一种基于循环预测和学习的网络流量异常检测方法与流程
一种基于循环预测和学习的网络流量异常检测方法,用于对网络流量异常的检测,属于网络安全领域。
背景技术:
随着internet的不断发展,网络规模日益扩大,其承载的网络业务逐渐增多。网络安全已成为人们越来越关心的问题。网络流量异常是指对网络正常使用造成不良影响的网络流量模式,网络扫描、ddos攻击、网络蠕虫病毒、恶意下载、物理链路损坏等都会导致网络流量异常。网络流量异常往往伴随严重后果,如占用网络资源,网络拥塞,造成丢包、延时增加;占用设备系统资源(cpu,内存等),网络设施面临瘫痪。因此网络异常流量的实时检测及合理响应对于维护网络安全、抑制恶意攻击和合理分配网络带宽具有重要意义。
目前常见的网络异常流量的检测方法有以下几种。
(1)基于数据挖掘的异常检测。数据挖掘可以有效的从海量网络流量数据中挖掘到潜在有用的信息。数据挖掘需要采集大量、真实有效的网络流量数据,通过抽样选取确定目标数据,对目标数据进行预处理及变换,然后应用数据挖掘中的算法,如分类、聚类分析、序列分析等,通过一定的判断规则,对流量数据进行检测。
(2)基于小波变换的异常检测。对于非稳定的信号,小波变换通过有限长的会衰减的小波基进行时频域变化,从而得到它的时频谱。小波变换检测流量的步骤通常为:对一个指标的全部采样值进行分析,将其拆分为不同的分量,通过计算不同分量的方差,来按照一定的概率发现指标异常。小波变换对于信号的分解和重构是有效的,分解后的信号在频域上具有专一性,并对信号进行了平滑处理,从而将处理方法从平稳时间序列扩展到了非平稳时间序列。通过分析不同的尺度下逼近信号和细节信号,可以方便的从中检测到异常流量。
(3)基于神经网络的异常检测。通过对输入信息的学习,构造输入和输出的关系模型,通过自动学习与更新,可以准确的表达非线性关系。因此当有新的输入进入时,可以良好的预测输出的情况。因此对于下一时间节点预测的错误概率一定程度上可以反过来代表该时间节点的行为异常程度。
上述中基于分类和神经网络检测模型对网络流量异常检测效果较好。其中,基于分类的方法主要包括有监督方法和无监督方法;而基于神经网络的异常检测方法分为多个变种,lstm则是近年研究热点。随着新的网络特征被不断挖掘,网络流量状态已经成为了一个多维时间序列,大量的特征指标(专用网络设备,如防火墙或流量分析系统对网络流量进行统计获得的某类流量统计特征指标,例如:“tcp报文数量”可以作为一个特征指标)和长时间周期(即为时间窗口,是指将一段连续时间划分为固定长度的多个时间周期,每个时间周期称为一个时间窗口)的跨度给分类和预测模型带来难度,提高了算法复杂度,且造成预测误报率偏高。原因是:现有基于神经网络的异常检测方法,基本上都基于一个基本假设,即:预测的结果一定是准确的,在网络未发生异常的情况下,预测值和实际值相当接近。事实上,在实际网络环境中,很难保证预测结果的准确性,因大规模网络往往存在大量突发流量,导致预测值和实际值存在不同程度的偏差。而在何种程度偏差的情况下输出异常告警,现有基于神经网络的异常检测方法普遍缺乏研究。如果单纯以预测值与实际值的差异作为异常判定条件,则会导致大量的误报和虚警。特别是在预测结果准确率不高的情况下,异常检测结果几乎不可用。
技术实现要素:
针对上述研究的问题,本发明的目的在于提供一种基于循环预测和学习的网络流量异常检测方法,解决现有技术中基于大量的特征指标和长时间周期,采用分类和预测模型对网络流量异常检测,会提高算法的复杂度和预测误报率的问题。
为了达到上述目的,本发明采用如下技术方案:
一种基于循环预测和学习的网络流量异常检测方法,其特征在于,如下步骤:
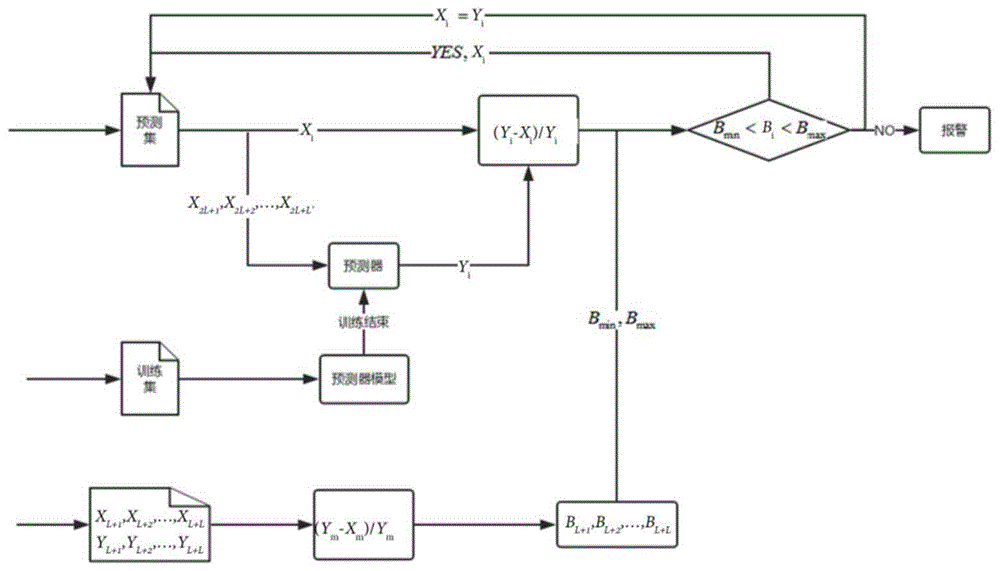
s1、基于第一个连续时间段,采集各时间周期内特征指标的采样值,对时间序列进行平滑修正,其中,采样值为一个时间周期内获得网络流量中一个特征指标的值,代表该特征指标在该时间周期内的数值,连续时间段为连续的l个时间周期;
s2、根据第一个连续时间段和平滑修正后的采样值,通过预测算法,获得第二个连续时间段内特征指标的预测值,其中,第二个连续时间段是指第l+1至第l+l;
s3、基于预测值和采集的第二个连续时间段内特征指标的采样值计算每个时间周期内指标的预测偏差率,根据所有预测偏差率得到预测偏差率正负极值;
s4、根据待判断的连续时间周期内特征指标的预测偏差率和步骤s3得到的预测偏差率正负极值进行异常判断。
进一步,所述步骤s1中各个时间周期内能采集一个特征指标或多个特征指标的采样值。
进一步,所述步骤s1的具体步骤为:
s1.1、基于连续的l个时间周期,采集各时间周期内同一特征指标的采样值构成时间序列x={x1,x2,...,xl};
s1.2、对时间序列x={x1,x2,...,xl}进行平滑修正,具体过程为:
s1.21、对时间序列x中的所有采样值取中位数,即中值,记为m/d;
s1.22、定义“正常最大值”为var,取初始值为mid,即var=mid;
s1.23、取出时间序列x中的所有采样值,按照从小到达进行重新排序,获得排序后的时间序列s={s1,s2,...,sl};
s1.24、按照从小到大的顺序,依次对时间序列s中的每个成员sk进行分析,计算其与mid的差值,如果sk-mid>0,而且sk-mid<var×3,则取var=sk;
s1.25、对时间序列x中的所有采样值进行检查和平滑,针对时间序列x中的采样值xk,计算其与var的差值,如果xk-var>0,则修改xk的值,取xk=max(xk-1,var)。
进一步,所述步骤s2中根据第一个连续时间段和平滑修正后的采样值,通过lstm算法,获得第二个连续时间段内、同一特征指标的预测值构成的时间序列y′=yl+1,yl+2,...,yl+l°
进一步,所述步骤s3的具体步骤为:
s3.1、采集第二个连续时间段内、同一特征指标的采样值构成的时间序列x’,特征指标与第一个连续时间段内采集的特征指标相同;
s3.2、基于对应编号,将时间序列γ′中的每个预测值ym与时间序列x′中的xm进行相减操作后,计算预测偏差率,构成预测偏差率时间序列b={bl+1,bl+2,...,bl+l},其中,计算公式为bm=(ym-xm)/ym,m=l+1,l+2,..·,l+l;
s3.3、初始化bmax和bmin的值为0,根据预测偏差率时间序列b={bl+1,bl+2,…,bl+l},统计其是否有大于零的值,若有,将最大值作为预测偏差率正极值bmax,若无,bmax为0,统计其是否有小于零的值,若有,将最小值作为预测偏差率负极值bmin,若无,bmin为0。
进一步,所述步骤s4中待判断的连续时间周期为第二个连续时间段后开始的多个连续时间周期,其中多个为l个时间周期或小于l个时间周期或大于l个时间周期中的一种。
进一步,的具体步骤为:
s4.1、基于待判断的连续时间周期,采集各时间周期内特征指标的采样值;同时针对第二个连续时间段的采样值构成的时间序列x’=xl+1,xl+2,...,xl+l,采用lstm算法,获得待判断的连续时间周期内,特征指标的预测值构成的时间序列y″=y2l+1,y2l+2,...,y2l+l′;
s4.2、根据步骤s4.1获得的待判断的连续时间周期的采样值和预测值,计算每个时间周期内特征指标的预测偏差率,并将计算得到的预测偏差率与bmin和bmax进行对比,如果bk<0且bk<bmin,或bk>0且bk>bmax判定为异常,输出异常告警,并转到步骤s4.3,否则判定为正常情况不告警;
s4.3、将待判断的连续时间周期的采样值构成的时间序列的xi替换为yi,i=2l+1,2l+2,…2l+l‘。
本发明同现有技术相比,其有益效果表现在:
一、本发明的预测、异常判断过程不需要人为进行训练,对预测算法的训练过程在步骤s1和步骤s2可自动完成,无需人工干预,也不需要使用传统机器学习异常检测方法所使用的训练集和测试集。
二、本发明克服了预测算法不准确的问题,即:本发明假设预测结果本身是不准确的,通过步骤s3的预测偏差率积累学习阶段,可识别可容忍的预测偏差率,从而避免了传统预测算法结果不准确带来的误报率过高的问题,降低异常检测的虚警率。相比之下,本发明解决了现有技术中假设的问题,即:通过对偏差值的学习,来容忍预测算法的合理偏差,在合理偏差范围内不触发异常告警。即使是在预测结果不准确的情况下,本发明也能够避免大量的异常误报,明显降低误报率。
附图说明
图1是本发明中的流程示意图;
图2是本发明实施例中连续时间段内特征指标的预测值构成的时间序列与特征指标的采样值构成的时间序列对比图。
具体实施方式
下面将结合附图及具体实施方式对本发明作进一步的描述。
一种基于循环预测和学习的网络流量异常检测方法,如下步骤:
s1、基于第一个连续时间段,采集各时间周期内特征指标的采样值,对时间序列进行平滑修正,其中,采样值为一个时间周期内获得网络流量中一个特征指标的值,代表该特征指标在该时间周期内的数值,连续时间段为连续的l个时间周期;各个时间周期内能采集一个特征指标或多个特征指标的采样值。具体步骤为:
s1.1、基于连续的l个时间周期,采集各时间周期内同一特征指标的采样值构成时间序列x={x1,x2,...,xl};
s1.2、对时间序列x={x1,x2,...,xl}进行平滑修正,具体过程为:
s1.21、对时间序列x中的所有采样值取中位数,即中值,记为m/d;
s1.22、定义“正常最大值”为var,取初始值为mid,即var=mid;
s1.23、取出时间序列x中的所有采样值,按照从小到达进行重新排序,获得排序后的时间序列s={s1,s2,...,sl};
s1.24、按照从小到大的顺序,依次对时间序列s中的每个成员sk进行分析,计算其与mid的差值,如果sk-mid>0,而且sk-mid<var×3,则取var=sk;
s1.25、对时间序列x中的所有采样值进行检查和平滑,针对时间序列x中的采样值xk,计算其与var的差值,如果xk-var>0,则修改xk的值,取xk=max(xk-1,var)。
s2、根据第一个连续时间段和平滑修正后的采样值,通过预测算法,获得第二个连续时间段内特征指标的预测值,其中,第二个连续时间段是指第l+1至第l+l;即根据第一个连续时间段和平滑修正后的采样值,通过lstm算法,获得第二个连续时间段内、同一特征指标的预测值构成的时间序列y′=yl+1,yl+2,...,yl+l
s3、基于预测值和采集的第二个连续时间段内特征指标的采样值计算每个时间周期内指标的预测偏差率,根据所有预测偏差率得到预测偏差率正负极值;具体步骤为:
s3.1、采集第二个连续时间段内、同一特征指标的采样值构成的时间序列x′,特征指标与第一个连续时间段内采集的特征指标相同;
s3.2、基于对应编号,将时间序列γ′中的每个预测值ym与时间序列x′中的xm进行相减操作后,计算预测偏差率,构成预测偏差率时间序列b={bl+1,bl+2,...,bl+l},其中,计算公式为bm=(ym-xm)/ym,m=l+1,l+2,..·,l+l;
s3.3、初始化bmax和bmin的值为0,根据预测偏差率时间序列b={bl+1,bl+2,…,bl+l},统计其是否有大于零的值,若有,将最大值作为预测偏差率正极值bmax,若无,bmax为0,统计其是否有小于零的值,若有,将最小值作为预测偏差率负极值bmin,若无,bmin为0。
s4、根据待判断的连续时间周期内特征指标的预测偏差率和步骤s3得到的预测偏差率正负极值进行异常判断。其中,待判断的连续时间周期为第二个连续时间段后开始的多个连续时间周期,其中多个为l个时间周期或小于l个时间周期或大于l个时间周期中的一种。
具体步骤为:
s4.1、基于待判断的连续时间周期,采集各时间周期内特征指标的采样值;同时针对第二个连续时间段的采样值构成的时间序列x’=xl+1,xl+2,...,xl+l,采用lstm算法,获得待判断的连续时间周期内,特征指标的预测值构成的时间序列y‘’=y2l+1,y2l+2,..,y2l+l,;
s4.2、根据步骤s4.1获得的待判断的连续时间周期的采样值和预测值,计算每个时间周期内特征指标的预测偏差率,并将计算得到的预测偏差率与bmin和bmax进行对比,如果bk<0且bk<bmin,或bk>0且bk>bmax判定为异常,输出异常告警,并转到步骤s4.3,否则判定为正常情况不告警;
s4.3、将待判断的连续时间周期的采样值构成的时间序列的xi替换为yi,i=2l+1,2l+2,...2l+l‘。
实施例
本发明采用硬件探针的方式收集数据流量,本实验的网络流量数据来自于2017年cernet中采集的正常流量数据。我们选取tcp下行流量特征指标(tcpinbytes特征指标)进行实施。实施例选取11月12日9∶42到10∶30的tcpinbytes原始数据部分,时间周期为一分钟,l=10。实验步骤如下:
步骤1:首先通过日志采集等手段,获得dpi或网络设备采集tcpinbytes特征指标的采样值,构成时间序列x。
首先获得并累积连续的10个tcpinbytes特征指标的采样值,即9∶42到9∶51的采样值,构成时间序列x={x1,x2,...,x10},具体为:x={2.89×109,2.88×109,2.90×109,2.91×109,2.90×109,2.88×109,2.87×109,2.89×109.15.73×109,2.90×109},对x进行预处理,即对其中的部分采样值进行平滑修正后,得到新的采样值构成的时间序列x={2.89×109,2.88×109,2.90×109,2.91×109,2.90×109,2.88×109,2.87×109,2.89×109.2.91×109,2.90×109},其中倒数第二个采样值被平滑处理了。
步骤2:初始预测阶段,获取特征指标的预测值,构成时间序列γ′。
依据步骤1中连续10个时间窗口的采样值构成的时间序列x,本步骤从第11个时间窗口开始,对此后的连续10个时间窗口进行预测,可获得连续的10个特征指标的预测值,即9∶52到10∶01的预测值,构成时间序列γ′,记为y′=yl+1,yl+2,...,y∶+l={2.80×109,2.88×109,2.89×109,2.89×109,2.82×109,2.88×109,2.80×109,2.89×109,2.91×109,2.94×109};
步骤3:获得预测偏差率时间序列b,以及预测偏差率正负极值;
将步骤2获得的10个连续的预测值构成的时间序列γ′,与获取的9∶52到10∶01的tcpinbytes特征指标的采样值构成的时间序列x′(x’=xl+1,xl+2,...,xl+l)={2.90×109,2.90×109,2.89×109,2.90×109,2.80×109,2.87×109,2.79×109,2.88×109,2.89×109,2.90×109}进行一对一(如9:52此时间周期内的预测值与采样值)的偏差率计算,计算预测偏差率bm=(ym-xm)/ym,该步骤中ym和xm分别为同一时间窗口内的指标预测值和特征指标的采样值,由此可以获得预测偏差率构成的时间序列b={bl+1,bl+2,...,bl+l}={-3.57%,-0.69%,0%,-0.35%,0.7%,0.35%,0.36%,0.35%,0.69%,1.36%},进而得出bmax=1.36%,bmin=-3.57%。
步骤4:该步骤为循环预测与异常检测阶段。获取10:02到10:12的tcpinbytes特征指标的采样值,构成时间序列x‘’={2.81×109,2.92×109,2.91×109,2.90×109,2.90×109,2.91×109,2.92×109,2.90×109,2.92×109,2.79×109,2.18×109},得到连续的预测值时间序列γ′={2.83×109,2.90×109,2.89×109,2.89×109,2.89×109,2.90×109,2.91×109,2.89×109,2.90×10q,2.88×109,2.80×109}与预测偏差率时间序列b={0.71%,-0.69%,-0.70%,-0.35%,-0.35%,-0.34%,-0.34%,-0.33%,-0.69%,3.10%,22.14%}。图2为该时段内的tcpinbytes预测序列和实际值的对比图。不难发现,在10:12时刻b=22.14%>bmax,即出现异常,此异常表现为tcp流量突降异常。
以上仅是本发明众多具体应用范围中的代表性实施例,对本发明的保护范围不构成任何限制。凡采用变换或是等效替换而形成的技术方案,均落在本发明权利保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!