视频制作模板的推荐方法及推荐装置与流程
本发明涉及视频处理技术领域,特别是涉及一种视频制作模板的推荐方法及推荐装置。
背景技术:
短视频即短篇视频,通常为时长几分钟左右的视频作品,随着移动终端的普及和网络的提速,同时由于短视频制作流程简单且制作成本低,短视频受到大众的青睐并吸引大众纷纷加入短视频的制作。
短视频在制作过程中,往往会加入音乐、特效等要素以丰富视频的内容。目前的短视频制作,对于加入的要素,通常为制作者的主观选择,这使得制作者在制作视频时,不了解该视频加入何种要素会获得最大程度的关注,且无法预期视频的效果,不利于制作者的制作体验。
如何给视频制作者智能推荐视频制作模板,是目前提高制作者制作体验亟待解决的问题之一。
技术实现要素:
本发明主要解决的技术问题是提供一种视频制作模板的推荐方法及推荐装置,可为视频制作者智能推荐视频制作模板,提高制作体验。
为解决上述技术问题,本发明提供一种视频制作模板的推荐方法,包括以下步骤:采集用户的视频信息并提取其中的视频要素;发送视频要素至服务器端;接收服务器端反馈的利用神经网络模型处理得到的视频制作模板,视频制作模板包括视频类型、背景音乐、特效类型和预期关注度;显示视频制作模板供用户参考使用。
其中,神经网络模型采用反向传播神经网络。
其中,视频类型为搞笑、怀旧、青春、情感或动作,特效类型为滤镜、美颜、抖动或装饰,视频要素包括生物和/或物体。
为解决上述技术问题,本发明还提供一种视频制作模板的推荐方法,包括以下步骤:接收移动终端发送的视频要素;将视频要素输入预先训练的神经网络模型进行处理,得出相应的视频制作模板,视频制作模板包括视频类型、背景音乐、特效类型和预期关注度;将视频制作模板反馈至移动终端;其中,神经网络模型为反向传播神经网络。
其中,神经网络模型通过以下步骤生成:采集样本视频的视频要素,以构成视频要素数据库,视频要素包括生物和/或物体;采集样本视频的附加信息,附加信息包括视频类型、背景音乐、特效类型和关注度,视频类型为搞笑、怀旧、青春、情感或动作,特效类型为滤镜、美颜、抖动或装饰;将视频要素作为输入,附加信息作为输出,训练神经网络模型的各个权值。
为解决上述技术问题,本发明提供一种视频制作模板的推荐装置,包括:采集模块,用于采集用户的视频信息并提取其中的视频要素;发送模块,用于发送视频要素至服务器端;第一接收模块,用于接收服务器端反馈的利用神经网络模型处理得到的视频制作模板,视频制作模板包括视频类型、背景音乐、特效类型和预期关注度;显示模块,用于显示视频制作模板供用户参考使用。
其中,神经网络模型采用反向传播神经网络。
其中,视频类型为搞笑、怀旧、青春、情感或动作,特效类型为滤镜、美颜、抖动或装饰,视频要素包括生物和/或物体。
为解决上述技术问题,本发明还提供一种视频制作模板的推荐装置,包括:第二接收模块,用于接收移动终端发送的视频要素;处理模块,用于将视频要素输入预先训练的神经网络模型进行处理,得出相应的视频制作模板,视频制作模板包括视频类型、背景音乐、特效类型和预期关注度;反馈模块,用于将视频制作模板反馈至移动终端;其中,神经网络模型为反向传播神经网络。
其中,神经网络模型包括:第一采集单元,用于采集样本视频的视频要素,以构成视频要素数据库,视频要素包括生物和/或物体;第二采集单元,用于采集样本视频的附加信息,附加信息包括视频类型、背景音乐、特效类型和关注度,视频类型为搞笑、怀旧、青春、情感或动作,特效类型为滤镜、美颜、抖动或装饰;训练单元,用于将视频要素作为输入,附加信息作为输出,训练神经网络模型的各个权值。
本发明的有益效果是:区别于现有技术的情况,本发明的推荐方法的具体过程为:首先采集用户的视频信息并提取其中的视频要素,然后发送视频要素至服务器端,服务器端利用预先训练的神经网络模型,获得相应的视频制作模板,并将视频制作模板反馈至移动终端,供用户参考使用。通过上述方式,可为用户智能推荐视频制作模板,视频制作模板的作用在于给出对于预制作的视频素材来说,最优的视频制作类型、音乐、特效以及如果使用该模板推荐可预期达到的关注度,视频制作模板的推荐可大大提高用户的视频制作体验。
附图说明
图1是本发明视频制作模板的推荐方法一实施例的流程示意图;
图2是本发明视频制作模板的推荐方法另一实施例的流程示意图;
图3是本发明视频制作模板的推荐装置一实施例的结构示意图;
图4是本发明视频制作模板的推荐装置另一实施例的结构示意图。
具体实施方式
下面结合附图和实施例对本发明进行详细说明。
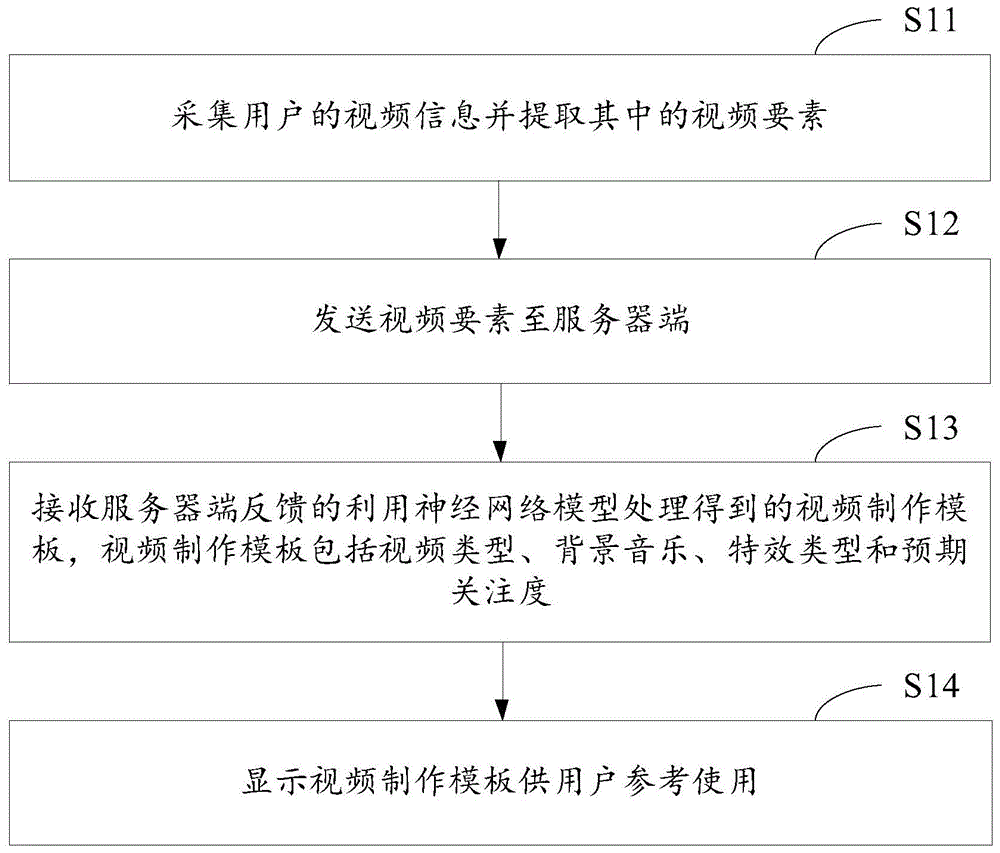
请参阅图1,图1是本发明视频制作模板的推荐方法一实施例的流程示意图,如图1所示,包括以下步骤:
s11,采集用户的视频信息并提取其中的视频要素。
本实施例的方法应用于移动终端,移动终端可以为手机、ipad等智能设备,移动终端的操作系统可以为windows、ios或android等操作系统。
本实施例中,用户的视频信息为用户拍摄的视频素材,对视频信息的提取过程具体为视频处理过程,如:视频关键帧提取、特征提取等,具体是提取视频素材中的视频要素,即生物、物体,此处所述的视频要素通常是常见的较大的生物或物体。
s12,发送视频要素至服务器端。
此处的服务器端可以为云端。
s13,接收服务器端反馈的利用神经网络模型处理得到的视频制作模板,视频制作模板包括视频类型、背景音乐、特效类型和预期关注度。
服务器端设置有神经网络模型,在本实施例中,神经网络模型为反向传播神经网络,通过神经网络模型利用接收的视频要素输出与视频要素对应的视频制作模板,并将视频制作模板发送至移动终端,供用户参考。需要指出的是,对于神经网络模型类型的选择,本发明不作限定,可根据需要选择其他的神经网络模型。
其中,视频制作模板是通过神经网络模型的智能推荐,为最优的、可获得最好关注度的视频制作方案,其中的视频类型为搞笑、怀旧、青春、情感或动作,特效类型为滤镜、美颜、抖动或装饰,预期关注度为预期可获得的关注数。需要指出的是,视频类型和特效类型仅是有限的列举,不作为对本发明的限定。
s14,显示视频制作模板供用户参考使用。
移动终端获得视频制作模板后,在相应的界面显示,供用户参考,以提高用户的视频制作体验。
请参阅图2,图2是本发明视频制作模板的推荐方法另一实施例的流程示意图,如图2所示,包括以下步骤:
s21,接收移动终端发送的视频要素。
本实施例方法应用于服务器端,服务器端可以为云端,此处的视频要素为生物、物体,是图1所示实施例中的视频要素。
s22,将视频要素输入预先训练的神经网络模型进行处理,得出相应的视频制作模板,视频制作模板包括视频类型、背景音乐、特效类型和预期关注度。
深度学习(deeplearning)是机器学习中一个非常接近人工智能的领域,其动机在于建立模拟人脑进行分析学习的神经网络。而神经网络是对人脑神经工作的一种简化模型,模拟人脑对神经元之间的联系和强度的调节。
在本实施例中,神经网络模型采用反向传播神经网络。bp算法也即反向传播算法,是为解决多层前向神经网络的权系数优化而提出。bp神经网络含有输入层、输出层,以及处于输入输出层之间的中间层,中间层包括单层或多层,又被称为隐层,改变隐层的权系数能够改变整个神经网络的性能。
在本实施例中,神经网络模型通过以下步骤生成:
a.采集样本视频的视频要素,以构成视频要素数据库,视频要素包括生物和/或物体。
获取一定数量的已经发表的短视频,采集每个短视频中的视频要素。
b.采集样本视频的附加信息,附加信息包括视频类型、背景音乐、特效类型和关注度,视频类型为搞笑、怀旧、青春、情感或动作,特效类型为滤镜、美颜、抖动或装饰。
在对短视频的采集过程中,除了采集视频要素,还需采集视频的附加信息,其中,视频类型和特效类型仅是有限的列举,不作为对本发明的限定。
c.将视频要素作为输入,附加信息作为输出,训练神经网络模型的各个权值。
且该神经网络模型在训练过程中,为使其输出结果精度更高,设定自动学习规则,加入人工干预因素。
在其他实施例中,还可选择其他类型的神经网络,进行视频制作模板的推荐。
s23,将视频制作模板反馈至移动终端。
在本实施例中,反向传播神经网络的作用为智能输出最优、预期可获得较多关注的视频制作模板。当移动终端的用户收到推荐的视频制作模板后,视频制作模板可对用户的视频制作起到参考作用,提高用户的制作体验。
请参阅图3,图3是本发明视频制作模板的推荐装置一实施例的结构示意图,如图3所示,包括:采集模块31、发送模块32、第一接收模块33和显示模块34。
上述各模块的功能具体如下:
采集模块31用于采集用户的视频信息并提取其中的视频要素;发送模块32用于发送视频要素至服务器端;第一接收模块33用于接收服务器端反馈的利用神经网络模型处理得到的视频制作模板,视频制作模板包括视频类型、背景音乐、特效类型和预期关注度;显示模块34用于显示视频制作模板供用户参考使用。
请参阅图4,图4是本发明视频制作模板的推荐装置另一实施例的结构示意图,如图4所示,包括:第二接收模块41、处理模块42和反馈模块43。
上述各模块的功能具体如下:
第二接收模块41用于接收移动终端发送的视频要素;处理模块42用于将视频要素输入预先训练的神经网络模型进行处理,得出相应的视频制作模板,视频制作模板包括视频类型、背景音乐、特效类型和预期关注度;反馈模块43用于将视频制作模板反馈至移动终端。
结合图3和图4,当用户在移动终端进行短视频制作时,首先采集模块31采集预制作的短视频中的视频要素,发送模块32发送视频要素至服务器端;服务器端的第二接收模块41接收到视频要素后,处理模块42进行处理,具体通过神经网络模型进行处理,其中,本实施例中的神经网络模型采用反向传播神经网络,但神经网络模型的类型不作限定,可根据需要进行选择;通过处理模块42处理,获得相应的视频制作模板,反馈模块43将视频制作模板反馈至移动终端;移动终端的第一接收模块33接收到视频制作模板后,显示模块34利用界面显示视频制作模板,供用户参考。
其中,视频要素包括生物和/或物体,视频类型为搞笑、怀旧、青春、情感或动作,特效类型为滤镜、美颜、抖动或装饰。需要指出的是,视频类型和特效类型仅是有限的列举,不作为对本发明的限定。
其中,神经网络模型包括:第一采集单元(图未示)、第二采集单元(图未示)及训练单元(图未示)。第一采集单元用于采集样本视频的视频要素,以构成视频要素数据库;第二采集单元用于采集样本视频的附加信息,附加信息包括视频类型、背景音乐、特效类型和关注度;训练单元用于将视频要素作为输入,附加信息作为输出,训练神经网络模型的各个权值。
以上所述,图3和图4所示的装置构成视频制作模板的推荐系统,实现视频制作模板的推荐。
综上所述,本发明利用反向传播神经网络为用户智能推荐视频制作模板,视频制作模板包括视频类型、背景音乐、特效类型和预期关注度,视频制作模板的作用在于给出对于预制作的视频素材来说,最优的视频制作类型、音乐、特效以及如果使用该模板推荐可预期达到的关注度,该视频制作模板的推荐可大大提高用户的视频制作体验。
以上所述仅为本发明的实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!