一种端到端的新闻节目结构化方法及其结构化框架体系与流程
本发明涉及新闻节目处理技术领域,更具体的是涉及一种端到端的新闻节目结构化方法及其结构化框架体系。
背景技术:
随着时代的发展,技术的进步,视频的索引和检索是个重要的问题,并且具有重大意义。而电视新闻是视频中的一大部分,也是会被反复多次利用的视频。如电视新闻播出后的点播,需要将电视新闻流分段,然后再对每段电视新闻流进行元数据标注,从而快速进行索引和访问;电视新闻节目作为一种素材再次被利用,用作其他新闻节目的编辑材料,往往再次利用的是新闻的有价值片段,也需要将电视新闻流按照电视新闻结构进行分解,并对有利用价值的片段进行标注。
新闻视频是视频的一种重要分支,他们包含着大量的有用信息,基于内容的视频检索系统指通过文本、图片或视频的其他特征在视频集中搜索需要的信息。
一档新闻节目一般包括片头、主要内容介绍、新闻报道、天气预报及片尾,对于点播而言,需求则是对新闻报道(story)这一层级进行索引和访问,对于作为素材再次利用即二次编辑而言,需求则是对scene这一层级进行索引和访问;面对当前不断增加的海量新闻视频内容,使用原人工的方法进行新闻流分段和标注已经不可行,新闻节目的访问和二次编辑需要的实时性也得不到满足。
技术实现要素:
本发明的目的在于:为了解决使用原人工的方法进行不断增加的海量新闻流的分段和标注,新闻节目的访问和二次编辑的实时性得不到满足的问题,本发明提供一种端到端的新闻节目结构化方法及其结构化框架体系,综合了新闻语法、视觉特征、音频特征、文本语义等跨模态信息,融合采用计算机视觉、机器学习、自然语言处理等多种人工智能技术,一次性实现了新闻节目的scene层级和story层级结构切分和核心元数据自动描述。
本发明为了实现上述目的具体采用以下技术方案:
一种端到端的新闻节目结构化框架体系,包括从下往上的shot层级、scene层级和story层级,所述shot层级包括多个shot,其中每一shot为由多个连续frame帧组成的具有相似视觉特征的镜头片段,scene层级包括多个scene,其中每一scene为由多个shot组成的具有相似语义特征的场景片段,story层级包括多个story,其中每一story为由多个scene组成的具有完整故事性描述的节目片段,一则新闻节目主要由一到多个story构成;每一scene的核心元数据包括主题topic、分类categorization、人物person和关键字keyword,每一story的核心元数据包括主题topic、人物person和关键字keyword。
一种端到端的新闻节目结构化方法,包括如下步骤:
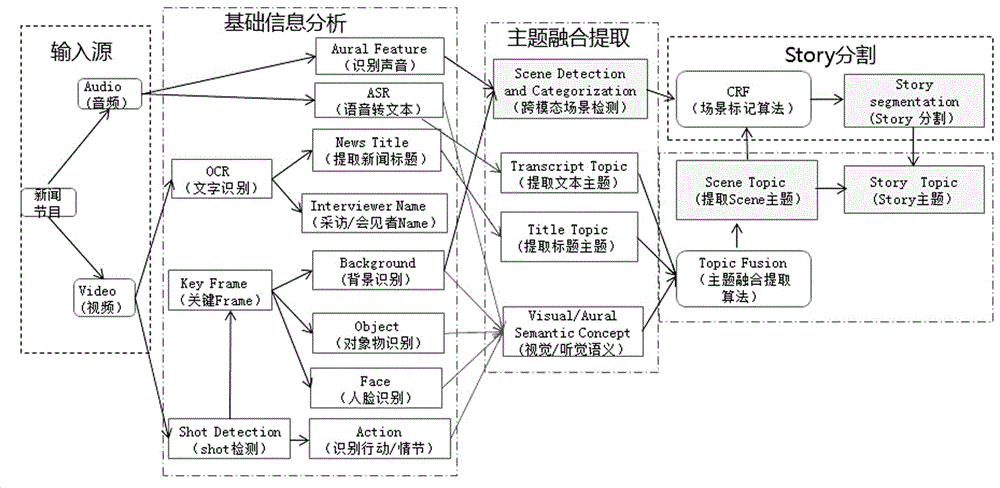
s1:对输入的新闻节目进行预处理,分别获取新闻节目的音频资源和视频资源;
s2:利用asr语音识别技术、ocr文字识别技术和shotdetection技术提取音频资源和视频资源内的基础信息;
s3:基于s2提取的基础信息,提取各模态的语义主题信息,并采用跨模态的主题融合提取算法,对各模态的语义主题信息进行融合聚类,输出scene主题;同时进行跨模态场景检测,输出scene层级;
s4:利用crf场景标记算法对s3中得到的scene层级和scene主题进行场景聚合和分割,输出具有相同语义的story层级和story主题。
进一步的,所述s2中对音频资源进行基础信息分析有以下两种方法:
方法a:基于mfccs音频特征的语音判定分析技术,识别音频资源的声音信息,通过音频特征分析判定语音播报的停顿间隔,音频的停顿间隔时间点将用于后续场景检测;
方法b:通过asr语音识别技术将音频资源的语音内容转化为文本内容,新闻节目中播音员的语音播报内容对于理解新闻节目语义含义、元数据提取都非常重要,因此语音识别技术的分析工作是基础分析工作。
进一步的,所述s2中对视频资源进行基础信息分析包括以下两种方式:
方法1:利用ocr文字识别技术对视频资源的文字部分进行文字识别,分析出文本信息,提取新闻节目标题和与会者名字信息;
方法2:利用shotdetection技术对视频资源的画面部分进行shot检测,将新闻节目自底向上切分为若干具有相似视觉特征的镜头,并通过关键提取技术提取出所述具有相似视觉特征的镜头的关键帧序列,再根据所提取的关键帧序列对视频资源的背景、特定物体、人脸和行为进行识别,这些识别信息将用于后续场景检测、主题融合分析和元数据自动填写流程环节。
进一步的,所述s3具体包括如下步骤:
s3.1:基于asr语音识别技术转化的文本内容和ocr文字识别技术提取的新闻节目标题,结合根据提取的关键帧序列得到的背景、特定物体、人脸和行为的识别信息,利用lda无监督学习算法得到各模态的语义主题信息,这些语义主题信息可看作各模态对当前视频片段的内容理解的概要表达,但这些独立模态的表达可能是不准确的,有缺失的,甚至是错误的,所以,我们还需要通过一种新闻节目多模态融合算法将各模态的主题表达进行融合聚类,最终形成相对正确的主题概要表达;
s3.2:采用跨模态的主题融合提取算法,对各场景的主题描述进行近似性计算,对主题相近的场景进行融合聚类,输出scene主题;
s3.3:由于新闻节目视频画面是基础,同一个场景中不论镜头如何切换,其画面的背景是相同或接近的,因此,以背景识别的时间点和基于mfccs音频特征的语音判定分析技术得到的停顿间隔时间点作为跨模态场景检测的基线时间点,对各模态的语义主题信息进行切分,输出scene层级。
进一步的,通过前面步骤基本完成了新闻节目各场景的切分和主题,人物,关键词等核心元数据的自动提取,但是还需将这些场景准确的组合成具备完整故事的节目片段。所以,我们采用基于crf算法通过对一定样本数据进行学习,将若干场景分割和聚合为不同的story片段中。crf算法输入是一组scene序列的视觉类别特征和文本主题特征,输出是对各场景序列的位置标签。这些位置标签将可用于切分和组合story片段,利用crf场景标记算法对s3中得到的scene层级和scene主题进行场景聚合和分割,输出相同语义的story,构成story层级和story主题。
本发明的有益效果如下:
1、本发明对不同来源的新闻节目,通过多维度结合asr语音识别技术、ocr文字识别技术等,进行跨模态的特征融合,主题融合提取,再基于crf场景标记算法,提高了story分割及scene和story主题提取的准确率,同时获取到的story层级、scene层级,方便新闻节目的点播和二次编辑直接取用,提高了使用时效性,端到端的整个过程系统自动完成,有效避免了人为干扰信息,减少出错,同时节省时间。
2、本发明对不同来源的新闻节目,充分利用其视频、文字、语音的特征信息,通过各智能识别分析技术分析出基础信息,采用跨模态的特征融合,对主题进行融合,形成scene主题和层级,再基于crf场景标记算法,实现story分割,产生结构化体系中的具有完整故事描述的节目片段story层次及story主题,既充分利用了各种来源视频、文字、语音的特征信息,又有效避免了干扰信息,确保提取结果的精准性。
附图说明
图1是本发明的新闻节目结构化方法流程示意图。
图2是本发明的新闻节目结构化框架体系示意图。
具体实施方式
为了本技术领域的人员更好的理解本发明,下面结合附图和以下实施例对本发明作进一步详细描述。
实施例1
如图1和图2所示,本实施例提供一种端到端的新闻节目结构化方法以及基于该方法的结构化框架体系,所述结构化框架体系包括从下往上的shot层级、scene层级和story层级,所述shot层级包括多个shot,其中每一shot为由多个连续frame帧组成的具有相似视觉特征的镜头片段,scene层级包括多个scene,其中每一scene为由多个shot组成的具有相似语义特征的场景片段,story层级包括多个story,其中每一story为由多个scene组成的具有完整故事性描述的节目片段,一则新闻节目主要由一到多个story构成,所述每一scene的核心元数据包括主题topic、分类categorization、人物person和关键字keyword,所述每一story的核心元数据包括主题topic、人物person和关键字keyword。
所述一种端到端的新闻节目结构化方法,包括如下步骤:
s1:对输入的新闻节目进行预处理,分别获取新闻节目的音频资源和视频资源;
s2:利用asr语音识别技术、ocr文字识别技术和shotdetection技术提取音频资源和视频资源内的基础信息;
所述s2中对音频资源进行基础信息分析有以下两种方法:
方法a:基于mfccs音频特征的语音判定分析技术,识别音频资源的声音信息,通过音频特征分析判定语音播报的停顿间隔,音频的停顿间隔时间点将用于后续场景检测;
方法b:通过asr语音识别技术将音频资源的语音内容转化为文本内容,新闻节目中播音员的语音播报内容对于理解新闻节目语义含义、元数据提取都非常重要,因此语音识别技术的分析工作是基础分析工作;
所述s2中对视频资源进行基础信息分析包括以下两种方式:
方法1:利用ocr文字识别技术对视频资源的文字部分进行文字识别,分析出文本信息,提取新闻节目标题和与会者名字信息;
方法2:利用shotdetection技术对视频资源的画面部分进行shot检测,将新闻节目自底向上切分为若干具有相似视觉特征的镜头,并通过关键提取技术提取出所述具有相似视觉特征的镜头的关键帧序列,再基于cnn、gan、c3d等深度神经网络模型根据所提取的关键帧序列对视频资源的背景、特定物体、人脸和行为进行识别,这些识别信息将用于后续场景检测、主题融合分析和元数据自动填写流程环节;
s3:基于s2提取的基础信息,提取各模态的语义主题信息,并采用跨模态的主题融合提取算法,对各模态的语义主题信息进行融合聚类,输出scene主题;同时进行跨模态场景检测,输出scene层级,具体包括如下步骤:
s3.1:基于asr语音识别技术转化的文本内容和ocr文字识别技术提取的新闻节目标题,结合根据提取的关键帧序列得到的背景、特定物体、人脸和行为的识别信息,利用lda无监督学习算法得到各模态的语义主题信息,这些语义主题信息可看作各模态对当前视频片段的内容理解的概要表达,但这些独立模态的表达可能是不准确的,有缺失的,甚至是错误的,所以,我们还需要通过一种新闻节目多模态融合算法将各模态的主题表达进行融合聚类,最终形成相对正确的主题概要表达;
s3.2:采用跨模态的主题融合提取算法,对各场景的主题描述进行近似性计算,对主题相近的场景进行融合聚类,输出scene主题;
s3.3:本实施例中新闻节目结构化最小单元是scene(场景),因此场景的精准检测定位尤为重要,由于新闻节目视频画面是基础,同一个场景中不论镜头如何切换,其画面的背景是相同或接近的,因此,以背景识别的时间点和基于mfccs音频特征的语音判定分析技术得到的停顿间隔时间点作为跨模态场景检测的基线时间点,对各模态的语义主题信息进行切分,输出scene层级,可忽略掉一些视觉场景错误切分的时间点;
s4:利用crf场景标记算法对s3中得到的scene层级和scene主题进行场景聚合和分割,输出具有相同语义的story层级和story主题,具体为:
通过前面步骤基本完成了新闻节目各场景的切分和主题、人物、关键词等核心元数据的自动提取,但是还需将这些场景准确的组合成具备完整故事的节目片段;所以,我们采用基于crf算法通过对一定样本数据进行学习,将若干场景分割和聚合为不同的story片段中。crf算法的输入是一组scene序列的视觉类别特征和文本主题特征,输出的是对各场景序列的位置标签。这些位置标签将可用于切分和组合story片段,即利用crf场景标记算法对s3中得到的scene层级和scene主题进行场景聚合和分割,输出相同语义的story,构成story层级和story主题。
如图2所示,本实施例在跨模态场景检测后输出scene层级,主题融合提取后输出scene主题,然后经过crf场景标记算法进行story分割后输出story层级以及story主题,由于shot层级和frame帧在新闻节目中的独立语义信息不够丰富,因此在本实施例中并不对其进行过多处理,本实施例重点关注具有明确语义含义的story层和scene层,通过ocr、asr等技术初始化信息解析,找出scene的主题、分类、人物、关键字等信息,经过提取主题、融合等复杂处理,输出scene层、scene主题、story层及story主题,多个shot组成scene,scene作为素材被二次编辑使用;多个scene构成story,电视新闻的点播可直接使用story层级,经过端到端的新闻节目结构化处理,避免了人工操作的繁琐和出错,提高了新闻节目使用时效性。
以上所述,仅为本发明的较佳实施例,并不用以限制本发明,本发明的专利保护范围以权利要求书为准,凡是运用本发明的说明书及附图内容所作的等同结构变化,同理均应包含在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!