基于强化学习的多径TCP传输调度方法与流程
本发明涉及一种基于强化学习的多径tcp传输调度方法。
背景技术:
随着网络的不断发展,人们对网络传输的要求和期望越来越高,因此近年来涌现了一批新的协议用于网络的多径传输,以提高网络传输的效能。多径tcp协议就是一种基于tcp协议的多径网络传输协议,它的目的是能在保证tcp传输的有序性情况下,利用多径传输加快tcp传输的速率。多径tcp协议会为一个tcp传输请求产生多条子tcp连接用于传输tcp数据流,然而要使得数据包能够通过所有子tcp连接进行传输并能够保证在接收终端不产生大量数据包乱序,则要对多径tcp传输时的数据包调度进行控制。主要是考虑到各条子链路的传输条件,合理分配tcp数据包进行传输,保证在不同链路上传输的数据包在接收终端按序到达。
现有较为常用的fps、f2p-dps、ocps三种多径tcp调度算法,其中ocps是对前两种算法种存在对不足进行改进。fps,提出根据每一轮数据的往返的rtt和排队时延情况,预测数据包到达的序号情况,从而来调度tcp子流的发送队列。f2p-dps则在fps的基础上增加考虑了链路的丢包情况,使得该调度策略更适合于无线传输网络。ocps认为fps和f2p-dps都只是单纯的预测算法,在实际中链路传输还存在许多不确定因素会导致链路传输质量的变动,为了防止多轮调度后的误差累计,提出使用子流级别的tcp选择性应答(selectiveacknowledgement,sack)判断当前接收端乱序情况。发送端可以根据tcpsack来判断,上一轮调度预留给其他子流数据包是过多还是过少,再通过类似tcp慢启动的方式产生一个修正因子,对下一轮调度进行修正。ocps在fps和f2p-dps的基础上,进一步增加了调度预测的准确和可靠性。然而,ocps采用了类似tcp慢启动的方式产生修正因子,这样就导致要经过若干轮之后修正因子才可能达到比较合理的值,而这需要消耗一定时间,才能够使得多径tcp传输的吞吐率和乱序度达到一个稳定的、相对较优的值。因此我们在ocps的基础上提出了一种基于强化学习的多径tcp调度方法,能够在相对较短时间内能够使得多径tcp的吞吐率和乱序度达到一个稳定的、相对较优的值。
技术实现要素:
本发明的目的在于提供一种基于强化学习的多径tcp传输调度方法,该方法能够更加准确的预测传输调度中需要预留的数据包数目n,并且时间开销相对更小,多径tcp传输的数据包乱序度更低。
为实现上述目的,本发明的技术方案是:一种基于强化学习的多径tcp传输调度方法,包括构建强化学习模型阶段、训练强化学习模型阶段、部署强化学习模型阶段;构建强化学习模型阶段,需要根据强化学习基础模型和多径tcp传输调度环境的需求确定四要素:智能体、环境状态、行动、奖励;训练强化学习模型阶段,将强化学习模型部署至多径tcp运行环境中,具体即将强化学习模型部署在通信的发送端主机的多径tcp层上,使用强化学习训练算法对强化学习模型进行训练;部署强化学习模型阶段,按照训练强化学习模型阶段的部署的方案进行部署;该方法具体包括如下步骤:
步骤s1、确定在多径tcp传输调度环境下强化学习模型的目标;
步骤s2、确定强化学习模型中智能体的组成部分;
步骤s3、确定强化学习模型中的环境状态、行动、奖励,以及相关计算反馈公式;
步骤s4、将强化学习模型部署至通信的发送端主机的多径tcp层上,使用强化学习训练算法进行训练;
步骤s5、根据实际拓扑,将训练完成的强化学习模型部署至多径tcp的发送终端实际运行。
在本发明一实施例中,多径tcp传输由多条多径tcp子流组成,在传输调度中传输调度策略需要根据传输情况识别需要预留的数据包传输量n,因此,强化学习模型的目标就是使得n值尽量合理,合理性的评价标准为多径tcp传输的吞吐量和包乱序度。
在本发明一实施例中,步骤s2中,所述强化学习模型中智能体的组成部分,包括:1)状态感知器i,用于从环境w收集当前环境状态信息s;其中,环境w,即多径tcp传输终端;s由sack包和rtt时延信息构成,因此,即环境状态信息s可由(sack,rtt)的二维数组表示,为了便于矩阵表示,把sack包返回的目标tcp子流和连续sack包数量作为组合量化,由编号1开始,具体编号数量q由组合的类别数决定,rtt以1ms的精度表示,并向下取整,rtt编号数量p由rtt的类别数决定;2)学习器l,其为三维矩阵m,x维、y维分别表示sack和rtt组成状态分量,z维表示可能的行动被选中概率,即可能的n值被选中的概率,z维度行动的数值即为n值,n为大于0的正整数,其数量k由训练网络中实际适用的n值类别数决定,因此矩阵m是一个q*p*k的矩阵;3)动作选择器p,其根据当前环境状态信息s,查询矩阵m,选择出对应的行动。
在本发明一实施例中,所述sack包是当接收终端发生乱序接收时,返回给发送终端的响应包,通过观察sack包返回的目标tcp子流和连续返回的sack包数量可以判断传输乱序情况和预留数据包传输量n值是偏大还是偏小;rtt反映了各tcp子流的链路质量情况。
在本发明一实施例中,所述步骤s3的具体实现方式如下:
对于环境w,每当接受一个行动,就会产生一个新的环境状态信息s',并返回一个奖励r,r决定了如何对智能体的学习器l中的三维矩阵m中的行动概率进行调整,即对n值被选中概率进行调整,使得n值的选择在每一种状态下逐渐趋向合理;r的奖励函数由公式(1)定义:
式中,mb代表在当前环境状态信息下以往最佳的数据包乱序度,mp代表当前行动ap所产生的数据包乱序度,以10%作为调整比例;因此,当mp大于mb时,奖励r是负数,相当于惩罚机制;当mp小于mb,奖励r是正数,相当于奖励机制;
r作用于学习器l的方式由公式(2)表示:
式中,v[x,y,z]表示一状态下对应的一动作的选中概率值,sackp,rttp,ap表示当前的状态和行动,aother表示除当前行动外的行动,一共有n个;当学习器l得到r值,首先学习器l会对当前的动作的选中概率作出程度为r的调整,然后对其余状态都作出程度为
在本发明一实施例中,步骤s4中,强化学习模型的部署,是在ns-3网络实验平台上对强化学习模型进行部署,包括多径tcp协议代码,将强化学习模型部署在发送终端主机的多径tcp协议层进行训练,强化学习训练算法则根据公式(1)、公式(2)进行设定;训练的收敛原则为强化学习模型为多径tcp传输做出的调度使得多径tcp传输的吞吐率和包乱序度稳定在根据需求而预先设定的数值。
相较于现有技术,本发明具有以下有益效果:本发明方法是对传统多径tcp调度方法进行改进,相较传统算法,本发明能够更加准确的预测多径tcp传输调度中需要预留的数据包数量,并且能够在较短的时间内完成合理的调度。
附图说明
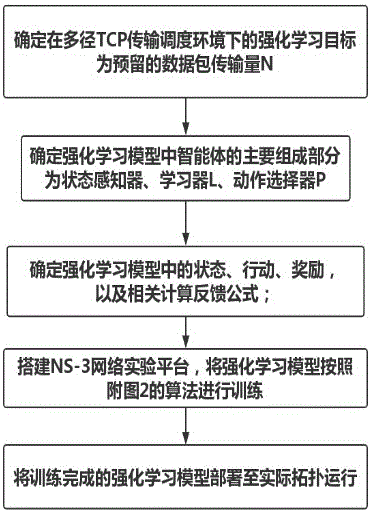
图1为本发明图1基于强化学习的多径tcp传输调度方法流程图。
图2为强化学习模型训练算法具体实现代码。
具体实施方式
下面结合附图,对本发明的技术方案进行具体说明。
如图1所示,本发明提供了一种基于强化学习的多径tcp传输调度方法,该方法由构建强化学习模型、训练强化学习模型、部署强化学习模型组成;在构建强化学习模型部分,需要根据强化学习基础模型和多径tcp场景的需求确定四要素:智能体(agent)、环境状态(environmentalstate)、行动(action)、奖励(reward);训练强化学习模型部分,需要将模型部署至多径tcp运行环境中,具体是将模型部署在通信的发送端主机的多径tcp层上,使用强化学习训练算法对模型进行训练;部署强化学习模型部分,按照训练模型时的部署的方案进行部署。具体包括如下步骤:
1、确定在多径tcp传输调度的环境下强化学习的目标:多径tcp传输由多条多径tcp子流组成,在传输调度中为了同时保证数据包的有序性和高效利用多径传输资源,传输调度策略需要根据传输情况识别需要预留的数据包传输量n,根据这一现象,多径tcp强化学习模型的目标就是使得n值尽量合理,合理性的评价标准为多径tcp传输的吞吐量和包乱序度。
2、确定强化学习模型中智能体的主要组成部分:在多径tcp强化学习模型中的智能体包括三个组成部分,1)状态感知器i,它会从环境w(即多径tcp传输终端)收集当前环境状态信息s,s由sack包和rtt时延信息构成;sack包是当接收终端发生乱序接收时,返回给发送终端的响应包,通过观察sack包返回的目标tcp子流和连续返回的sack包数量可以判断传输乱序情况和预留数据包传输量n值是偏大还是偏小;rtt反映了各tcp子流的链路质量情况;因此当前状态s可由(sack,rtt)的二维数组表示,为了便于矩阵表示,把sack包返回的目标tcp子流和连续sack包数量作为组合量化,由编号1开始,具体编号数量q由组合的类别数决定,rtt以1ms的精度表示(比如:1.4ms则记为1,2.5ms则记为2),rtt编号数量p由rtt的类别数决定。2)学习器l,它是一个三维矩阵m,x维、y维分别表示sack和rtt组成状态分量,z维表示可能的行动(action)的被选中概率,即可能的n值被选中的概率,z维度行动的数值即为n值,n是一个大于0的正整数,其数量k由训练网络中实际适用的n值类别数决定,因此矩阵m是一个q*p*k的矩阵。3)动作选择器p,它会根据当前状态信息s,查询矩阵m,选择出对应的行动(action)。
3、强化学习模型中的环境状态、行动、奖励,以及相关计算反馈公式的确定:对于环境w,每当接受一个行动(action),就会产生一个新的环境状态信息s',并返回一个奖励r,r决定了如何对智能体的学习器l中的三维矩阵m中的行动概率进行调整,即对n值被选中概率进行调整,使得n值的选择在每一种状态下逐渐趋向合理。r的奖励函数由公式(1)定义,mb代表在当前环境状态信息下以往最佳的数据包乱序度(bestofmess),mp代表当前行动ap所产生的数据包乱序度,以10%作为调整比例。因此,当mp大于mb时,奖励r是负数,相当于惩罚机制。当mp小于mb,奖励r是正数,相当于奖励机制。r作用于学习器l的方式由公式(2)表示,v[x,y,z]表示某状态下对应的某动作的选中概率值,sackp,rttp,ap表示当前的状态和行动,aother除当前行动外的其他行动,一共有n个。当学习器l得到r值首先它会对当前的动作的选中概率作出程度为r的调整,然后对其他状态都作出程度为
4、将强化学习模型部署至发送终端主机并使用训练算法进行训练:在ns-3网络实验平台上对强化学习模型进行部署,其中包含了多径tcp协议代码,将模型部署在发送终端主机的多径tcp协议层进行训练,训练算法则根据公式(1)、公式(2)的原则进行设定,请参照图2。训练的收敛原则为强化学习模型为多径tcp传输做出的调度使得多径tcp传输的吞吐率和包乱序度稳定在根据用户需求而预先设定的数值(吞吐率、包乱序度可由多径tcp传输终端测得)。
5、将训练好的强化学习模型部署至主机终端进行实际运行:训练好的强化学习模型,可以根据实际拓扑情况,部署至任意基于多径tcp协议的网络中。
以上是本发明的较佳实施例,凡依本发明技术方案所作的改变,所产生的功能作用未超出本发明技术方案的范围时,均属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!