基于密度聚类的非正交多址接入用户聚类方法与流程
本发明属于无线通信中的非正交多址接入技术,具体涉及一种基于密度聚类的非正交多址接入用户聚类方法。
背景技术:
受限于信号处理技术和系统复杂度的约束,在第一代至第四代无线通信系统中均采用正交多址接入(orthogonalmultipleaccess,oma)方案。而为了满足新一代移动通信系统对传输速率及传输可靠性的需求,非正交多址接入(non-orthogonalmultipleaccess,noma)方案被认为是oma的更优替代者。在oma中,不同用户的信号在信道资源上是彼此正交的,即每个用户占据各自的信道资源;而在noma中,允许多个用户复用信道资源进行通信,在接收端采用串行干扰消除(successiveinterferencecancellation,sic)技术得到所需要的信号。由于用户间信道资源的复用,不可避免地会出现用户间彼此的干扰,因此必须借助各种能够有效减少甚至消除干扰的方法来提升noma系统的性能。在多天线noma下行通信场景中,通过对用户聚类可以有效地减少聚类间的干扰,提升系统的整体信息传输速率。选择合适的聚类方法对于系统整体性能的提升有着重要的意义,考虑到现有的非基于密度的聚类方法存在对初始值敏感、无法识别非凸形状聚类等缺点,本发明采用基于密度聚类的noma场景用户聚类方法,该方法能够得到比其它聚类方案更合理的聚类效果,并能够适用于更复杂的场景。
技术实现要素:
发明目的:针对上述现有技术对初始值敏感、无法识别非凸形状聚类问题,本发明提供一种基于密度聚类的非正交多址接入用户聚类方法。
一种基于密度聚类的非正交多址接入用户聚类方法,所述方法基于密度的带有噪声的空间聚类方法,包括如下步骤:
(1)初始化处理,设定超参数ε和ω划分聚类,并计算数据集x中数据点密度ρ(xi);
(2)执行dnscan方法进行聚类,标记噪声点或对核心点进行二次划分处理;
(3)完成聚类划分,对每个聚类中的核心点数据取算术平均作为该聚类的质心数据,并将当前仍存在的不属于任何聚类的噪声点和不确定归属的边缘点划分至距其欧式距离最近的核心点所在的聚类。
进一步的,步骤(2)具体如下:
(21)从未遍历状态的数据点中任取一个xi,将其标记为“已遍历”;
(22)若ρ(xi)<ω,则暂时将对应节点记作噪声点;
(23)若ρ(xi)≥ω,则将该节点标记为核心点并将其划分至一个新聚类,同时依次判断其ε邻域范围内的所有节点,任取一个xj,将其标记为“已遍历”:
(24)完成当前聚类和数据点的遍历,跳转至步骤(1)开始下一个聚类,直至所有数据点均为“已遍历”状态,结束聚类。
更进一步的,步骤(23)具体步骤如下:
(231)若该节点没有被处理过或为噪声点,则将其划分至步骤(23)中核心点所在聚类,并暂时记作边缘点;
(232)若ρ(xj)≥ω,则将其记作核心点,并依次判断其ε邻域范围内的所有节点,重复执行(231)和(232)。
所述方法中,对于第m个聚类中的第i个用户而言,其接收到的信号表达式如下:
其中,v0为加性高斯白噪声,其功率谱密度n0由信道估计得到,pm,i为第m个聚类中第i个用户所分得的功率大小,sm,i为基站发送给第m个聚类中第i个用户的信号,
进一步的,所述方法包括在发送端采用非正交传输,主动引入干扰信号,在接收端通过串行干扰删除实现正确解调,其中基站给其它聚类中用户的干扰信号表达式如下:
有益效果:与现有技术相比,本发明中基于密度聚类的noma场景用户聚类方法,能够利用dbscan方法完成用户聚类。其显著效果包括如下几点:
(1)本发明可以完成任意形状的空间聚类且不受到噪声数据点的干扰,而现有的非基于密度的聚类方法一般只能完成凸形状的聚类,且对噪声数据点的干扰敏感。
(2)现有方法一般对聚类初始值的选择敏感,即可能需要多次重复聚类才能确定最终的聚类结果,而本发明中方法的聚类结果不会因初始值的不同对聚类结果产生影响。
(3)基于dbscan的聚类方法无需提前指定聚类数目,聚类数目可以通过密度聚类过程自动确定,这在具有复杂用户分布的实际场景中具有很重要的意义。
附图说明
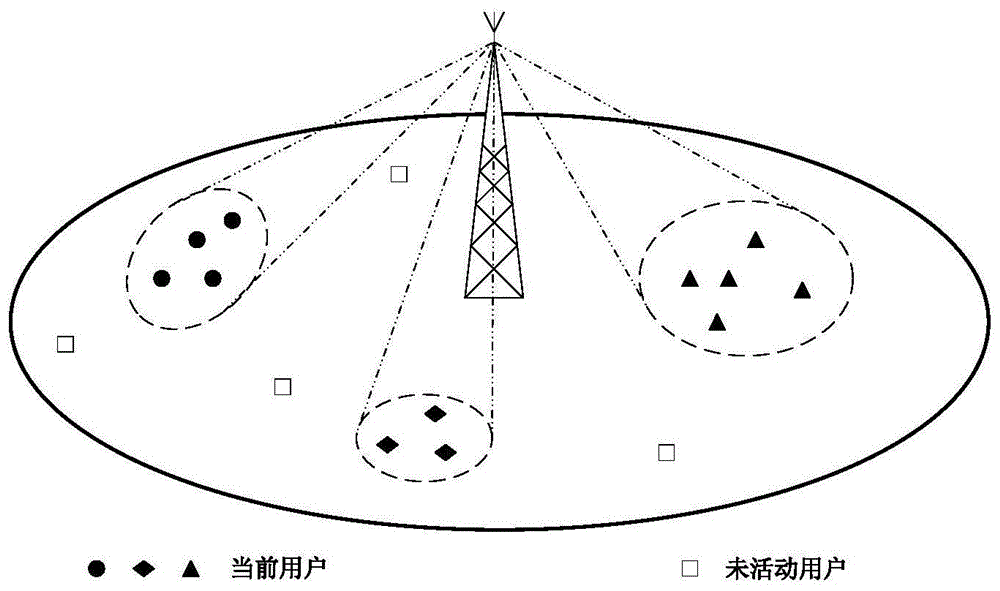
图1是本发明所适用的多天线noma下行通信场景图;
图2是实施例中用户分布示意图;
图3是实施例中未遍历”状态的数据点中任选取示意图;
图4是实施例中“已遍历”转态的数据点分布示意图;
图5是实施例中聚类完成的数据点分布示意图;
图6是实施例中所有数据点均为“已遍历”状态结束聚的数据点分布图。
具体实施方式
为了详细的说明本发明所述的技术方案,下面结合说明书附图及具体实施例做进一步的阐述。
本发明所适用的多天线noma下行通信场景如图1所示,基站通过参与通信用户的位置信息完成聚类,对于第m个聚类中的第i个用户而言,其接收到的信号为:
其中,v0为加性高斯白噪声,其功率谱密度n0可由信道估计得到。pm,i为第m个聚类中第i个用户所分得的功率大小,可由聚类内部功率分配方案获得。sm,i为基站发送给第m个聚类中第i个用户的信号。
上述用户接收信号的表达式(1)式中,第一项
dbscan方法是一种典型的基于密度聚类的方法,其核心思想是用一个数据点的ε邻域内的邻居点个数来衡量该点所在空间的密度。现有的非基于密度的聚类方法大都是基于数据之间的距离进行聚类,聚类结果呈现圆形或球状。dbscan方法可以在有噪声的数据中完成任意不规则形状的聚类,并且在聚类时不需要提前指定聚类的数目,以上特点使得该方法有着更为广泛的应用。
dbscan方法中有两个重要超参数:邻域半径ε和核心点最小阈值ω。在场景不发生改变的情况下,ε和ω在首次选择后可以反复使用。定义数据集合:
x={x1,x2,…,xn}(2)
其中x1为包含第一个用户位置信息的数据,用户的位置信息可由坐标、经纬度、海拔等物理参数表示;x2为包含第二个用户位置信息的数据,以此类推。假设y为数据集合x中的一个数据点,即y∈x,我们称
ρ(y)=|nε(y)|(3)
为数据点y的密度,其中nε(y)代表y的ε邻域内所包含其它数据点的个数,其取值依赖于ε的大小。若ρ(y)≥ω,则称y为x的核心点。若y不是核心点,且y落在某个核心点的ε邻域内,则称y为x的一个边界点。在集合x中,既不是核心点也不是边界点的数据点称为噪声点。核心点位于聚类的内部,它确定无误地属于某个特定的聚类;噪声点是数据集中的干扰数据,它不属于任何一个聚类,我们在实际操作时将噪声点划分至距离最近的聚类;边界点是聚类的边缘地带,其归属并不明确,我们也将其划分至距离最近的聚类中。
实施例1
一种基于密度聚类的非正交多址接入用户聚类方法,所述方法基于基于密度的带有噪声的空间聚类方法,包括如下步骤:
(1)初始化处理,设定超参数ε和ω划分聚类,并计算数据集x中数据点密度ρ(xi);
(2)执行dnscan方法进行聚类,标记噪声点或对核心点进行二次划分处理;
(3)完成聚类划分,对每个聚类中的核心点数据取算术平均作为该聚类的质心数据,并将当前仍存在的不属于任何聚类的噪声点和不确定归属的边缘点划分至距其欧式距离最近的核心点所在的聚类。
具体步骤如下:
第一步:初始化,包括如下流程:
(1)选取超参数ε和ω。若希望聚类的划分尽量细致,则应选择较小的ε值,而选择较大的ε值可以忽略样本点中的部分差异,用更少的聚类数目划分样本点。在实际中一般需要在多组试验值里面选择一个合适的ε值。ε参数没有一个相对明确的选取原则,这里只做了定性的表述,本领域技术人员根据具体的数据集来确定。ω的选取有一个指导性的原则,即ω≥dim+1,这里dim表示数据集x的中数据的空间维度。
(2)将数据集x中所有数据点标记为“未遍历”状态,并计算每个数据点的密度ρ(xi)。
第二步:执行dnscan方法进行聚类。本步骤包括如下流程:
(1)从“未遍历”状态的数据点中任取一个xi,将其标记为“已遍历”;
(2)若ρ(xi)<ω,则暂时将该节点记作噪声点;
(3)若ρ(xi)≥ω,则将该节点标记为核心点并将其划分至一个新聚类,同时依次考察其ε邻域范围内的所有节点,任取一个xj,将其标记为“已遍历”:
(3.1)若该节点没有被处理过或为噪声点,则将其划分至(3)中核心点所在聚类,并暂时记作边缘点;
(3.2)若ρ(xj)≥ω(即xj也满足核心点条件),则将其记作核心点,并依次考察其ε邻域范围内的所有节点,重复执行(3.1)和(3.2);
(4)此时一个聚类已经完成,跳转至该步骤(1)开始下一个聚类,直至所有数据点均为“已遍历”状态结束聚类。
聚类完成后,我们对每个聚类中的核心点数据取算术平均作为该聚类的质心数据,并将当前仍存在的不属于任何聚类的噪声点和不确定归属的边缘点划分至距其欧式距离最近的核心点所在的聚类。基站依照每个聚类的质心数据来估计每个聚类的信号到达方向,借助基站所发射的具有方向性的信号波束,使每个聚类中用户可以正常接收所属聚类的信号,而收到其它聚类的干扰信号则会被“削弱”,如此一来,每个用户所受到的其它聚类用户带来的干扰((1)式中第三项)会明显减少,用户的速率和系统整体信息传输速率会相应提升。
实施例2
本发明中基于密度聚类的非正交多址接入场景用户聚类方法,下面以图2中所示用户分布为例进行说明。本实施例中仅使用数据点在二维平面上的分布信息构成数据集x,聚类过程包括如下步骤:
第一步:初始化,具体包括如下流程:
(1)选定超参数ε和ω。这里在多组试验值中选择ε=1并依照ω≥dim+1的原则,选择ω=3;
(2)将数据集x中所有数据点标记为“未遍历”状态,并计算每个数据点的密度ρ(xi);
第二步:执行dnscan方法进行聚类,具体包括如下流程:
(1)从“未遍历”状态的数据点中任取一个,如图3所示,记为x1。
(2)这里不满足ρ(x1)<ω,因此x1不是噪声点。进而执行下一步。
(3)x1满足ρ(x1)≥ω,因此将x1标记为核心点并将其划分至一个新聚类,同时依次考察其ε邻域范围内的x2、x3和x4,将它们标记为“已遍历”,如图4所示:
(3.1)上述3个节点均没有被处理过,暂时将它们记作边缘点,并将它们划分至(3)中核心点x1所在聚类。
(3.2)3个节点中,x3和x4满足ρ(xi)≥ω(即x3和x4也满足核心点条件),则将它们更改为核心点,并依次考察其ε邻域范围内的所有节点,重复执行(3.1)和(3.2)。
(4)如图5所示,此时一个聚类已经完成,跳转至该步骤(1)开始下一个聚类,直至所有数据点均为“已遍历”状态结束聚类。图6所示为最终聚类结果。
聚类完成后,我们对每个聚类中的核心点数据取算术平均作为该聚类的质心数据,并将当前仍存在的不属于任何聚类的噪声点及归属不明确的边缘点划分至距其欧式距离最近的核心点所在的聚类。基站依照每个聚类的质心数据来估计每个聚类的信号到达方向,借助基站所发射的具有方向性的信号波束,使用户接收到的不同聚类用户的信号分别被“加强”或被“削弱”,本实施例中cluster1中用户可以正常接收该聚类内用户的信号,而收到cluster2中用户的干扰信号则会被明显“削弱”,如此一来,每个用户所受到的其它聚类用户带来的干扰((1)式中第三项)会明显减少,用户的速率和系统整体信息传输速率会相应提升。
本发明所述方法能够完成任意形状的空间聚类且不受到噪声数据点的干扰。从而有效减少noma下行通信场景中的聚类间干扰,提高系统整体的信息传输速率。
- 还没有人留言评论。精彩留言会获得点赞!