一种集中收集分析蜜罐探针日志的技术的制作方法
1.本发明属于计算机信息技术领域,具体涉及一种集中收集蜜罐探针日志的方法。
背景技术:
2.现有的蜜罐日志一般存储于磁盘文件中、关系数据库中、或nosql中,大部分蜜罐日志的存储就很少利用起来,由于缺少专门的dsl(domain specific language)查询语言,导致蜜罐日志只是静态的存储,没有形成分析报表提供给企业来决策,或由于开发报表的成本高而放弃。
3.原有的日志存储于关系数据库中,在面对大日志时,分库分表的实现比较复杂,同时分库分表后,原有的sql语句可能不再有效,需要重新编写sql语句,由于复杂的sql语句不利于debug,常常导致开发工作周期加大,影响了可视化报表作为重点工作来开发。
技术实现要素:
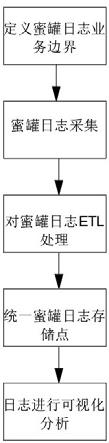
4.本发明目的在于,针对现有技术的不足,提供了一种集中收集分析蜜罐探针日志的方法,使单机或多机存储系统在维持较高的读请求响应性能的同时,减少日志报表系统开发难度,主要步骤如下:步骤1、定义蜜罐日志业务边界。黑客攻击蜜罐探针时会使用相应协议及操作码,所有的攻击链接、数据包、协议头部信息等攻击元数据以半结构化方式存储。
5.步骤2、蜜罐日志采集。探针记录的日志先落盘,日志采集程序将日志的落盘路径添加到监控列表中,使日志文件保持着打开的状态,有close_inactive通知才关闭文件,文件状态及偏移量的监控动作由日志文件收割机来负责。由于日志文件处于打开状态,接着日志采矿程序就能读取到日志文件内容,并将读取出来的原始日志数据投递下一个阶段进一步处理。
6.步骤3、对蜜罐日志etl处理。对原始日志进行过滤处理,支持正则表达式、geoip计算、过滤多余字段等功能。日志经过该阶段的转换处理后会变成结构化的数据格式,该阶段的数据将投递到下一个阶段,用于存储。
7.步骤4、统一蜜罐日志存储点。将所有探针记录的日志在变成结构化数据后,都投递到统一的接口来实现存储,存储过程中需要建立一些索引,以加速后续搜索。
8.步骤5、日志进行可视化分析。主要是根据已经存储好的结构化数据进行垂直投影、水平选择、聚合计算方法来实现日志报表的统计。
9.本发明充分利用了elastic stack技术栈来实现蜜罐日志的采集、转换过滤、集中存储、可视化报表开发。整个流程实现模块化操作,开发工作量显著下降,能为公司节约开发人力成本。蜜罐日志文件的监控和读取不需要开发人员去编写代码监控日志文件内容的变化及文件读取游标的偏移量。蜜罐日志transform部分只需编写正式表达来就能把日志内容从非结构化变为结构化的数据,从而当作最终的数据存储到elasticsearch中。由于elasticsearch提供了专有的dsl语言,所以对报表数据部分能直接通过编写dsl语句来聚
合成可视化报表所需要的数据。
附图说明
10.图1为一种集中收集分析蜜罐探针日志的方法的工作流程图。
具体实施方式
11.步骤1、在node1节点的主机中启动各个协议(例如modbus协议)的蜜罐探针容器。
12.步骤2、将容器中运行的蜜罐探针程序产生的日志挂载到指定的宿主机某个目录下,对应的logs目录将存储其中,以协议名.log的格式进行存储。如图中modbus.log、http.log、ssh.log等。
13.步骤3、filebeat读取2中设置的路径下的日志文件。filebeat对日志文件进行实时的监控并一行一行的读取日志文件里的内容。日志文件内容必须以\n作为一行的换行符号,采集流程即为采集原理。
14.步骤4、filebeat采集到的原始日志内容投递到下一个阶段的logstash。该阶段主要解决日志的结构化问题,将日志文件中的非结构化日志内容转换成结构化数据格式。只有结构化的数据格式才方便查询、聚合计算、添加索引等。
15.步骤5、将第4步中的结构化数据存储于elasticsearch中,由于存入的数据是结构化的数据格式,所以方便通过利用elasticsearch自带的dsl查询语句来进行数据分析和聚合计算。
16.步骤6、步骤ics-dashboard看板用于蜜罐日志的可视化统计。比如将攻击按ip地址排序、按城市名称排序、统计攻击操作码、按时间维护展示最近天、周、月、年的攻击情况等。ics-dashboard看板所需要的展示数据都可以通过dsl语句来实现,从而提高了开发效率。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1