面向分布式机器学习任务的云资源在线调度方法及装置与流程
本发明涉及云计算技术领域,具体涉及一种面向分布式机器学习任务的云资源在线调度方法及装置。
背景技术:
传统式机器学习倾向于把所有的数据集集中起来离线式训练,从而得到较优的模型。而实际训练的过程中,数据源通常是地理分散的,并且并不是同一时刻产生的,而是随着时间呈序列顺序产生,因而传统的机器学习的训练方法不再适用,而需要借助于分布式机器学习(geo-distributedmachinelearning)。分布式机器学习能够有效地训练随着时间的推移而产生的大型地理分散型数据集,无须再把所有的数据集集中在一个中心站点训练。
目前,分布式机器学习普遍采用参数服务器(parameterserver)框架,为了训练一个全局机器学习模型,如何战略性地部署和调整地理分布式机器学习任务中的计算节点(worker)和参数服务器(parameterserver),以便于随时轻松访问数据集并且快速交换模型参数,是一个热点问题。与此同时,许多云平台提供总额折扣以鼓励大家使用他们的机器学习资源。
本申请发明人在实施本发明的过程中,发现现有技术的方法,至少存在如下技术问题:
现有的很多地理分布式机器学习任务一般单独从各个云资源平台租赁任务所需要的资源,调度效果不佳,用户很少能够享受折扣,因此,需要耗费巨额租赁费用,扩大了支出成本。
由此可知,现有技术中的方法存在调度效果不佳的技术问题。
技术实现要素:
有鉴于此,本发明提供了一种面向分布式机器学习任务的云资源在线调度方法及装置,用以解决或者至少部分解决现有技术中的方法存在调度效果不佳的技术问题。
本发明第一方面提供了一种面向分布式机器学习任务的云资源在线调度方法,包括:
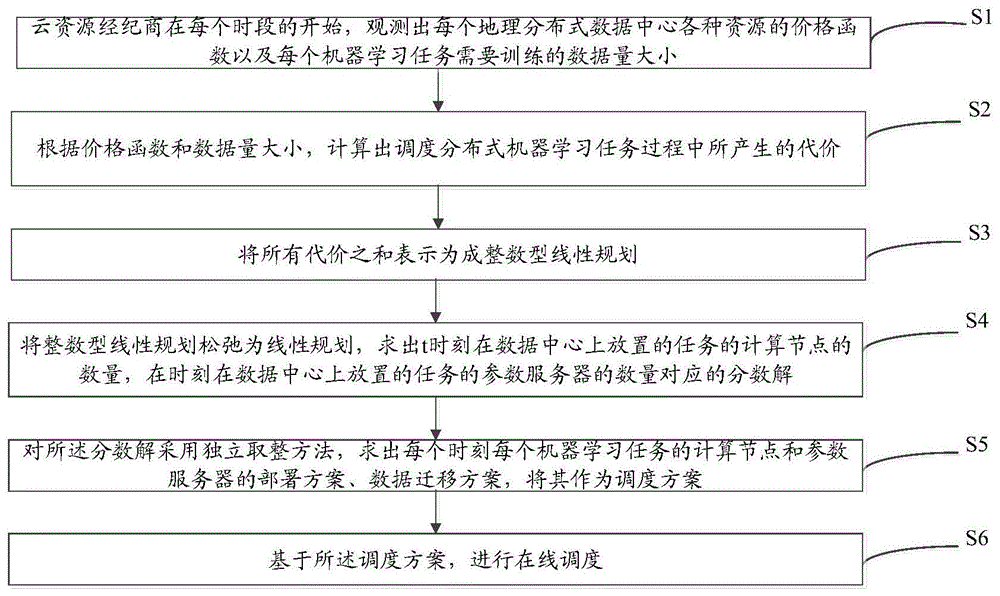
步骤s1:云资源经纪商在每个时段的开始,观测出每个地理分布式数据中心各种资源的价格函数以及每个机器学习任务需要训练的数据量大小,其中,地理分布式数据中心用于放置计算节点和参数服务器,机器学习任务由用户提交,并且在每个时刻产生下个时刻每个任务需要训练的数据量,价格函数为
其中,h为资源使用量,
步骤s2:根据价格函数和数据量大小,计算出调度分布式机器学习任务过程中所产生的代价;
步骤s3:将所有代价之和表示为成整数型线性规划;
步骤s4:将整数型线性规划松弛为线性规划,求出t时刻在数据中心r上放置的任务i的计算节点的数量,在t时刻在数据中心r上放置的任务i的参数服务器的数量对应的分数解;
步骤s5:对所述分数解采用独立取整方法,求出每个时刻每个机器学习任务的计算节点和参数服务器的部署方案、数据迁移方案,将其作为调度方案;
步骤s6:基于所述调度方案,进行在线调度。
在一种实施方式中,调度分布式机器学习任务过程中所产生的代价包括数据迁移代价、资源租用代价、部署代价和通信代价,步骤s2具体包括:
步骤s2.1:获取与调度相关的参数,具体包括:任务i的计算节点的处理能力为pi,任务i的计算节点需要的k类资源的数量为ni,k,任务i的参数服务器需要的k类资源的数量为mi,t,参数服务器和计算节点之间需要交换的参数大小为bi,在t时刻在数据中心r上放置的任务i的计算节点的数量为
步骤s2.2:根据单位数据迁移成本与迁移的数据量,表示数据迁移代价c1(t),其中,
步骤s2.3:根据用户任务所需要消耗的资源量和资源价格方程,表示出资源租用代价c2(t),其中,
步骤s2.4:根据上一时刻和当前时刻计算节点和参数服务器的部署情况来表示部署代价c3(t),其中,
步骤s2.5:根据部署方案表示出节点和参数服务器的通信代价
在一种实施方式中,步骤s3具体包括:
将数据迁移代价、资源租用代价、部署代价和通信代价相加表示为整数型线性规划,minimize∑t∈t(c1(t)+c2(t)+c3(t)+c4(t)),并构建约束条件,约束条件具体包括约束条件(1)~(11):
其中,i表示用户总数,t为总时长,r为地理分布式数据中心数量,
在一种实施方式中,步骤s4具体包括:
将整数型线性规划松弛成线性规划,再采用正则化方法将每相邻两个时段内的关系解耦获得归一化项:
在一种实施方式中,步骤s5具体包括:
步骤s5.1:对步骤s4的
根据概率
步骤s5.2:将
步骤s5.3:将通过步骤s5.1和步骤s5.2求出来的
基于同样的发明构思,本发明第二方面提供了一种面向分布式机器学习任务的云资源在线调度装置,包括:
价格函数及数据量观测模块,用于在每个时段的开始,观测出每个地理分布式数据中心各种资源的价格函数以及每个机器学习任务需要训练的数据量大小,其中,地理分布式数据中心用于放置计算节点和参数服务器,机器学习任务由用户提交,并且在每个时刻产生下个时刻每个任务需要训练的数据量,价格函数为
其中,h为资源使用量,
代价计算模块,用于根据价格函数和数据量大小,计算出调度分布式机器学习任务过程中所产生的代价;
整数型线性规划表示模块,用于将所有代价之和表示为成整数型线性规划;
松弛化模块,用于将整数型线性规划松弛为线性规划,求出t时刻在数据中心r上放置的任务i的计算节点的数量,在t时刻在数据中心r上放置的任务i的参数服务器的数量对应的分数解;
调度方案求解模块,用于对所述分数解采用独立取整方法,求出每个时刻每个机器学习任务的计算节点和参数服务器的部署方案、数据迁移方案,将其作为调度方案;
调度模块,用于基于所述调度方案,进行在线调度。
在一种实施方式中,调度分布式机器学习任务过程中所产生的代价包括数据迁移代价、资源租用代价、部署代价和通信代价,代价计算模块具体用于执行下述步骤:
步骤s2.1:获取与调度相关的参数,具体包括:任务i的计算节点的处理能力为pi,任务i的计算节点需要的k类资源的数量为ni,k,任务i的参数服务器需要的k类资源的数量为mi,t,参数服务器和计算节点之间需要交换的参数大小为bi,在t时刻在数据中心r上放置的任务i的计算节点的数量为
步骤s2.2:根据单位数据迁移成本与迁移的数据量,表示数据迁移代价c1(t),其中,
步骤s2.3:根据用户任务所需要消耗的资源量和资源价格方程,表示出资源租用代价c2(t),其中,
步骤s2.4:根据上一时刻和当前时刻计算节点和参数服务器的部署情况来表示部署代价c3(t),其中,
步骤s2.5:根据部署方案表示出节点和参数服务器的通信代价c4(t),其中,
在一种实施方式中,整数型线性规划表示模块具体用于:
将数据迁移代价、资源租用代价、部署代价和通信代价相加表示为整数型线性规划,minimize∑t∈t(c1(t)+c2(t)+c3(t)+c4(t)),并构建约束条件,约束条件具体包括约束条件(1)~(11):
其中,i表示用户总数,t为总时长,r为地理分布式数据中心数量,
基于同样的发明构思,本发明第三方面提供了一种计算机可读存储介质,其上存储有计算机程序,该程序被执行时实现第一方面所述的方法。
基于同样的发明构思,本发明第四方面提供了一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现如第一方面所述的方法。
本申请实施例中的上述一个或多个技术方案,至少具有如下一种或多种技术效果:
本发明公开的一种面向分布式机器学习任务的云资源在线调度方法,首先由云资源经纪商在每个时段的开始,观测出每个数据中心各种资源的价格函数,以及每个任务需要训练的数据量大小,计算出调度分布式机器学习任务过程中所产生的所有的代价之和,表示成整数型线性规划,然后将松弛后的线性规划通过正则化方法(regularizationmethod)将每相邻两个时段内的关系解耦,将难以处理的整个t时刻的在线规划问题转化成每个时刻(one-slot)独立的线性规划,这样就可以实时决策不需要依赖未来的信息,最后采用设计的独立取整(dependentrounding)方法求出每个时刻每个机器学习任务的计算节点(worker)和参数服务器(parameterserver)的部署方案,以及数据迁移方案,最后进行在线调度,从而达到保证任务完成效果的基础上总体的代价之和最小,优化了调度效果。
此外,本发明采用了在线正则化算法将难以处理的全时段关联性问题,分割成独立的单时刻问题,并且在计算过程中运用了在线独立取整,从而保证了算法的合理性。本发明能够在不需要知道未来情况下,趋向最优地在线调度地理分布式机器学习任务和资源,避免了高额的租赁费用和运行任务的高成本,从而在以最低成本高效地实时调度和部署各项任务和资源。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本发明实施例中面向分布式机器学习任务的云资源在线调度方法的流程图;
图2为一种具体实施方式中求解调度方案的计算流程图;
图3a和3b为本发明实施例的方法和其他现有方法的实验结果对比图;
图4为本发明实施例面向分布式机器学习任务的云资源在线调度装置的结构框图;
图5为本发明实施例中一种计算机可读存储介质的结构框图;
图6为本发明实施例中计算机设备的结构图。
具体实施方式
本发明的目的在于提供一种面向分布式机器学习任务的云资源在线调度方法及装置,用以改善现有技术中的方法存在调度效果不佳的技术问题。
为了解决上述技术问题,本发明的主要构思如下:
首先,由云资源经纪商在每个时段的开始,观测出每个数据中心各种资源的价格函数,以及每个任务需要训练的数据量大小,并计算出调度分布式机器学习任务过程中所产生的所有的代价之和,表示成整数型线性规划;然后,将松弛后的线性规划通过正则化方法(regularizationmethod)将每相邻两个时段内的关系解耦,再采用独立取整(dependentrounding)方法求出每个时刻每个机器学习任务的计算节点(worker)和参数服务器(parameterserver)的部署方案,以及数据迁移方案,得到调度方案,最后基于调度方案进行在线调度,从而使得在保证任务完成效果的基础上总体的代价之和最小。
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
实施例一
本实施例提供了一种面向分布式机器学习任务的云资源在线调度方法,请参见图1,该方法包括:
步骤s1:云资源经纪商在每个时段的开始,观测出每个地理分布式数据中心各种资源的价格函数以及每个机器学习任务需要训练的数据量大小,其中,地理分布式数据中心用于放置计算节点和参数服务器,机器学习任务由用户提交,并且在每个时刻产生下个时刻每个任务需要训练的数据量,价格函数为
其中,h为资源使用量,
具体来说,本申请发明人通过大量的实践和研究发现,为了更好地利用总额折扣以最优的方式租赁资源,调度分布式机器学习任务,便需要资源经纪商(brokerage)来汇总所有任务的资源需求,并且以其名义利用总额折扣。因此,基于各个机器学习任务在不同时刻不同地理位置产生不同的数据量大小的情况,如何高效的部署每个任务的计算节点,以使得运行所有任务最终付出的代价最小的情况下保证任务完成的质量,成为一个关键性的问题,因此提出了本发明的在线调度方法。
其中,各种资源包括gpu、cpu、内存、外存等,每个任务在每个数据中心上新增需要训练的数据量大小
本发明的方法涉及的信息包括:有i个用户在总长为t的时刻里提交机器学习任务,定义r个地理分布式数据中心,用来放置计算节点和参数服务器,并且在每个时刻产生下个时刻每个任务需要训练的数据
其中h为资源使用量,
步骤s2:根据价格函数和数据量大小,计算出调度分布式机器学习任务过程中所产生的代价。
其中,调度分布式机器学习任务过程中所产生的代价包括数据迁移代价、资源租用代价、部署代价和通信代价,步骤s2具体包括:
步骤s2.1:获取与调度相关的参数,具体包括:任务i的计算节点的处理能力为pi,任务i的计算节点需要的k类资源的数量为ni,k,任务i的参数服务器需要的k类资源的数量为mi,t,参数服务器和计算节点之间需要交换的参数大小为bi,在t时刻在数据中心r上放置的任务i的计算节点的数量为
步骤s2.2:根据单位数据迁移成本与迁移的数据量,表示数据迁移代价c1(t),其中,
步骤s2.3:根据用户任务所需要消耗的资源量和资源价格方程,表示出资源租用代价c2(t),其中,
步骤s2.4:根据上一时刻和当前时刻计算节点和参数服务器的部署情况来表示部署代价c3(t),其中,
步骤s2.5:根据部署方案表示出节点和参数服务器的通信代价c4(t),其中,
具体来说,步骤s2.2中,数据迁移代价,即为单位数据迁移成本乘以迁移的数据量的累加;步骤s2.3中,资源租用代价,即为计算节点和参数服务器的总结点需要的资源量在价格函数中的值的累加,步骤s2.4中,对每个任务和每个数据中心进行累加,则可以求得所有的部署代价之和。步骤s2.5中的通信代价,即为单位迁移数据的成本乘以参数服务器和计算节点直接一共要交换的数据量大小的累加。
步骤s3:将所有代价之和表示为成整数型线性规划。
在一种实施方式中,步骤s3具体包括:
将数据迁移代价、资源租用代价、部署代价和通信代价相加表示为整数型线性规划,minimize∑t∈t(c1(t)+c2(t)+c3(t)+c4(t)),并构建约束条件,约束条件具体包括约束条件(1)~(11):
其中,i表示用户总数,t为总时长,r为地理分布式数据中心数量,
具体来说,该线性规划方程式的目标函数即为四种代价的累加和,subjectto后即为所要满足的约束条件。第一个约束条件满足每个任务在每个数据中心布置了足够多的计算节点完成相应的训练任务;第二个约束条件满足了每个时刻的数据集全部都被处理掉;第三至第五个约束条件满足了尽可能地利用总额折扣降低租赁资源成本;第六个约束条件保证每个任务都配有一个参数服务器;第七个和第八个约束条件保证了部署的完备性,即只要任务发生变化都要进行重新部署。第九个和第十个约束条件保证每个任务的计算节点和参数服务器都能够成功通讯,最后一个约束条件保证了每个变量的合理性。
其中,
步骤s4:将整数型线性规划松弛为线性规划,求出t时刻在数据中心r上放置的任务i的计算节点的数量,在t时刻在数据中心r上放置的任务i的参数服务器的数量对应的分数解。
在一种实施方式中,步骤s4具体包括:
将整数型线性规划松弛成线性规划,再采用正则化方法将每相邻两个时段内的关系解耦获得归一化项:
具体来说,将整数型线性规划松弛成线性规划,即将约束条件(11)的所有变量的范围都调整为大于等于零。然后在这基础上用正则化regularizationmethod将目标方程式的c3(t)替换成一个证明凸性的归一化项,归一化项中的ε和σ用来进行归一化和防止分母为零两个作用,在实际计算时,取大于0小于1的数。通过这个方法可以去除掉相邻两个时间段之间的关联性,使得可以将整个时间段t上的线性规划分割成每个时刻(one-slot)独立的线性规划,从而可以运用经典的内点法求出相应的分数解。
步骤s5:对所述分数解采用独立取整方法,求出每个时刻每个机器学习任务的计算节点和参数服务器的部署方案、数据迁移方案,将其作为调度方案。
具体来说,由于每个数据中心上放置的计算节点数和参数服务器的数量必须是整数,因而该步骤采用独立取整dependentrounding的方法将前述步骤求出的分数解转化为整数解,并且保证转化后的性能基本不变。最后求出的整数解即为云资源经纪商的调度方案,即每个时刻在每个数据中心为每个任务部署多少个计算节点和参数服务器(对应于变量
在一种实施方式中,步骤s5具体包括:
步骤s5.1:对步骤s4的
根据概率
步骤s5.2:将
步骤s5.3:将通过步骤s5.1和步骤s5.2求出来的
具体来说,通过步骤s5.1后,如果新的pi1(t)和pi2(t)中有变为0或者1的,则将从集合
步骤s201:初始化
步骤s202:在每个时段的开始时刻,观测每个数据中心各种资源的价格函数
步骤s203:计算四种成本,联立原始线性规划方程;
步骤s204:采用正则化方法替换c3(t),并计算出
步骤s205:采用独立取整方法计算出
在获得调度方案后,执行步骤s6:基于所述调度方案,进行在线调度。
具体来说,再通过本发明设计的算法模型求解出调度方案后,则可以根据调度方案对用户提交的机器学习任务进行在线调度,通过基于总额折扣,在线调度地理分布式机器学习任务,以实现所有的成本之和最小化,从而优化了调度效果。
为了便于本领域普通技术人员理解和实施本发明,下面结合附图及实施例对本发明作进一步的详细描述,应当理解,此处所描述的实施示例仅用于说明和解释本发明,并不用于限定本发明。
在本示例中,采用的数据中心的个数为15,时隙跨度t=50~100。设置每个计算节点需要0-4个gpu,1-10个cpu,2-32gb内存,5-10gb外存,每个计算节点的处理能力在16-66gb,每个时刻的训练数据集大小在100-600gb,并设置计算节点和参数服务器之间交换的参数在每个时刻(半天)内总共的大小为4.32-82.8gb,数据迁移的单位成本设置为0.01-0.02usd每gb,部署成本设置为0.05-0.1usd每gb,gpu,cpu,内存和外存的单位价格分别设置为1.2-9.6,0.13-0.24,0.01-0.1,0.01-0.1usd每gb,总额折扣设置为70%-80%,总额阈值设置在500-600,800-1000,1000-1050,1000-1050之间取随机。请参见图3a和3b,为采用本发明的调度方法与现有方法的对比结果,其中,图3a横坐标表示每个算法,分别为理想情况下最优算法opt,本发明的算法ours,集中式算法cen,本地训练式算法lo和oasis算法。纵坐标表示每个算法最后导致的代价总和,其中,同一个柱形的不同段标识的是总代价之和中的某一个代价分支的大小。图3a分为左半图和右半图,区别是每个时刻训练数据的大小,左半图的训练数据量在500gb-600gb之间,本发明的算法是在图中是ours,可以看出在两个情况下,均为本发明算法是在实际算法中总代价之和最少,并且总是最趋近于理想最优解。图3b横坐标表示每个时刻训练任务的数量,纵坐标表示和理想最优解的比值。可以看出无论训练任务数量如何变化,本发明的算法是最优的。
基于同一发明构思,本申请还提供了与实施例一中面向分布式机器学习任务的云资源在线调度方法对应的装置,详见实施例二。
实施例二
本实施例提供了一种面向分布式机器学习任务的云资源在线调度装置,请参见图4,该装置包括:
价格函数及数据量观测模块201,用于在每个时段的开始,观测出每个地理分布式数据中心各种资源的价格函数以及每个机器学习任务需要训练的数据量大小,其中,地理分布式数据中心用于放置计算节点和参数服务器,机器学习任务由用户提交,并且在每个时刻产生下个时刻每个任务需要训练的数据量,价格函数为
其中,h为资源使用量,
代价计算模块202,用于根据价格函数和数据量大小,计算出调度分布式机器学习任务过程中所产生的代价;
整数型线性规划表示模块203,用于将所有代价之和表示为成整数型线性规划;
松弛化模块204,用于将整数型线性规划松弛为线性规划,求出t时刻在数据中心r上放置的任务i的计算节点的数量,在t时刻在数据中心r上放置的任务i的参数服务器的数量对应的分数解;
调度方案求解模块205,用于对所述分数解采用独立取整方法,求出每个时刻每个机器学习任务的计算节点和参数服务器的部署方案、数据迁移方案,将其作为调度方案;
调度模块206,用于基于所述调度方案,进行在线调度。
在一种实施方式中,调度分布式机器学习任务过程中所产生的代价包括数据迁移代价、资源租用代价、部署代价和通信代价,代价计算模块具体用于执行下述步骤:
步骤s2.1:获取与调度相关的参数,具体包括:任务i的计算节点的处理能力为pi,任务i的计算节点需要的k类资源的数量为ni,k,任务i的参数服务器需要的k类资源的数量为mi,t,参数服务器和计算节点之间需要交换的参数大小为bi,在t时刻在数据中心r上放置的任务i的计算节点的数量为
步骤s2.2:根据单位数据迁移成本与迁移的数据量,表示数据迁移代价c1(t),其中,
步骤s2.3:根据用户任务所需要消耗的资源量和资源价格方程,表示出资源租用代价c2(t),其中,
步骤s2.4:根据上一时刻和当前时刻计算节点和参数服务器的部署情况来表示部署代价c3(t),其中,
步骤s2.5:根据部署方案表示出节点和参数服务器的通信代价c4(t),其中,
在一种实施方式中,整数型线性规划表示模块具体用于:
将数据迁移代价、资源租用代价、部署代价和通信代价相加表示为整数型线性规划,minimize∑t∈t(c1(t)+c2(t)+c3(t)+c4(t)),并构建约束条件,约束条件具体包括约束条件(1)~(11):
其中,i表示用户总数,t为总时长,r为地理分布式数据中心数量,
由于本发明实施例二所介绍的装置,为实施本发明实施例一中面向分布式机器学习任务的云资源在线调度方法所采用的装置,故而基于本发明实施例一所介绍的方法,本领域所属人员能够了解该装置的具体结构及变形,故而在此不再赘述。凡是本发明实施例一的方法所采用的装置都属于本发明所欲保护的范围。
实施例三
请参见图5,基于同一发明构思,本申请还提供了一种计算机可读存储介质300,其上存储有计算机程序311,该程序被执行时实现如实施例一中所述的方法。
由于本发明实施例三所介绍的计算机可读存储介质为实施本发明实施例一中面向分布式机器学习任务的云资源在线调度方法所采用的计算机设备,故而基于本发明实施例一所介绍的方法,本领域所属人员能够了解该计算机可读存储介质的具体结构及变形,故而在此不再赘述。凡是本发明实施例一中方法所采用的计算机可读存储介质都属于本发明所欲保护的范围。
实施例四
基于同一发明构思,本申请还提供了一种计算机设备,请参见图6,包括存储401、处理器402及存储在存储器上并可在处理器上运行的计算机程序403,处理器402执行上述程序时实现实施例一中的方法。
由于本发明实施例四所介绍的计算机设备为实施本发明实施例一中面向分布式机器学习任务的云资源在线调度方法所采用的计算机设备,故而基于本发明实施例一所介绍的方法,本领域所属人员能够了解该计算机设备的具体结构及变形,故而在此不再赘述。凡是本发明实施例一中方法所采用的计算机设备都属于本发明所欲保护的范围。
本领域内的技术人员应明白,本发明的实施例可提供为方法、系统、或计算机程序产品。因此,本发明可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本发明可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、cd-rom、光学存储器等)上实施的计算机程序产品的形式。
本发明是参照根据本发明实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
尽管已描述了本发明的优选实施例,但本领域内的技术人员一旦得知了基本创造性概念,则可对这些实施例做出另外的变更和修改。所以,所附权利要求意欲解释为包括优选实施例以及落入本发明范围的所有变更和修改。
显然,本领域的技术人员可以对本发明实施例进行各种改动和变型而不脱离本发明实施例的精神和范围。这样,倘若本发明实施例的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也意图包含这些改动和变型在内。
- 还没有人留言评论。精彩留言会获得点赞!