一种用于无线传感网异常数据检测的分层聚合方法与流程
本发明涉及一种异常数据检测方法,具体的说是一种异常数据检测的分层聚合方法。
背景技术:
根据可用数据背景知识的类型,异常检测机制一般可以分为三类方法。第一类方法不需要先验知识就能发现异常值,该方法一般使用聚类或者无监督学习方法,并假设能够很好地分离异常值与正常值。第二种是监督式异常检测,此方法需要一个所含数据已经被明确标记为正常值或者异常值的数据集。通过监督训练,训练有素的分类器能够获得将新数据分类为正常或异常的能力。如果系统中正常和异常数据的特征发生变化,则该方法要求分类器重新训练。第三种方法是半监督异常检测方法。这里分类器所采用到的训练数据集未被异常数据污染,根据这个训练器来识别异常。当数据可用时,可以逐步学习正常模型,以便适应数据分布的变化,然后检测得到的学习模型生成检验的测试实例的可能性。
目前国内外的已有的传感器网络的异常检测技术大致可分为如下几类:
基于密度的方法。
基于子空间与相关性的高维数据的孤立点检测。
一类支持向量机。
复制神经网络。
基于聚类分析的孤立点检测。
与关联规则和频繁项集的偏差。
数据集和参数的不同取值会极大的影响检测方法的性能,以上各种方法并无绝对的优劣之分,检测性能与具体的数据集以及参数取值有关。
下面介绍下最近几年基于数据聚类的异常检测方法。
数据聚类是找到相似数据点的群集的过程,聚类的结果能够使得每组数据点被很好的分离。基于数据聚类的异常检测基本都是首先将数据聚类,然后使用这些簇执行异常检测算法。
s.rajasegara提出了一种基于固定宽度聚类的算法,该算法为数据创建具有固定半径的球形簇。如果这些簇和其他簇的距离比较近,那么这些簇被标记为正常的数据点;反之,该方案将会标记其为异常。如果任何新的流量数据点落在正常簇之外,则它们被标记为异常。然而该方案的精确性受限于聚类半径的选取,而且作为集中式方案的一种,该方案会消耗大量的通信费用。
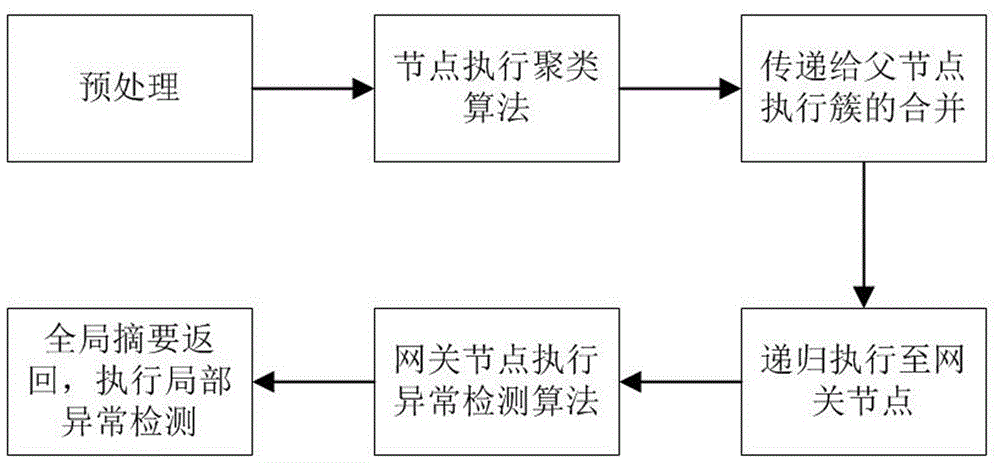
s.rajasegarar针对传感器网络提出了一种基于多层聚合的分布式异常数据检测技术,并提出了一种具有分层拓扑的无线传感器网络模型。在集中式方案中,每个传感器节点将收集到的数据全部传递给网关节点,网关节点根据收到的数据执行异常检测算法并返回异常簇摘要就能够将异常数据区分。在提出的分布式方法中,传感器节点对自身收到的数据进行聚类操作产生本地簇群,聚类算法采用最简单的基于宽度的聚类,传感器节点然后将簇群的摘要合并信息发送到其各自的父节点,因此可以缩减用于数据传递的能量消耗。该过程迭代执行直到网关节点。在网关节点处,根据收到的簇群摘要集作为数据,执行异常簇群检测算法,以将簇标记为正常或异常。但是该方案同样存在一个参数难以确定的问题,而且随着迭代的进行,会产生累计误差。
技术实现要素:
本发明的目的是提供一种用于无线传感网异常数据检测的分层聚合方法,结合k-means++算法,簇群合并算法以及基于knn的异常检测算法,实现较高的检测效率以及较低的能量消耗,显著地降低了数据通信对无线传感器网络的影响,能够满足无线传感器节点带宽、能量等各方面受限的特点。
本发明提供一种用于无线传感网异常数据检测的分层聚合方法,将代表底层节点的簇摘要向上传递,由父节点进行簇群合并,最后迭代执行直到最顶层的网关节点,网关节点执行异常簇的检测,将分辨出异常簇和正常簇,根据正常簇的数据,计算一个用于局部异常检测的阈值数据返回至其他节点,从而在底层节点识别全局异常值。
作为本发明的进一步限定,所述簇摘要的获取方法为:将标准化的检测数据向量用k-means++算法进行聚类,得到各个簇的摘要信息,对于簇ci,其摘要为:
作为本发明的进一步限定,所述簇群合并的具体方法为:将上述摘要信息
step.1对于父节点收到的簇的摘要
step.2若dis(ci,cj)>w,不执行合并操作,将簇的摘要信息继续向上传递,得到簇中心点彼此之间的距离构成的矩阵,将矩阵中元素与w比较,如果dis(ci,cj)<<w,则执行step.1,否则执行step.3;
step.3将得到的簇的摘要信息继续逐层上传直至网关节点,中间由父节点执行簇合并算法,网关节点执行k近邻算法,算出距离当前考虑聚类中心较近的k个簇中心的加权距离的平均值,与特定阈值进行比较,找到异常的簇。
作为本发明的进一步限定,所述异常簇检测算法具体为:
定义簇ci与其他簇的亲近度为:
将异常簇定义为
然后综合正常簇的摘要信息,计算出全局摘要信息
本发明采用以上技术方案与现有技术相比,具有以下技术效果:本发明以无线传感器网络异常数据检测为基础,对已有的hscbd算法进行改进,提出了基于k-means++的聚类算法,然后对簇合并算法提出了改进,通过人工构造的高斯数据集以及真实环境收集到的数据集论证了本发明的技术方案能够实现很高的异常数据检测率,并且该技术方案在能量损耗方面有极大地降低。
附图说明
图1为本发明的工作流程图。
图2为本发明中簇合并的原理图。
图3为本发明中分布式方案全局异常数据检测示意图。
图4为人造高斯数据集分布示意图。
图5为hscbd方案检测效果图(高斯数据集)。
图6为a_hscbd方案检测效率图(高斯数据集)。
图7为a_hscbd检测效率图(k=14,高斯数据集)。
图8为hscbd与a_hscbd两种方案的通信费用节省率(高斯数据集)。
图9为因特尔伯克利实验室节点分布图。
图10为取样数据的散点分布。
图11为hscbd方案检测效率(ibrl数据集)。
图12为a_hscbd方案检测效率(ibrl数据集)。
图13为hscbd与a_hscbd两种方案的通信费用节省率(ibrl数据集)。
具体实施方式
下面结合实施例和附图对本发明的技术方案做进一步的详细说明:
实施例
1.数据预处理
在t时刻,每个传感器节点si测得一个特征向量
无线传感器网络内的数据在使用前需要进行预处理,把数据转换成适用于基于距离簇的形式,通常来说,计算两个数据向量x1,x2之间的距离使用欧式距离dis(x1,x2)。然而传感器节点不同维特征向量经常处于不同的动态范围,因此将每个数据向量vkj(k为时间,j代表测量数据的第j维)转换成其标准形式:ukj=(vkj-uvj)/σvj,其中uvj和σvj分别是数据特征向量vkj的平均值和标准差。进一步的每个特征向量可以标准化到[0,1],
2.基于k-means++算法的簇的划分
将上环节中经过预处理过后的数据进行聚类操作,本发明采用基于k-means++算法的聚类,可以在节点级别得到簇集的划分,以及簇的摘要;
算法的基本描述如下:
输入:标准化后的测量向量dataset,聚类中心的数量k
输出:每个节点的簇的摘要digest,以及簇集c={cr:r=1...nc}
3.迭代式簇合并算法
如果两个簇的中心间欧几里得距离小于给定阈值w,则将这两个簇进行合并操作,如图2所示;
算法mergecluster(cm)基本描述如下:
输入:簇群c={cr:r=1...nc},合并阈值w
输出:合并后的簇集cm
4.基于knn的异常簇检测方案
各个簇根据网关节点返回的信息,执行局部异常检测算法;将簇群中所包含的数据算出与之对应的簇中心的距离,将该距离与从全局摘要中的得到的
图3为通过
5.性能分析
实验环境为intel(r)core(tm)i3-2370mcpu@2.40ghz,windows10操作系统,整个实验基于python2.7实现。
5.1基于人工构造的高斯数据集的仿真分析
第一个数据集为人工构造的高斯数据集,该数据集有两个特征向量,每个特征向量均服从正态分布,该正态分布的均值随机选自[0.3,0.35,0.45],标准差为0.03,然后给每个特征向量引入噪声(异常),异常数据点为[0.5,1]上的均匀分布,此高斯数据集由10个传感器节点的数组组成,每个节点包含100个正常数据以及5个异常数据,数据需要先标准化到[0,1]区间以供使用。由于该数据集不含传感器节点的拓扑信息,所以建立单层网络结构。
该高斯数据集分布如下图4所示,左下角部分为正常的正太分布数据,右上角稀疏数据为异常数据点,该数据集为二维向量组成,分别为temperature和humidity。
检测率(dr)是指根据异常检测算法检测出的异常数据个数占实际异常数据总个数的比例。误报率(fpr)是指被算法误判为异常值的正常数据个数占实际正常数据总量的比例。
rajasegarars提出的hscbd检测方案的检测效率如图5所示。由图可知当w∈[0.05,0.018]的时候,该算法有着较高的检测率以及较低的误报率。当w∈[0.03,0.04]时,异常数据点可能会被划分到正常数据簇群内,从而影响检测效率,并且导致较高的误报率。可见hscbd方案对w参数比较敏感。
基于高斯数据集,利用控制单一变量法,聚类数量k从[5,30]中取值,得到图6,从该图中看出当k∈[13,15],改进的a_hscbd方案同样能够实现较高的检测效率,当k取为14时,得到如图7的检测图像,从图7可知,该方案能够实现与hscbd相当的检测效率,另外基于数据总量以及聚类操作得到的簇群的数量,可以衡量hscbd与a_hscbd相对于集中式方案所能够实现的通信费用节省率。
由图8可知改进后的a_hscbd方法能够实现较高的通信费用节省率。从图中可以看出,改进后的方案比hscbd方案相比进一步提高了通信费用节省率。
5.2基于ibrl数据集的仿真分析
第二个数据集为真实环境中收集的数据,来自美国加利福尼亚州的因特尔伯克利实验室;收集该数据的传感器节点部署于室内环境,图9为该实验室传感器节点的分布图,传感器以31秒的间隔收集五个测量值:温度、光强、温度相对湿度、电压(单位为伏特)和拓扑信息;由于数据量巨大,只研究一个四小时的时间窗口(2004年3月1日的0:00:00-03:59:59)。由于节点5和15不包含任何数据,则忽略不计,利用该数据中的拓扑信息结合簇头选举策略进行分层,可得到比较节省能量的网络分层结构。图10为该实验数据的散点图分布,将明显孤立的区域标记为异常数据,用于进行检测率的判断。图11为hscbd方案基于ibrl数据的仿真结果,根据图可以看出,当w∈[0.005,0.019]时,hscbd方案实现了较好的检测结果,异常数据检测率达到96%以上,同时误报率fpr也比较低;图12为a_hscbd方案基于ibrl数据集的仿真结果,根据图像可以看出,当w∈[0.013,0.015]时,a_hscbd方案的检测效率与hsbcs方案相比有了进一步的提高,检测率达到98%以上,并且误报率fpr也比较低。
由于集中式方案的主要缺点是通信消耗比较高,所以图13给出了hscbd方案与a_hscbd方案相对于集中式方案的能量节省率的对比,从图13可以看出,文中提出的a_hscbd方案与hscbd方案相比,能量节省率有了进一步提高。
为了避免一次实验对于提出方案的精确性的影响,该方案进行了10次,最后得出了如表1的两种实现方案实验结果的对比;由表1可知,改进式a_hscbd方案与集中式方案、hscbd方案相比,检测效率都有所提升。
表1.hscbd与a_hscbd方案十次平均检测效率对比
综合分析可知,本文提出的改进式a_hscbd方案,与集中式方案和hscbd方案相比,实现了检测效率的提升和通信效率的提升,但是由于聚类算法k的确定,需要一个学习过程,在时间复杂度上有所提高。
该方案以ibrl实验室收集到的数据为基础,建立了一个分层聚合的无线传感器网络模型,将底层节点收到的数据先进行聚类处理,提出了一种新型簇群合并的方法,然后所有簇摘要信息传送至网关节点执行基于knn的异常检测算法进行异常簇识别,最后将网关节点得到的正常簇信息发送至其他节点,进行分布式的异常数据检测,通过仿真实验可知本发明提出的技术方案的检测效率可达到98%,且与传统的方案相比实现显著地能量消耗的节省。
以上所述,仅为本发明中的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉该技术的人在本发明所揭露的技术范围内,可理解想到的变换或替换,都应涵盖在本发明的包含范围之内,因此,本发明的保护范围应该以权利要求书的保护范围为准。
- 还没有人留言评论。精彩留言会获得点赞!