无介质浮空投影声源定向语音交互系统、智能汽车的制作方法
本发明涉及无介质投影技术,特别涉及一种无介质浮空投影声源定向语音交互系统和智能汽车。
背景技术:
现有技术中,无介质浮空投影技术,利用一种使入射图像的光线产生弯曲的sma或dcra光学元件,所述光线在光学元件中经过至少2次反射后,形成与入射图像对应的空中实像。应用空中成像技术,不需要任何介质,可在不存在任何事物的空中,出现正事的映像,便于实现崭新的空中成像人机交互系统。虽然基于无介质浮空投影系统的成像具有单线可视的特点,但是观看者必须在固定的一个视角范围内进行观看体验,不能满足不同角度都进行观看交互,用户体验较差,并且不利于产业化。
技术实现要素:
根据本发明实施例,提供了一种无介质浮空投影声源定向语音交互系统,包含:
显示模块,所述显示模块用于产生影像内容;
投影模块,所述投影模块用于将所述影像内容转化成浮空的空中实像;
交互模块,所述交互模块用于实现用户对所述空中实像进行浮空触控操作;
声源定向模块,所述声源定向模块用于对声源进行定位,确定声源坐标;
控制模块,所述控制模块用于根据声源坐标控制所述显示模块的显示方向和所述交互模块的交互位置。
进一步,显示模块包含:
显示器,所述显示器用于显示外部设备的影像内容;
转向机构,所述转向机构与显示器连接,所述转向机构与所述控制模块通过电路连接。
进一步,转向机构为转盘。
进一步,投影模块包含光学成像元件,所述光学成像元件将显示模块所显示的影像内容,进行不少于2次反射,在浮空中形成与入射影像内容对应的空中实像。
进一步,光学成像元件为sma或dcra光学元件。
进一步,交互模块包含:
红外激光器,所述红外激光器设置在光学成像元件上,用于在浮空影像平面形成不可见光膜;
摄像头,所述摄像头用于定位所述空中实像的各个坐标点;
信号接收器,所述信号接收器用于接受用户对空中实像的触控信息。
进一步,声源定向模块包含:
语音识别模组,所述语音识别模组识别语音信息;
麦克风阵列,所述麦克风阵列包含声源定位处理器和若干麦克风,所述声源定位处理器对若干麦克风采集的声音进行声源定位。
进一步,麦克风的数量不少于2。
进一步,麦克风阵列包含但不限于一字、十字、平面、螺旋、球形及无规则阵列。
进一步,声源定位处理器对声源的定位算法包含但不限于基于时延估计算法、基于高分辨率谱估计算法、基于稀疏表示算法。
根据本发明又一实施例,提供了一种智能汽车,包含上述的无介质浮空投影声源定向语音交互系统。
根据本发明实施例的无介质浮空投影声源定向语音交互系统和智能汽车,可以随着用户的声音来源进行转动,用户在不同角度都可以观看使用,还可以进行语音互动,安装和应用场景丰富。
要理解的是,前面的一般描述和下面的详细描述两者都是示例性的,并且意图在于提供要求保护的技术的进一步说明。
附图说明
图1为根据本发明实施例无介质浮空投影声源定向语音交互系统的逻辑框图;
图2为根据本发明实施例无介质浮空投影声源定向语音交互系统的系统结构示意图;
图3为根据本发明实施例无介质浮空投影声源定向语音交互系统的声源定位原理流程图。
具体实施方式
以下将结合附图,详细描述本发明的优选实施例,对本发明做进一步阐述。
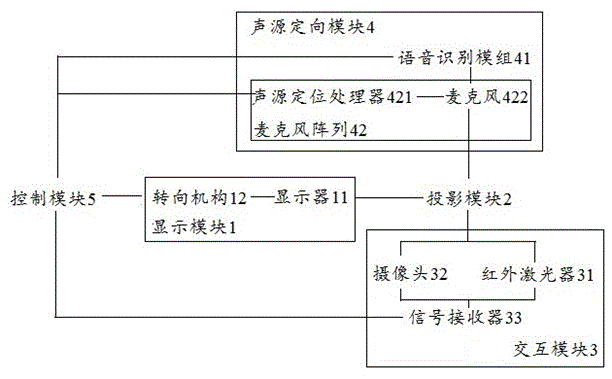
首先,将结合图1~3描述根据本发明实施例的无介质浮空投影声源定向语音交互系统,包含:显示模块1、投影模块2、交互模块3、声源定向模块4以及控制模块5。其中,显示模块1用于产生影像内容,投影模块2将影像内容转化成浮空的空中实像,通过交互模块3,用户可以对浮空投影进行浮空触控操作,同时,通过声源定向模块4,可以对用户的声源进行定位,确定声源坐标,不仅可以实现语音交互,还可以通过控制模块5改变显示模块1的显示方向和交互模块3的交互位置,以保证说话的用户能够看到浮空的空中实像。
具体地,如图1和2所示,显示模块1包含:显示器11和与显示器连接的转向机构12,其中,显示器11用于显示外部设备的影像内容,转向机构12和控制模块5通过电路连接,控制模块5与声源定向模块4相连,根据声源定位控制转向机构带动显示器11转向,以实现与系统进行语音交互的用户能够正视空中实像。在本实施例中,转向机构12为转盘。
具体地,如图1和2所示,投影模块2包含光学成像元件,光学成像元件将显示模块1所显示的影像内容,进行不少于2次反射,在浮空中形成与入射影像内容对应的空中实像,内容可以是2d或者3d的,兼容性强。在本实施例中,光学成像元件为sma或dcra光学元件,其中,sma光学元件为在透明平板的内部以一定的间距并列形成带状的平面光反射部的第一光控制面板、第二光控制面板以第一光控制面板的平面光反射部与第二光控制面板的平面光反射部交叉的方式相对配置的光学成像装置;而dcra光学元件则是由100μm大小的微小镜子组合而成的光学元件。光线在sma或dcra光学元件中经过至少2次反射后,形成与入射图像对应的空中实像,不需要任何介质,可在不存在任何事物的空中,出现正视的映像,实现崭新的空中成像人机交互系统。
具体地,如图1和2所示,交互模块3可以选用激光触控模块、深度摄像头、红外触控等模块进行交互,在本实施例中,以激光触控模块为例,交互模块3包含:红外激光器31、摄像头32以及信号接收器33。在dcra或者sma光学元件上安装一个红外激光器31,在浮空影像平面形成一个高于图像1-3mm、厚度约1mm的不可见光膜,摄像头32通过定位软件在空中获取画面的坐标点定位空中成像画面。当用户的手指或其他任何不透明的物体如触控笔等,接触空中成像画面时,光线被反射到的信号接收器33,再通过对光电位置的精确计算,得到手势的坐标,从而实现在空中进行触控,大大提高了人机交互的便捷性,并且,可实现多人操作。
具体地,如图1和2所示,声源定向模块4包含:语音识别模组41和麦克风阵列42,麦克风阵列42又包含声源定位处理器421和若干麦克风422,如图3所示,若干麦克风422将声音获取后,由声源定位处理器421对声音进行定位,同时,语音识别模组41则进行语音识别以及和用户进行语音交互,系统结合语音识别结果和定位,通过控制模块5控制显示器11进行相应动作,从而实现对显示方向和的交互位置的调整。在本实施例中,麦克风422的数量不少于2个,并且,麦克风阵列42包含但不限于一字、十字、平面、螺旋、球形及无规则阵列,可根据具体的产品定位和用户场景选择合适的麦克风阵列。在本实施例中,声源定位处理器421对声源的定位算法包含但不限于基于时延估计算法(time-delayestimation,tde)、基于高分辨率谱估计算法、基于稀疏表示算法。
需要特别说明的是,由于声源分为近场和远场,当声源足够远时,麦克风阵列42的直径与声源距离相比可忽略,此时一般采用声源的定位算法远场模型。远场模型认为声源位于无穷远处,麦克风422接收到的声波为平面波,此时仅考虑声波的入射方向,而不考虑声源相对于麦克风阵列42的距离。
当声源的距离较近时,需要考虑声源相对于麦克风阵列42中的距离,此时远场模型则不再适用,应当采用声源的定位算法近场模型。近场模型认为麦克风422接收到的声波为球面波,近场模型更符合实际应用情况,能提供更多的声源位置信息,提高定位的精度。在实际的近场模型应用中,麦克风阵列42所接收到的信号主要包括:声源直达信号、经过墙壁或障碍物的反射信号以及环境噪声信号,需要降噪处理。
根据本发明另一实施例,如图2和3所示,提供了一种智能汽车,包含了前述实施例的无介质浮空投影声源定向语音交互系统,能够为用户提供绝佳的驾乘体验。
以上,参照图1~3描述了根据本发明实施例的无介质浮空投影声源定向语音交互系统,可以随着用户的声音来源进行转动,可以与用户同时在不同角度进行交互,比如观看、触摸、语音互动,安装和应用场景丰富,不仅可以应用在智能办公系统、会议系统,还可以直接集成于智能汽车的整车中,大大提升了驾驶安全性和驾乘乐趣,革新了司机以及乘客与汽车的交互方式。
需要说明的是,在本说明书中,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个无介质浮空投影声源定向语音交互系统”限定的要素,并不排除在包括所述要素的过程、方法、物品或者设备中还存在另外的相同要素。
尽管本发明的内容已经通过上述优选实施例作了详细介绍,但应当认识到上述的描述不应被认为是对本发明的限制。在本领域技术人员阅读了上述内容后,对于本发明的多种修改和替代都将是显而易见的。因此,本发明的保护范围应由所附的权利要求来限定。
- 还没有人留言评论。精彩留言会获得点赞!