声音播放系统及其调整输出声音的方法与流程
本发明关于一种声音播放系统及其调整输出声音的方法,特别是一种可根据使用者年龄进行调整的声音播放系统及其调整输出声音的方法。
背景技术:
随着科技的进步,已经发展出很多语音助理程序,例如苹果公司的siri、google公司的googlenow、微软公司的cortana或是亚马逊公司的alexa等。使用者可以利用手机或平板等装置与语音助理程序直接进行语音对话。另一方面,由于不同年龄的使用者对于不同频率的听力损失程度及对声音大小的耐受度不同,所以不同年龄的使用者都会有最佳听力的个人听力曲线。尤其是人类随着年龄逐渐的增长,耳朵所能听到声音的音频范围会越来越小,对于频率较高的声音,听力弱化的情形更是特别明显。但现今的语音助理程序并未考虑到使用者的年龄来调整输出声音的个人听力曲线。
因此,有必要发明一种新的声音播放系统及其调整输出声音的方法,以解决先前技术的缺失。
技术实现要素:
本发明的主要目的在于提供一种声音播放系统,其可根据使用者年龄进行调整。
本发明的另一主要目的在于提供一种用于上述声音播放系统的调整输出声音的方法。
为达成上述的目的,本发明声音播放系统包括近端电子装置及远程语音系统。近端电子装置包括声音接收模块、传输模块及发声模块。声音接收模块用以接收自使用者发出的输入声音信号,输入声音信号内包括表示使用者的年龄的语音信号。传输模块电性连接声音接收模块,用以传送输入声音信号至网络。发声模块电性连接传输模块,用以发出输出声音信号给使用者。远程语音系统经由网络连接至近端电子装置,并可发出输出声音信号,远程语音系统包括辨识模块、均衡器及处理模块。辨识模块接收输入声音信号,用以根据输入声音信号的语音信号进行语音识别,以得到语音识别结果。均衡器用以调整输出声音信号的各频段的增益值。处理模块电性连接辨识模块及均衡器,用以根据语音识别结果控制均衡器调整输出声音信号的各频段的增益值,借以传输输出声音信号到近端电子装置,以自发声模块发出输出声音信号给使用者。
本发明调整输出声音的方法,包括以下步骤:接收自使用者发出的输入声音信号,输入声音信号内包括使用者表示年龄的语音信号;传输输入声音信号到远程语音系统;根据输入声音信号的语音信号进行语音识别,以得到语音识别结果;根据语音识别结果对输出声音信号的各频段的增益值进行调整;以及传输输出声音信号到近端电子装置以发出输出声音信号给使用者。
附图说明
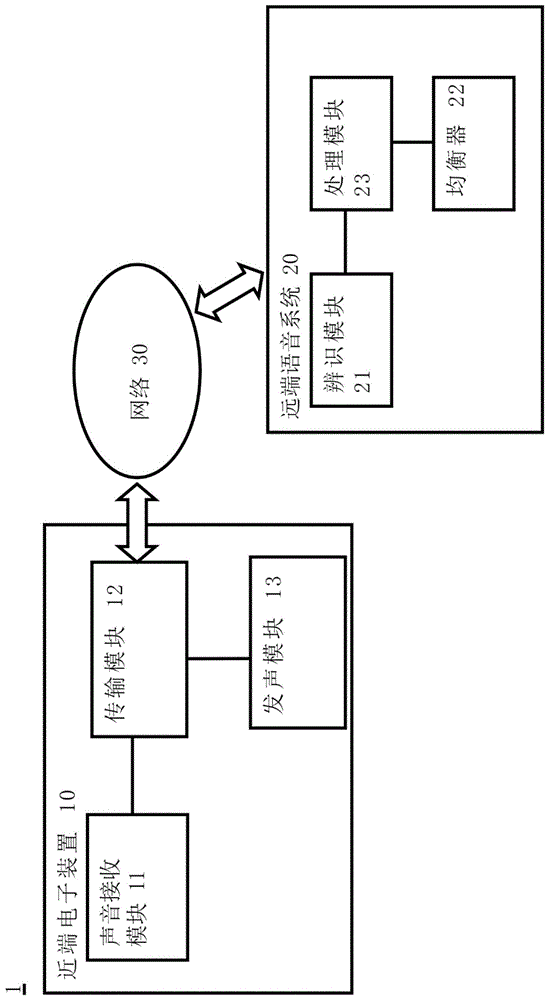
图1为本发明的第一实施例的声音播放系统的架构示意图。
图2为本发明的第一实施例的调整输出声音的方法的步骤流程图。
图3为本发明的第二实施例的声音播放系统的架构示意图。
图4为本发明的第二实施例的调整输出声音的方法的步骤流程图。
其中附图标记为:
声音播放系统1、1’
近端电子装置10、10’
声音接收模块11
传输模块12
发声模块13
撷取模块14
远程语音系统20、20’
辨识模块21
均衡器22
处理模块23
声纹分析模块24
影像分析模块25
网络n
具体实施方式
为能让贵审查委员能更了解本发明的技术内容,特举较佳具体实施例说明如下。
以下请参考图1为本发明的第一实施例的声音播放系统的架构示意图。
本发明的声音播放系统1包括近端电子装置10及远程语音系统20。近端电子装置10可以为智能型手机、平板计算机或笔记本电脑等,但本发明并不限于此。近端电子装置10用以供一使用者使用,并经由网络30连接一远程语音系统20。远程语音系统20可用于任意的人工智能语音系统,例如苹果公司的siri、google公司的googlenow、微软公司的cortana或是亚马逊公司的alexa,但本发明并不限于此。
近端电子装置10包括声音接收模块11、传输模块12及发声模块13。声音接收模块11可为一麦克风,用以接收自一使用者发出的一输入声音信号。该输入声音信号内包括表示该使用者的年龄的一语音信号,例如使用者可以说出「alexa,iam60yearsold.pleasesetupmyeq.」。传输模块12电性连接该声音接收模块11,用以传送该输入声音信号至一网络n。传输模块12可以利用有线或无线方式连接网络n,本发明并不限定其联机方式。发声模块13电性连接该传输模块12。发声模块13可以为喇叭或耳机,用以发出一输出声音信号给该使用者,输出声音自远程语音系统20得到。
该远程语音系统20包括辨识模块21、均衡器22及处理模块23。辨识模块21接收该输入声音信号,用以根据该输入声音信号的该语音信号进行一语音识别,以得到一语音识别结果。均衡器(equalizer,eq)22用以调整该输出声音信号的各频段的一增益值,均衡器22为一种可调配声音输出的工具,可改变声音于不同频段下的增益值,因而常被用于输出音效的调整上。处理模块23电性连接该辨识模块21及该均衡器22,用以根据该语音识别结果控制该均衡器22调整该输出声音信号的该各频段的一增益值。最后传输该输出声音信号到该近端电子装置10,以自该发声模块13发出该输出声音信号给该使用者。在此处的输出声音信号指远程语音系统20在处理模块23之后所产生并要会传到发声模块13的声音。如此一来,处理模块23即可根据使用者本身的状况调整出处理模块23较适合的声音信号。例如对于年长的使用者,处理模块23可控制该均衡器22将输出声音信号的高频频段增加音量,让年长的使用者较容易听见。
接着请参考图2为本发明的第一实施例的调整输出声音的方法的步骤流程图。此处需注意的是,以下虽以上述声音播放系统1为例说明本发明的调整输出声音的方法,但本发明的调整输出声音的方法并不以使用在上述相同结构的声音播放系统1为限。
首先进行步骤s201:接收自该使用者发出的一输入声音信号。
首先声音接收模块11用以接收自一使用者发出的一输入声音信号,该输入声音信号内包括表示该使用者的年龄的一语音信号。
其次进行步骤s202:传输该输入声音信号到该远程语音系统20。
其次传输模块12传送该输入声音信号至一网络n,再由远程语音系统20接收。
远程语音系统20再进行步骤s203:接收该输入声音信号。
再接着远程语音系统20接收输入声音信号。
接着进行步骤s204:根据该输入声音信号的该语音信号进行一语音识别,以得到一语音识别结果。
接着辨识模块21接收该输入声音信号,用以根据该输入声音信号的该语音信号进行一语音识别,以得到一语音识别结果。例如当使用者说「alexa,iam60yearsold.」,辨识模块21的语音识别结果即为60岁。
再进行步骤s205:根据该语音识别结果对该输出声音信号的各频段的一增益值进行调整。
处理模块23用以根据该语音识别结果控制该均衡器22调整该输出声音信号的该各频段的一增益值。例如对于年长的使用者控制该均衡器22将输出声音信号的高频频段增加音量。借此远程语音系统20产生的输出声音信号都会经过均衡器22的调整。
接着进行步骤s206:传输该输出声音信号到该近端电子装置10。
接着当均衡器22调整后,远程语音系统20输出声音信号到该近端电子装置10。
最后进行步骤s207:发出该输出声音信号给该使用者。
最后发声模块13发出调整后的输出声音信号给该使用者。如此一来,处理模块23即可根据使用者本身的状况调整出处理模块23较适合的声音信号。
接着请参考图3为本发明的第二实施例的声音播放系统的架构示意图。
于本发明的第二实施例中,声音播放系统1’的该近端电子装置10’更包括一撷取模块14,用以撷取该使用者的一脸部影像。该远程语音系统20’更包括一声纹分析模块24及影像分析模块25。声纹分析模块24用以根据该输入声音信号进行一声纹分析,以得到一年龄分析结果。影像分析模块25用以根据该脸部影像进行一影像分析,以得到一脸部影像分析结果。远程语音系统20’也可以仅具有声纹分析模块24或影像分析模块25,近端电子装置10’也可能不具有撷取模块14,即远程语音系统20可能只能进行声纹分析或影像分析两者其中之一,但本发明并不限于此。
借此,该处理模块23同时根据该脸部影像分析结果、该语音识别结果及该年龄分析结果控制该均衡器22调整该输出声音信号的各频段的该增益值。当该脸部影像分析结果、该语音识别结果及该年龄分析结果的结果不一致时,处理模块23可以只根据其中一个数据进行调整。于本发明之一实施方式中,处理模块23的判断可以用脸部影像分析结果或该年龄分析结果为优先,当脸部影像分析结果或该年龄分析结果与语音识别结果不符时,不考虑语音识别结果的数据。例如若辨识模块21的语音识别结果为60岁,但声纹分析模块24的年龄分析结果为50岁时,处理模块23依照年龄分析结果控制该均衡器22进行调整。或者由影像分析模块25的影像分析得到使用者的年龄应为40岁时,处理模块23也可依照影像分析结果控制该均衡器22进行调整。再者,但本发明并不限只根据其中一个数据进行调整,也可以取不同数据中的最大值、最小值或平均值。
需注意的是,上述各个模块除可配置为硬件装置、软件程序、固体或其组合外,亦可借电路回路或其他适当型式配置;并且,各个模块除可以单独的型式配置外,亦可以结合的型式配置。此外,本实施方式仅例示本发明的较佳实施例,为避免赘述,并未详加记载所有可能的变化组合。然而,本领域之通常知识者应可理解,上述各模块或元件未必皆为必要。且为实施本发明,亦可能包含其他较细节的现有模块或元件。各模块或元件皆可能视需求加以省略或修改,且任两模块间未必不存在其他模块或元件。
接着请参考图4为本发明的第二实施例的调整输出声音的方法的步骤流程图。
首先进行步骤s401:接收自该使用者发出的一输入声音信号,并同时进行步骤s402:撷取该使用者的一脸部影像。
除了声音接收模块11用以接收自使用者发出的输入声音信号外,也利用撷取模块14撷取该使用者的一脸部影像。
再进行步骤s403:传输该输入声音信号及该脸部影像到该远程语音系统20’。
接着传输模块12传送该输入声音信号及脸部影像至一网络n,再由远程语音系统20’步骤s404:接收该输入声音信号及该脸部影像。
接着进行步骤s405:根据该输入声音信号的该语音信号进行一语音识别,以得到一语音识别结果。
此步骤s405与步骤s204相同,皆利用辨识模块21根据该输入声音信号的该语音信号进行语音识别,以得到语音识别结果。
同时进行步骤s406:根据该输入声音信号进行一声纹分析,以得到一年龄分析结果。
声纹分析模块24也根据相同的输入声音信号进行一声纹分析,以得到一年龄分析结果。
再进行步骤s407:根据该脸部影像进行一影像分析,以得到一脸部影像分析结果。
影像分析模块25用以根据该脸部影像进行一影像分析,以得到一脸部影像分析结果。
接着进行步骤s408:同时根据该脸部影像分析结果、该语音识别结果及该年龄分析结果对该输出声音信号的各频段的该增益值进行调整。
处理模块23同时根据该脸部影像分析结果、该语音识别结果及该年龄分析结果控制该均衡器22调整该输出声音信号的各频段的该增益值,以进行步骤s409:传输该输出声音信号到该近端电子装置10’。当脸部影像分析结果或该年龄分析结果与语音识别结果不符时,以脸部影像分析结果或该年龄分析结果为准,先不考虑语音识别结果的数据。
需注意的是,于不同实施方式中,本发明也可只进行步骤s406来进行声纹分析或是只进行s407来进行影像分析,本发明并不限定一定要同时根据该脸部影像分析结果、该语音识别结果及该年龄分析结果进行调整。
最后进行步骤s410:发出该输出声音信号给该使用者。
最后发声模块13发出调整后的输出声音信号给该使用者。
此处需注意的是,本发明的调整输出声音的方法并不以上述的步骤次序为限,只要能达成本发明的目的,上述的步骤次序亦可加以改变。
由上述的说明可知,本发明的声音播放系统1或1’可依照使用者的年龄去做调整,以得到最适合该使用者的输出声音信号。
需注意的是,上述仅为实施例,而非限制于实施例。譬如此不脱离本发明基本架构者,皆应为本专利所主张的权利范围,而应以专利申请范围为准。
- 还没有人留言评论。精彩留言会获得点赞!