一种基于神经网络的大规模MIMO的CSI多倍率压缩反馈方法与流程
本发明涉及一种基于神经网络的大规模mimo的csi多倍率压缩反馈方法,属于通信技术领域。
背景技术:
大规模mimo(multiple-inputmultiple-output)系统已被公认为是5g及以上通信系统的关键技术。在大规模mimo系统中,基站端配备了大量的天线,能够在低信噪比(snr)的情况下恢复从用户端接收到的信息,同时为多个用户提供服务。然而,为了获得这些潜在的好处,基站端需要获得准确的信道状态信息(csi)。对于上行链路,基站端可以通过对用户端发送的导频进行信道估计,获得准确的csi。然而,下行csi是很难实现的,尤其是对于目前使用最多的蜂窝系统的频分双工(fdd)系统。在时分双工(tdd)系统中,利用互易性可以从上行链路的csi中推断下行链路的csi。然而,fdd系统不具有互易性,因此在用户端获得的下行csi需要通过反馈链路发送给基站端。反馈完整的csi将带来巨大的开销,而实际中通常用来减小开销的基于量化或码本的方法,会随着天线数量的增加导致反馈开销线性增加,因此在大规模mimo系统中是不可取的。
目前在大规模mimo系统信道状态信息反馈的研究中,利用信道状态信息的空时相关性和压缩感知的理论可先将信道状态信息变换至某个基下的稀疏矩阵,再利用压缩感知获得低维度测量值,通过反馈链路传递至基站端,基站端从该测量值中重建出原稀疏信道矩阵。基于压缩感知方法提出的基于深度学习的信道反馈及重建模型csinet作为一种非迭代算法,大大减小了反馈开销。该模型基于自动编码器架构,在用户端编码,在基站端进行译码重建。由于其整个网络是一个“黑盒”,因而其网络的构造并没与充分利用csi编解码的原理,在网络的设计上有需要改进的地方。此外,大规模mimo系统的csi反馈在相干时间较短的情况下需要进行大幅度压缩,在相干时间较长时可采用较小幅度的压缩。因此,csi的压缩率必须能够根据环境进行调整。迭代算法能够适用于不同压缩率,但是现有的基于深度学习下的压缩方法只能在固定的压缩率下压缩csi矩阵,用户端需要存储多个网络架构和相应的参数集才能实现可变倍率压缩,由于用户端的存储空间有限,这是不可行的。
技术实现要素:
为克服现有技术的不足,本发明提供一种基于神经网络的大规模mimo的csi多倍率压缩反馈方法,以解决现有的csinet模型无法实现可变倍率压缩反馈的问题,并且基于理论对csinet的网络设计进行了改进。
本发明为解决上述技术问题采用以下技术方案:
本发明提供一种基于神经网络的大规模mimo的csi多倍率压缩反馈方法,包括以下步骤:
步骤一:在用户端,对mimo信道状态信息在空频域的信道矩阵
步骤二:构建包括编码器和译码器的信道反馈及重建模型csinet+,引入串联多倍率压缩框架sm-csinet+和并联多倍率压缩框架pm-csinet+,即在用户端引入串联或并联多倍率压缩编码器实现可变倍率压缩编码器,将信道矩阵h编码为更低维度的码字;译码器属于基站端,选择相应倍率的解压缩译码器,从码字重建出原信道矩阵估计值
步骤三:对信道反馈及重建模型csinet+、sm-csinet+、pm-csinet+分别进行训练,使代价函数最小,以获得各自的模型参数;
步骤四:对上述三种信道反馈及重建模型输出的重建信道矩阵
步骤五:将待反馈和重建的信道状态信息输入已训练的信道反馈及重建模型csinet+、sm-csinet+或pm-csinet+中,由模型输出角延迟域重建信道矩阵序列并通过二维逆dft变换恢复得到原始空频域的信道矩阵序列的重建值。
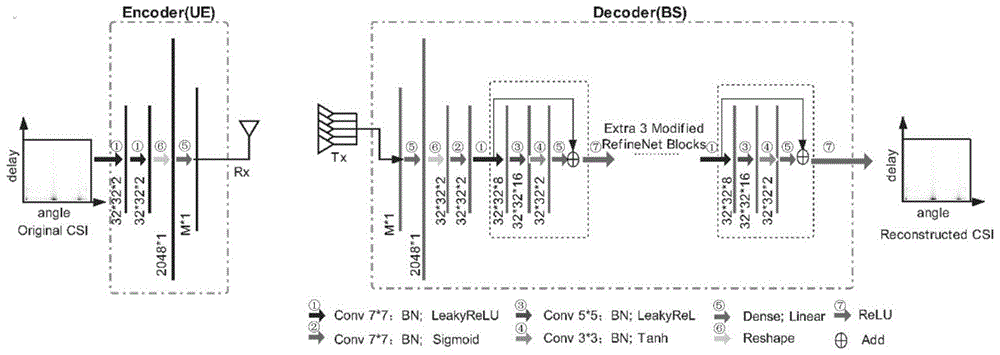
作为本发明的进一步技术方案,步骤二中的csinet+由csinet改进而来,具体为:
1)csinet+的编码器中使用了两个7×7卷积层来替换csinet在编码器处的第一个3×3卷积层,csinet+的译码器的refinenet中分别用一个7×7和一个5×5的卷积核来替换csinet相应位置的两个3×3卷积核;
2)csinet+移除了csinet中最后一个refinenet后附加的卷积层,csinet+在译码端的全连接层和第一个refinenet单元之间插入一个卷积层和一个bn层。
作为本发明的进一步技术方案,步骤二中引入了串联多倍率压缩框架sm-csinet+,在用户端采用串联方式将不同倍率的压缩编码器相接,用小倍率编码器的压缩码字去生成大倍率编码器的压缩码字,同时,压缩前用于提取特征的前两个卷积层也由不同的压缩编码器共享,在基站端将不同解码器的输出串联,进行端到端的训练。
作为本发明的进一步技术方案,步骤二中引入了并联多倍率压缩框架pm-csinet+,采用并联方式将同倍率的大倍率压缩编码器相接,用大倍率编码器的压缩码字去生成小倍率编码器的压缩码字,与基站端的解码器联合进行端到端的训练。
作为本发明的进一步技术方案,csinet+编码器包含一个全连接层和两个卷积层,译码器包含一个全连接层、两个卷积层和四个refinenet单元。
作为本发明的进一步技术方案,串联多倍率压缩框架sm-csinet+编码器包括一个4倍压缩编码器和三个2倍压缩编码器,均由全连接层构成;四个编码器相串联,译码器包含对应的4倍、8倍、16倍和32倍解压缩译码器,各译码器结构与csinet+译码器相同。
作为本发明的进一步技术方案,并联多倍率压缩框架pm-csinet+编码器包括八个32倍压缩编码器,均由全连接层构成;八个编码器相并联,译码器包含对应的4倍、8倍、16倍和32倍解压缩译码器,各译码器结构与csinet+译码器相同。
作为本发明的进一步技术方案,步骤三中的代价函数为:
(1)所述csinet+的代价函数为:
其中,m为训练集的所有样本数,||·||2为欧几里得范数,hi为第i个训练样本对应的信道矩阵;
(2)所述sm-csinet+、pm-csinet+的代价函数为:
ltotal(θ)=c4l4(θ4)+c8l8(θ8)+c16l16(θ16)+c32l32(θ32)
其中ln(·)、cn、θn分别表示在n倍压缩网络中输出端的的mse损失函数、损失函数的系数、训练得到的模型参数,n取4、8、16、32分别对应4倍、8倍、16倍、32倍压缩网络,cn表示将各损失项的幅度大小缩放到相同范围内的超参数。
本发明采用以上技术方案与现有技术相比,具有以下技术效果:
本发明提出在网络结构和重建质量上均超过已有csinet的csinet+模型,以及同时在环境适应性和存储空间占用量上均优于已有csinet的sm-csinet+和pm-csinet+模型。首先csinet+是通过分析csi的稀疏性特点和深度学习相关理论,对其卷积核和译码器的refine过程进行了改进,使其网络结构得到改善,进一步提升了重建精度。此外,串联多倍率压缩框架sm-csinet+和并联多倍率压缩框架pm-csinet+的提出又进一步实现了在不同场景中的可变倍率压缩反馈;
本发明是多倍率压缩的信道压缩及重建网络,该网络与csinet类似,也是基于自动编码器架构,主要由神经网络中的卷积层和全连接层构成,通过端到端和数据驱动的训练方案,直接从信道样本中学习信道结构,得到有效压缩编码,并借助由卷积层构成的残差网络从中恢复出原始信道矩阵。然而,csinet的压缩率是固定的,若要实现多倍率压缩,只能训练并存储多个cs网络架构和相应的参数集,需要很大的存储空间。而用户端的存储空间是有限的,因此csinet在不同的场景不能实现可变倍率的压缩。通过利用串联或并联编码译码器的方式,在csinet的基础上提出可变倍率压缩的网络架构,可以提升重建性能对压缩率的鲁棒性;
本发明可大大减少csi反馈网络的参数,降低用户端的存储空间,提高系统的可行性,同时还可以提高重建精度,而且在不同场景下可实现压缩率的的可变性。
附图说明
图1是本发明方法采用的csinet+的网络架构图。
图2是本发明方法采用的sm-csinet+的网络架构图。
图3是本发明方法采用的pm-csinet+的网络架构图。
具体实施方式
下面结合附图对本发明的技术方案做进一步的详细说明:
如图1所示,本发明设计了一种基于神经网络的大规模mimo的csi多倍率压缩反馈方法,该方法具体包括以下步骤:
步骤一:在用户端,对mimo信道状态信息在空频域的信道矩阵
步骤二:构建基于csinet改进的、包括编码器和译码器的模型csinet+,并引入串联多倍率压缩框架sm-csinet+和并联多倍率压缩框架pm-csinet+,即在用户端引入串联或并联多倍率压缩编码器实现可变倍率压缩编码器,将信道矩阵h编码为多种较低维度的码字,译码器属于基站端,从码字重建出原信道矩阵估计值
(1)通过分析csi的稀疏性特点并结合深度学习中的refinement理论,提出了csi反馈的两个网络设计原则,对现有的信道反馈与重建模型csinet的网络进行了改进,引入了一个新的网络架构csinet+。csinet+相较于csinet主要做了两个改进:卷积核大小和refine过程。
①改进1:无线通信系统的信道矩阵中的非零值呈块状分布,csinet用卷积核为3×3滤波器的卷积层来提取块稀疏信道矩阵的特征会导致较大的“空白区域”,则卷积运算是无效的。因此在csinet+的编码器中使用了两个7×7卷积层来替换csinet在编码器处的第一个3×3卷积层,在译码器的refinenet中分别用一个7×7和一个5×5的卷积核来替换csinet相应位置的两个3×3卷积核。
②改进2:refinenet的核心思想为通过叠加带有shortcut的卷积层,不断地将初始的信道矩阵估计值改善,使其越来越接近原始信道矩阵,即最后一个refinenet单元的输出应该为最终的信道矩阵估计值。然而在csinet中最后一个refinenet单元后还附加了一个卷积层,因此干扰了细化。因此,我们在csinet+中移除这个卷积层。此外,csinet中很难获得一个好的初始信道估计值,因此在译码端的全连接层和第一个refinenet单元之间插入一个卷积层和一个bn层,插入的该卷积层的输出即可作为初始信道矩阵估计,后面各refinenet单元对其进行细化。
此外,csinet+编码器包含一个全连接层和两个卷积层,译码器包含一个全连接层、两个卷积层和四个refinenet单元。
(2)引入了串联多倍率压缩框架sm-csinet+,在用户端采用串联方式将不同倍率的压缩编码器相接,用小倍率编码器的压缩码字去生成大倍率编码器的压缩码字,同时,压缩前用于提取特征的前两个卷积层也由不同的压缩编码器共享,在基站端将不同解码器的输出串联,进行端到端的训练;既实现了可变倍率压缩,又大大减少了编码器参数的数量。
此外,在串联多倍率压缩框架sm-csinet+中编码器包括一个4倍压缩编码器和三个2倍压缩编码器,均由全连接层构成。四个编码器相串联,实现了4倍、8倍、16倍和32倍压缩;译码器包含对应的4倍、8倍、16倍和32倍解压缩译码器,各译码器结构与csinet+译码器相同。
(3)引入了并联多倍率压缩框架pm-csinet+,采用并联方式将同倍率的大倍率压缩编码器相接,用大倍率编码器的压缩码字去生成小倍率编码器的压缩的压缩码字,与基站端的解码器联合进行端到端的训练。相比串联框架进一步减少了编码器参数数量。
此外,在并联多倍率压缩框架pm-csinet+中编码器包括八个32倍压缩编码器,均由全连接层构成。八个编码器相并联,实现了4倍、8倍、16倍和32倍压缩;译码器包含对应的4倍、8倍、16倍和32倍解压缩译码器,各译码器结构与csinet+译码器相同。
步骤三:采用adam优化算法和端到端的学习方式,分别联合训练三种信道反馈及重建模型csinet+、sm-csinet+、pm-csinet+的编码器和译码器的参数,使各自的代价函数最小,以获得模型参数。
(1)所述csinet+的代价函数为:
其中,m为训练集的所有样本数,||·||2为欧几里得范数,hi为第i个训练样本对应的信道矩阵;
(2)所述sm-csinet+、pm-csinet+的代价函数为:
ltotal(θ)=c4l4(θ4)+c8l8(θ8)+c16l16(θ16)+c32l32(θ32)
其中ln(·)、cn、θn分别表示在n倍压缩网络中输出端的的mse损失函数、损失函数的系数、训练得到的模型参数。n取4、8、16、32分别对应着4倍、8倍、16倍、32倍压缩网络。另外可通过设置超参数cn来将各损失项的幅度大小缩放到相同范围内。
此外,sm-csinet+、pm-csinet+框架进行端到端训练时,需要将不同倍率的译码器的输出拼接作为总输出,对所有倍率的压缩编码器和解压缩译码器同时进行训练,得到模型参数。所获得的模型参数包括全连接层的权重、偏置,以及卷积层的卷积核、偏置。
步骤四:对信道反馈及重建模型csinet+、sm-csinet+、pm-csinet+输出的重建信道矩阵
步骤五:将待反馈和重建的信道状态信息输入已训练的信道反馈及重建模型csinet+、sm-csinet+或pm-csinet+中,由模型输出角延迟域重建信道矩阵序列并通过二维逆dft变换恢复得到原始空频域的信道矩阵序列的重建值。其中将sm-csinet+、pm-csinet+框架投入实际场景中使用时,需要选择合适倍率的压缩编码器和解压缩译码器。
为了验证本发明方法可减少csi反馈网络的参数,降低用户端的存储空间,同时还可以提高重建精度,在不同场景下可实现压缩率的的可变性,特列举一个验证例进行说明。
本验证例是一种基于神经网络的大规模mimo的csi多倍率压缩反馈方法,通过数据驱动的编码器和译码器架构,在用户端用不同压缩率的编码器将信道矩阵压缩编码为低维度码字,经反馈链路传送至基站端,由不同解压缩率的译码器重建出当前信道矩阵,减少csi反馈网络的参数,同时提高信道重建质量和实现对压缩率的可变性,具体包括如下步骤:
步骤一:在一种mimo的fdd系统中,基站端配置32根发送天线,用户端使用单根接收天线,采用ofdm载波调制方式,使用1024个子载波。用cost2100模型根据上述条件,在5.3ghz的室内微蜂窝场景和300mhz的室外乡村场景各产生15000个空频域信道矩阵的样本,将样本集分成训练集、验证集和测试集,分别包含100000、30000和20000个样本。对样本中每一个空间-频率域的信道矩阵,用维度分别为1024×1024和32×32的dft矩阵fd和fa,对
步骤二:如图1所示的csinet+架构、如图2所示的sm-csinet+架构、如图3所示的pm-csinet+架构中编码器部分分别设计用户端的编码器。其中:
(1)csinet+:将复数域信道矩阵
(2)sm-csinet+:压缩前的处理与csinet+完全相同。用全连接层实现的压缩部分是先将2048×1维向量压缩4倍,然后将压缩后的512×1维向量继续压缩2倍,得到8倍压缩。以此类推,通过串联多个2倍压缩编码器,可以实现16倍和32倍压缩。计算可得该方法在用户端的参数个数为1221532个,相比用csinet+实现多倍压缩减少了约38%的csi反馈参数,降低了用户端的存储空间。
(3)pm-csinet+:压缩前的处理与csinet+完全相同。用全连接层实现的压缩部分是先将2048×1维向量以32倍的压缩率并行压缩八次,压缩后得到的八个64×1维向量取第一个则得到32倍压缩后的码字,取前两个则得到16倍压缩后的码字,取前四个则得到8倍压缩后的码字,八个全取则可以实现4倍压缩。计算可得该方法在用户端的参数个数为1049500个,较sm-csinet+更少,与csinet+单独实现4倍压缩的参数量相同,相比用csinet+实现多倍压缩减少了约46.7%的csi反馈参数,降低了用户端的存储空间。
步骤三:如图1所示的csinet+架构、如图2所示的sm-csinet+架构、如图3所示的pm-csinet+架构中编码器部分分别设计用户端的译码器。其中:
(1)csinet+:将接收到的码字作为译码器的输入,先通过一个全连接层恢复到原始的2048×1维向量,再将其重组为两个32×32大小的矩阵,产生初始信道矩阵估计值。再将这两个矩阵作为两通道的特征图输入,经四个refinenet单元不断地提取特征细化后,得到最终重建的信道矩阵
(2)sm-csinet+和pm-csinet+:基站端由各不同倍率的解压缩译码器共同构成,各译码器结构均与csinet+相同。
步骤四:用步骤1中产生的训练样本,采用adam优化算法和端到端的学习方式。分别联合训练csinet+、sm-csinet+和pm-csinet+架构中编码器和译码器的参数,包括所有卷积层的卷积核和全连接层的权重和偏置,使得代价函数最小。
(1)csinet+的代价函数为:
(2)sm-csinet+、pm-csinet+的代价函数为:
ltotal(θ)=c4l4(θ4)+c8l8(θ8)+c16l16(θ16)+c32l32(θ32)。其中ln、cn、θn分别是mse损失函数,权重和学习可得的n倍压缩网络的参数。
对sm-csinet+、pm-csinet+架构进行网络训练时,需要将各倍率编码译码器同时进行训练,以32×32×8的信道矩阵为输出。
每次迭代使用训练集中200个样本计算梯度,根据adam优化算法更新参数,以此方法遍历训练集500次,其种采用动态学习率,即前期使用学习率为0.001,当代价函数值趋于稳定时采用0.0001学习率。训练过程中用验证集调整模型超参数,用测试集测试模型最终性能。
步骤五:将训练好的csinet+、sm-csinet+和pm-csinet+模型用于fddmimo系统的信道csi反馈中。对sm-csinet+和pm-csinet+模型,根据信道特点,选择相应倍率的压缩编码器和译码器,对用户端的信道矩阵进行编码后反馈到基站端进行译码,重建出原始信道矩阵。
本发明公开了一种基于神经网络的大规模mimo的csi多倍率压缩反馈方法,包括:首先,对现有的信道反馈与重建模型csinet的网络进行了改进,提出了csi反馈的两个网络设计原则,并根据这些原则引入了一个新的网络架构csinet+。此外,引入了两种不同的可变倍率压缩框架,即串联多倍率压缩框架sm-csinet+和并联多倍率压缩框架pm-csinet+。
sm-csinet+框架在用户端采用串联方式将不同倍率的压缩编码器相接,用小倍率编码器的压缩码字去生成大倍率编码器的压缩码字,同时,压缩前用于提取特征的前两个卷积层也由不同的压缩编码器共享,减少了编码器参数的数量,在基站端将不同解码器的输出串联,进行端到端的训练;在实际应用时对训练好的模型选择相应的解码器对接收到的csi压缩码字进行解码,输出重建值。
pm-csinet+框架在用户端采用并联方式将同倍率的压缩编码器相接,用大倍率编码器的压缩码字去生成小倍率编码器的压缩的压缩码字,相比串联框架进一步减少了编码器参数数量。与基站端的器联合进行端到端的训练,在实际应用时对训练好的模型选择相应的器对接收到的csi压缩码字进行解码,输出重建值。
综上,本发明可改造在重建质量上超过csinet的csinet+模型,以及在重建质量、环境适应性和存储空间上均优于csinet的sm-csinet+和pm-csinet+模型,使其网络结构得到改善,进一步提升重建精度,同时可减少csi反馈网络的参数,降低用户端的存储空间,同时还可以提高重建精度,在不同场景下可实现压缩率的的可变性,在有限的资源开销下,实现高效的信道状态信息的反馈。
上面结合附图对本发明的实施方式作了详细说明,但是本发明并不限于上述实施方式,在本领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下做出各种变化。
- 还没有人留言评论。精彩留言会获得点赞!