一种语音唤醒方法、语音唤醒装置及耳机与流程
本发明实施例涉及语音唤醒技术领域,尤其涉及一种语音唤醒方法、语音唤醒装置及耳机。
背景技术:
耳机(earphones;headphones;head-sets;earpieces)是一对转换单元,它接受媒体播放器或接收器所发出的电讯号,利用贴近耳朵的扬声器将其转化成可以听到的音波。耳机可通过插头、蓝牙等方式与媒体播放器连接,好处是在不影响旁人的情况下,可独自聆听音响;亦可隔开周围环境的声响,对在录音室、dj、旅途、运动等在噪吵环境下使用的人很有帮助。耳机原是给电话和无线电上使用的,但随着可携式电子装置的盛行,耳机多用于手机、随身听、收音机、可携式电玩和数位音讯播放器等。
随着耳机技术的发展,耳机还常用于语音唤醒终端的功能。现有技术中,实现耳机的语音唤醒功能,通常会采集到除了耳机佩戴者以外的用户的语音,从而造成误判。
技术实现要素:
本发明实施例的一个目的是提供一种能降低语音唤醒误判率的语音唤醒方法、语音唤醒装置及耳机。
第一方面,本发明实施例提供了一种语音唤醒方法,应用于耳机,所述方法包括:
获取唤醒语音信息及检测所述耳机佩戴者发声所产生的振动信息;
当所述唤醒语音信息与预设唤醒语音信息匹配,且所述振动信息满足预设条件时,生成唤醒指令。
可选地,在所述语音检测模式下,获取唤醒语音信息及检测所述耳机佩戴者发声所产生的振动信息之前,还包括:
实时获取触发语音信息,根据所述触发语音信息确定是否触发语音检测模式。
可选地,所述实时获取触发语音信息,根据所述触发语音信息确定是否触发语音检测模式,包括:
提取所述触发语音信息的能量;
判断所述能量是否大于预设的能量阈值;
若是,则触发语音检测模式成功,跳转获取唤醒语音信息及检测所述耳机佩戴者发声所产生的振动信息该步骤;
若否,则触发语音检测模式失败。
可选地,所述唤醒语音信息与预设唤醒语音信息匹配,包括:
判断所述唤醒语音信息是否匹配预设唤醒语音信息。
可选地,所述预设唤醒语音信息为预设唤醒关键词;
所述判断所述唤醒语音信息是否匹配预设唤醒语音信息,包括;
检测所述唤醒语音信息是否包括与预设唤醒关键词匹配的词语;
若是,则确定所述唤醒语音信息与预设唤醒信息匹配;
若否,则唤醒终止。
可选地,所述振动信息满足预设条件,包括:
判断所述振动信息是否满足预设条件。
可选地,所述预设条件为振动信息的频率大于预设振动频率阈值;
所述判断所述振动信息是否满足预设条件,包括:
若所述振动信息的频率大于预设频率阈值时,则确定所述振动信息满足预设条件;
若所述振动信息频率阈值小于或等于预设频率阈值,则确定所述振动信息不满足预设条件。
可选地,在所述当所述唤醒语音信息与预设唤醒语音信息匹配,且所述振动信息满足预设条件时,生成唤醒指令之前,所述方法还包括:
验证所述唤醒语音信息与振动信息是否匹配;
若是,在跳转所述当所述唤醒语音信息与预设唤醒语音信息匹配,且所述振动信息满足预设条件时,生成唤醒指令该步骤;
若否,唤醒终止。
可选地,所述验证所述唤醒语音信息与振动信息是否匹配,包括:
提取所述唤醒语音信息与振动信息的波形;
判断所述唤醒语音信息与振动信息的波形是否匹配;
若是,则确定所述唤醒语音信息与振动信息匹配;
若否,则确定所述唤醒语音信息与振动信息不匹配。
可选地,所述方法还包括:
实时获取所述耳机佩戴者发声所产生的振动信息;或者,
在所述语音检测模式下,获取所述耳机佩戴者发声所产生的振动信息。
第二方面,本发明实施例还提供了一种语音唤醒装置,应用于耳机,所述装置包括:
获取模块,用于获取唤醒语音信息及检测所述耳机佩戴者发声所产生的振动信息;
生成模块,用于当所述唤醒语音信息与预设唤醒语音信息匹配,且所述振动信息满足预设条件时,生成唤醒指令。
可选地,所述装置还包括:
确定模块,用于实时获取触发语音信息,根据所述触发语音信息确定是否触发语音检测模式;
所述确定模块具体用于提取所述触发语音信息的能量;判断所述能量是否大于预设的能量阈值;若是,则触发语音检测模式成功,跳转获取唤醒语音信息及检测所述耳机佩戴者发声所产生的振动信息该步骤;若否,则触发语音检测模式失败。
可选地,所述装置还包括:
第一判断模块,用于判断所述唤醒语音信息是否匹配预设唤醒语音信息;
所述第一判断模块具体用于检测所述唤醒语音信息是否包括与预设唤醒关键词匹配的词语;若是,则确定所述唤醒语音信息与预设唤醒信息匹配;若否,则唤醒终止;
第二判断模块,用于判断所述振动信息是否满足预设条件;
所述第二判断模块具体用于若所述振动信息的频率大于预设振动频率阈值,则确定所述振动信息满足预设条件;
若所述振动信息小于或等于预设频率阈值,则确定所述振动信息不满足预设条件。
可选地,所述装置还包括:
验证模块,用于验证所述唤醒语音信息与振动信息是否匹配;若是,在跳转所述当所述唤醒语音信息与预设唤醒语音信息匹配,且所述振动信息满足预设条件时,生成唤醒指令该步骤;若否,唤醒终止;
所述验证模块具体用于提取所述唤醒语音信息与振动信息的波形;判断所述唤醒语音信息与振动信息的波形是否匹配;若是,则确定所述唤醒语音信息与振动信息匹配;若否,则确定所述唤醒语音信息与振动信息不匹配。
可选地,所述装置还包括:
第二获取模块,用于实时获取所述耳机佩戴者发声所产生的振动信息;或者,在所述语音检测模式下,获取所述耳机佩戴者发声所产生的振动信息。
第三方面,本发明实施例还提供了一种耳机,包括:
至少一个处理器;以及,
与所述至少一个处理器通信连接的存储器;其中,
所述存储器存储有可被所述至少一个处理器执行的指令,所述指令被所述至少一个处理器执行,以使所述至少一个处理器能够执行上述语音唤醒方法。
第四方面,本发明实施例提供一种存储介质,所述存储介质存储有可执行指令,所述可执行指令被智能终端执行时,使所述智能终端执行如上所述的语音唤醒方法。
第五方面,本发明实施例还提供了一种程序产品,所述机程序产品包括存储在存储介质上的程序,所述程序包括程序指令,当所述程序指令被智能终端执行时,使所述智能终端执行如上所述的语音唤醒方法。
本发明实施例提供的语音唤醒方法、语音唤醒装置和耳机,通过获取唤醒语音信息及检测所述耳机佩戴者发声所产生的振动信息;当所述唤醒语音信息与预设唤醒语音信息匹配,且所述振动信息满足预设条件时,生成唤醒指令。该方法只有同时满足唤醒语音信息与耳机佩戴者发声所产生的振动信息这两个条件时,所述耳机才产生唤醒指令进行唤醒动作,能够降低因佩戴者以外的用户的语音信息产生的误判率,提高了语音唤醒的准确率。
附图说明
一个或多个实施例通过与之对应的附图中的图片进行示例性说明,这些示例性说明并不构成对实施例的限定,附图中具有相同参考数字标号的元件表示为类似的元件,除非有特别申明,附图中的图不构成比例限制。
图1是本发明语音唤醒方法和语音唤醒装置的应用场景示意图;
图2是本发明语音唤醒方法的一个实施例的流程图;
图3是本发明语音唤醒方法的一个实施例的流程图;
图4是本发明语音唤醒方法的一个实施例的流程图;
图5是本发明语音唤醒方法的一个实施例的流程图;
图6是本发明语音唤醒方法的一个实施例的流程图;
图7是本发明语音唤醒方法的一个实施例的流程图;
图8是本发明语音唤醒装置的一个实施例的结构示意图;
图9是本发明语音唤醒装置的一个实施例的结构示意图;
图10是本发明实施例提供的耳机的硬件结构示意图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
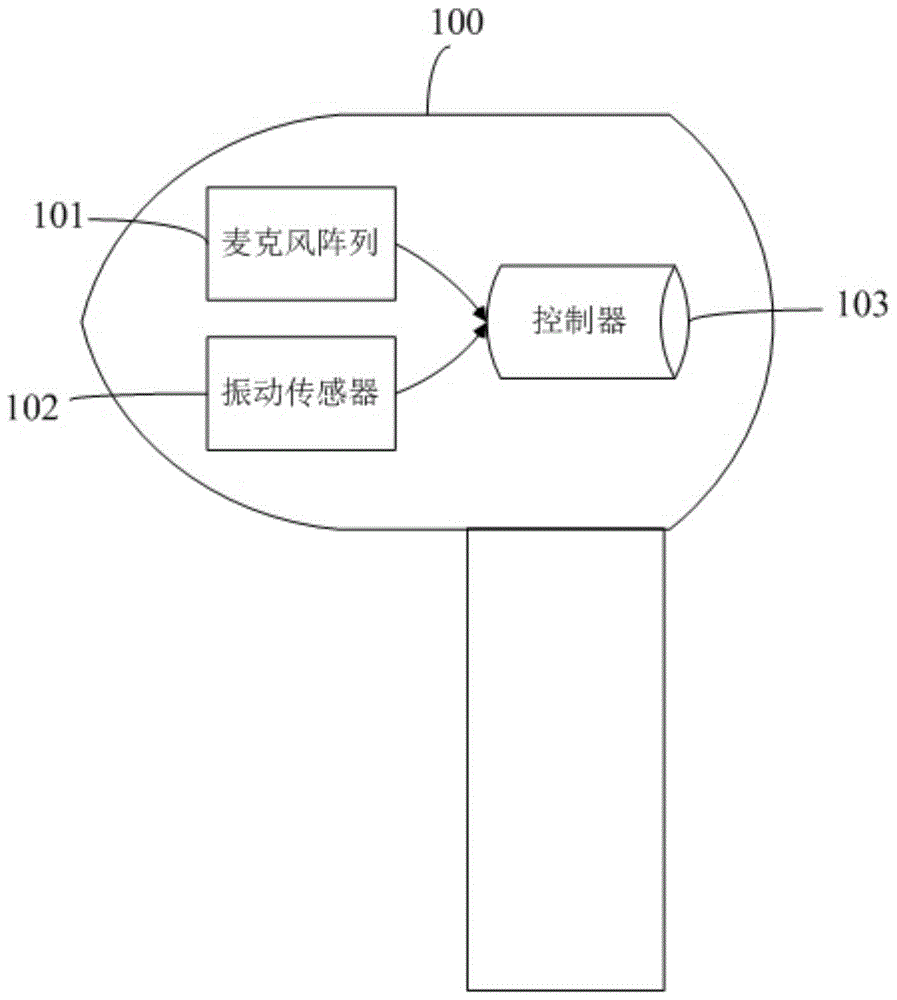
本发明实施例提供的语音唤醒方法和语音唤醒装置,适用于图1所示的应用场景。在图1所示的应用场景中,包括耳机100。其中,耳机100包括麦克风阵列101、振动传感器102以及控制器103。所述麦克风阵列100包括至少一个处于开启状态的麦克风,所述麦克风阵列100用于获取用户的语音信息。所述振动传感器102用于获取用户发生所产生的振动信息。所述控制器103用于对所述麦克风阵列101与振动传感器102获取的语音信息与振动信息进行分析与处理,判断是否生成唤醒信息。
其中,耳机100可与终端连接,在生成唤醒信息之后将所述唤醒信息发送至终端,以使所述终端进行对应所述唤醒信息的动作。例如,所述终端为手机,且所述耳机100与所述终端连接,所述耳机100生成了唤醒语音助手的唤醒信息,并把该唤醒信息发送至所述手机,所述手机接收到所述唤醒信息之后,开启手机上的唤醒助手软件。
基于此,本发明实施例提供了一种语音唤醒方法、语音唤醒装置及耳机。
其中,本发明施例提供的应用于语音唤醒方法是一种能够提高语音唤醒准确率的语音唤醒方法,具体为:通过获取唤醒语音信息及检测所述耳机佩戴者发声所产生的振动信息;当所述唤醒语音信息与预设唤醒语音信息匹配,且所述振动信息满足预设条件时,生成唤醒指令。该方法只有同时满足唤醒语音信息与耳机佩戴者发声所产生的振动信息这两个条件时,所述耳机才产生唤醒指令进行唤醒动作,能够降低因佩戴者以外的用户的语音信息产生的误判率,提高了语音唤醒的准确率。
其中,本发明实施例提供的运行于耳机的一种语音唤醒装置是由软件程序构成的能够实现本发明实施例提供的应用于耳机的虚拟装置,其与本发明实施例提供的应用于耳机的一种语音唤醒方法基于相同的发明构思,具有相同的技术特征以及有益效果。
其中,本发明实施例提供的耳机能够执行本发明实施例提供的语音唤醒方法,或者,运行本发明实施例提供的语音唤醒装置。
需要说明的是,以上仅示例性的示出了应用场景的一种形式,本发明实施例提供的语音唤醒方法还可以进一步的拓展到其他合适的应用环境中,而不限于图1中所示的应用环境。
图2为本发明实施例提供的语音唤醒方法的一个实施例的流程图,所述语音唤醒方法可由图1中的耳机100执行,如图2所示,所述语音唤醒方法包括:
s210:获取唤醒语音信息及检测所述耳机佩戴者发声所产生的振动信息;
在本实施例中,所述耳机100预设有一个语音检测模式,只有在所述语音检测模式下,所述耳机100才能对所述唤醒语音信息与振动信息进行获取与分析处理。所述唤醒语音信息可为一段语音,例如,所述唤醒语音信息可为用户发出的语音“唤醒语音助手”这个短句,所述唤醒语音信息也可为用户发出的“唤醒”这个词语,具体唤醒语音信息可根据用户需求自行定义设置。所述振动信息是指所述振动传感器将所述耳机佩戴者在说话时所产生的振动转换成的电信号,该电信号即为振动信号。
其中,所述语音检测模式开始时,通过所述麦克风阵列101进行唤醒语音信息的获取,同时,触发所述振动传感器102进行振动信息的获取。或者,所述语音检测模式开启时,通过所述麦克风阵列101进行唤醒语音信息的获取,在所述麦克风阵列101对所述的唤醒语音信息进行获取的过程中,通过所述振动传感器102对耳机佩戴者发声所产生的振动信息进行获取。又或者,所述振动麦克风一直处于开启状态,实时获取所述振动信息。换句话说,所述振动信息的获取时间可稍稍晚于所述唤醒语音信息的获取时间点,而因所述振动信息是根据所述唤醒语音信息而产生的,因此振动信息的获取需在所述唤醒语音信息获取的过程中进行获取。
优选地,所述获取唤醒语音信息的开启时刻与检测所述耳机佩戴者发声所产生的振动信息开启时刻是相同的。
在一些实施例中,用于可预先设置所述语音检测模式的开启时长。例如,用户预先设置了所述语音检测模式的开启时长为1分钟,当所述耳机100开启了语音检测模式一分钟之后,所述耳机100自动关闭所述语音检测模式,停止所述唤醒语音信息与振动信息的获取。所述语音检测模式的开启时长的设置,可提前在与所述耳机100通信连接的终端上进行设置,在终端中进入所述耳机100的设置模式,自行设置所述耳机100的语音检测模式的开启时长。当然,所述语音检测模式的开启时长并不受限制,用户可自行定义。
s220:当所述唤醒语音信息与预设唤醒语音信息匹配,且所述振动信息满足预设条件时,生成唤醒指令。
其中,所述耳机在获取到所述唤醒语音信息与振动信息时,对所述唤醒语音信息与振动信息进行分析处理,当所述唤醒语音信息与预设唤醒语音信息匹配,且所述振动信息满足预设条件时,生成唤醒指令。具体地,所述预设唤醒语音信息是指用户预先设置的唤醒语音信息,所述耳机100在语音检测模式下获取到唤醒语音信息时,将所述唤醒语音信息与预设唤醒语音信息进行匹配。举个例子,所述耳机100预先设置的预设唤醒语音信息为“唤醒语音助手”这短句对应的语音信息,在语音检测模式下获取到唤醒语音信息也为“唤醒语音助手”对应的唤醒语音信息时,即说明所述唤醒语音信息与预设唤醒语音信息匹配。所述振动信息满足预设条件,是指所述耳机100获取到的振动信息满足预先设置的预设条件。所述预先设置的条件可为是否存在振动信息。例如,所述振动传感器在检测到所述佩戴耳机者的振动信息超过了预设振动信息阈值,则说明存在振动信息,进而证明所述振动信息满足预设条件。
具体地,当所述唤醒语音信息与预设唤醒语音信息不匹配,且所述振动信息满足预设条件时,所述耳机100不生成唤醒指令;当所述唤醒语音信息与预设唤醒语音信息匹配,且所述振动信息不满足预设条件时,所述耳机100不生成唤醒指令;当所述唤醒语音信息与预设唤醒语音信息不匹配,且所述振动信息不满足预设条件时,所述耳机100不生成唤醒指令。只有当所述唤醒语音信息与预设唤醒语音信息匹配,且所述振动信息满足预设条件时,所述耳机100才生成唤醒指令。
需要说明的是,在所述耳机100与所述终端连接时,所述唤醒指令用于控制终端进行对应动作。例如,所述唤醒指令对应动作为开启语音助手,则所述耳机100发送该唤醒指令至所述终端时,所述终端进行开启语音助手这一动作。
需要说明的是,所述振动信息的获取方式,可为:实时获取所述耳机佩戴者发声所产生的振动信息;或者,在所述语音检测模式下,获取所述耳机佩戴者发声所产生的振动信息。也即是说,所述振动信息可为实时获取,或者当进入所述语音检测模式时,才进行振动信息的获取。换句话说,对应附图1的应用场景进行解析,即是所述振动传感器可以是一直处于开启状态(即一直处于振动信息的获取状态),也可以是在所述耳机100进入语音检测模式时,所述振动传感器才开启(即在所述语音检测模式下,获取所述耳机佩戴者发声所产生的振动信息)。
本发明实施例提供的语音唤醒方法,通过获取唤醒语音信息及检测所述耳机佩戴者发声所产生的振动信息;当所述唤醒语音信息与预设唤醒语音信息匹配,且所述振动信息满足预设条件时,生成唤醒指令。该方法只有同时满足唤醒语音信息与耳机佩戴者发声所产生的振动信息这两个条件时,所述耳机才产生唤醒指令进行唤醒动作,能够降低因佩戴者以外的用户的语音信息产生的误判率,提高了语音唤醒的准确率。
图3为本发明实施例提供的语音唤醒方法的一个实施例的流程图,所述语音唤醒方法可由图1中的耳机100执行。如附图3所示,所述语音唤醒方法包括:s310:实时获取触发语音信息,根据所述触发语音信息确定是否触发语音检测模式;s320:获取唤醒语音信息及检测所述耳机佩戴者发声所产生的振动信息;s330:当所述唤醒语音信息与预设唤醒语音信息匹配,且所述振动信息满足预设条件时,生成唤醒指令。与上述实施例相比,本实施例的区别在于,在所述语音检测模式下,获取唤醒语音信息及检测所述耳机佩戴者发声所产生的振动信息之前,所述方法还包括:
s310:实时获取触发语音信息,根据所述触发语音信息确定是否触发语音检测模式。
在本实施例中,所述耳机100的麦克风阵列处于实时开启状态,用于实时获取所述触发语音信息。所述耳机100的麦克风阵列实时获取的触发语音信息,并对所述触发语音信息进行实时的分析与处理,并根据分析与处理的结果,确定是否触发语音检测模式。
具体地,所述耳机100是预先设置了所述语音检测模式的触发条件,所述耳机100的麦克风阵列在实时获取所述触发语音信息,当所述触发语音信息符合所述语音检测模式的触发条件时,所述耳机100则进入所述语音检测模式。所述触发条件可以是根据所述触发语音信息的信号能量进行设定
具体地,所述实时获取触发语音信息,根据所述触发语音信息确定是否触发语音检测模式,包括:
提取所述触发语音信息的能量;
判断所述能量是否大于预设的能量阈值;
若是,则触发语音检测模式成功;
若否,则触发语音检测模式失败。
其中,所述耳机100实时获取所述触发语音信息,并对所述触发语音信息进行能量的提取,所述能量的提取可根据所述触发语音信息在单位时间内质点振动的次数、单位时间波动传播的距离以及波长所获得。所述耳机100预先设有能量阈值,在获取到所述触发语音信息的能量后,将所述能量与预设的能量阈值进行比对。若所述能量大于预设的能量阈值,则触发语音检测模式成功;若所述能量小于或等于预设的能量阈值,则触发语音检测模式失败。
具体地,所述能量阈值可预先在与耳机100连接的终端上进行设置。例如,在与所述耳机100连接的手机上进入所述耳机100的设置模式,进入能量阈值的录入界面,点击能量阈值录入按钮,然后向所述麦克风阵列发出符合自身想要的能量的语音,点击录入完成。
需要说明的是,所述耳机100在获取所述触发语音信息的能量之前,会先对所述触发语音信息进行降噪处理,过滤所述触发语音信息中存在的噪音,以防止噪音对所述触发语音检测模式造成影响,从而降低误判率。
具体地,当触发语音检测模式失败时,跳转所述实时获取触发语音信息,根据所述触发语音信息确定是否触发语音检测模式该步骤,继续实时检测是否存在能够触发所述语音检测模式的触发语音信息。当触发语音检测模式成功时,跳转所述获取唤醒语音信息及检测所述耳机佩戴者发声所产生的振动信息该步骤。
需要说明的是,所述耳机100的触发关键词需要预先设置。所述耳机100的触发关键词可通过与其连接的终端中进行预先设置。例如,在所述耳机100与所述手机连接时,触控手机中先进入所述耳机100的“设置模式”,在所述耳机100的“设置模式”中点击触发关键词的录取,通过对所述耳机100的麦克风阵列录入提前准备的触发关键词语音进行识别或者直接键入所述触发关键词,点击录入完成,实现触发关键词的录入。
本发明实施例提供的语音唤醒方法,通过获取唤醒语音信息及检测所述耳机佩戴者发声所产生的振动信息;当所述唤醒语音信息与预设唤醒语音信息匹配,且所述振动信息满足预设条件时,生成唤醒指令。该方法只有同时满足唤醒语音信息与耳机佩戴者发声所产生的振动信息这两个条件时,所述耳机才产生唤醒指令进行唤醒动作,能够降低因佩戴者以外的用户的语音信息产生的误判率,提高了语音唤醒的准确率。并且,通过实时获取触发语音信息,根据所述触发语音信息确定是否触发语音检测模式,使得所述耳机不会一直处于语音检测模式下,避免了不必要的功耗浪费。
图4为本发明实施例提供的语音唤醒方法的一个实施例的流程图,所述语音唤醒方法可由图1中的耳机100执行。如附图4所示,所述语音唤醒方法包括:s410:获取唤醒语音信息及检测所述耳机佩戴者发声所产生的振动信息;s420:判断所述唤醒语音信息是否匹配预设唤醒语音信息;s430:当所述唤醒语音信息与预设唤醒语音信息匹配,且所述振动信息满足预设条件时,生成唤醒指令。
其中,所述耳机100预先设置有预设唤醒语音信息,在获取到所述唤醒语音信息后,判断所述唤醒语音信息是否匹配所述预设唤醒语音信息。所述预设唤醒语音信息可为关键词对应的语音信息。例如,所述预设唤醒语音信息为“唤醒语音助手”这一关键词对应的语音信息。
需要说明的是,所述耳机100在进入所述语音检测模式之后,则开启所述唤醒语音信息的获取,并将获取到的唤醒语音信息与预设唤醒语音信息进行比对计算,即是判断所述唤醒语音信息是否匹配预设唤醒语音信息。
具体地,所述预设唤醒语音信息为预设唤醒关键词;
所述判断所述唤醒语音信息是否匹配预设唤醒语音信息,包括:
检测所述唤醒语音信息是否包括与预设唤醒关键词匹配的词语;
若是,则确定所述唤醒语音信息与预设唤醒信息匹配;
若否,则唤醒终止。
其中,所述唤醒语音信息为至少一个词语对应的语音信息,例如,所述唤醒语音信息可为词语“语音助手”对应的语音信息,或者,所述唤醒语音信息也可为词语“唤醒语音助手”对应的语音信息。所述耳机100中预设唤醒语音信息为预设唤醒关键词,当所述耳机100获取到所述唤醒语音信息时,检测所述唤醒语音信息是否匹配预设唤醒语音信息,若所述唤醒语音信息匹配预设唤醒语音信息,将确定所述唤醒语音信息与预设唤醒信息是匹配的,若所述唤醒语音信息不匹配预设唤醒语音信息,终止本次唤醒,并跳转至所述实时获取触发语音信息,根据所述触发语音信息确定是否触发语音检测模式该步骤。
需要说明的是,所述唤醒语音信息对应的预设唤醒语音信息需要预先设置,可在与所述耳机100连接的终端上进行所述预设唤醒语音信息的设置。例如,所述耳机100与手机连接,用户在所述手机上进入所述耳机的设置模式,进入预设唤醒语音信息的设置界面,点击预设唤醒语音信息的录入,可通过耳机100的麦克风阵列录入预设唤醒语音信息进行识别,或者直接在所述手机上键入所述预设唤醒语音信息对应的关键词。或者,所述预设唤醒语音信息是预先在生产厂商中预先设定的,用户无需自行设置所述预设唤醒语音信息,而所述预设唤醒语音信息可通过说明书或者其他可行方式进行获知,例如,通过翻阅说明书或者致电所述耳机厂商客服进行口头获取。
具体地,参阅附图5,所述语音唤醒方法包括:s510:获取唤醒语音信息及检测所述耳机佩戴者发声所产生的振动信息;s520:判断所述振动信息是否满足预设条件;s530:当所述唤醒语音信息与预设唤醒语音信息匹配,且所述振动信息满足预设条件时,生成唤醒指令。本实施例与上述实施例的区别在于,所述振动信息满足预设条件,包括:
s520:判断所述振动信息是否满足预设条件。
其中,所述耳机100预先设置有针对所述振动信息的预设条件。所述耳机100在获取到所述振动信息后,判断所述振动信息是否满足所述预设条件。所述预设条件可为预设振动信息阈值,当所述耳机100获取到振动信息时,将所述获取的振动信息与预设振动信息阈值进行比对,从而确定所述振动信息是否蛮子预设条件。又或者,定义所述振动信息为超过预设振动频率的振动信息,所述预设条件则可为是否存在所述振动信息。当所述耳机100没有获取到所述振动信息时,确定所述振动信息不满足预设条件,当所述耳机100获取到所述振动信息时,确定所述振动信息满足预设条件。
具体地,所述预设条件为振动信息的频率大于预设频率阈值;
所述判断所述振动信息是否满足预设条件,包括:
若所述振动信息的频率大于预设频率阈值时,则确定所述振动信息满足预设条件;
若所述振动信息频率阈值小于或等于预设频率阈值,则确定所述振动信息不满足预设条件。
其中,所述耳机100预设的预设条件为振动信息的频率大于预设频率阈值,当所述耳机100获取到所述振动信息之后,计算所述振动信息的信号频率,根据所述信号频率与预设频率阈值的比对结果,确定所述振动信息是否满足预设条件。需要说明的是,用户在没有进行说话动作时,因用户的肢体动作行为或者其他外在因素造成身体的振动,所述耳机100也是能够获取到振动信息。而因说话动作对应的振动信号的频率为远远大于其他动作造成的振动信号的频率,则将预设条件用预设一个预设频率阈值与所述发声动作的振动信息的频率进行比对,能够提高判断的准确率。
需要说明的是,在获取所述唤醒语音信息的同时,获取所述振动信息,然后判断所述唤醒语音信息是否匹配预设唤醒语音信息且判断所获取到的振动信息是否满足预设条件,此时,判断所述唤醒语音信息是否匹配预设唤醒语音信息与判断所述振动信息是否满足预设条件是同步进行的。或者,在获取所述唤醒语音信息的过程中,获取所述振动信息,然后判断所述唤醒语音信息是否匹配预设唤醒语音信息且判断所获取到的振动信息是否满足预设条件,此时,判断所述振动信息是否满足预设条件是稍稍晚于判断所述预设唤醒语音信息是否匹配所述预设唤醒语音信息的。但所述判断所述振动信息的开启时间点必定是在所述判断所述预设唤醒语音信息是否匹配所述预设唤醒语音信息的过程中。
优选地,判断所述唤醒语音信息是否匹配所述预设唤醒语音信息的开始时间点与判断所述振动信息是否满足预设条件的开始时间点相同。
需要说明的是,所述“所述判断所述振动信息是否满足预设条件”与所述“判断所述唤醒语音信息是否匹配预设唤醒语音信息”是相互独立进行的,但两者开始运行的时间点是相同的,或者,“所述判断所述振动信息是否满足预设条件”的开始时间点在所述“判断所述唤醒语音信息是否匹配预设唤醒语音信息”的运行过程中。例如,所述耳机100在判断所述唤醒语音信息是否匹配预设唤醒语音信息是从第1秒开始,且在第8秒结束,则所述“所述判断所述振动信息是否满足预设条件”的开始时间点可为第1秒,或者在第1秒与第8秒之间。
在其他一些实施例中,所述预设条件可为所述振动信息是否匹配所述预先设置预设振动信息。所述预设振动信息可为预先在与所述耳机连接的终端上进行提前录入。例如,预先佩戴耳机,并在与所述耳机100连接的手机上进入所述耳机100的预设振动信息录入界面,点击预设振动信息按钮,进行预设语音信息的发声,比如,预设语言信息为词组“唤醒语音助手”对应的语音信息,用户则对着耳机的麦克风阵列进行词组“唤醒语音助手”的朗读,以使耳机能够录入对应预设语言信息的振动信息,最后点击录取完成。在所述耳机100获取到所述振动信息后,将所述振动信息与预设振动信息进行匹配,判断所述振动信息是否匹配预设振动信息,从而确定所述振动信息是否满足预设条件。
本发明实施例提供的语音唤醒方法,通过获取唤醒语音信息及检测所述耳机佩戴者发声所产生的振动信息;当所述唤醒语音信息与预设唤醒语音信息匹配,且所述振动信息满足预设条件时,生成唤醒指令。该方法只有同时满足唤醒语音信息与耳机佩戴者发声所产生的振动信息这两个条件时,所述耳机才产生唤醒指令进行唤醒动作,能够降低因佩戴者以外的用户的语音信息产生的误判率,提高了语音唤醒的准确率。并且,预先判断所述唤醒语音信息是否匹配预设唤醒语音信息和/或判断所述振动信息是否满足预设条件,以使提高语音唤醒方法的判断准确率。
图6为本发明实施例提供的语音唤醒方法的一个实施例的流程图,所述语音唤醒方法可由图1中的耳机100执行。如附图6所示,所述语音唤醒方法包括:s610:获取唤醒语音信息及检测所述耳机佩戴者发声所产生的振动信息;s620:验证所述唤醒语音信息与振动信息是否匹配;s630:当所述唤醒语音信息与预设唤醒语音信息匹配,且所述振动信息满足预设条件时,生成唤醒指令。本实施例与上述实施例的区别在于,所述振动信息满足预设条件,包括:
s620:验证所述唤醒语音信息与振动信息是否匹配;
若是,则跳转所述当所述唤醒语音信息与预设唤醒语音信息匹配,且所述振动信息满足预设条件时,生成唤醒指令该步骤;
若否,唤醒终止。
其中,所述耳机100在获取到所述唤醒语音信息与振动信息之后,还判断所述唤醒语音信息是否与振动信息匹配。所述唤醒语音信息与振动信息匹配是指,该振动信息是否为用户发出该唤醒语音信息产生的。举个例子,单单是用户自己说出所述预设唤醒语音信息中对应的关键词“你好”时,产生“你好”该词对应的语音信息,同时产生“你好”该词对应的振动信息,则所述“你好”该词对应的语音信息是与“你好”该词对应的振动信息匹配的。而当用户以外的其他人说出唤醒语音信息的关键词“你好”,且此时用户说出并非关键词时,此时耳机也会获取到关键词“你好”对应的唤醒语音信息,且非关键词对应的振动信息,但此时非关键词对应的振动信息是不与关键词“你好”对应的唤醒语音信息匹配的,也即关键词“你好”并非是佩戴耳机者发出时,振动信息是不与语音信息匹配的。
具体地,当所述唤醒语音信息与振动信息匹配时,则跳转所述当所述唤醒语音信息与预设唤醒语音信息匹配,且所述振动信息满足预设条件时,生成唤醒指令该步骤;若所述唤醒语音信息与振动信息不匹配时,则终止本次唤醒,跳转实时获取触发语音信息,根据所述触发语音信息确定是否触发语音检测模式该步骤。
具体地,参阅附图7,所述验证所述唤醒语音信息与振动信息是否匹配,包括:
s710:提取所述唤醒语音信息与振动信息的波形;
其中,所述耳机100在获取到所述唤醒语音信息与振动信息之后,提取所述唤醒语音信息与振动信息对应的波形。当所述唤醒语音信息与振动信息均来自佩戴耳机者时,所述唤醒语音信息与振动信息的波形是相似的。例如,唤醒语音信息为“你好,唤醒语音助手”时,对应词语“你好”的唤醒语音信息这一段波形的总波长与对应词语“你好”的振动信息这一段波形的总波长是相等的,对应词语“唤醒语音助手”的唤醒语音信息这一段波形的总波长与对应词语“唤醒语音助手”的振动信息这一段波形的总波长是相等的。
s720:判断所述唤醒语音信息与振动信息的波形是否匹配;
其中,判断所述唤醒语音信息与振动信息的波形是否匹配,可根据所述振动信息中的至少一小段波形的总波长是否在所述唤醒语音信息中能够找到相匹配的总波长。例如,唤醒语音信息为“你好,唤醒语音助手”时,对应词语“你好”的唤醒语音信息这一段波形的总波长与对应词语“你好”的振动信息这一段波形的总波长是相等的,对应词语“唤醒语音助手”的唤醒语音信息这一段波形的总波长与对应词语“唤醒语音助手”的振动信息这一段波形的总波长是相等的。则可通过“你好”与“唤醒语音助手”两个词语对应的振动信息的总波长,在所述唤醒语音信息的整个波形中进行查找对应,判断是否存在相同总波长的一小段波长,若存在,则确定所述唤醒语音信息与振动信息匹配,若不存在,则确定所述唤醒语音信息与振动信息不匹配。
s730:若是,则确定所述唤醒语音信息与振动信息匹配;
其中,若所述唤醒语音信息与振动信息的波形是匹配时,则跳转当所述唤醒语音信息与预设唤醒语音信息匹配,且所述振动信息满足预设条件时,生成唤醒指令该步骤。
s740:若否,则确定所述唤醒语音信息与振动信息不匹配。
其中,若所述唤醒语音信息与振动信息的波形是不匹配时,则终止本次唤醒,跳转实时获取触发语音信息,根据所述触发语音信息确定是否触发语音检测模式该步骤。
本发明实施例提供的语音唤醒方法,通过获取唤醒语音信息及检测所述耳机佩戴者发声所产生的振动信息;当所述唤醒语音信息与预设唤醒语音信息匹配,且所述振动信息满足预设条件时,生成唤醒指令。该方法只有同时满足唤醒语音信息与耳机佩戴者发声所产生的振动信息这两个条件时,所述耳机才产生唤醒指令进行唤醒动作,能够降低因佩戴者以外的用户的语音信息产生的误判率,提高了语音唤醒的准确率。并且,在生成唤醒指令之前还预先验证所述唤醒语音信息与振动信息是否匹配,提高语音唤醒的准确率。
相应的,本发明实施例还提供了一种语音唤醒装置,所述语音唤醒装置用于图1所示的耳机100,如图8所示,所述语音唤醒装置800包括:
获取模块801,用于获取唤醒语音信息及检测所述耳机佩戴者发声所产生的振动信息;
生成模块802,用于当所述唤醒语音信息与预设唤醒语音信息匹配,且所述振动信息满足预设条件时,生成唤醒指令。
本发明实施例提供的语音唤醒装置,通过获取唤醒语音信息及检测所述耳机佩戴者发声所产生的振动信息;当所述唤醒语音信息与预设唤醒语音信息匹配,且所述振动信息满足预设条件时,生成唤醒指令。该方法只有同时满足唤醒语音信息与耳机佩戴者发声所产生的振动信息这两个条件时,所述耳机才产生唤醒指令进行唤醒动作,能够降低因佩戴者以外的用户的语音信息产生的误判率,提高了语音唤醒的准确率。
具体地,参阅附图9,所述装置900包括:
第一获取模块901,用于获取唤醒语音信息及检测所述耳机佩戴者发声所产生的振动信息;
生成模块902,用于当所述唤醒语音信息与预设唤醒语音信息匹配,且所述振动信息满足预设条件时,生成唤醒指令。
所述装置900还包括:
确定模块903,用于实时获取触发语音信息,根据所述触发语音信息确定是否触发语音检测模式;
所述确定模块903具体用于检测所述触发语音信息是否包括与预设的触发关键词相匹配的词语;若是,则触发语音检测模式成功;若否,则触发语音检测模式失败。
第一判断模块904,用于判断所述唤醒语音信息是否匹配预设唤醒语音信息;
所述第一判断模块904具体用于检测所述唤醒语音信息是否包括与预设唤醒关键词匹配的词语;若是,则确定所述唤醒语音信息与预设唤醒信息匹配;若否,则唤醒终止;
第二判断模块905,用于判断所述振动信息是否满足预设条件;
所述第二判断模块905具体用于若所述振动信息的频率大于预设振动频率阈值,则确定所述振动信息满足预设条件;
若所述振动信息小于或等于预设频率阈值,则确定所述振动信息不满足预设条件。
验证模块906,用于验证所述唤醒语音信息与振动信息是否匹配;若是,在跳转所述当所述唤醒语音信息与预设唤醒语音信息匹配,且所述振动信息满足预设条件时,生成唤醒指令该步骤;若否,唤醒终止;
所述验证模块906具体用于提取所述唤醒语音信息与振动信息的波形;判断所述唤醒语音信息与振动信息的波形是否匹配;若是,则确定所述唤醒语音信息与振动信息匹配;若否,则确定所述唤醒语音信息与振动信息不匹配。
第二获取模块907,用于实时获取所述耳机佩戴者发声所产生的振动信息;或者,在所述语音检测模式下,获取所述耳机佩戴者发声所产生的振动信息。
本发明实施例提供的语音唤醒装置,通过获取唤醒语音信息及检测所述耳机佩戴者发声所产生的振动信息;当所述唤醒语音信息与预设唤醒语音信息匹配,且所述振动信息满足预设条件时,生成唤醒指令。该方法只有同时满足唤醒语音信息与耳机佩戴者发声所产生的振动信息这两个条件时,所述耳机才产生唤醒指令进行唤醒动作,能够降低因佩戴者以外的用户的语音信息产生的误判率,提高了语音唤醒的准确率。
图10是本发明实施例提供的耳机10的硬件结构示意图,如图10所示,该耳机10包括:
一个或多个处理器11以及存储器12,图6中以一个处理器11为例。
处理器11和存储器12可以通过总线或者其他方式连接,图6中以通过总线连接为例。
存储器12作为一种非易失性计算机可读存储介质,可用于存储非易失性软件程序、非易失性计算机可执行程序以及模块,如本发明实施例中的语音唤醒方法对应的程序指令/模块(例如,附图8所示的获取模块801与生成模块802)。处理器11通过运行存储在存储器12中的非易失性软件程序、指令以及模块,从而执行服务器的各种功能应用以及数据处理,即实现上述方法实施例的语音唤醒方法。
存储器12可以包括存储程序区和存储数据区,其中,存储程序区可存储操作系统、至少一个功能所需要的应用程序;存储数据区可存储根据语音唤醒装置的使用所创建的数据等。此外,存储器12可以包括高速随机存取存储器,还可以包括非易失性存储器,例如至少一个磁盘存储器件、闪存器件、或其他非易失性固态存储器件。在一些实施例中,存储器12可选包括相对于处理器11远程设置的存储器,这些远程存储器可以通过网络连接至语音唤醒装置。上述网络的实例包括但不限于互联网、企业内部网、局域网、移动通信网及其组合。
所述一个或者多个模块存储在所述存储器12中,当被所述一个或者多个处理器11执行时,执行上述任意方法实施例中的语音唤醒方法,例如,执行以上描述的图2中的方法步骤s210至步骤s220,图3中的方法步骤s310至步骤s330;实现图4中的模块s410-s430、图5中模块s510-s540、图6中模块s610-s630子模块、图7中模块s710-s740、图8中子模块801-802和图9中子模块901-906的功能。
上述产品可执行本发明实施例所提供的方法,具备执行方法相应的功能模块和有益效果。未在本实施例中详尽描述的技术细节,可参见本发明实施例所提供的方法。
本发明实施例提供了一种非易失性计算机可读存储介质,所述计算机可读存储介质存储有计算机可执行指令,该计算机可执行指令被一个或多个处理器执行,例如图10中的一个处理器11,可使得上述一个或多个处理器可执行上述任意方法实施例中的语音唤醒方法,例如,执行以上描述的图2中的方法步骤s210至步骤s220,图3中的方法步骤s310至步骤s330;实现图4中的模块s410-s430、图5中模块s510-s540、图6中模块s610-s630子模块、图7中模块s710-s740、图8中子模块801-802和图9中子模块901-906。
以上所描述的装置实施例仅仅是示意性的,其中所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部模块来实现本实施例方案的目的。
通过以上的实施方式的描述,本领域普通技术人员可以清楚地了解到各实施方式可借助软件加通用硬件平台的方式来实现,当然也可以通过硬件。本领域普通技术人员可以理解实现上述实施例方法中的全部或部分流程是可以通过计算机程序来指令相关的硬件来完成,所述的程序可存储于一计算机可读取存储介质中,该程序在执行时,可包括如上述各方法的实施例的流程。其中,所述的存储介质可为磁碟、光盘、只读存储记忆体(read-onlymemory,rom)或随机存储记忆体(randomaccessmemory,ram)等。
最后应说明的是:以上实施例仅用以说明本发明的技术方案,而非对其限制;在本发明的思路下,以上实施例或者不同实施例中的技术特征之间也可以进行组合,步骤可以以任意顺序实现,并存在如上所述的本发明的不同方面的许多其它变化,为了简明,它们没有在细节中提供;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的范围。
- 还没有人留言评论。精彩留言会获得点赞!