一种电力光网络主动式负载均衡方法与流程
本发明涉及电力光网络通信技术领域,特别是涉及电力光网络主动式负载均衡方法。
背景技术:
随着国家智能电网及新能源互联网的整体建设与发展,电力新业务流量也在倍速增长,对整个电力通信网的实时性和可靠性提出了更高要求。而不同电力业务在不同传输通道上的负载也不相同,例如在某些热点地区,往往会聚集比其他地区更多的用户。这种用户在电力通信网中的分布不均使得电力业务在一些通道上出现过载情况,而在另一些通道上贼出现空闲状态。这会导致热点地区的用户可能由于电力光网络无法及时提供足够的资源而遭遇恶劣的服务体验。为了改善用户的服务质量,同时更充分地利用负载较轻的基站的空闲资源,需要使用业务负载均衡技术来对电力光网络业务进行调整,改善网络整体的负载均衡状态。
因此希望有一种电力光网络主动式负载均衡方法以解决现有技术中存在的问题。
技术实现要素:
本发明公开了一种电力光网络主动式负载均衡方法,所述负载均衡方法包括以下步骤:
步骤1:根据家族优生学算法和神经网络算法对电力光网络的业务进行预测;
步骤2:进行光纤链路负载状态分析;
步骤3:使用时间序列分析模型对基站的历史负载状态记录进行分析,网络预测到新业务即将到来时,通过资源分配策略优化网络的负载均衡。
优选地,所述步骤1进一步包括:利用所述家族优生学算法和神经网络算法建决策树模型预测将来时刻的业务流量及业务的持续时间。
优选地,所述步骤2根据所述将来时刻的业务流量及业务的持续时间,对当前所有链路的负载进行分析,分离出重负载,轻负载和中度负载链路集合并分别进行标记。
优选地,所述步骤2中所有链路的总负载计算公式如下:
其中,h为所有链路的总业务量,wi为每条链路上的链路,f(ti)是每条链路业务量与时间ti的函数。
优选地,所述步骤3的资源分配策略是根据负载状态对链路进行等级划分,根据业务是否处于重负载链路,判定是否启动负载均衡。
本发明通过对电力光网络业务进行移动性预测,分析目标周围的负载状态,提前制定合理的资源分配方案,优化网络的负载均衡,本发明电力光网络主动式负载均衡方法的有益效果包括:
(1)本发明着重于未来业务的流量预测,能够较早地解决相关的网络负载问题,避免出现链路堵塞;
(2)本发明方法通过对电力光网络业务的持续性时间进行周期性预测,能够分析出整体网络的业务特性及发展趋势;
(3)本发明方法综合考虑网络整体负载状态变化,提前制定资源分配策略,实现了对网络负载均衡的优化,满足热点地区用户的服务需求,改善了网络性能。
附图说明
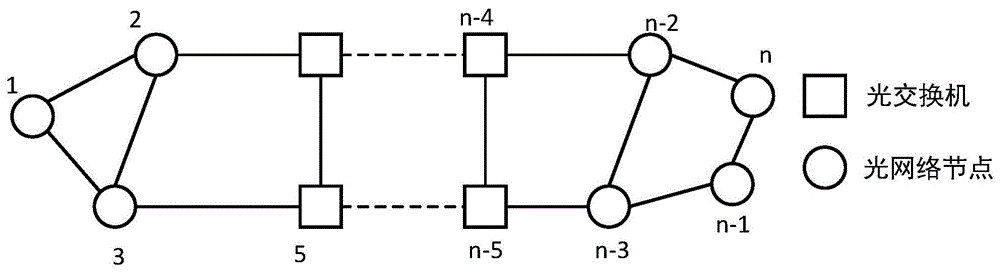
图1是电力光网络节点示意图。
具体实施方式
实施例:
步骤1:家族优生学及神经网络算法对电力光网络的业务预测:
本发明方法在对用户的移动性预测过程中,利用家族优生学算法及神经网络算法,研究比较链路上此前状态对未来状态的影响,选择最佳的业务量输入属性特征,提高移动性预测准确率。本发明通过对业务量的流动性进行分析,挖掘其中的规律,可以对链路下一时刻的业务量做出预测。其次,通过给链路进行合理的负载均衡从而优化整个网络的性能。然后,提前制定资源分配策略,优化网络的负载均衡,改善热点地区的网络性能,提高用户服务体验。
业务的预测阶段中,考虑到神经网络能比较好的处理大时间尺度和小时间尺度的数据共同的影响,家族优生学能提供最好的流量输出,所以以神经网络及家族优生学来作为本次研究的主要算法。
传统的神经网络,模型存在“只关注当前时刻”的问题,而忽略了对过去时刻的应用,和对未来时刻的预测。在这样的场景下,可借用家族优生学融合神经网络来记住各个时刻的信息。
电力光网络被抽象为如图1所示的拓扑结构,节点集合包括n-1(1,2,3……n-1)个节点和一个目的节点n,边集合是具有邻接关系节点构成的光纤链路集。图中每个光节点均连接了多个用户负载,并经过多跳传输将用户信息传递到目的节点。光纤节点之间存在一条光纤链路则称该两个节点具有邻接关系,这条链路属于光纤链路集介。节点i能够覆盖到的节点为i的邻居节点集介为ni={j|(i,j)∈e}。节点i的候选节点集合为si,是ni的子集。
本发明基于家族优生学及神经网络算法构建决策树模型,来预测下一个业务的流量。在建立决策树模型时,首先需要输入当前状态中的业务量及其特性,目标属性是下一时刻的业务流量与特性。在周期性的统计和预测中,可得出当前链路的业务的流量wn和当前业务的持续时间ti,则可得出各个时间点的流量wi{w1,w2,…,wi-1,wi,…},结合马尔可夫模型的思想,研究此前几个业务状态对预测准确率的影响。二阶马尔可夫模型考虑了此前两个状态对未来位置的影响,它的预测准确率更高。因此,在较低的算法复杂度下,尽量地提高预测准确率,选择用户此前的2个状态作为训练特征,建立决策树模型。预测将来时刻的业务流量wn+1及业务一时刻的业务流量及持续时间后,需要对当前所有链路si的负载进行分析,分离出重负载,轻负载,中度负载链路集合并分别进行标记。
此时,所有链路的总负载计算公式如下
其中,h为所有链路的总业务量,wi为每条链路上的链路,f(ti)是每条链路业务量与时间ti的函数。
即当前时刻的业务量是与时间节点有关的函数。
时间序列分析是使用历史数据,通过统计分析了解其发展规律,并进一步对未来的发展趋势做出预测。arima模型是时间序列分析中一种重要的分析方法,且预测精度较高。arima模型包含3种形式,自回归ar模型、移动平均ma模型和两者的混合自回归移动平均arma模型。在使用arma模型时,需要保证要分析的对象是平稳的时间序列。如果序列非平稳,则需要先进行差分,得到平稳序列,否则无法应用该模型。而arima模型中的“i”就代表序列的平稳性。
假设yt是一个平稳时间序列,那么对应的p阶ar(p)模型可以表示为:
yt=α1yt-1+α2yt-2+…+αpyt-p+ε(t)
其中,p为模型的自回归项,αi(i=1,2,…p)是自回归参数,ε(t)是随机误差项。y(t)表示一个平稳的时间序列。t表示第t个时刻。
对应的q阶ma(q)模型可以表示为:
yt=ε(t)-θ1ε(t-1)-θ2ε(t-2)-…-θqε(t-q)
其中,q为模型相应的移动平均项数,θj(j=1,2,…,q)为移动平均参数,ε(t-j)表示第q个预测平均项的随机误差。
将ar(p)模型和ma(q)模型结合,即可得到arma(p,q)模型,表示为:
arma(p,q)模型可以用以下形式来表示:
αp(b)y(t)=θq(b)ε(t)
αp(b)=1-α1b1-…-αpbp
αq(b)=1-θ1b1-…-θpbp
其中,bk为k步滞后算子,αp(b)是一个p阶自回归多项式,θq(b)是一个q阶移动平均多项式。
ar(p)、ma(q)和arma(p,q)模型的对象都必须是一个平稳的时间序列。本发明中,将单条链路的负载情况作为研究对象。在步骤1预测到下一时刻该链路上的业务时,将这种周期性的预测数据所为一个随机序列,设为业务负载量x(t)。若x(t)为一个平稳的时间序列,则直接将x(t)作为y(t),利用arima模型进行仿真预测。若x(t)是一个非平稳的时间序列,需要先将它转换为一个平稳的时间序列。如果x(t)经过d阶差分后得到序列y(t),y(t)为平稳时间序列。那么对y(t)建立arma(p,q)模型,即为x(t)的arima(p,d,q)模型,表示为:
αp(b)(1-b)dx(t)=θq(b)ε(t)
步骤3,属于负载均衡优化状态,针对步骤2中的预测因子,使用arima模型对基站的历史负载状态记录进行分析,当网络预测到新业务即将到来,然后通过制订合理的资源分配策略,优化网络的负载均衡。
本发明方法首先综合考虑全部链路的负载状态,然后根据负载状态对链路进行等级划分,然后考虑业务是否处于较重的负载链路上,并决定是否要启动负载均衡措施。
由于每条链路都有其相应的业务流门限,因此假设全部网络的链路资源总量为r,当前医用资源为s,则链路的负载状态为:
假设整个网络有n条链路,则整体的网络负载状态为:
为了使网络的负载更加均衡,各个链路和网络整体的负载状态之间的差的绝对值越小,则表示单个链路与整体状态的偏离更小。参考数学中方差的概念,分别对各个基站与网络整体负载的求差值,然后取所有差值的平方和,能够反映各个基站相比于网络平均负载的偏离情况。
得出平均负载之后,剔除重负载链路,对新业务在新子网中进行路由传输。
最后需要指出的是:以上实施例仅用以说明本发明的技术方案,而非对其限制。尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
- 还没有人留言评论。精彩留言会获得点赞!