一种共生网络中用户关联的方法与流程
本发明属于无线通信技术领域,涉及一种共生网络中基于深度强化学习的用户关联的方法。
背景技术:
物联网(iot)设备数量的指数增长将导致未来对无线频谱和网络基础设施的巨大需求。为了支持大规模iot设备连接,这非常需要设计一种频谱,能源和基础设施高效的通信技术。共生无线电(sr)被是一种可行的解决方案,在sr中,iot传输寄生在传统网络中。特别地,iot设备通过反射从传统发射机接收的信号来发送它们的消息,而不需要有源射频(rf)链。这意味着物联网设备的数据传输使用无源无线电技术,并且不需要专用频谱和基础设施。
sr系统有三个节点:rf源,iot设备和接收机。iot设备通过改变反射系数来反射环境rf源信号来将信息传输到接收机。接收机接收两种类型的信号:来自rf源的直接链路信号和来自iot设备的反向散射链路信号。反向散射链路信号包含rf源消息,并且iot设备的传输速率低于传统系统的传输速率,这意味着反向散射链路可以被视为传统传输的附加路径,来提高传统通信系统的性能。因此sr系统可以实现传统通信系统和iot通信的互利共生。
技术实现要素:
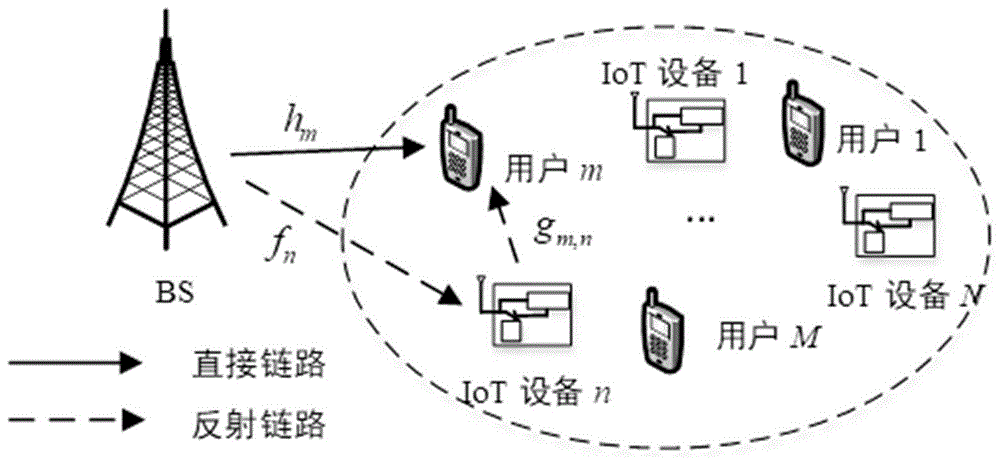
本发明考虑蜂窝网络和iot网络的共生模型,本发明设计了如图1所示的共生网络,蜂窝网络中的基站(bs)服务m个蜂窝用户,而iot网络中的n个iot设备通过反射来自bs的接收信号来将它们的消息发送到相关的蜂窝用户。本发明设计了在此sr网络中的传输协议,如图2所示,bs通过时间多址接入(tdma)的方式服务多个蜂窝用户,iot设备仅在一个关联的时隙中发送信息。蜂窝用户使用连续干扰消除(sic)策略对来自bs和相关联的iot设备信号进行解码。
在此sr网络中,所有的信道由两部分组成:大尺度衰落和小尺度衰落。如图1所示,在sr中,
其中m=1,…,m,n=1,…,n并且
bs在一帧中的一个时隙给用户m传输的信息为xm,iot设备n将自己的信息cn传送给关联的蜂窝用户,本发明假定iot设备的传输周期是bs传输周期的k倍。则用户m接收到的信号可以写为
其中p是bs的传输功率,αn表示iot设备n的反射系数,um表示用户m端的复高斯噪声,服从分布
蜂窝用户采用sic方式解码自己的信号和关联的iot设备的信号,由于来自基站的直接链路能量强于反射链路,因此在接收端先解调蜂窝用户自己的信号,然后在根据能量强弱解调相关联的iot设备信号。定义
本发明目标是找出一种有效的用户关联方案使所有蜂窝用户的速率和最大,即
其中
中心式深度强化学习的的奖励函数(rewardfuction)为
中心式深度强化学习在第t帧的状态(state)为
其中
其中bn∈{1,…,m}表示与iot设备n关联的蜂窝用户的标号,动作空间大小为mn。
分布式深度强化学习中的深度q-网络是针对每一个iot设备,决策既可以在bs做,也可以在iot设备端做,因此分布式深度强化学习的动作(action)为
分布式深度强化学习的在第t帧关于iot设备n的状态
其中
分布式深度强化学习的的奖励函数(rewardfuction)为
其中
本发明的有益效果在于,本发明不需要实时得到所有链路的信道信息,而是根据历史信息进行预测当前决策的有效信息,进而得到使所有iot设备合速率最大的用户关联策略。
附图说明
图1示出了本发明中的sr网络模型;
图2示出了本发明中sr网络中蜂窝通信和iot通信的帧结构;
图3示出了本发明中的中心式深度强化学习决策和信息交互流程;
图4示出了本发明中的分布式深度强化学习决策和信息交互流程;
图5示出了本发明提出的基于两种深度强化学习的用户关联方案和其他用户关联方案的性能对比;
图6出了本发明提出的基于分布式深度强化学习用户关联方案在iot设备数目发生变化时的性能。
具体实施方式
图1示出了本发明中的sr网络模型。本发明考虑蜂窝网络和iot网络的共生模型,蜂窝网络中的基站(bs)服务m个蜂窝用户,而iot网络中的n个iot设备通过反射来自bs的接收信号来将它们的消息发送到相关的蜂窝用户。在此sr网络中,所有的信道由两部分组成:大尺度衰落和小尺度衰落。如图1所示,在sr中,
其中m=1,…,m,n=1,…,n并且
图2示出了本发明中sr网络中蜂窝通信和iot通信的帧结构。bs通过时间多址接入(tdma)的方式服务多个蜂窝用户,iot设备仅在一个关联的时隙中发送信息。蜂窝用户使用连续干扰消除(sic)策略对来自bs和相关联的iot设备信号进行解码。bs在一帧中的一个时隙给用户m传输的信息为xm,iot设备n将自己的信息cn传送给关联的蜂窝用户,本发明假定iot设备的传输周期是bs传输周期的k倍。则用户m接收到的信号可以写为
其中p是bs的传输功率,αn表示iot设备n的反射系数,um表示用户m端的复高斯噪声,服从分布
蜂窝用户采用sic方式解码自己的信号和关联的iot设备的信号,由于来自基站的直接链路能量强于反射链路,因此在接收端先解调蜂窝用户自己的信号,然后在根据能量强弱解调相关联的iot设备信号。定义
本发明目标是找出一种有效的用户关联方案使所有蜂窝用户的速率和最大,即
其中
图3示出了本发明中的中心式深度强化学习决策和信息交互流程。bs根据ε-贪婪策略做出决策ac(t)。iot设备基于来自bs的决策来接入相关联的蜂窝用户。并且蜂窝用户解码相关联的iot设备信号并将所有有用和可用信息,即rc(t)和sc(t+1)反馈给bs。然后,bs将经验数据存储到存储器d中,并随机地对d中的经验数据进行小片采样以训练深度q-网络。ε-贪婪策略是指以ε概率采取随机决策,以1-ε概率采取深度q-网络获得的结果。
中心式深度强化学习的的奖励函数(rewardfuction)为
中心式深度强化学习在第t帧的状态(state)为
其中
其中bn∈{1,…,m}表示与iot设备n关联的蜂窝用户的标号,动作空间大小为mn。
图4示出了本发明中的分布式深度强化学习决策和信息交互流程。蜂窝用户、iot设备和bs之间的信息传递与中心式drl算法相同,在分布式深度强化学习中,bs需要分配n个计算单元来为分布式深度强化学习算法中的n个iot设备做出决策。另外,在分布式深度强化学习算法中,在训练深度q-网络之后,bs将更新的深度q-网络权重传递给每个计算单元。然后,n个计算单元根据相应的状态分别为n个iot设备做决策。
分布式深度强化学习中的深度q-网络是针对每一个iot设备,决策既可以在bs做,也可以在iot设备端做,因此分布式深度强化学习的动作(action)为
分布式深度强化学习的在第t帧关于iot设备n的状态
其中
分布式深度强化学习的的奖励函数(rewardfuction)为
其中
下面,本发明将根据仿真结果来阐述本发明提出方案的性能。首先,在一个100米乘100米区域内,bs位于该区域的中心,在距离bs10-100米的距离内均匀分布生成蜂窝用户的位置,并且iot设备则均匀分布的随机放置在距离蜂窝用户0~50米的距离内。设定bs的发射功率为p=40dbm,背景噪声功率为σ2=-114dbm。路径损耗模型为32.45+20log10(f)+20log10(d)-gt-gr(以db为单位),其中f(mhz)是载波频率,d(km)是距离,gt表示发射天线增益,gr表示接收天线增益。本发明设置f=1ghz,gt=gr=2.5db。并且αn=α=0.8,k=50。两个深度强化学习算法使用tensorflow实现,ε=0.4,并且从0.4线性减少到0。
图5示出了本发明提出的基于两种深度强化学习的用户关联方案和其他用户关联方案的性能对比。两种对比算法为随机策略和最优策略。在随机策略中,每个iot设备将随机与蜂窝用户相关联。在最优策略中,假设bs知道完美的全实时信道信息,并通过搜索方式获得最优策略。设置ρ=0.5,m=n=3。可以看出,中心式深度强化学习算法和分布式深度强化学习算法几乎可以逼近最优和传输速率。并且,中心式深度强化学习算法大约在2000帧收敛,而分布式drl算法大约在5000帧收敛。中心式深度强化学习收敛更快一些。
图6出了本发明提出的基于分布式深度强化学习用户关联方案在iot设备数目发生变化时的性能,其中ρ=0.5,m=3。若iot设备的数量增加,分布式drl算法几乎可以达到或接近最优策略,并且总是优于随机策略。当环境以相对动态的方式变化时,该图验证了所提出的分布式drl算法的可扩展性。
- 还没有人留言评论。精彩留言会获得点赞!