一种基于深度神经网络的分布式功率分配方法与流程
本发明属于无线通信技术领域,涉及一种基于深度神经网络的分布式功率分配方法。
背景技术:
随着智能设备的广泛普及,移动通信量呈爆炸性增长,给蜂窝移动网络带来了前所未有的压力。为了提高蜂窝网络的能量效率、提高系统吞吐量和优化通信基础设施,设备到设备(d2d)被认为是一种可行的解决方案。在d2d网络中,多对d2d对与全频复用共存,导致链路间干扰复杂,通过功率控制进行干扰管理来优化系统容量,传统功率控制算法大部分都是基于实时信道信息迭代实现的,复杂的矩阵运算和信道估计需要的时间使得实时的功率调整十分困难。
技术实现要素:
本发明针对以上传统功率控制中存在问题,提出了一种无需迭代的基于深度神经网络(deepneuralnetwork,dnn)的分布式功率控制算法。
本发明采用的技术方案为:
一种基于深度神经网络的分布式功率分配方法,其特征在于,包括以下步骤:
s1、信息收集:n对链路对分别从中心控制器(centralcontroller,cc)中接收过时的信道,功率信息,得到各自的观测向量;n对链路和中心控制器组成d2d系统;
s2、信息约简:每一对对各自原始接收到的观测向量进行约简,去除大量冗余信息,得到约简后的观测向量;
s3、判决:构建基于深度神经网络的功率控制模型,采用步骤s2获得的数据进行训练,得到训练好的深度神经网络模型,获得功率分配结果;
本发明提出的一种基于深度神经网络的检测框架,主要包括离线训练和在线检测:
数据:d2d系统分别为离线模块和在线模块提供信道信息和功率数据。对于离线模块:d2d系统提供有标记的采样数据,作为训练集;对于在线模块:d2d系统提供(无标记)的采样数据,作为检测数据。
离线训练:通过离线训练设计检测统计量。将离散功率分配看作一个多元分类任务,那么dnn的输出可以建模为后验概率,从而开发适合于功率分配的代价函数(比如,本发明设计的基于最大后验概率的代价函数);给定训练集,通过离线训练,得到训练好的dnn,进而基于dnn设计检测统计量;将训练集送入训练好的dnn,根据标签拟合功率分配函数。
在线检测:将数据送到训练好的dnn,得到判决结果。
本发明所提基于深度神经网络输入和隐藏层运用了线性整流函数(rectifiedlinearunit,relu)作为各层的激活函数
relu(x)=log(1+expx)(1)
输出层使用softmax函数来确定最后离散功率输出档位。输出的值为:
本发明所提基于深度神经网络的功率分配机制是一种通用的dnn框架,其dnn可以为任意类型的网络,因此可以对不同网络泛化。本发明的有益效果在于不需要实时得到所有链路的信道信息,而是根据部分历史信息预测当前链路周围的通信环境,进而进行实时的功率决策以最大化全局网络的加权和速率。
附图说明
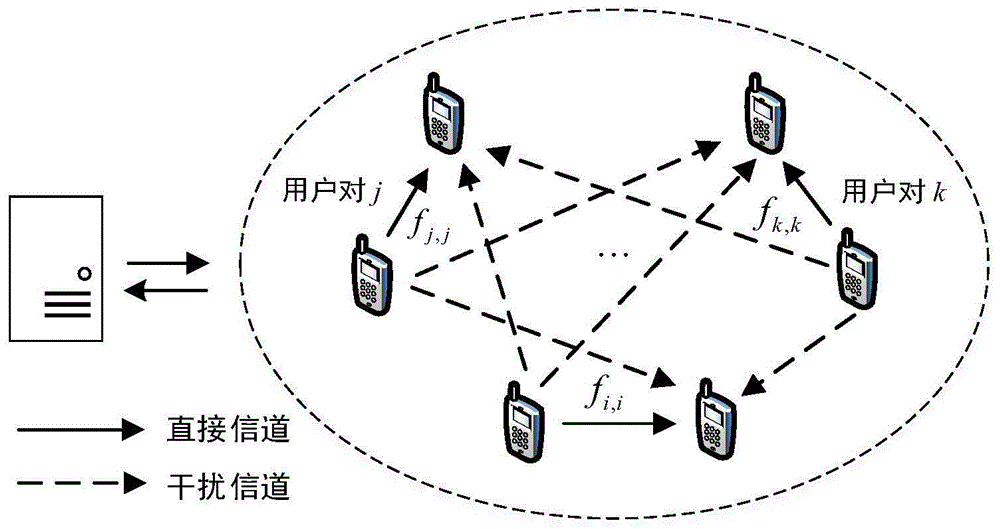
图1示出了本发明中的d2d网络模型;
图2示出了本发明中d2d网络中用户通信的帧结构;
图3示出了本发明中的用户功率决策流程;
图4示出了本发明提出的基于深度学习的功率分配方案和其他功率分配方案的性能在测试链路个数不同的情况下做对比;
图5出了本发明提出的基于深度学习的功率分配方案和其他功率分配方案的性能在测试区域不同的情况下做对比。
具体实施方式
下面结合附图,对本发明的具体实施方式作进一步详细描述。
图1示出了本发明中的d2d网络模型。在此d2d网络中,系统完全同步,由t时隙组成。每个时隙的信道参数由两部分组成:大尺度衰落和小尺度衰落。如图1所示,本发明用jakes模型来表述第t帧的小尺度衰落的变化,即
其中
其中
本发明目标是找出一种有效的用户关联方案使所有d2d用户的速率和最大,即
其中
在大型的d2d网络中,由于巨大的开销和回程网络的延迟,实际中很难获得实时的csi。在这里,本发明假设只有过去的信息被拿得到,因此只能最大化实时加权和速率的期望函数:
其中过去的信息
其中
其中
其中
上式中的输入数量为τ(n2+n)。当n很大时,神经网络需要拟合的函数会很复杂。另外,输入数量与n相关会导致用户个数变化时,网络会需要重新训练。为了降低神经网络训练的复杂性并去除与n的相关性,本发明提出一个对输入进行约简的方法。本发明以下面流程为例来讲述约检可行性方法:
首先,本发明根据对链路i的干扰对
然后,本发明根据相同的过程链路i对其他链路干扰对
根据排序结果本发明选择
下面讲述本发明提出的分布式神经网络样例。分布式神经网络可由六个独立的线性滤波器和一个四层神经网络组成。首先将r时刻的
图2示出了本发明中d2d网络中用户通信的帧结构。图3示出了本发明中的用户功率决策流程。d2d链路对将在一个时隙的数据帧分成三部分。在帧头的第一部分,d2d链路对先接收从cc中接收上一个时刻的过时干扰信息,然后对所接收到的干扰信息进行约简,约简后的结果输入到神经网络进行功率决策。第二部分,d2d链路对根据分配的功率进行数据传输,同时进行实时的干扰信息收集。最后,在帧尾的第三部分将这个时刻的干扰信息传输到cc。
下面,本发明将根据仿真结果来阐述本发明提出方案的性能。首先,考虑一个由100个d2d链路对组成的网络。所有链路对的发送机随机分布在边长为500米的正方形区域中,链路对接收器和发送器之间的距离均匀分布在2m到65m之间。设定d2d发送机最大的发送功率为p=38dbm,背景噪声功率为σ2=-114dbm,多普勒频移为10hz,相邻信道之间的相关系数ρ=0.01。路径损耗模型为32.45+20log10(f)+20log10(d)-gt-gr(以db为单位),其中f(mhz)是载波频率,d(km)是距离,gt表示发射天线增益,gr表示接收天线增益。本发明设置f=2.4ghz,gt=gr=2.5db。深度学习算法使用tensorflow实现,三个线性滤波器大小分别为m1=5,m2=15,m3=30,滑窗大小m=m1+m2+m3=50。神经网络所利用的过去信息时刻数量τ=2。
图4示出了本发明提出的基于深度学习的功率分配方案(dl)和其他功率分配方案的性能在测试区域不同的情况下做对比。三种对比算法为全部满功率传输策略(mpt),利用实时信道信息的fp方案(r-fp),利用过时信道信息的fp方案(o-fp)。可以从图中看出,当测试区域中链路个数持续增长时,dl方案的性能始终保持了可观的增长,dl方案与r-fp方案之间的性能差距从1%增长到最大为3%左右,而始终比o-fp方案的性能要好2%。值得强调的是,dl只用了一部分过时信道信息就得到了比较好的性能。而且随着链路个数的增长,dl的性能也保持了持续的增长,这也证明了dl方案的拓扑可延展性。
图5出了提出的基于深度学习的功率分配方案和其他功率分配方案的性能在测试区域不同的情况下做对比。在测试区域不断增长的条件下,dl一直与r-fp保持着大约1%的性能差距,而且随着链路区域的不断扩大,dl的性能几乎达到了r-fp一样的性能。在链路同时始终比o-fp性好2%。而且随着测试区域面积的增长,dl的性能也保持了持续的增长,这也证明了dl方案的拓扑可延展性。
- 还没有人留言评论。精彩留言会获得点赞!