基于可疑度评估的HTTP混淆流量检测方法与流程
本发明涉及网络与信息安全技术,具体涉及一种基于可疑度评估的http混淆流量检测方法。
背景技术:
流量混淆技术利用特定手段将任意协议格式的数据转换成特定协议的数据,它既可以作为网络流量数据传输过程中的一种隐私保护手段,也可以用于对抗网络安全机制,泄露数据或用作c&c通道,威胁公众安全。尤其是http混淆技术,因为http被互联网广泛使用,对应的80端口承载着大量必要应用,所以几乎没有防火墙会对该端口进行封堵,这使http混淆十分泛滥。因此,检测http混淆流量的存在,防止危害发生,是至关重要的环节。http混淆流量检测技术作为网络安全防护领域内的一项非常重要的技术,引起了研究者的广泛关注,而且目前为止已经取得了很多的研究成果。
根据文献检索,发现现有的检测技术大部分都是基于机器学习分类算法,这种研究方法相比较传统的基于规则和模式的方式而言,有了很大的进一步,但是研究对象大多设定为某个特定混淆软件产生的混淆流量,并且有指定的监测环境,不具备通用性。同时这类检测方案的机器学习训练大都基于有限的实验数据,在较为封闭的数据集上的效果甚至接近100%,但真实网络环境中流量的形态更加丰富,这些基于较为封闭的实验数据得到的分类器,在真实的网络环境中会产生大量的虚警。
技术实现要素:
本发明的目的在于提供一种基于可疑度评估的http混淆流量检测方法。
本发明的目的在于提供一种基于可疑度评估的http混淆流量检测方法,包括以下流程:
步骤1:捕获网络流量数据,筛选出其中的http流量;
步骤2:提取http流中每个数据包的tcp有效负载,重组成完整报文;
步骤3:对每条流的首个请求报文和首个响应报文进行特征匹配,匹配内容为协议头部信息的完整性匹配、内容类型标识与负载实际类型的一致性匹配;
步骤4、根据匹配结果,计算每个特征的可疑度数值;
步骤5、进行可疑度加权,与可疑度阈值比较,确定混淆http。
作为一种优选实施方式,步骤1中,采用wireshark软件和hyperscan正则匹配库捕获网络流量数据。
作为一种优选实施方式,步骤2中,采用matlab软件提取http流中每个数据包的tcp有效负载。
作为一种优选实施方式,步骤3中,在协议头部完整性匹配过程中,设置一个长度为n的一维向量,代表所考察的n个首部字段的匹配结果,匹配对象中未出现的首部字段,一维向量中对应的位置设1;匹配对象中出现的首部字段,一维向量中对应的位置设0。
作为一种优选实施方式,步骤3中,内容类型标识与负载实际类型匹配包括负载的压缩格式匹配和负载mime类型匹配,具体为:
根据内容类型标识“content-encoding”字段匹配负载的压缩格式,若符合“content-encoding”字段,匹配结果设0,并解压负载数据;若不符合,匹配结果设1;
根据内容类型标识“content-type”字段匹配负载的mime类型,若负载类型为文本文件,则计算负载内容的负载信息熵,设负载信息x共有m个字符,当中的每个字符x出现的次数为n(x),则每个字符出现的概率为n(x)/m,由公式(1)计算负载熵:
若负载信息熵高于明文负载熵阈值,匹配结果设1,否则匹配结果设0;若负载类型为非文本文件,则根据“content-type”字段所标识的mime类型匹配负载数据的文件头,若符合“content-type”字段,匹配结果设0,否则匹配结果设1。
作为一种优选实施方式,步骤4中,由公式(2)计算每个特征的可疑度数值:
其中
作为一种优选实施方式,步骤5中,由公式(3)计算可疑度加权值:
其中
作为一种优选实施方式,步骤5中,根据可疑度加权值与可疑度阈值确定分类结果的判决函数如公式(4):
其中se(x)是数据流x的可疑度数值,thres是可疑度阈值,可疑度阈值可以根据实际网络情况和检测需求进行动态调整,若可疑度加权值大于等于可疑度阈值,输出结果为混淆http,否则输出结果为正常http。
有益效果:本发明在分析数据多种维度信息的基础上,根据匹配程度使用可疑度函数进行可疑度计算,并通过判决器进行混淆流量判定,可有效克服依赖流量特征带来的虚警率高的问题,具有良好的适应性,能够适应不同网络环境的复杂情况。
附图说明
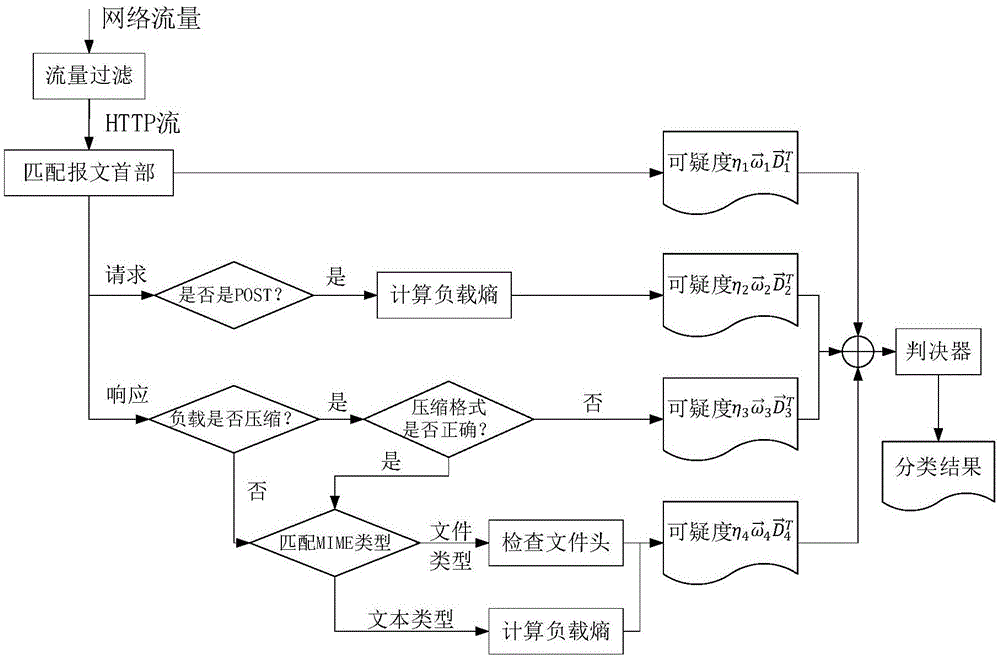
图1为本发明的流程示意图;
图2为明文和密文负载的负载信息熵分布散点图。
具体实施方式
下面结合附图和具体实施例,进一步说明本发明方案。
本发明通过分析http数据流的协议头部信息的完整性、内容类型标识以及负载的数据类型三个特征,使用可疑度函数计算各特征的可疑度,将计算结果输入判决器,由判决器判别数据流是否是http混淆流量,如图1所示,基于可疑度评估的http混淆流量检测方法,具体包括以下流程:
步骤1:设置数据捕获器,利用数据捕获器捕获网络流量数据,并筛选出其中的http流量;作为一种实施方式,数据捕获器可以采用wireshark软件和hyperscan正则匹配库。
步骤2:设置数据处理器,利用数据处理器提取http流中每个数据包的tcp有效负载,重组成完整报文;作为一种具体实施方式,数据处理器可以采用matlab。
步骤3:设置特征匹配器,利用特征匹配器分别对每条流的首个请求报文和首个响应报文进行特征匹配,匹配内容为协议头部信息的完整性匹配、内容类型标识与负载实际类型的一致性匹配。
在协议头部完整性匹配过程中,设置一个长度为n的一维向量,代表所考察的n个首部字段的匹配结果。匹配对象中未出现的首部字段,一维向量中对应的位置设1;匹配对象中出现的首部字段,一维向量中对应的位置设0;
内容类型标识与负载实际类型的一致性匹配中,根据内容类型标识“content-encoding”字段匹配负载的压缩格式,若符合“content-encoding”字段,匹配结果设0,并解压负载数据;若不符合,匹配结果设1;
根据内容类型标识“content-type”字段匹配负载的mime类型,若负载类型为文本文件,则计算负载内容的负载信息熵。设负载信息x共有m个字符,当中的每个字符x出现的次数为n(x),则每个字符出现的概率为n(x)/m。负载熵可由公式(1)计算:
若负载信息熵高于明文负载熵阈值,匹配结果设1,否则匹配结果设0。若负载类型为非文本文件,则根据“content-type”字段所标识的mime类型匹配负载数据的文件头,若符合“content-type”字段,匹配结果设0,否则匹配结果设。
步骤4:设置可疑度评估器,可疑度评估器根据步骤3的特征匹配器输出的匹配结果计算每个特征的可疑度数值,可疑度数值可由公式(2)计算:
其中
对于“协议头部信息”特征而言,
对于“负载数据类型”特征而言,匹配结果只有成功和失败两种,
步骤5:设置判决器,判决器根据可疑度加权值输出判决结果,可疑度加权值可由公式(3)计算:
其中
判决器根据可疑度加权值与可疑度阈值的比较结果输出分类结果。判决函数如公式(4):
其中se(x)是数据流x的可疑度数值,thres是可疑度阈值。可疑度阈值可以根据实际网络情况和检测需求进行动态调整。若可疑度加权值大于等于可疑度阈值,输出结果为混淆http,否则输出结果为正常http。
实施例
为了验证本发明方案的有效性,以某某某大学校园网为检测环境,进行如下仿真实验。
首先过滤网络流量,提取出http协议形式的数据流,分析http数据流的协议头部信息的完整性、内容类型标识以及负载的数据类型三个特征,使用可疑度函数计算各特征的可疑度,将可疑度的加权数作为判决器的输入,由判决器判别数据流属于正常http还是混淆http。具体流程如下:
步骤1:设置数据捕获器,利用数据捕获器捕获网络流量数据,并筛选出其中的http流量,筛选规则适用正则表达式“[a-za-z]{3,7}.*http/1.[0,1]”和“http/1.[0,1][0-9]{0,3}”。
步骤2:设置数据处理器,利用数据处理器提取http流中每个数据包的tcp有效负载,重组成完整报文。
步骤3:设置特征匹配器,利用特征匹配器分别对每条流的首个请求报文和首个响应报文进行特征匹配,匹配内容为协议头部信息的完整性匹配、内容类型标识与负载实际类型的一致性匹配。
在协议头部完整性匹配过程中,设置一个长度为12的一维向量,代表所考察的12个首部字段的匹配结果。匹配对象中未出现的首部字段,一维向量中对应的位置设1;匹配对象中出现的首部字段,一维向量中对应的位置设0。所考察的首部字段见表1。
表1为校园网中http报文首部字段信息的比例分布和对应的权重值;
根据内容类型标识“content-encoding”字段匹配负载的压缩格式,若符合“content-encoding”字段,匹配结果设0,并解压负载数据;若不符合,匹配结果设1。
根据内容类型标识“content-type”字段匹配负载的mime类型,若负载类型为文本文件,则计算负载内容的负载信息熵。设负载信息x共有m个字符,当中的每个字符x出现的次数为n(x),则每个字符出现的概率为n(x)/m。负载熵可由公式(1)计算:
若负载信息熵高于明文负载熵阈值5.5,匹配结果设1,否则匹配结果设0。若负载类型为非文本文件,则根据“content-type”字段所标识的mime类型匹配负载数据的文件头,若符合“content-type”字段,匹配结果设0,否则匹配结果设1。
步骤4:设置可疑度评估器,可疑度评估器根据步骤3的特征匹配器输出的匹配结果计算每个特征的可疑度数值,可疑度数值可由公式(2)计算:
其中
对于“协议头部信息”特征而言,
对于“负载数据类型”特征而言,匹配结果只有成功和失败两种,
步骤5:设置判决器,判决器根据可疑度加权值输出判决结果,可疑度加权值可由公式(3)计算:
其中
判决器根据可疑度加权值与可疑度阈值的比较结果输出分类结果。判决函数如公式(4):
其中se(x)是数据流x的可疑度数值,thres是可疑度阈值。可疑度阈值可以根据实际网络情况和检测需求进行动态调整。若可疑度加权值大于等于可疑度阈值输出结果为混淆http,否则输出结果为正常http。
本实例中设定{η1,η2,η3,η4}={0.2,0.5,0.5,0.5},采集到的正常http与混淆http的可疑度计算结果如表2所示。
表2为本发明流量数据可疑度评估实验结果
正常http中有5条的可疑度在0.5到0.7之间,经过分析发现这5条是web服务器发回的压缩编码的响应报文,头部字段“content-encoding”却被隐藏,导致负载类型匹配失败。混淆流量的可疑度数值大多落在0.5到0.7之间,当请求报文为post时,该条流的可疑度超过了1.0。可见本发明在检测http混淆流量通信中具有良好的效果。
- 还没有人留言评论。精彩留言会获得点赞!