一种网络服务块资源分配方法及存储介质与流程
本发明涉及网络技术领域,尤其涉及一种网络服务块资源分配方法及存储介质。
背景技术:
当前社会随着科技的进步,移动设备如手机、平板等在日常生活中扮演着越来越重要的作用,一些更加轻量级的移动设备更是应运而生,例如智能手表、智能眼镜等等,这些轻量级设备可随身携带,通过无线网络尤其是边缘网络节点连入网络,可支持一些应用和服务的执行,例如智能手表可以时刻监控配当人的身体状况。这些轻量级设备的使用可以更好地服务社会,然而其容量小以及依赖网络的特点,对其推广使用造成了不便。并且,由于轻量级设备本地容量不足以及其与服务器之间不稳定的通信质量等各种因素,通常移动设备的一些网络优化模型在轻量级设备上进行建模时会遇到难点。
block-streamasaservice(baas)可以说是专门为了轻量级设备而提出的一种服务供应模型,它可以把应用切分为一个个独立的服务块在设备和服务器之间进行传递和处理,这样灵活的块切分结构不仅可以减少服务传递时不必要的能量开销,而且可以减少应用占用的本地容量。在baas的基础之上,每次当用户在轻量级设备上请求服务时,设备会向服务器发送请求,服务器收到之后会将该服务的块发送给该设备。此时若通信质量不加,例如有大量的服务块等待请求或网络本身的波动等原因,设备在发送服务请求到该服务处理完成之前会有延迟,而这个延迟的等待时间很大程度地决定了用户对此服务请求的满意度。轻量级设备上的应用往往对延迟非常敏感,所以如何能够在轻量级设备的服务加载网络上,不仅可以减轻设备容量和能耗的压力,还能够最大程度地减低服务的延迟,是一个有思考价值的难题。同时,由于物联网移动设备的存储容量有限,电池能量有限,可以通过多种方式获取能量等特点,在进行加载分配是也需要充分考虑由这些特点所产生的影响。
申请号为201710232309.7,名称为《一种基于可穿戴设备的授权方法、装置和设备》的专利文件,以及申请号为201110160626.5,名称为《一种在移动设备间通过无线网络的查找和定位进行数据交换的方法》的专利文件,是本申请的背景技术文献。
技术实现要素:
本发明要解决的技术问题就在于:针对现有技术存在的技术问题,本发明提供一种可优化服务块分配,使资源提供更为灵活的网络服务块资源分配方法及存储介质。
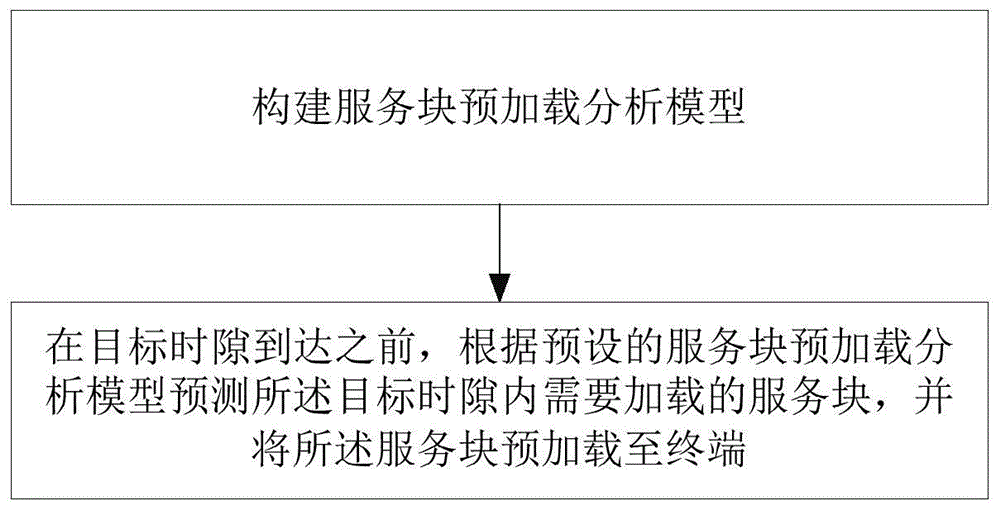
为解决上述技术问题,本发明提出的技术方案为:一种网络服务块资源分配方法,在目标时隙到达之前,根据预设的服务块预加载分析模型预测所述目标时隙内需要加载的服务块,并将所述服务块预加载至终端;
所述服务块预加载分析模型通过求解使得各服务块在预加载和直接加载两种状态下的延迟和能耗差之和最小化函数来确定需要预加载的服务块。
进一步地,所述预加载分析模型如式(1)所示:
式(1),un,p(t)为服务块n是否进行预加载,预加载为1,否则为0,v为预设的李雅普诺夫参数,dn,d(t)为服务块n的延迟,r(t)为所述终端的能量赤字队列,cn,d(t)为服务块n的能耗差,n为服务块的序号,sn为服务块n的大小,θ为所述终端的存储容量,t为时间参数。
进一步地,所述服务块n的延迟dn,d(t)如式(2)所示,所述服务块n的能耗差cn,d(t)如式(3)所示:
式(2)和式(3)中,e(z)为信道状态期望值,pd为所述终端的下载功率,z(t-1)为信道状态,an(t)为服务块在目标时隙被需要的概率,t为时间参数。
进一步地,通过学习服务块资源的实际分配过程,确定所述服务块在目标时隙被需要的概率和信道状态及信道状态概率,并根据所述信道状态及信道状态概率确定信道状态期望;
所述服务块在目标时隙被需要的概率an(t)如式(4)所示:
式(4)中,
其中,
式(5)和式(6)中,γ为学习时长,in()为服务块n在是否被需要,需要时为1,不需要时为0,t为时间参数;
所述信道状态及信道状态概率如式(7)所示:
式(7)中,
进一步地,还包括通过学习服务块资源的实际分配过程,确定最优化分配参数,并以所述最优化分配参数修正所述终端的能量赤字队列参数r(t);所述确定最优化分配参数如式(8)所示:
式(8)中,fπ(y)为最优化函数,πx为信道状态和服务块的联合需求状态(h)处于x时的概率,ux为在状态处于x时如何分配资源的策略集合,v为预设的李雅普诺夫参数,x为信道状态和服务块的联合需求状态(h)的状态,an,x为在状态处于x时服务块n被需求的概率,un,p,x表示在状态处于x时服务块n是否被预下载,on为服务块n的指令数,c为所述终端的执行速度,un,w,x为在状态处于x时服务块n没有被预下载,sn为服务块n的大小,z(x)为在状态处于x时的信道状态,y为最优化分配参数,pd为所述终端的下载功率,e(z)为信道状态期望值,pl为所述终端的执行功率,ρ为所述终端的获取能量的期望值,θ为所述终端的存储容量。
进一步地,以最优化分配参数修正所述终端的能量赤字队列参数r(t)的方式如式(9)所示:
式(9)中,
进一步地,所述可控修正参数如式(10)所示:
式(10)中,v为预设的李雅普诺夫参数,γ为学习时长。
一种存储介质,存储有可被计算机执行的程序,所述程序被执行时可实现如上任一项所述的分配方法。
与现有技术相比,本发明的优点在于:
1、本发明通过预测服务块的需求情况,提前将服务块预加载到终端,从而在目标时隙不需要再加载服务块,只是预加载的服务块不是终端所需要的服务块时,终端才需要从服务器加载服务块,因此,本发明可以明显提高了服务块的分配效率,降低系统因服务块分配而产生的延迟。
2、本发明的预加载分析模型不仅仅预测需要预加载的服务块,而且,在预测过程中,还综合考虑了终端的能量,终端与服务器之间的信道状态,从而能够在提高服务块分配效率的基础上,还能保证终端的能量稳定,保证终端的稳定运行。
附图说明
图1为本发明具体实施例的流程示意图。
图2为本发明具体实施例的服务块的二态马尔科夫模型。
图3为本发明具体实施例实验结果的网络绩效图。
图4为本发明具体实施例不同参数下实验结果的延迟和能耗变化图。
图5为本发明具体实施例不同参数对实验结果的影响分析图一。
图6为本发明具体实施例不同参数对实验结果的影响分析图二。
图7为本发明具体实施例学习时长对结果的影响分析图一。
图8为本发明具体实施例学习时长对结果的影响分析图二。
具体实施方式
以下结合说明书附图和具体优选的实施例对本发明作进一步描述,但并不因此而限制本发明的保护范围。
如图1所示,本实施例的网络服务块资源分配方法,在目标时隙到达之前,根据预设的服务块预加载分析模型预测所述目标时隙内需要加载的服务块,并将所述服务块预加载至终端;
所述服务块预加载分析模型通过求解使得各服务块在预加载和直接加载两种状态下的延迟和能耗差之和最小化函数来确定需要预加载的服务块。
进一步地,所述预加载分析模型如式(1)所示:
式(1),un,p(t)为服务块n是否进行预加载,预加载为1,否则为0,v为预设的李雅普诺夫参数,dn,d(t)为服务块n的延迟,r(t)为所述终端的能量赤字队列,cn,d(t)为服务块n的能耗差,n为服务块的序号,sn为服务块n的大小,θ为所述终端的存储容量,t为时间参数。
在本实施例中,所述服务块n的延迟dn,d(t)如式(2)所示,所述服务块n的能耗差cn,d(t)如式(3)所示:
式(2)和式(3)中,e(z)为信道状态期望值,pd为所述终端的下载功率,z(t-1)为信道状态,an(t)为服务块在目标时隙被需要的概率,t为时间参数。
在本实施例中,通过学习服务块资源的实际分配过程,确定所述服务块在目标时隙被需要的概率和信道状态及信道状态概率,并根据所述信道状态及信道状态概率确定信道状态期望;
所述服务块在目标时隙被需要的概率an(t)如式(4)所示:
式(4)中,
其中,
式(5)和式(6)中,γ为学习时长,in()为服务块n在是否被需要,需要时为1,不需要时为0,t为时间参数;
所述信道状态及信道状态概率如式(7)所示:
式(7)中,
在本实施例中,还包括通过学习服务块资源的实际分配过程,确定最优化分配参数,并以所述最优化分配参数修正所述终端的能量赤字队列参数r(t);所述确定最优化分配参数如式(8)所示:
式(8)中,fπ(y)为最优化函数,πx为信道状态和服务块的联合需求状态(h)处于x时的概率,ux为在状态处于x时如何分配资源的策略集合,v为预设的李雅普诺夫参数,x为信道状态和服务块的联合需求状态(h)的状态,an,x为在状态处于x时服务块n被需求的概率,un,p,x表示在状态处于x时服务块n是否被预下载,on为服务块n的指令数,c为所述终端的执行速度,un,w,x为在状态处于x时服务块n没有被预下载,sn为服务块n的大小,z(x)为在状态处于x时的信道状态,y为最优化分配参数,pd为所述终端的下载功率,e(z)为信道状态期望值,pl为所述终端的执行功率,ρ为所述终端的获取能量的期望值,θ为所述终端的存储容量。
在本实施例中,以最优化分配参数修正所述终端的能量赤字队列参数r(t)的方式如式(9)所示:
式(9)中,
在本实施例中,所述可控修正参数如式(10)所示:
式(10)中,v为预设的李雅普诺夫参数,γ为学习时长。
在本实施例中,通过一个具体物联网系统模型来对本发明进行说明。该物联网系统模型包括服务器和终端,采用block-streamasaservice(baas)架构,服务器和终端之间通过网络连接,终端从服务器上获取所需要的资源服务,为了使资源提供更为灵活,将资源服务切分为一个个的服务代码块。
在本实施例中,将物联网系统模型的运行过程以时隙为单位进行划分。在传统的方法中,对于每个时隙,终端先将本时隙所需要的资源加载到本地,然后再执行所加载的资源。而在本发明中,在目标时隙到来之前(定义目标时隙为时隙t),就先行进行预测,优选在时隙t-1时对时隙t所需要的资源进行预测,即优选在当前时隙来对下一时隙所需要的资源进行预测,通过式(1)所示的预加载分析模型,预测出需要预加载的服务块,并将预测得到的服务块预先加载到终端,在预测准确时,在时隙t终端就不需要临时从服务器加载资源,可以直接进行执行步骤,从而降低的终端的延迟;而当预测不准确时,即预先加载的服务块不是终端在时隙t所需要的资源,则终端还是需要临时从服务器加载相应的服务块。
在本实施例中,将终端对服务块的服务需求定义为一个二态马尔科夫模型,如图2所示,i代表该服务块在当前的需求,β和α分别代表到下一个时隙,服务块在需求/不被需求这两个状态之间的转移概率。在本实施例中,终端设备的存储空间的容量用θ表示,终端设备的电池的容量用φ表示,在时隙t内,终端设备获取的能量用e(t)θ表示,服务器与终端之间的信道状态用z(t)表示,服务块n的大小用sn表示,服务块n的指令数用on表示。
在系统运行过程中,当终端设备需要某个资源时,需要从服务器下载该资源,然后再执行,执行完毕后再删除该资源。在本实施例中,通过预测并进行预加载,可以减少下载所需要的时间,但当为错误的预加载时,即预加载的服务块不是终端设备所需要的服务块时,那将导致终端设备不必要的能量损失。因此,本发明不仅通过预加载来缩短因临时下载所造成的延迟,还需要在预加载时尽可能的准确,尽可能减少能量的损耗,即需要在尽可能减少能耗的基础上来缩短延迟。在本实施例中,用表示un,p(t)表示服务块n在时隙t-1是否进行了预加载,当进行了预加载时,un,p(t)=1,当没有进行预加载时,un,p(t)=0。当终端设备在时隙t所需要的服务块n在时隙t-1被成功的预加载了时,那么,在时隙t,终端设备的延迟即为服务块n被执行时所产生的延迟,即执行延迟,如式(11)所示:
式(11)中,dn,p(t)为执行延时,in()为服务块n在是否被需要,需要时为1,不需要时为0,t为时间参数,c为终端的执行速度,其余参数的定义与上文中的定义相同。
当终端设备在时隙t所需要的服务块n在时隙t-1没有被成功的预加载了时,此时包括预加载的服务块不是时隙t所需要的服务块,以及在时隙t-1没有预加载服务块两种情况。这时,终端设备需要在时隙临时向服务器下载服务块n,在下载完后再执行,以un,a(t)表示终端设备是否在时隙t需要直接向服务器下载服务块n,当终端设备需要在时隙t直接向服务器下载服务块n时,un,a(t)=1;当终端设备不需要在时隙t直接向服务器下载服务块n时,un,a(t)=0。那么,终端设备在时隙t所需要的服务块n在时隙t-1没有被成功的预加载了时,终端设备的延迟为下载延迟与执行延迟,此时的延迟如式(12)所示:
式(12)中,dn,a(t)为终端设备需要直接下载服务块时的延时,z(t)为时隙t的信道状态,其余参数的定义与上文中的定义相同。
进一步地,当在时隙t-1对服务块进行预加载时,终端设备的能耗为在时隙t-1中的下载能耗和在时隙t中,所预加载的服务块执行时的执行能耗,如式(13)所示:
式(13)中,cn,p(t)为服务块n被预加载时终端设备的能耗,pd为所述终端的下载功率,pl为所述终端的执行功率,z(t-1)为时隙t-1时的信道状态,in(t)为服务块n在时隙t的需要状态,被终端需要时in(t)=1,不被终端需要时in(t)=0,其余参数的定义与上文中的定义相同。
而直接下载的能耗如式(14)所示:
式(14)中,cn,a(t)为服务块n没有预加载,需要直接加载时的能耗,其余参数的定义与上文相同。
则对于服务块n,在时隙t上,终端设备的能耗cn(t)如式(15)所示:
cn(t)=cn,p(t)+cn,a(t)(15)
式(15)中,各参数的定义与上文相同。
对于所有服务块,在每个时隙,定义总的能耗为c(t),延迟为d(t)。设在每个时隙内,终端设备获取能量为e(t),则终端设备获取能量的过程可表述为多态马尔科夫过程,终端设备的能量队列可表示为如式(16)所示:
式(16)中,e(t)和e(t+1)为终端设备的能量队列,其余参数的定义与上文相同。
为了确保在长时隙(时间t→∞)内具有最小化的平均延迟,并且保证终端设备的能量队列稳定,同时还满足终端设备存储空间的约束条件,在本实施例中设置目标函数为如式(17)所示:
式(17)中,u所有块的预下载的策略,对块n来说包括(un,p(t),un,w(t))这两个变量,前者为1,后者为0指示预下载块n;前者为0,后者为1指示不预下载块n,
由于在时隙t-1,对于服务块是在当前时隙(即时隙t-1)进行预加载,还是在下一时隙(即时隙t)直接下载进行判断和选择时,对于时隙t上的网络状态和能量状态往往是未知的。因此,需要定义随机变量,并进行学习,通过定义一个时间长度为γ为学习时长,来学习所定义的随机变量,以获取这些随机变量的极大似然估计,通过这些极大似然估计值,就可以预加载模型预测如何对服务块进行预加载。需要学习的随机变量包括αn、βn、z和ρ,αn为服务块n由被需要转为不被需要的马尔科夫转移概率,βn为服务块n由不被需要转为需要的马尔科夫转移概率,αn和βn可统一描述为服务块的需求马尔科夫转移概率(如图2中所示的α和β),z为信道状态,ρ为终端获取能量的期望值。学习的过程优选在线学习,当然,也可以是通过离线数据来进行学习。
其中,服务块的需求马尔科夫转移概率如式(5)和式(6)所示,通过式(5)和式(6)所表示的学习过程,可以预测出服务块n的需求马尔科夫转移概率。信道状态及信道状态概率如式(7)所示,通过式(7)所表示的学习过程,可以预测信道状态及信道状态概率。
进一步地,终端设备获取能量的多态马尔科夫转移概率如式(18)所示,终端设备获取能量的期望值如式(19)所示:
式(18)和式(19)中,
在本实施例中,服务块预加载分析模型是一个lyapunov(李雅普诺夫)优化模型,为了进一步加速算法的收敛速度,可以预先学习一个预设的全局比例参数,该参数可以加速在线算法的收敛,该学习全局函数如式(8)所示,即:
式中各参数的定义与上文相同。式(8)中,在状态处于x时服务块n被需求的概率an,x通过式(4)即可确定。
在本实施例中,由于式(8)是因为有un,p(t)+un,w(t)=1,并且在本问题中只需要对是否需要预下载作出判断,而将具体延迟和能耗中直接下载判断中的un,a变成为了un,w,并用an(t)代替了in(t),以能够用un,p,x和un,w,x来对比预加载和直接加载的延迟和能耗而作出选择。通过式(8)体现了所有状态下的预加载的情况,通过求解式(8),使得式(8)最大化的最优化分配参数y即是所需要的比例参数,记为
本实施例的预加载分析模型运用lyapunov优化算法,将长时隙内的延迟最小化问题转化为能量赤字队列稳定性问题,并用服务块是否被需要两种状态下的转移来使得预测结果能够同时满足长时隙内的延迟最小和能量稳定性的要求。
进一步地,在本实施例中,以r(t)表示终端设备的能量赤字队列,并且满足式(20)所示的约束条件:
式(20)中,r(t)和r(t+1)为能量赤字队列,t为时间参数,其余参数的定义与上文相同。
终端设备的电池的容量满足如式(21)所示的约束条件:
r(t)+e(t)=ф(21)
式(21)中,各参数的定义与上文相同。
为了保证目标函数(17)中的能量约束,则能量赤字队列r(t)需要保持稳定,即需要
式(22)中,l(t)用于定义lyapunov方程,其余各参数的定义与上文相同。
那么,单个时隙内,终端设备的能量转移方程为如式(23)所示:
δ(t)=l(t+1)-l(t)(22)
式(22)中,δ(t)为相邻时隙的变化量,各参数的定义与上文相同。
为了保证能量赤字队列稳定,则需要在每个时隙内具有最小化δ(t),然后,将此时隙上的总延迟函数
式(23)中,各参数的定义与上文相同。
由于这是在根据每个时隙t-1时进行预加载的判断作出的,因此,式中的总延迟函数
对式(23)进行拆分整理,可得到式(24):
式(24)中,b如式(25)所示,其余各参数的定义与上文相同。
式(25)中,emax为最大的单位时隙能量获取,cmax为最大的单位时隙能量消耗,n为资源块的数量。
通过式(24),可以得到最终在每个时隙内需要进行处理的预加载函数如式(26)所示:
式(26)中,各参数的定义与上文相同。
通过上述lyapunov转换,就把一个全局性的问题转换成了式(26)所示的在每一个时隙上的预加载判断问题,通过每次求解式(26),就可以得到每个时隙上的预加载的选择。
通过用具体的数值重写式(26),并加上每个时隙的约束条件,可以得到式(27):
式(27)中,各参数的定义与上文相同。
由于式(27)中有关于时隙参数t的随机变量都采用了期望或概率表示,其值来源于学习过程中得到的估计值。又因为有un,p(t)+un,w(t)=1,即un,w(t)=1-un,p(t),将之代入式(27)中,并去年与判断选择无关的变量和参数值,即可以得到如式(1)所示的预加载分析模型。这样,在每个时隙t-1,服务块的预加载问题就变成了一个多变量的0-1规划问题,可以通过遍历解法进行求解,在每个时隙处理的式(1)所示的问题,还可以采用matlab等数学软件进行自动求解。
在时隙t-1进行完预加载的判断后,在时隙t需要处理的直接加载函数可表示为式(28)所示:
式(28)中,wn(t)为服务块n的需求权重,其余各参数的定义与上文相同。
根据lyapunov在线优化的特性,为了进一步加快收敛,将上文中通过学习确定的最优化分配参数
在本实施例中,终端设备的能量队列的上限和算法的收敛性可通过理论分析得出,在满足概率不低于
式(29)中,dd=max[dn,d(t)],cd=min[cn,d(t)],其余各参数的定义与上文相同。
此时,算法的收敛性满足式(30)所示:
式(30)中,
收敛时间满足式(31)所示:
式(31)中,t为收敛时间,t0和η为预设参数,均为大于0的自然数。
进一步地,通过仿真实验对本发明的方法进行验证,具体实验中的参数选择包括:n={3,5,7},选择不同的pi,j、αn、βn、πx,服务块的大小取s={580;520;2400}kb,服务块的指令数与块大小的数据相对应为o={2900;12000;14750},终端设备的执行速度为c=2×105,信道状态的可能取值为z={1,3}mb/s,pd=0.2w,pl=0.69w,ρ={0.3,0.35,0.4}。进一步地,为了避免偶然性,每次实验的每组数值做5次取平均值,实验如果如图3至图8所示。
通过图3所示的网络的绩效图可以看出,本方法相对于传统的lyapunov在线优化收敛更快且收敛值更低。能量收获过程是一个马尔可夫转台,所以系统在收敛后也会存在小幅度波动。可见,当t=845时,本方法即收敛,而一般lyapunov算法需要在t=1331时才收敛。因此,在收敛速度上看,本方法是传统lyapunov算法的1.6倍。此外,本方法的r(t)的值更低,意味着本方法具有更小的能量赤字,能够有效减轻电池的负担。
进一步地,随着v的变化,在不同ρ值下,延迟和能耗变化如图4所示,可以看出,随着v的增大,延迟所占比例更大,则延迟更小,而所付出的能耗则更大。不同的ρ意味着系统不同的能耗界限,ρ值越大,代表系统可以付出用来预加载服务的能耗越多,延迟就越低。
图5和图6分别描绘了α和β对预加载的影响。在图5中,固定了β的值为0.5,在图中可以发现随着α的值从0增到0.5,由于熵越来越大,随机性越拉越高,系统对预加载的判读失误也越来越高,使延迟增加。从0.5到1的过程中,虽然混乱度降低了,但是与此同时α的增加代表着块的需求增多,此时的延迟是混乱度和服务加载需求的综合影响,导致曲线波动。在图6中,我们联合改变α和β的值,由于是两个值联合改变,此时系统的服务加载需求一直保持不变,可以看到在α和β皆为0.5的时候混乱度最高,则延迟最高,α和β越趋向于0或1,预加载判断的准确度越高,延迟越低。
图7和图8体现的是学习过程γ对结果的影响,两张图中的水平线(没有方框点的)皆为使用真正的概率状态得出的最佳结果,而学习得到的参数极大似然估计值与其存在差距,但是随着学习时间γ的增加,这个差距会越来越小。而图8中,随着学习时间γ的增加,可以看到每组5次试验的误差变小,则试验的稳定性会变高。通过上述实验也验证了本发明的方法相对于传统的方法能够可优化服务块分配,使资源提供更为灵活,并且,具有良好的收敛特性。
本实施例的一种存储介质,存储有可被计算机执行的程序,该程序被执行时可实现如上任一项所述的分配方法。
上述只是本发明的较佳实施例,并非对本发明作任何形式上的限制。虽然本发明已以较佳实施例揭露如上,然而并非用以限定本发明。因此,凡是未脱离本发明技术方案的内容,依据本发明技术实质对以上实施例所做的任何简单修改、等同变化及修饰,均应落在本发明技术方案保护的范围内。
- 还没有人留言评论。精彩留言会获得点赞!