度,在大规模规则情景下效率低下。
ternarycam算法、bitmapintersection算法等是基于专用芯片与设备的算法,适用范围狭窄。
hierachicaltries是一种基于trie树的最长前缀匹配算法,该算法对规则维数的可扩展性支持比较差,规则动态更新困难,不支持业务逻辑层面的灵活高效匹配,比如地址范围、端口范围的比对;set-pruningtries算法通过复制规则来改进了hierachicaltries算法的回溯问题,但是又带来了空间复杂度上升以及对动态更新规则的困难;
rfc算法是另一类典型的包分类和规则匹配算法,其核心思想是构建规则的交叉乘积表来实现高效匹配。该算法实现比较复杂,在大规模规则集、多维的场景下,规则预处理和生成交叉乘积表的空间复杂度不可控。
还有另外一大类算法,核心思想是基于对规则的历史匹配数统计(统计数据可以来自防火墙引擎或防火墙日志统计),来调整规则的匹配顺序和优先级,从而达到降低规则的平均匹配数量,改善性能的效果。这类算法的缺点在于它的关键是依赖历史匹配数统计,依赖待处理数据的特征以及匹配统计情况,因此性能不稳定,优点是实现很简单。
技术实现要素:
本发明解决的技术问题在于提供一种基于规则树检索的防火墙数据包匹配算法;提供一种性能出色,空间复杂度可控,对增减规则支持友好的算法。
本发明解决上述技术问题的技术方案是:
所述的方法包括:预处理规则、构建规则树和数据包匹配;
所述的预处理规则是对规则进行形式化和标准化处理,包括逻辑合理性检查、逻辑关系拆分操作,产生结构完整一致的规则集;
所述的构建规则树是将所有规则进行处理,生成一个经过组织的、存储了所有规则信息的、易于快速检索的树状数据结构;
所述的数据包匹配包括如下步骤:
步骤1:解析要匹配的数据包,得到数据包特征;
步骤2:根据构建的规则树,对数据包的每个特征逐个进行检索匹配,最终匹配到某条规则;对匹配计数和回溯计数进行记录;
步骤3:执行匹配到的规则设置的策略,或匹配不到规则,执行默认策略。
所述的构建规则树包括如下步骤:
一、对每一条规则赋予识别序号;
二、将每条规则按字段分解,所有规则相同类型的字段组成一个表;相同值则合并存储;由序号哈希表索引;根据具体情况选择一个类型的字段充当根节点。
所述的根节点字段的检索是通过哈希索引进行。
所述的方法对字段的匹配方法是每一类字段的节点都记录回溯次数,依据每类字段的回溯计数之和的大小,来调整匹配的优先级;匹配顺序按回溯计数从小到大依次进行。
所述的方法对字段的匹配方法是每一类字段的节点都记录回溯次数,依据每类字段的回溯计数之和的大小,来调整匹配的优先级;匹配顺序按回溯计数从小到大依次进行。
所述的方法中,依据类型和先后顺序分别对数据包特征进行匹配;每匹配成功一个字段,就根据其记录的关联规则序号链表ref_list,匹配下一个字段;链表里的多个规则序号按匹配成功的统计计数,从大到小排序、依次进行匹配;匹配成功的规则序号,count增加计数记录,并根据计数调整链表项的先后排序;通过匹配计数机制来提高匹配成功率,减少匹配不成功导致的回溯;如果字段匹配失败,则退回上一个字段,去匹配上一个字段的链表里记录的下一个规则序号;如果所有序号都匹配失败,则增加此字段的回溯失败计数,再退回上一级字段,进行下一个匹配。
采用本发明基于规则树检索以及相关性能优化策略的数据包匹配算法,可以实现防火墙类设备中对数据的快速匹配,从而提高数据处理的性能。同时,又能保证算法的简单和适用性,具有良好的时间和空间复杂度,易于动态修改规则。
附图说明
下面结合附图对本发明进一步说明:
图1是本发明端口字段示意图;
图2是本发明节点字段索引逻辑图;
图3是本发明实施例中算法初始化构建规则树的流程图;
图4是本发明实施例中规则树匹配数据包的示意图。
具体实施方式
见图3,是本发明一个包括规则树构建以及处理数据包的流程图。包括如下方法:
第一步:预处理规则。
预处理规则,对输入的防火墙规则进行处理。这里指的防火墙,包括网络防火墙、数据库防火墙、web应用防火墙等所有基于数据分类和规则匹配原理来实现访问控制的系统和设备。本发明所述算法对它们皆适用。
该实施例中,对输入的防火墙规则进行预处理,以用于下一阶段进行规则树的构建;
其具体操作包括为:对规则进行形式化和标准化处理。如果提交的规则在描述字段上有缺失的,则对规则进行逻辑上的补全。检查补全后的规则是否存在逻辑上相等、被包含等情况,有则精简掉。对具有复杂逻辑,如列表、包含、相与等的规则进行分解。处理后,就得到了具有一致结构和完整业务逻辑的规则集。
例如,以网络防火墙规则为例。网络防火墙的规则不失一般性地,至少具有6个维度,它们是:
规则=(源地址,源端口,目的地址,目的端口,传输层协议,状态);
形式化表达为:
r=(s1,s2,s3,s4,s5,s6)
这里s1,s2等称为一个字段,不同位置的字段具有不同意义。假设有一条规则,禁止访问80与8888端口的请求进入。对于此规则,经过逻辑分解和字段补全等查找,可以转化为两条规则:
r1=(*,*,*,80,tcp,syn)
r2=(*,*,*,8888,tcp,syn)
*号表示该规则字段对内容不加限制,原理一致,只是一种特殊情况。本步骤生成标准化和结构化的规则,便于下一步进行处理。
第二步:构建规则树。本步骤是本发明所述算法的核心与关键部分,描述如何构建一棵规则树。
该实施例中,将所有规则进行处理,然后生成一个经过组织的、存储了所有规则信息的、易于快速检索的树状数据结构,这里称之为规则树。构建步骤如下:
一、对每一条规则赋予识别序号,用于定位和识别。识别序号可以简单地用正整数;
r1=(s11,s12,s13,s14,s15,s16)
r2=(s21,s22,s23,s24,s25,s26)
r3=(s31,s32,s33,s34,s35,s36)
...
rn=(sn1,sn2,sn3,sn4,sn5,sn6)
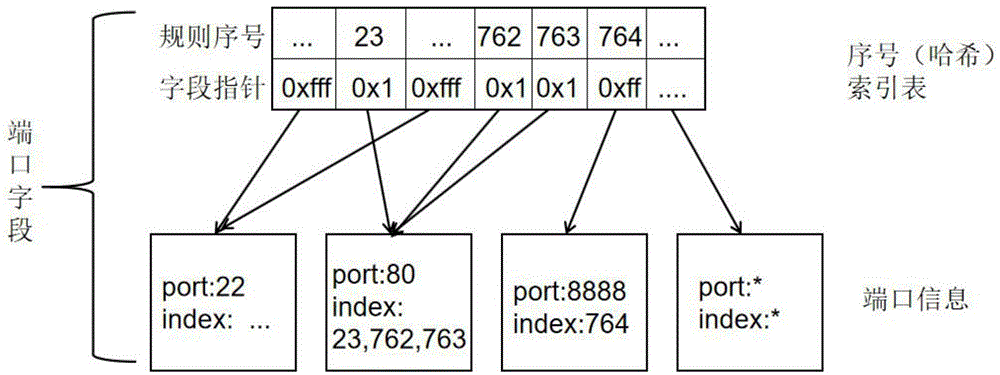
二、将每条规则按字段分解,所有规则相同类型的字段组成一个表,表的元素就是相同类型的字段,例如(s11,s21,s31,s41...sn1)。如果字段的内容有重复则合并之,并记录到同一个元素里,元素里也记录了该元素所存储的规则序号。元素记录的规则序号用于关联其他规则字段。该表的元素使用哈希表来索引,比如典型地,以规则序号来索引,哈希空间大小就是规则数量大小。如图1端口字段所示。
图1中,号索引表的数据结构实现代码示例(c语言描述)如下:
如此,依次对规则的所有字段进行处理,得到多个表;不同的表之间,规则序号作为索引,互相关联起来,形成一棵规则树。相同值的多个节点会由一个节点来表示,并记录它们的序号。这棵规则树可能有多个根节点,节点数取决于充当根节点的字段有多少个。例如,如果用协议类型字段充当根节点,则根节点就有三个,因为目前传输层协议有tcp、udp和sctp三种。
以上是树构建的基本方法,另外还有两个比较关键的地方。第一是根节点如何检索,因为根节点可能不止一个,而且它前面没有字段可以关联到其上;第二是多个字段匹配的先后顺序问题,此问题包括选用何个字段充当根节点。下面分别说明。
第一个问题,通过对根节点字段进行哈希索引来进行快速检索。如图2,根节点由协议字段来充当。假设网络防火墙支持3种传输层协议,分别是tcp、udp和sctp,使用某种方法,比如包头长度,来代表包的类型,从而构造出哈希表,从而实现索引。比如用目的端口字段做根节点,则可以直接用端口号来做索引。方法对所有类型的字段都是适用的。
第二个问题,各个字段的匹配先后顺序,原则是减少回溯,提高检索效率。方法是每一类字段的节点都会记录回溯次数,依据每类字段的回溯计数之和的大小,来调整匹配的优先级。匹配顺序按回溯计数从小到大依次进行。构造规则树的时候,每个字段的不同值,如图2的目的端口字段的值,21,80,1024等,每个值的数据结构都包含了recall_count字段。21,80,1024等节点的数据结构的recall_count字段之和,就是端口类字段的回溯计数之和。
第三步:规则树构建完毕,可以用于数据包匹配。如图4所示。
图4是规则树构建完毕后,数据包匹配过程的基本逻辑示意图。包括如下步骤:
第一步:解析数据包,得到描述数据包特征的各个特征字段。以前面步骤所述网络防火墙为例(具体实现中不排除还会匹配其他特征,如链路层协议),就是如下特征:
特征=(源地址,源端口,目的地址,目的端口,传输层协议,状态)
第二步:根据规则树的构建情况,可以知道各个字段匹配的类型和先后顺序。依据此类型和先后顺序分别对数据包特征进行匹配。如匹配port记录的端口是否一致。每匹配成功一个字段,就根据其记录的关联规则序号链表ref_list,匹配下一个字段。链表里的多个规则序号是按匹配成功的统计计数,从大到小排序过的,会依次进行匹配。匹配成功的规则序号,count会增加计数记录,并根据计数调整链表项的先后排序。通过匹配计数机制来提高匹配成功率,减少匹配不成功导致的回溯。如果字段匹配失败,则退回上一个字段,去匹配上一个字段的链表里记录的下一个规则序号。如果所有序号都匹配失败,则增加此字段的回溯失败计数,再退回上一级字段,进行下一个匹配。
第三步:如此,直到匹配到一条规则,然后执行规则设定的操作策略;如果匹配不到任何规则,则执行防火墙设定的默认策略。伪代码如下:
本发明的关键改进点及解决的问题如下:
一、对规则集的规则进行语义及业务逻辑层面的分解(区别于基于最长前缀树算法的ht匹配算法),并基于分解得到的字段构造规则树。此种规则集的处理方法,具有简单,时间和空间复杂度可控,支持灵活业务逻辑等特点,如端口范围匹配;
二、根节点的检索基于哈希算法,实现o(1)时间复杂度的检索;
三、规则树实现的数据结构支持匹配计数机制,可以实时动态调整部分具有相同特征字段的规则的匹配优先级,减少匹配路径的回溯数量;
规则树实现的数据结构支持回溯计数机制,基于此计数机制实时动态调整多个字段的匹配优先级问题,实现匹配的最少总回溯次数,改进检索性能。
- 还没有人留言评论。精彩留言会获得点赞!