基于全链路监控的时空大数据平台应用性能管理方法与流程
1.本发明涉及时空大数据领域,特别涉及基于全链路监控的时空大数据平台应用性能管理方法。
背景技术:
2.随着大数据发展的趋势,时空大数据平台作为其基础大数据重要组成部分。时空大数据是指同时具有时间和空间维度的数据,现实世界中的数据超过80%与地理位置有关。从地理信息时空多维度将感知网络层、公共设施层(iaas)、大数据层(daas)、平台层(paas)、应用层(saas)多层融合打通。伴随着微服务架构的流行,时空大数据平台在其纵向维度上进行不同层面的拆分与组合,一次服务请求往往涉及到多个层面、几种服务的汇聚与转发,横跨大数据的多个子平台。
3.时空大数据平台应用的性能管理,要求跟踪系统对在线服务的影响应足够小,同时对应用的开发者来说是不需要知道有跟踪系统的存在即无处不在的部署,另外应满足至少未来几年的服务和集群规模。当前大数据平台由于存在分阶段的多次建设,可能是由不同的团队开发、可能使用不同的编程语言来实现、可能布在了几千台服务器,横跨多个不同的数据中心;通常对性能管理存在无管理或者被动管理的情况;并且由于涉及系统多,即使有管理,也会存在管理标准不一致,要求不同,只能在自己内部进行监控,并且多数只能做到服务器和网络级别的管理,无法对应用链路和应用本身的监控状况进行实时的监控和维护。国内地理时空大数据生产管理与应用面临的数据存储组织难、数据吞吐处理难、数据集成应用难和数据生产全过程管理难等问题,无法快速定位和解决平台故障。
技术实现要素:
4.为克服上述缺点,本发明的目的在于提供一种基于全链路监控的时空大数据平台应用性能管理方法,该方法通过traceid关联时空数据资源id和运行服务器资产标志,对应用数据和环境运行情况进行监控和记录,保障时空大数据平台分散的各类数据资源从提供方到管理方的链路可靠、稳定和高效运行。
5.为了达到以上目的,本发明采用的技术方案是:基于全链路监控的时空大数据平台应用性能管理方法,使用基于zabbix、elk和zipkin的技术,以前端页面整合和后端分布式对象存储进行历史信息的同步保障、实时监控和历史特征分析数据同步保存,其特征在于:整合通用的单项技术,利用数据同步技术达到各个维度的监控和管理,包括如下步骤:
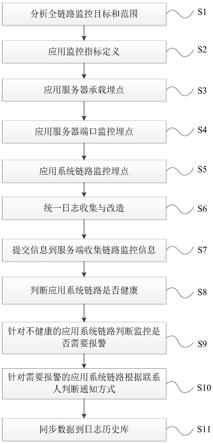
6.s1、分析全链路监控目标和范围,所述全链路监控目标根据各种服务器的运行性能参数,所述运行性能参数包括网络的吞吐量,用户服务的响应时间,故障的恢复时间标注,所述全链路监控范围包括实时日志监控和分析、承载环境监控、数据汇集链路监控和数据共享交换监控;
7.s2、定义应用系统监控指标,所述应用系统监控指标包括承载环境、链路监控和统一日志收集;
8.s3、应用服务器承载埋点,根据所述s2中定义的承载环境指标,应用服务器承载埋点并传送信息至zabbix服务端;
9.s4、应用服务器端口监控埋点,根据所述s2中定义的承载环境指标,应用服务器端口监控埋点并传送信息至zabbix服务端;
10.s5、应用系统链路监控埋点,根据所述s2中定义的链路监控指标,应用系统链路监控埋点并提交信息至zipkin服务端;
11.s6、应用系统统一日志收集与改造,基于elk调用链,根据所述s2定义的统一日志收集,将孤立的日志串在一起,重组成调用链排查过程中出现的问题;
12.s7、提交信息到服务端收集链路监控信息,提交将s3~s6中采集的信息均提交至服务端;;
13.s8、判断应用系统链路是否健康服务,服务端根据s7中提交的信息判断应用系统链路是否健康服务,包括共享平台内部系统间链路、汇聚系统到服务器资源之间链路;
14.s9、针对不健康的应用系统链路判断监控是否需要报警,各项监控指标达到阈值并保持一定时间后触发报警;
15.s10、针对需要报警的应用系统链路根据联系人判断通知方式,通知方式包括邮件、手机短信和其他sns;
16.s11、同步数据到日志历史库,将时空大数据平台的审计信息统一更新收集到日志历史库中,保障历史信息的实时监控和历史特征分析数据同步保存。
17.通过实时日志监控和分析、承载环境监控、数据汇聚链路运行监控、数据共享交换监控内容,把孤立的日志串在一起重组成调用链,监控出入口流量和基础承载,对各种来源数据的接入状态检测,日常主动状态巡检,监控所有数据采集接口服务,监控使用方调用资源状态等一系列操作,实现时空大数据平台应用性能管理。
18.优选地,所述s1中全链路监控目标包括探针的性能消耗、代码的侵入性、可扩展性和数据的分析能力;
19.(1)探针的性能消耗,apm组件服务的影响应该做到足够小,服务调用埋点本身会带来性能损耗,这需要调用跟踪的低损耗,实际中还会通过配置采样率方式,选择一部分请求去分析请求路径,在一些高度优化过的服务,即使一点点损耗也会很容易察觉到,而且有可能迫使在线服务的部署团队不得不将跟踪系统关停代码的侵入性、代码的侵入性和数据的分析能力;
20.(2)代码的侵入性、即作为业务组件,应当尽可能少入侵或者无入侵其他业务系统,对于使用方透明,减少开发人员的负担;
21.(3)可扩展性,一个优秀的调用跟踪系统必须支持分布式部署,具备良好的可扩展性,能够支持的组件越多越好,或者提供便捷的插件开发api,对于一些没有监控到的组件,应用开发者也可以自行扩展;
22.(4)数据的分析,数据的分析要快,分析的维度尽可能多;跟踪系统能提供足够快的信息反馈,就可以对生产环境下的异常状况做出快速反应;分析的全面,能够避免二次开发。
23.优选地,所述s2中应用系统监控指标包括
24.应用平台运行服务器的承载环境指标,由s3和s4中埋点采集;
25.服务器所在的网络指标,由s3和s4中埋点采集;
26.关键服务器端口的监控,应用服务之间的调用链路监控、调用频率和耗时指标,由s5中埋点采集;
27.服务健康状态的监控指标,由步骤s6收集;
28.应用系统的关键步骤和关键节点记录的审计信息收集;
29.过程中的所有日志信息记录,统一收集到elasticsearch做为介质的服务器上。
30.优选地,所述承载环境指标包括cpu的指标、内存的指标、磁盘的指标和一般性指标,所述cpu的指标包括cpu空闲时间、cpu等待时间、处理负载;所述内存的指标包括可用内存、剩余交换空间和剩余交换空间占比;所述磁盘的指标包括根目录磁盘的可用空间、根目录的可用磁盘空间比、引导区的可用空间、引导区的可用磁盘空间比;所述一般性指标包括主机名、系统信息、系统正常运行时间;
31.所述网络指标包括ens32的传入网络流量、ens32的传出网络流量;
32.所述应用服务之间的调用链路监控、调用频率和耗时指标包括应用链路和慢服务查询指标,所述应用链路指标用于监控应用或api调用链路,所述慢服务查询指标用于根据链路占用时常统计最慢前十名;
33.服务健康状态的监控指标包括日志类型监控、异常出现频率监控、自定义关键字出现频率、异常日志详细信息查询、高频出错服务和api查询指标。
34.优选地,所述s3、s4采用zabbix工作机制,zabbix是一个基于web界面的提供分布式系统监视以及网络监视功能的企业级的开源解决方案,所述zabbix包括zabbix agent和zabbix server,所述zabbix agent安装在被监控的目标服务器上,定期收集硬件信息或与操作系统有关的监控指标,并发送到zabbix server端,zabbix server将数据存储到数据库中,zabbix web根据数据在前端进行展现和绘图。
35.优选地,所述zabbix agent收集数据分为主动和被动两种模式,所述主动收集数据模式为zabbix agent请求zabbix server,获取主动的监控项列表,并主动将监控项内需要检测的数据提交给zabbix server;所述被动收集数据为zabbix server向zabbix agent请求获取监控项的数据,所述zabbix agent返回数据。
36.优选地,所述s5采用采用zipkin工作机制,zipkin用于跟踪分布式服务之间的应用数据链路,分析处理延时,帮助改进系统的性能和定位故障,具体步骤如下
37.s51、请求到来生成一个全局traceid,关联本次请求处理的关键时空数据资源标志和所运行服务器的资产唯一标志,通过所述traceid可以串联起整个调用链,一个所述traceid代表一次请求;
38.s52、生成一个spanid,所述spanid记录调用父子关系,每个服务会记录下parent id和spanid,通过他们可以组织一次完整调用链的父子关系;
39.s53、要一个没有parent id的spanid成为root span,所述root span为调用链入口;
40.s54、traceid、spanid和parent id可用全局唯一的64位整数表示;
41.s55、整个调用过程中每个请求都要透传所述traceid和spanid;
42.s56、每个服务将该次请求附带的所述traceid和附带的spanid作为parent id记录下,并且将自己生成的spanid记录下;
43.s57、查看某次完整的调用则只要根据traceid查出所有调用记录,然后通过parent id和spanid组织起整个调用父子关系,最终结合关键数据资源和资产资源,可以明确资源使用分布和资源的流传路径。
44.优选地,所述s6包括调用路径分析和调用去向分析,过程采用elk工作机制,具体步骤如下
45.s61、logstash通过输入安装在应用中的插件从多种数据源获取数据,一个logstash数据搜集节点扩展到多个,分布于多台机器,将解析好的数据发送到elasticsearch server进行存储;
46.s62、elasticsearch把收集的数据统一存储到对应的介质中,并提供搜集、分析、存储数据三大功能,开放rest和java api结构,提供高效搜索功能和可扩展的分布式系统,它构建于apache lucene搜索引擎库之上;
47.s63、kibana利用elasticsearch的rest接口来检索数据,允许用户创建他们自己数据的定制仪表板视图,并允许他们以特殊的方式查询和过滤数据,可以提供各种web图形界面用于搜索、分析和可视化存储在elasticsearch指标中的日志数据。
48.优选地,所述s8中应用系统链路是否健康的判断标准如下
49.应用所在服务器的监控状况,根据服务器经验阈值来判断;
50.应用本身运用的监控状况,判断包括应用服务端口是否正常、应用的health检查服务能否正常返回up状态,应用本身处理请求的响应时间是否正常、应用请求对应的上游服务分布是否均衡。
51.优选地,根据所述s3~s7中埋点信息和日志记录检查与反馈应用监控指标,所述s8~s10包括事前检查与反馈、事中检查与反馈和事后检查与反馈。事前检查与反馈根据监控历史数据,预测系统链路健康趋势,进行应急预案演练;事中检查与反馈将收集的各种监控记录指标和数据作为问题排查和整改方案的数据依据,判断应用系统链路健康状况并反馈报警的必要性和通知方式,全面还原故障现场,除吞吐量、响应时间和错误数外,可再现故障发生时的流量、并发用户数、总连接数、并发连接数和错误详情,跟踪记录每个错误,包括请求url、返回码、sql语句、绑定参数或变量,帮助运维人员快速隔离问题域;事后检查与反馈根据所收集的监控指标数据形成专业的数据分析和统计报告,可看到各项指标的增量,发现系统的性能趋势,根据增量趋势分析在未来的什么时间系统会出现性能瓶颈,帮助用户找到出现异常的根源,进而安排什么时间做什么样的策略来解决这些瓶颈,促进运维管理体系的改进,避免和减少同类问题的发生,让运维从被动转为主动,从安排下一步应急预案策略和类似新项目上线和运维角度来形成知识库。
52.上述s1为全链路监控目标和范围分析;s2~s7为应用监控指标采集和定义;s8~s10为应用系统链路健康检查与反馈;s11日志历史库数据同步。
53.本发明的有益效果是:本发明采用全链路监控性,能从整体到局部维度瞄准吞吐量、响应时间、错误记录日志等关键指标,实现请求链路追踪、故障快速定位、依赖合理优化、链路数据分析与阶段耗时可视化,帮助时空大数据平台自动化、智能化、流程化地进行运维与管理工作。通过统一的微服务治理规范,通过traceid关联时空数据资源id和运行服务器资产标志,实现数据的收集和分发、应用跟踪和监控,保障出现问题和故障时,能够快速发现和定位故障点,最终实现以数据为核心价值的面向服务的架构和智慧运营的效果。
附图说明
54.图1为本实施例的流程示意图。
具体实施方式
55.下面对本发明的较佳实施例进行详细阐述,以使本发明的优点和特征能更易于被本领域技术人员理解,从而对本发明的保护范围做出更为清楚明确的界定。
56.参照附图1,基于全链路监控的时空大数据平台应用性能管理方法,使用基于zabbix、elk和zipkin的技术,以前端页面整合和后端分布式对象存储进行历史信息的同步保障、实时监控和历史特征分析数据同步保存。整合通用的单项技术,利用数据同步技术达到各个维度的监控和管理。通过实时日志监控和分析、承载环境监控、数据汇聚链路运行监控、数据共享交换监控内容,把孤立的日志串在一起重组成调用链,监控出入口流量和基础承载,对各种来源数据的接入状态检测,日常主动状态巡检,监控所有数据采集接口服务,监控使用方调用资源状态等一系列操作,实现时空大数据平台应用性能管理。包括如下步骤:
57.s1、分析全链路监控目标和范围,全链路监控目标根据各种服务器的运行性能参数,运行性能参数包括网络的吞吐量,用户服务的响应时间,故障的恢复时间标注,全链路监控范围包括实时日志监控和分析、承载环境监控、数据汇集链路监控和数据共享交换监控。
58.s2、定义应用系统监控指标,应用系统监控指标包括承载环境、链路监控和统一日志收集。
59.s3、应用服务器承载埋点,根据s2中定义的承载环境指标,应用服务器承载埋点并传送信息至zabbix服务端。
60.s4、应用服务器端口监控埋点,根据s2中定义的承载环境指标,应用服务器端口监控埋点并传送信息至zabbix服务端。
61.s5、应用系统链路监控埋点,根据s2中定义的链路监控指标,应用系统链路监控埋点并提交信息至zipkin服务端。
62.s5采用zipkin工作机制,zipkin用于跟踪分布式服务之间的应用数据链路,分析处理延时,帮助改进系统的性能和定位故障,具体步骤如下
63.s51、请求到来生成一个全局traceid,关联本次请求处理的关键时空数据资源标志和所运行服务器的资产唯一标志,通过traceid可以串联起整个调用链,一个traceid代表一次请求;
64.s52、生成一个spanid,spanid记录调用父子关系,每个服务会记录下parent id和spanid,通过他们可以组织一次完整调用链的父子关系;
65.s53、要一个没有parent id的spanid成为root span,root span为调用链入口;
66.s54、traceid、spanid和parent id可用全局唯一的64位整数表示;
67.s55、整个调用过程中每个请求都要透传traceid和spanid;
68.s56、每个服务将该次请求附带的traceid和附带的spanid作为parent id记录下,并且将自己生成的spanid记录下;
69.s57、查看某次完整的调用则只要根据traceid查出所有调用记录,然后通过
parent id和spanid组织起整个调用父子关系,最终结合关键数据资源和资产资源,可以明确资源使用分布和资源的流传路径。
70.s6、应用系统统一日志收集与改造,基于elk调用链,根据s2定义的统一日志收集,将孤立的日志串在一起,重组成调用链排查过程中出现的问题。
71.s6包括调用路径分析和调用去向分析,过程采用elk工作机制,具体步骤如下
72.s61、logstash通过输入安装在应用中的插件从多种数据源获取数据,一个logstash数据搜集节点扩展到多个,分布于多台机器,将解析好的数据发送到elasticsearch server进行存储;
73.s62、elasticsearch把收集的数据统一存储到对应的介质中,并提供搜集、分析、存储数据三大功能,开放rest和java api结构,提供高效搜索功能和可扩展的分布式系统,它构建于apache lucene搜索引擎库之上;
74.s63、kibana利用elasticsearch的rest接口来检索数据,允许用户创建他们自己数据的定制仪表板视图,并允许他们以特殊的方式查询和过滤数据,可以提供各种web图形界面用于搜索、分析和可视化存储在elasticsearch指标中的日志数据。
75.s7、提交信息到服务端收集链路监控信息,提交将s3~s6中采集的信息均提交至服务端。
76.s8、判断应用系统链路是否健康服务,服务端根据s7中提交的信息判断应用系统链路是否健康服务,包括共享平台内部系统间链路、汇聚系统到服务器资源之间链路;
77.s9、针对不健康的应用系统链路判断监控是否需要报警,各项监控指标达到阈值并保持一定时间后触发报警。如服务器cpu空闲率连续5分钟少于20%、网络延时连续5次超过100毫秒、应用请求联系出现5次超过200毫秒等情况都会触发,并且系统支持根据管理的要求动态定制触发阈值。
78.s10、针对需要报警的应用系统链路根据联系人判断通知方式,通知方式包括邮件、手机短信和其他sns。
79.s11、同步数据到日志历史库,将大数据平台承载环境、运行服务的监控状态、运行服务的调用链路和故障点位置及快速恢复记录、应用系统的关键步骤和关键节点记录的审计信息统一更新收集到日志历史库中,保障历史信息的实时监控和历史特征分析数据同步保存。
80.通过实时日志监控和分析、承载环境监控、数据汇聚链路运行监控、数据共享交换监控内容,把孤立的日志串在一起重组成调用链,监控出入口流量和基础承载,对各种来源数据的接入状态检测,日常主动状态巡检,监控所有数据采集接口服务,监控使用方调用资源状态等一系列操作,实现时空大数据平台应用性能管理。
81.s1中全链路监控目标是保障分散的各类数据资源从提供方到管理方的链路可靠、稳定和高效运行,包括探针的性能消耗、代码的侵入性、可扩展性和数据的分析能力;
82.(1)探针的性能消耗,apm组件服务的影响应该做到足够小,服务调用埋点本身会带来性能损耗,这需要调用跟踪的低损耗,实际中还会通过配置采样率方式,选择一部分请求去分析请求路径,在一些高度优化过的服务,即使一点点损耗也会很容易察觉到,而且有可能迫使在线服务的部署团队不得不将跟踪系统关停代码的侵入性、代码的侵入性和数据的分析能力;
83.(2)代码的侵入性、即作为业务组件,应当尽可能少入侵或者无入侵其他业务系统,对于使用方透明,减少开发人员的负担;
84.(3)可扩展性,一个优秀的调用跟踪系统必须支持分布式部署,具备良好的可扩展性,能够支持的组件越多越好,或者提供便捷的插件开发api,对于一些没有监控到的组件,应用开发者也可以自行扩展;
85.(4)数据的分析,数据的分析要快,分析的维度尽可能多;跟踪系统能提供足够快的信息反馈,就可以对生产环境下的异常状况做出快速反应;分析的全面,能够避免二次开发。
86.s2中应用系统监控指标包括
87.应用平台运行服务器的承载环境指标,由s3和s4中埋点采集;
88.服务器所在的网络指标,由s3和s4中埋点采集;
89.关键服务器端口的监控,应用服务之间的调用链路监控、调用频率和耗时指标,由s5中埋点采集;
90.服务健康状态的监控指标,由步骤s6收集;
91.应用系统的关键步骤和关键节点记录的审计信息收集;
92.过程中的所有日志信息记录,统一收集到elasticsearch做为介质的服务器上。
93.承载环境指标包括(服务器以centos7.2为原型)
94.(1)cpu的指标
95.(1.1)cpu空闲时间:通常定义为小于百分之15,产生严重问题;
96.(1.2)cpuio等待时间:通常定义为5分钟内平均大于20%,产生告警;
97.(1.3)处理负载(每个核心平均一分钟内):通常5分钟内平均大于5,产生告警。
98.(2)内存的指标
99.(2.1)可用内存:通常定义为小于128m,产生一般问题,也可以根据应用特性支持本系数;
100.(2.2)剩余交换空间通常定义为小于128m,产生问题;
101.(2.3)剩余交换空间占比:通常小于30%,产生告警提示。
102.(3)磁盘的指标
103.(3.1)根目录磁盘的可用空间:通常定义为可用磁盘空间小于5g产生问题;
104.(3.2)根目录的可用磁盘空间比:通常定义为小于20%,产生问题;
105.(3.3)引导区的可用空间:常定义为可用磁盘空间小于5g产生问题;
106.(3.4)引导区的可用磁盘空间比:通常定义为小于20%,产生问题;
107.(3.5)其他磁盘也可以根据以上给出的磁盘剩余空间和磁盘空间比两个维度来定义。
108.(4)一般性指标
109.(4.1)主机名:当被修改,会产生信息;
110.(4.2)系统信息:主机信息更改,产生信息;
111.(4.3)系统正常运行时间:重新启动主机,产生信息。
112.网络指标包括
113.(1)ens32的传入网络流量:传入网络流量大于5m,产生告警;
114.(2)ens32的传出网络流量:传出网络流量大于5m,产生告警。
115.应用服务之间的调用链路监控、调用频率和耗时指标包括
116.(1)应用链路:监控应用或api调用链路;
117.(2)慢服务查询指标:根据链路占用时常统计最慢前十名。
118.服务健康状态的监控指标包括
119.(1)日志类型监控:统计各种日志信息的占比;
120.(2)异常出现频率监控:统计各个时间段内出现异常消息的比例;
121.(3)自定义关键字出现频率(配合日志规范):统计一些关键字在一定时间内出现的次数;
122.(4)异常日志详细信息查询:根据关键字查询异常明细;
123.(5)高频出错服务和api查询:根据统计日志的服务出错情况统计服务质量。
124.s3、s4采用zabbix工作机制,zabbix是一个基于web界面的提供分布式系统监视以及网络监视功能的企业级的开源解决方案,zabbix包括zabbix agent和zabbix server,zabbix agent安装在被监控的目标服务器上,定期收集硬件信息或与操作系统有关的监控指标,并发送到zabbix server端,zabbix server将数据存储到数据库中,zabbix web根据数据在前端进行展现和绘图。zabbix agent收集数据分为主动和被动两种模式,主动收集数据模式为zabbix agent请求zabbix server,获取主动的监控项列表,并主动将监控项内需要检测的数据提交给zabbix server;被动收集数据为zabbix server向zabbix agent请求获取监控项的数据,zabbix agent返回数据。
125.s8中应用系统链路是否健康的判断标准如下
126.应用所在服务器的监控状况,根据服务器经验阈值来判断;
127.应用本身运用的监控状况,判断包括应用服务端口是否正常、应用的health检查服务能否正常返回up状态,应用本身处理请求的响应时间是否正常、应用请求对应的上游服务分布是否均衡。
128.根据s3~s7中埋点信息和日志记录检查与反馈应用监控指标,s8~s10包括事前检查与反馈、事中检查与反馈和事后检查与反馈。事前检查与反馈根据监控历史数据,预测系统链路健康趋势,进行应急预案演练;事中检查与反馈将收集的各种监控记录指标和数据作为问题排查和整改方案的数据依据,判断应用系统链路健康状况并反馈报警的必要性和通知方式,全面还原故障现场,除吞吐量、响应时间和错误数外,可再现故障发生时的流量、并发用户数、总连接数、并发连接数和错误详情,跟踪记录每个错误,包括请求url、返回码、sql语句、绑定参数或变量,帮助运维人员快速隔离问题域;事后检查与反馈根据所收集的监控指标数据形成专业的数据分析和统计报告,可看到各项指标的增量,发现系统的性能趋势,根据增量趋势分析在未来的什么时间系统会出现性能瓶颈,帮助用户找到出现异常的根源,进而安排什么时间做什么样的策略来解决这些瓶颈,促进运维管理体系的改进,避免和减少同类问题的发生,让运维从被动转为主动,从安排下一步应急预案策略和类似新项目上线和运维角度来形成知识库。
129.上述s1为全链路监控目标和范围分析;s2~s7为应用监控指标采集和定义;s8~s10为应用系统链路健康检查与反馈;s11日志历史库数据同步。
130.全链路监控目标和范围分析:全链路监控目标是保障分散的各类数据资源从提供
方到管理方的链路可靠、稳定和高效运行;范围包含实时日志监控和分析、承载环境监控、数据汇聚链路运行监控、数据共享交换监控。
131.应用监控指标采集和定义:应用监控指标定义了承载环境、链路监控与统一日志收集两大部分。应用服务器承载埋点、应用服务器端口监控埋点信息指的是承载环境指标,即cpu、磁盘、网络、内存与一般指标,根据zabbix工作机制,将这些信息提交到zabbix服务端。cpu指标包含每秒上下切换、cpu空闲时间、cpuio等待时间、处理器负载(每个核心平均1分钟);磁盘指标包含引导区磁盘空间容量、引导区可用磁盘空间百分比、根目录的可用磁盘空间容量、根目录上的可用磁盘空间百分比、网络指标包含ens32的传入网络流量、ens32的传出网络流量;内存的指标包括可用内存、剩余交换空间、剩余交换空间、总内存、总交换空间;一般指标包含主机名、系统信息、系统正常正常运行时间。应用系统链路监控埋点信息指的是应用链路、慢服务查询指标,根据zipkin工作机制,提交信息到zipkin服务端。应用链路指标用于监控应用或api调用链路;慢服务查询指标用于根据链路占用时常统计最慢top10。
132.应用系统统一日志收集与改造信息指的是日志类型监控、异常出现频率监控、自定义关键字出现频率(配合日志规范)、异常日志详细信息查询、高频出错服务和api查询指标,根据elk工作机制,利用logstash收集日志数据,elasticsearch将收集的数据统一存储到对应的介质并提供搜索功能,kibana通过各种web的图形界面展示存储在elasticsearch指标中的日志数据。日志类型监控指标用于统计各种日志信息的占比;异常出现频率监控指标用于统计各个时间段内出现异常消息的比例;自定义关键字出现频率(配合日志规范)指标用于统计一些关键字在一定时间内出现的次数;异常日志详细信息查询指标用于根据关键字查询异常明细;高频出错服务和api查询指标用于根据统计日志的服务出错情况统计服务质量。
133.应用监控指标的检查与反馈:应用系统链路健康检查包括事前检查与反馈、事中检查与反馈和事后检查与反馈三种。事前根据监控历史数据,预测系统链路健康趋势,进行应急预案演练;事中检查与反馈需要将收集的各种监控记录指标和数据作为问题排查和整改方案的数据依据,判断应用系统链路健康状况并反馈报警的必要性和通知方式,全面还原故障现场,除吞吐量、响应时间和错误数外,还能再现故障发生时的流量、并发用户数、总连接数、并发连接数和错误详情,跟踪记录每个错误,包括请求url、返回码、sql语句、绑定参数或变量,帮助运维人员快速隔离问题域;事后检查与反馈根据所收集的监控指标数据形成专业的数据分析和统计报告,可以看到各项指标的增量,发现系统的性能趋势,根据增量趋势分析在未来的什么时间系统会出现性能瓶颈,帮助用户找到出现异常的根源,进而安排什么时间做什么样的策略来解决这些瓶颈,促进运维管理体系的改进,避免和减少同类问题的发生,让运维从被动转为主动,从安排下一步应急预案策略和类似新项目上线和运维角度来形成知识库。
134.以上实施方式只为说明本发明的技术构思及特点,其目的在于让熟悉此项技术的人了解本发明的内容并加以实施,并不能以此限制本发明的保护范围,凡根据发明精神实质所做的等效变化或修饰,都应涵盖在本发明的保护范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1