基于用户社交属性的D2D多播通信分簇方法与流程
本发明属于通信技术领域,具体涉及一种基于用户社交属性的d2d多播通信分簇方法。
背景技术:
庞大的数据流量需求,日益丰富的业务种类,导致无线通信网络负载越来越重。思科2018年的统计和预测表明,从2017年到2022年,无线移动设备数据量将会增长7倍,2022年移动数据流量将会达到77.5exabytes每月。在2017年至2022年之间移动数据流量将以46%的复合年增长率(compoundannualgrowthrate,cagr)持续增长。由此看来,未来移动数据流量的需求将会持续暴增,这对无线移动网络的负载能力带来了巨大的挑战。
作为第五代(5th-generation,5g)移动通信的关键技术之一,d2d通信技术在提升用户服务质量(qualityofservice,qos)、扩展蜂窝系统覆盖和提高系统性能等方面具有广阔的应用前景,成为当前产业界和学术界的研究热点。d2d多播通信技术可以完成一个用户同时向多个用户发送数据,通过用户共享频谱资源,极大的提高了频谱利用率。随着多媒体业务的急剧增加和5g通信的商用,d2d多播通信的应用越来越广泛,针对d2d多播通信进行系统研究非常必要。
终端设备由于人为携带被间接地赋予了社交属性。将终端设备的通信属性与用户之间的社交属性结合,构建用户间直通通信网络,能够更高效地实现资源共享,进一步提高传输的有效性和可靠性。
然而,现有d2d分簇技术中较少考虑用户的社交属性、移动性,都假定用户处于准静态状态,因此使得得到的d2d多播簇稳定性较差,导致d2d通信用户的性能无法保障。目前大多数文献中,用户社交属性因子仅通过二进制变量表示用户是否具有社交关系,以上模型难以准确衡量用户间的社交关系。可见,目前对d2d通信用户的社交属性的建模方法较为单一,需要对用户社交属性进行更深入的分析和更合理的建模。从而能够更高效地实现资源共享,进一步提高传输的有效性和可靠性。
技术实现要素:
本发明的目的是提供一种基于用户社交属性的d2d多播分簇方法,以解决现有d2d多播簇稳定性较差带来的用户性能损失的问题。
本发明采用以下技术方案:基于用户社交属性的d2d多播分簇方法,包括以下步骤:
s101、随机选取k个d2d用户{u1,…,un,…,uk}分到k个簇内{c1,…,ck,…ck};un(n=1,...,k)表示第n个d2d通信用户,k为d2d多播通信总簇数,ck(k=1,...,k)表示第k个d2d多播通信簇;
s102、计算每个簇的均值向量:
其中,mk表示第k个簇的均值向量,xn表示第n个d2d通信用户的坐标,ck为第k个簇中心用户的坐标,||xn-ck||2表示第n个d2d通信用户到第k个簇中心点的欧式距离,
s103、对第n个用户,分别计算它到每个簇的分簇因子距离:
dk,n表示第n个d2d通信用户到第k个簇中心用户的分簇因子距离,选取分簇因子距离最近的簇作为第n个用户最终选择的簇,即
s104、将用户n划分到簇c*n中;
s105、对第k个簇(k=1,...,k),计算新的均值向量mk′;
s106,判断第k个簇(k=1,...,k)新的均值向量mk′与当前簇的均值向量mk是否相等;如果不相等mk≠mk′,(k=1,...,k),将新计算的均值向量替换原均值向量
s107,返回执行s103-s106,直到每一个簇的均值向量都和前一轮计算的均值向量相等,此时算法收敛;
s108,将算法收敛时的结果,作为最终分簇结果。
进一步的,得到最终分簇结果后,在第k个簇(k=1,...,k)中,进行核心用户的选择,其具体方法为:将第n个用户的核心用户适应度fn作为衡量用户是否适合作为核心用户的参数,表示为:
其中,α、β、
根据潜在核心用户的适应度高低,选择第k个簇内适应度最高的用户作为第k个簇的核心节点,该核心节点作为d2d多播通信的传输节点;
进一步的,第n个用户的社交因子dn通过下式计算:
其中,
进一步的,第n个用户的驻留概率pn=tc,n/ts,n,其中,ts,n表示第n个用户在所有簇内驻留的总历史时间,tc,n表示第n个用户在当前簇内驻留的时间。
进一步的,第n个用户到第m个用户之间的社交属性因子可表示为:
进一步的,第n个用户和第m个用户之间平均关联时长的归一化表示:
其中,zn,m(t)表示t时刻第n个用户和第m个用户之间的内容分享状态,zn,m(t)=1表明t时刻第n个用户和第m个用户之间处于内容分享状态;否则zn,m(t)=0;δn,m(t)表示t时刻第n个用户和第m个用户之间的内容分享值。
进一步的,在δt时间内,第n个用户对第m个用户的d2d通信传输收益占二者之间总的传输收益的比例
其中,cotn,m(t)表示t时刻第n个用户对第m个用户的传输收益,cotm,n(t)表示t时刻第m个用户对第n个用户的传输收益。
本发明的有益效果是:本发明将用户社交属性因子引入d2d多播通信分簇算法,能够建立更稳定的d2d多播通信传输组,更高效地实现资源共享,进一步提高d2d通信传输的有效性和可靠性。
【附图说明】
图1为本发明实施例的系统效用图;
图2为本发明实施例的通信吞吐量图;
图3为本发明实施例的中断概率图;
图4为本发明实施例的簇鲁棒性图;
图5为本发明基于用户社交属性的d2d多播通信分簇方法的方法流程图。
【具体实施方式】
下面结合附图和具体实施方式对本发明进行详细说明。
一、本发明提供了一种基于用户社交属性的d2d多播分簇方法。
1、该方法是基于一个d2d通信用户社交属性模型,模型具体如下:
用户之间的社交属性受到用户联系的频率、联系时长、用户亲密度、互动方式的影响。由于本项目的研究对象是d2d通信用户之间的数据传输,因此本发明主要考虑用户之间进行内容分享的频率和时长。用户间社交关联度通过在一个确定时长内两个用户之间内容分享的次数以及每次内容分享的持续时间来描述。
令δn,m(t)表示t时刻第n个用户和第m个用户之间的内容分享值,zn,m(t)表示t时刻第n个用户和第m个用户之间的内容分享状态,zn,m(t)=1表明t时刻第n个用户和第m个用户之间处于内容分享状态;否则zn,m(t)=0。在δt时间内第n个用户和第m个用户之间内容分享的平均时长为:
根据高斯相似度函数,可以得到用户之间平均关联时长的归一化表示:
在d2d通信激励机制下,在δt时间内,第n个用户对第m个用户的d2d通信传输收益占二者之间总的传输收益的比例为:
其中cotn,m(t)表示t时刻第n个用户对第m个用户的传输收益,cotm,n(t)表示t时刻第m个用户对第n个用户的传输收益。
综合考虑d2d用户间关联关系和传输收益,第n个用户到第m个用户之间的社交属性因子可表示为:
其中,ρ是权重因子,可以根据业务特点进行调整。
2、为了稳定牢固的d2d多播组,在分簇中,我们考虑用户之间的社交关系。基于社交的k均值分簇算法为了解决以下优化问题:
其中,||xj-ci||2指的是用户j与第i个簇中心点间的欧氏距离。ωij为分布参数,当用户j属于第i个簇时(xj∈ci),ωij=1,否则,ωij=0。c2表示每个簇不为空;c3表示每个用户只能存在一个簇内。以上问题是np-hard问题,即使k=2。为了解决上述问题,本发明提出一种基于社交的k均值分簇算法。
基于社交的k均值分簇算法是为了将n个d2d用户{u1,u2,…,un}划分到k个簇中{c1,c2,…ck},如图5所示,基本步骤如下:
s101、随机选取k个d2d用户{u1,…,un,…,uk}分到k个簇内{c1,…,ck,…ck};un(n=1,...,k)表示第n个d2d通信用户,k为d2d多播通信总簇数,ck(k=1,...,k)表示第k个d2d多播通信簇。
s102、计算每个簇的均值向量:
其中,mk表示第k个簇的均值向量,xn表示第n个d2d通信用户的坐标,ck为第k个簇中心用户的坐标,||xn-ck||2表示第n个d2d通信用户到第k个簇中心点的欧式距离,
s103、对第n个用户,分别计算它到每个簇的分簇因子距离:
dk,n表示第n个d2d通信用户到第k个簇中心用户的分簇因子距离,选取分簇因子距离最近的簇作为第n个用户最终选择的簇,即
s104、将用户n划分到簇c*n中;
s105、对第k个簇(k=1,...,k),计算新的均值向量mk′;
s106、判断第k个簇(k=1,...,k)新的均值向量mk′与当前簇的均值向量mk是否相等;如果不相等mk≠mk′,(k=1,...,k),将新计算的均值向量替换原均值向量
s107、返回执行s103-s106,直到每一个簇的均值向量都和前一轮计算的均值向量相等,此时算法收敛;
s108、将算法收敛时的结果,作为最终分簇结果。
3、完成d2d多播分簇之后,需要在簇内选择核心用户作为d2d发射结点进行数据传输,具体如下:
为了满足数据传输速率需求,选择d2d核心用户时应综合考虑用户终端的电量、存储空间以及移动特性。
长时间驻留在一个簇内的用户,在传输过程中也有更高概率驻留,如果作为核心用户具有更高可靠性。用户的驻留概率pn与用户在簇内停留的时间有关。令驻留概率pn=tc,n/ts,n,ts,n表示第n个用户在所有簇内驻留的总历史时间,tc,n表示第n个用户在当前簇内驻留的时间。
将第n个用户的核心用户适应度fn作为衡量用户是否适合作为核心用户的参数,表示为:
其中,α、β、
根据潜在核心用户的适应度高低,选择第k个簇内适应度最高的用户作为第k个簇的核心节点,该核心节点作为d2d多播通信的传输节点;
其中,第n个用户的社交因子dn通过下式计算:
其中,
第n个用户的驻留概率pn=tc,n/ts,n,其中,ts,n表示第n个用户在所有簇内驻留的总历史时间,tc,n表示第n个用户在当前簇内驻留的时间。
第n个用户到第m个用户之间的社交属性因子可表示为:
其中,ρ是权重因子,
第n个用户和第m个用户之间平均关联时长的归一化表示:
其中,zn,m(t)表示t时刻第n个用户和第m个用户之间的内容分享状态,zn,m(t)=1表明t时刻第n个用户和第m个用户之间处于内容分享状态;否则zn,m(t)=0;δn,m(t)表示t时刻第n个用户和第m个用户之间的内容分享值。
在δt时间内,第n个用户对第m个用户的d2d通信传输收益占二者之间总的传输收益的比例
其中,cotn,m(t)表示t时刻第n个用户对第m个用户的传输收益,cotm,n(t)表示t时刻第m个用户对第n个用户的传输收益。
二、系统效用函数分析:
令φ为d2d通信核心用户的集合φ={1,2,...,m},m∈φ。ψ为接收节点的集合,ψ={1,2,...,u},用户u∈ψ。令θ={1,...,k}表示系统中所有可用子载波集合。根据香农公式,可以推导出第m个核心用户连接第u个接收用户在子载波k上的传输速率为:
其中,b为单位带宽,n0为单位带宽下的噪声,nm表示第m个d2d多播组的接收用户集合,
其中,t为传输时间。
令αu表示用户u每单位数据率的收益,βm,u为用户u连接发送节点m时消耗的带宽,γm,u用户u给发送节点m反馈时消耗的带宽,φu表示用户u选择d2d通信带来的每单位数据率的收益,ψu为用户u单位存储空间的代价。
其中,am,u表示内容分配参数:当用户u所请求的数据已经存储在发送节点m中时am,u=1,否则,am,u=0。
三、簇稳定性分析:
第m个簇的稳定性可以定义为:
其中,fm0为第m个簇的核心用户的适应值,dmu表明第m个簇内第u个用户的社交属性值,λ1,λ2为权重系数,满足λ1+λ2=1。
系统的簇平均稳定性可以表示为:
四、实施例
为了评估本发明提出的基于用户社交属性的d2d多播分簇方法(简称为sa-kca),将仿真结果与基于距离的分簇算法(简称为dbca)和传统k均值分簇算法(简称为kca)性能进行了比较。基于距离的分簇算法(dbca)基本思路是随机选取用户作为核心用户,然后每个用户选择离自己距离最近的核心用户所在的簇加入其中。传统k均值分簇算法(kca)的基本思路与本专利相同,但是按照用户之间的欧氏距离进行簇的更新和选择。
基本仿真参数如表1所示:
表1.仿真参数
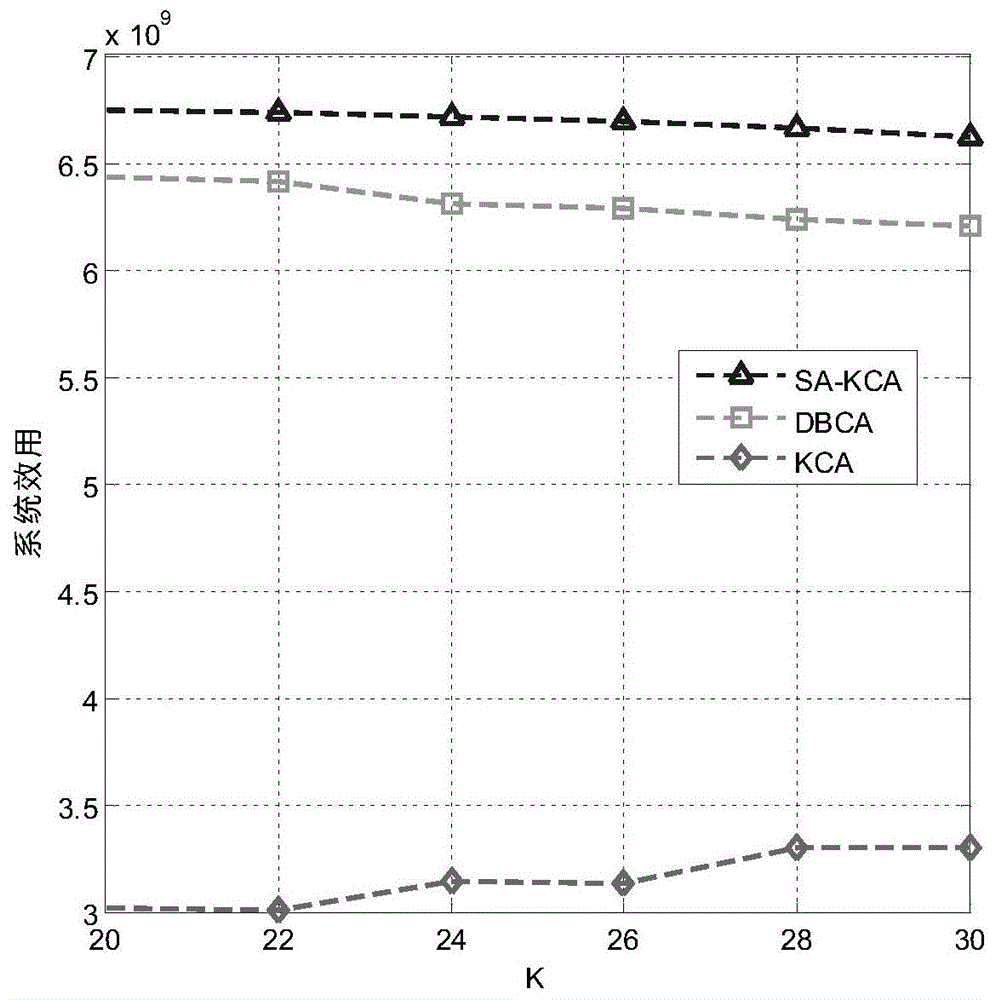
如图1所示,其描述了系统效用和簇数k之间的关系,可以看出,本发明提出的sa-kca可以获得最高的系统效用。图中,sa-kca算法下系统效用可以达到6.7*109,其他三种算法下,系统效用均低于6.5*109.这是由于sa-kca算法不仅考虑了用户之间的欧氏距离,同时将社交属性考虑进去,其中包括系统的开销,用户的能量剩余,电池剩余等因素,这些也是系统效用的重要参数,因此,sa-kca算法下系统效用可以得到保障。从图中还可以看出,sa-kca、dbca算法下系统效用随着k的增大都有稍微的降低,sa-kca下系统效用随k的增大降低幅度很小。这是由于随着d2d多播组数目的增多,每个多播组内用户数会降低,因此,多播效率降低,消耗资源数增多,从而导致了系统效用的降低。而本发明所提出的算法,分簇过程中能够尽量规避这些消耗,使得降低幅度不明显。
如图2所示的d2d通信吞吐量性能与k的曲线图。从图中可以得到以下结论,首先,sa-kca的系统获得了最高的d2d吞吐量性能,平均能达到225mbps,采用dbca的系统d2d总吞吐量性能次之,平均约为215mbps。采用kca的系统d2d总吞吐量最低,平均约为125mbps。其次,sa-kca、dbca算法下系统d2d吞吐量随着k的增大都有稍微的降低,sa-kca下d2d吞吐量随k的增大降低幅度很小。最后,kca算法下系统d2d吞吐量随着k的增大呈上升趋势,虽然kca系统下吞吐量性能虽然不会随着多播组数目k的增多而降低,但是吞吐量性能较低。
图3比较了不同算法下用户的中断概率。从图中可以看出:sa-kca,dbca系统下用户的中断概率随着k增大都有增大的趋势。sa-kca系统下用户的中断概率最低,dbca系统和kca系统下用户中断概率较高。这也证明了虽然kca系统下系统效用和吞吐量性能虽然不会随着多播组数目k的增多而降低,但是用户的性能无法得到较好保障。
图4给出了簇鲁棒性的仿真曲线。从图中可以看出,sa-kca算法下得到的簇鲁棒性性能最好,kca的鲁棒性次之,dbca算法下得到的簇鲁棒性较差。这是因为dbca算法在分簇过程中并没有考虑到用户的移动性和核心用户的剩余电量等因素,导致簇稳定性较差。
从以上仿真结果可以看出,本发明提出的算法不仅能够提高用系统效用和吞吐量性能,还提供了较高的簇鲁棒性。
- 还没有人留言评论。精彩留言会获得点赞!