蜂窝系统中的低复杂度MU-MIMO配对调度方法及其计算机程序产品和调度装置与流程
本发明涉及mu-mimo(多用户多输入多输出)配对和调度,并且更具体地,涉及电信网络的蜂窝系统中的联合用户配对/调度和预编码。
背景技术:
在电信网络的蜂窝系统中,多用户调度允许联合地实现每个用户的服务质量(qos)要求并优化系统频谱效率。多用户调度对于具有大量自由度的多载波系统而言变得至关重要,该多用户调度可以被调度程序利用以便改善频谱使用。
在实践中,与多用户调度相关的优化可能具有高复杂度并且代表重要的挑战。已经开发出自诩最优的低复杂度解决方案。例如,已经开发出基于度量最大化在一个资源之后分配另一资源的机会调度程序。在该示例中,度量与各个用户相关联并反映了向用户分配资源的有用性。已定义的度量反映了在服务质量(qos)达成、系统的频谱效率以及用户之间的公平性方面的资源分配。qos代表用户观察到的性能。公平性反映了调度程序以相似的比例服务于系统的不同用户的能力,也就是说,不是偏袒某些用户而损害其它用户。
随着长期演进(lte)系统的发展,已经开发出多天线技术。已经引入这些多天线技术以便增强频谱效率。这些技术在将若干用户的信号放在一起并以线性方式或非线性方式通过多个天线发送的情况下特别相关。
mimo传输管理强制调度程序考虑额外的维度:空间维度。空间预编码操作向传输提供空间属性,例如,该空间属性可以是通过形成指向特定方向的波束。这种额外的空间维度使得能够在各个接收器处分离信号。为此,由于反馈机制,信道在发射器处必须是公知的。这些反馈机制可以是tdd(时分双工)模式或fdd(频分双工)模式中的隐式或显式的信道状态信息反馈机制。
由于存在可以根据给定的效用函数进行优化的预编码(precoder),因此实现了多用户mimo(mu-mimo)。例如,特征波束形成方法可以最大化针对每个用户的有用信号功率,而不考虑用户之间的剩余干扰。波束成形是用于定向的信号发送或接收的信号处理技术。另一个示例是块对角预编码,该块对角预编码能够消除用户之间的干扰,但会降低有用信号功率。存在多种折衷技术;然而,要接近最优的信号与干扰加噪声比(sinr)或使容量最大化通常会需要高复杂度。通常情况下,网络的容量可以由高负载小区流动的最大总速率表示。由于矩阵运算,接近最优的mimo预编码确定会涉及到通常具有高复杂度的优化步骤。
可以注意到,在mu-mimo系统中,为了有效地收集那些信道兼容的用户,用户配对步骤是必需的。根据给定的预编码策略,这些信道需要在有用信号和剩余干扰功率方面兼容。这个配对步骤是通过创建mu-mimo信道(其中预编码展示了良好性能)而利用次优预编码方案来得到良好性能的机会。然而,该配对步骤增加了系统的自由度,进而增加了其优化复杂度。
多用户调度和mu-mimo技术的使用使得能够满足关于近期部署的蜂窝网络效率的要求。通常情况下,为了具有最低的复杂度,策略是基于长期方法来对用户进行配对。也就是说,针对用户和各个资源的各个固定对来计算调度程序度量,并执行机会调度程序。这种方法的一个缺点是:用户配对是静态的,这涉及到错过了考虑使用预编码技术而创建足够的mu-mimo信道的机会。
在现有技术中已经开发出使用块对角化预编码、配对以及调度方法的另一低复杂度联合多用户mimo。在该方法中,策略是根据调度程序度量连续选择要配对的用户。首先,选择具有最大无干扰容量的用户作为第一用户。其次,在固定的第一用户的干扰下选择具有最佳容量的用户作为第二用户,依此类推。该解决方案具有缺点。实际上,用户选择过程并未完全考虑信道的几何形状。在该方法中,第一用户容量确实是最大的,然而,第一用户的选择可以急剧减少第二用户容量等等。因此,即使这类方法具有低复杂度的优点,根据用户的容量来选择用户也远非最优。实际上,降低mimo预编码的计算复杂度和计算次数是有意义的。
技术实现要素:
本发明建议改进该情况。
本发明涉及一种在蜂窝系统中进行调度的方法,该蜂窝系统包括多个天线装置,多个天线装置发送多个空间流,其中,多个空间流服务于具有相应容量的多个用户,并且该方法为此包括:
-针对以下各项的各个可能组合计算近似调度度量:
○多个用户中的用户,以及
○多个空间流中的相关联的空间流,
近似调度度量是在不考虑干扰的情况下的用户容量的函数;
-按降序对近似调度度量进行排序以便获得可能组合的分类;
-为分类中的第一组合计算局部调度度量,该局部调度度量是在考虑干扰的情况下的实际用户容量的函数;
-针对分类中的各个后续组合:
○将后续组合的近似度量与先前计算出的局部调度度量进行比较,并且
○如果后续组合的近似度量高于先前计算出的局部调度度量,则计算后续组合的局部调度度量,而如果所计算出的局部调度度量高于先前计算出的局部调度度量,则用所计算出的局部调度度量替换先前计算出的局部调度度量,
○如果后续组合的近似度量低于或等于先前计算出的局部调度度量,则将提供先前计算出的局部调度度量的组合规定为用户与相关联的空间流的最佳组合。
利用这种方法,降低了计算复杂度,并且可以在针对用户和关联的空间流的组合的循环之外计算近似调度度量。实际上,根据上述方法,不需要为所有组合计算局部调度度量,这涉及比近似度量计算更高的计算复杂度。在最佳的情况下,仅需要计算第一组合的一个局部调度度量。
在实施方式中,该方法还可以包括:根据最佳组合更新用户的平均速率。根据另一实施方式,针对蜂窝系统的n个资源中的各个资源n重复方法的步骤。
因此,可以针对蜂窝系统的n个资源中的n个资源执行循环,以使可以根据上述方法执行资源分配。
在实施方式中,干扰至少归因于使用具有相同的空间方向的各自空间流的若干用户。
在实施方式中,局部调度度量的计算的步骤包括预编码的计算。
在实施方式中,根据预编码计算实际用户容量。
在实施方式中,在计算近似调度度量的步骤之前执行简化调度度量的计算,简化调度度量取决于小区中的用户近似容量和用户平均速率。
在实施方式中,基于以下公式确定简化调度度量:
其中:
msimpl是简化调度度量;
k是用户索引;
n是资源索引;
r(k)是小区中用户k的平均速率;
α是公平性标准。
在实施方式中,基于以下公式确定近似调度度量:
其中:
mapprox是近似调度度量;
n是资源索引;
t是空间流的数量;
kt(n)是在资源n的t个空间蒸气中的第t个空间蒸气上发送的用户索引;
r(kt(n))是小区中在针对资源n的第t个空间蒸气上发送的第kt(n)个用户的平均速率;
α是公平性标准。
调度度量的近似值是容量值的上限。这提供了降低计算复杂度的优点。
在实施方式中,基于以下公式确定局部调度度量:
其中:
mlocal是局部调度度量;
n是资源索引;
t是空间流的数量;
kt(n)是在资源n的t个空间蒸气中的第t个空间蒸气上发送的用户索引;
r(n,kt(n))是在针对资源n的第t个空间蒸气上发送的第kt(n)个用户的实际容量;
r(kt(n))是小区中在针对资源n的第t个空间蒸气上发送的第kt(n)个用户的平均速率;
α是公平性标准。
因此,结合公平效应和无干扰度量两者使用户更加满意地去放弃,并且在假设用户没有受到高度干扰的情况下优先考虑需要更多分配的这些用户。
在实施方式中,蜂窝系统是5g系统。
本发明的另一方面涉及一种计算机程序产品,计算机程序产品包括指令,当处理器运行该指令时执行如前述权利要求的方法。
第三方面涉及一种蜂窝系统中的调度装置,该蜂窝系统包括多个天线装置,多个天线装置发送多个空间流,其中,多个空间流服务于具有各自容量的多个用户,该调度装置包括电路,该电路被布置以:
-针对以下各项的各个可能组合计算近似调度度量:
○多个用户中的用户,以及
○多个空间流中的相关联的空间流,
近似调度度量是在不考虑干扰的情况下的用户容量的函数;
-按降序对近似调度度量进行排序以便获得可能组合的分类;
-为分类中的第一组合计算局部调度度量,该局部调度度量是在考虑干扰的情况下的实际用户容量的函数;
-针对分类中的各个后续组合:
○将后续组合的近似度量与先前计算出的局部调度度量进行比较,并且
○如果后续组合的近似度量高于先前计算出的局部调度度量,则计算后续组合的局部调度度量,如果计算出的局部调度度量高于先前计算出的局部调度度量,则用计算出的局部调度度量替换先前计算出的局部调度度量,
○如果后续组合的近似度量低于或等于先前计算出的局部调度度量,则将提供先前计算出的局部调度度量的组合规定为用户与相关联的空间流的最佳组合。
在实施方式中,电路还被布置以:
-根据最佳组合更新用户的平均速率。
本发明在附图中通过示例而非限制的方式进行了例示,在附图中类似的标号指代相似的元件。
附图说明
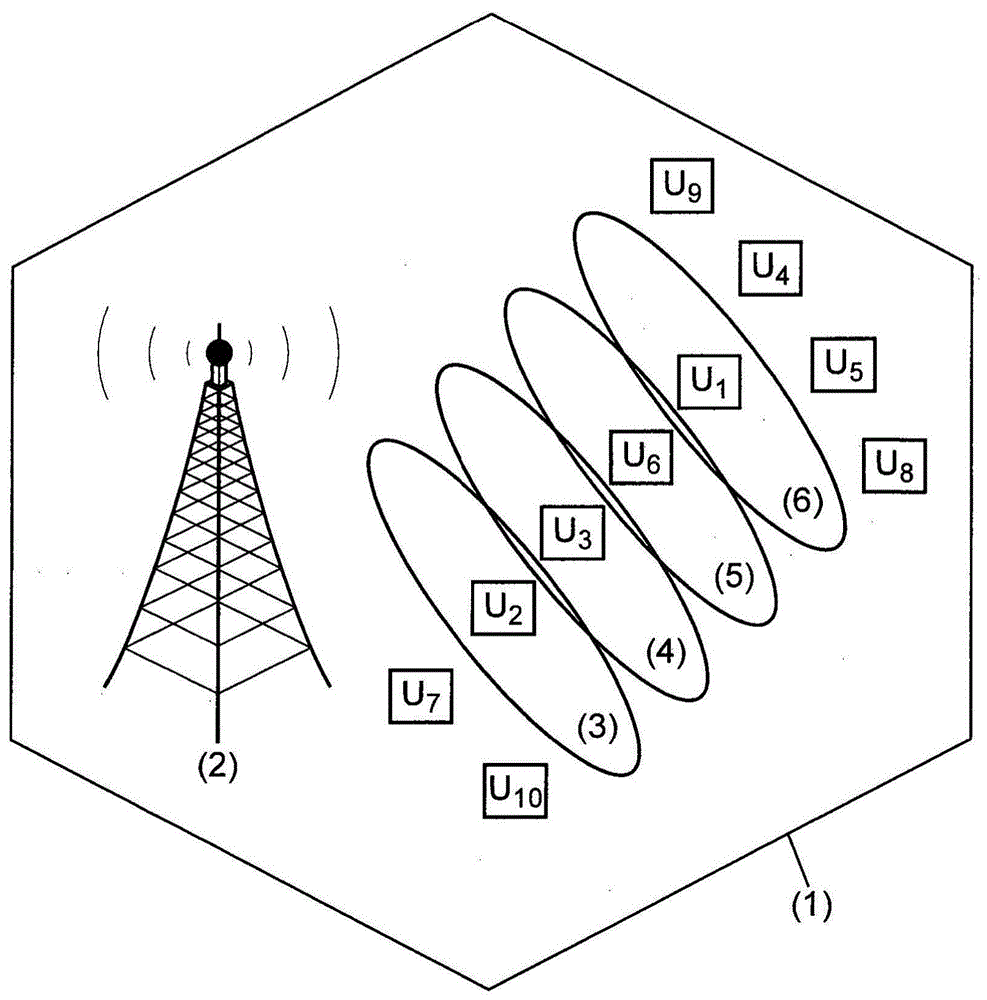
-图1是可以应用本方法的经典mu-mimo系统的示例。
-图2是例示强制实施调度和用户设备配对的不同步骤的流程图。
-图3是描述本发明的可能实施方式中的不同步骤的流程图。
-图4表示该方法的性能,其中平均小区容量是利用jain的公平性绘制的。
-图5是使得能够实现本发明的装置的可能实施方式。
具体实施方式
本发明提出以低复杂度来解决蜂窝网络的下行链路的联合用户配对、预编码以及调度。此外,基于中央处理单元(cpu)和图形处理单元(gpu)的硬件架构是本发明的目标。这些硬件架构允许考虑更为动态的方法,该方法具有可变的执行时间而优化的结果必须定期给出。预编码是关于性能达成的重要要素。然而,预编码要求大量的计算复杂度。关于用户配对则需要许多使用计算机进行的计算。
图1是可以应用本方法的经典mu-mimo系统的示例。预编码的维度基数是必须考虑的。图1表示具有基站2以及四个空间流3、4、5和6的小区1。小区1包括十个用户:u1、u2、(…)以及u10。具有500个物理资源块(prb)的100兆赫兹宽正交频分复用(ofdm)系统需要来自10个用户的各4元组用户的500次决策以在prb上进行发送。为了作出调度决策,必需获知每个用户的容量。获知每个用户的容量暗示了预编码的计算以及与该预编码相关联的性能。在线性情况下,这种粗暴(brute)的方法需要计算:
关于非线性预编码,也就是说,在没有对用户进行智能排序的情况下,大小为4×4的预编码的数量会多达10^4。两个数量的预编码关系到导出一个prb的分配,这涉及每帧(即,1ms)计算105000个预编码或100万个预编码。实际上,prb表示调度程序可以分配给用户设备(ue)的最小频率资源单元。
考虑处理k个用户并配备有t个空间流的蜂窝网络的基带单元(bbu)。各个空间流可以连接至更大的物理天线集。例如,更大的天线集可以是大规模天线阵列以及许多物理天线与一个功率放大器的模拟组合,从而将空间流的数量减少至t。因此,信号的数值设计考虑到了具有t个输入的mimo信道。
为了提供更好的理解,考虑各个ue配备有相同数量的r个接收天线。这种考虑只是为了简单起见,它不会缩小本发明的范围,实际上,本发明可以应用于跨ue的不均匀数量的接收天线。各个传输帧被认为是包括可以视作彼此独立的n个资源。
图2是例示强制实施调度和用户设备配对的不同步骤的流程图。
在步骤201中,在第n个资源上观察到bbu与第k个ue之间的r×tmimo信道矩阵h(n,k)。矩阵h(n,k)的系数由信噪比进行加权,从而导致下面以具有归一化功率1来考虑噪声。bbu借助于信道状态信息(csi)反馈机制接收必要的信息。kt(n)定义了在n个资源中的第n个资源的t个空间流中的第t个空间流上发送的处于[1k]的用户索引。
t元组{k1(n),…,kt(n)}表示考虑在第n个资源上的下行链路传输的t个ue的集合。
等效的mimo信道不一定是正交的。各个用户意在仅接收该用户的消息。结果,用户之间可能发生干扰。可以设计mimo预编码技术以便优化每个用户接收的传输速率r(n,kt(n))。可以利用若干线性预编码技术或非线性预编码技术。每种预编码技术都有其优点和缺点。此外,每种预编码技术具有针对每个ue的最终sinr或容量进行优化的方式。
速率集{r(n,k1(n)),…,r(n,kt(n))}是预编码设计的函数。该速率集{r(n,k1(n)),…,r(n,kt(n))}取决于t元组{k1(n),…,kt(n)}。考虑将基于shannon容量的度量用于评估预编码的性能。结果,h(n,k)p(n)是用户k在资源n上观察到的预编码的mimo信道,p(n)表示t×t预编码矩阵。在矩阵p的第一行上发送专用于第一用户的符号,依此类推。ofdm符号表示时域中的信号,其对应于在系统频带的各个子载波上发送的调制符号块。可以将若干符号发送给同一用户设备,这涉及到在t元组{k1(n),…,kt(n)}中可以若干次找到该第k个用户设备的索引。
在步骤202中,对于给定的预编码,基于以下方程计算第k个ue的速率:
其中:
ek是大小为t的选择矢量,该选择矢量除位置k为1之外其它项为空值;
w(n,k)从第k个用户的角度来看是噪声加干扰的协方差矩阵;
其中,基于以下方程确定w(n,k):
考虑具有机会实现策略的调度程序。该调度程序实现了用户之间的α公平性。小区中用户k的平均速率由r(k)表示。调度程序意在使α公平和速率(alpha-fairsumrate)最大化:
其中:
为此,调度程序执行分配决策。该策略是:获取每个资源n,并且根据预编码策略和信道实现来分配用户,从而最大化根据针对该用户获得的在t个流中的第t个流上发送的各个用户k的平均速率以及瞬时速率r(n,kt(n))的局部知识r(k)计算出的度量。优化
因此,在步骤203中,计算局部调度度量mlocal(n),其中,基于以下方程进行计算局部度量mlocal(n):
对于在集合{k1(n),...,kt(n)}中未选择的用户k,给定速率r(n,k)=0。将各个用户k的速率更新为r(k)←r(k)+r(n,k)或者取平均速率r(k)←r(k)+(r(n,k)-r(k))/n,或者r(k)←r(k)+μ(r(n,k)-r(k)),其中,μ是预定的遗忘因子。
使用粗暴实施方法进行联合调度和ue配对,通过使用机会调度程序来最大化
-计算预编码(步骤201)
-计算速率{r(n,k1(n)),...,r(n,kt(n))}(步骤202)
-计算局部调度度量mlocal(n)(步骤203)
对于各个资源,在步骤204中选择最大化mlocal(n)的最佳t元组{k1(n),...,kt(n)},并且根据{r(n,k1(n)),...,r(n,kt(n))}更新速率r(k),并移至下一资源。
图3是描述本发明的可能实施方式中的不同步骤的流程图。
降低复杂度的第一种方法是对涉及计算各个t元组{k1(n),...,kt(n)}的预编码p(n)的步骤201进行简化。可以放弃预编码计算步骤201。速率{r(n,k1(n)),...,r(n,kt(n))}计算步骤202可以用具有更简单计算的近似速率
其中,在r(n,kt(n))中忽略了与其它用户的干扰相关的项。
近似速率计算步骤310允许基于以下方程计算步骤311中的近似调度度量mapprox计算:
在步骤310中,计算所有用户k的近似速率,其中,1≤k≤k。然后,针对所有用户计算并存储
在步骤314中,开始对采取排序后顺序的这些t元组{k1(n),...,kt(n)}进行循环。如果该排序后顺序中的第一个t元组的近似度量mapprox小于或等于mbest,则这些t元组的循环结束。如果该排序后顺序中的第一个t元组的近似度量mapprox大于mbest,则这些t元组的循环继续。可以将该排序后顺序中的第一个t元组指定为besttuple(i)={k1(n),...,kt(n)},其中,i是递增索引。因此,当递增i(i=i+1)时,besttuple(i)按该排序后顺序来指定后续t元组。
在步骤315中执行预编码计算,并且在步骤316中根据预编码来计算速率{r(n,k1(n)),...,r(n,kt(n))}。然后,在步骤317中针对besttuple(i)计算局部调度度量mlocal。在步骤318中,将mbest与先前步骤中针对besttuple(i)计算出的局部调度度量mlocal进行比较。如果在步骤317中针对besttuple(i)计算出的局部调度度量mlocal高于mbest,则mbest由mlocal进行更新,并且将besttuple(i)存储为最佳t元组。在步骤318或步骤319之后,将递增所述递增索引并且继续进行t元组的循环,直到在步骤314中mbest高于besttuple(i)的当前近似度量,或者直到所有可能的t元组{k1(n),...,kt(n)}的集合当中不再有要测试的t元组。一旦满足步骤314的条件,就在步骤320中标识最佳t元组。根据所标识的最佳t元组
对于n个资源中的每个资源n重复从步骤310到步骤320的上述步骤,这构成n的循环。
为了进一步澄清,考虑数值示例。考虑四个用户和两个空间流。下表中列出了t元组(mlocal和mapprox)的详尽列表。
与用户{1,2,3,4}相关联的近似速率分别为{10,20,30,40}。所有用户都以平均速率r(k)=1开始。
在介绍中描述的现有技术方法中,首先,选择具有最高速率的用户,即,用户4具有速率40。然后,根据预编码策略测试涉及4的对({1,4}、{2,4}以及{3,4}),并选择最佳对,即{3,4}。有若干测试未被执行。因此,减少了复杂度,但所述解并非最优,因为尚未找到最佳解{2,3}。
根据步骤310,首先以低复杂度独立地计算用户{1,2,3,4}的近似速率({10,20,30,40})。然后,在表格的最后一列中,分别根据步骤311和步骤312计算并排序所有t元组的mapprox({3,4},{2,4},{2,3},{1,4},{1,3},{1,2})。
根据步骤313将mbest设定成0。t元组{3,4}的mapprox是70。由于该70大于0(步骤314),因此在步骤315中计算预编码,并且在步骤317中获得mlocal16。由于16高于0,因此在步骤319中将16存储为mbest。继续进行对多个t元组的循环。
t元组{2,4}是排序后顺序中的后续t元组,并且mapprox为60,其大于16。计算预编码并获得度量14,其小于16并且不被存储为mbest。
t元组{2,3}的mapprox为50,其大于16。计算预编码,并获得度量48并且将48存储为mbest。
t元组{1,4}的mapprox为50,其大于48。计算预编码并获得度量10,其小于48并且不被存储为mbest。
t元组{1,3}的mapprox为40,其小于48。因此,根据步骤314,停止进行对t元组的循环并且可以执行调度步骤320。可以注意到,已经保存了两个预编码计算,并且找到了最佳解{2,3}。
图4表示该方法的性能,其中针对每小区10个用户和四个流的lte部署,以jain的公平性对平均小区速率进行了绘制。考虑了块对角预编码。与现有技术相比,所提出的方法性能更好,该方法优于单用户mimoα公平调度。未达到脏纸编码(dirtypapercoding)的理论上限,但是可以通过用非线性预编码替换线性bd预编码来接近该理论上限,例如使用tomlinsonharashima预编码来接近所述理论上限。
图5是使得能够实现本发明的装置的可能实施方式。
在此实施方式中,装置500包括计算机,该计算机包括存储器505以存储程序指令,所述程序指令可加载到电路中并且适于在通过电路504运行该程序指令时使所述电路504执行本发明的步骤。
存储器505还可以存储用于执行如上所述的本发明的步骤的数据和有用信息。
例如,电路504可以是:
-处理器或处理单元,该处理器或处理单元被调适为解释采用计算机语言的指令,该处理器或处理单元可以包括包含所述指令的存储器、可以与包含所述指令的存储器相关联或者可以连接至包含所述指令的存储器,或者
-处理器/处理单元与存储器的关联件,该处理器或处理单元被调适为解释采用计算机语言的指令,该存储器包含所述指令,或者
-电子卡,其中,在硅片内记载了本发明的步骤,或者
-可编程电子芯片,例如fpga芯片(用于“现场可编程门阵列”)。
该计算机包括用于接收用于根据本发明的上述方法的测量值的输入接口503以及输出接口506。
为了简化与该计算机的交互,可以设置屏幕501和键盘502并将该屏幕和键盘连接至计算机电路504。
装置500可以是基站200的一部分。
可以将本方法用于许多应用。例如,在计算机或gpu的情况下,以及将在软件定义网络和云ran的情况下,可以将该方法实现于在不同进程之间共享功率的计算架构上。该方法的计算时间的可变性是有意义的。实际上,根据信道实现,停止条件将早于或晚于平均值出现。当使用诸如现场可编程门阵列之类的固定架构时,必须针对最坏情况确定硬件的尺寸或者评估性能损失。
在实现所述方法时,可以通过前几个prb分配来取得n个prb的计算预算,这可能导致针对大多数prb的空决策并降低频谱效率。因此,有意义的是保证对每个prb作出至少一个决策,并次要优先的是保证该决策尽可能最佳。为了实现该目标,可以通过首先对所有prb执行近似计算和对近似度量的排序来修改该方法的操作调度。然后,可以在排序后的列表中执行对所述t元组的索引的循环。此后,可以执行对物理资源块的循环。如果该方法尚未停止,则检查与所考虑的物理资源块的索引相关联的t元组的性能。
当然,本发明不限于作为示例的上述实施方式。本发明能扩展至其它变型。例如,可以使用正交度量来代替用于预先排序的累积距离。本发明能扩展至用来代替单个流传输的mimo传输。可以使用各种类型的预编码,例如:特征波束形成、具有特征波束形成的块对角预编码、非线性预编码thp以及具有块三角测量的非线性预编码。
- 还没有人留言评论。精彩留言会获得点赞!