针对大数据处理平台Hadoop的攻击方法与流程
本发明属于计算机领域中的大数据安全领域,涉及针对大数据处理平台hadoop的攻击方法。
背景技术:
随着云计算和大数据的兴起和发展,越来越多的企业和用户使用hadoop和spark等大数据处理平台来处理和分析海量数据。例如,平台即服务(paas)平台通过云计算技术提供应用程序开发和运行时环境。由于大数据分析的结果为大量应用程序提供了关键信息,因此数据处理框架的安全性成为一个非常重要的问题。
现有的大数据处理平台是分布式平台。所有操作不在一台机器上执行,而是分布在不同的机器上,这可以缩短作业的执行时间并提高执行效率。但是,由于集群规模较大,用户无法处理每个节点,这使得一些恶意用户有机会攻击这些节点[1][2]。
在hadoop集群中,由于集群的规模较大,用户无法针对每个节点进行处理,这就使得一些恶意的用户有了攻击节点的机会。现有的技术和发明并没有对hadoop集群中可能出现的安全风险进行系统的研究和实验分析;现有的研究既没有系统地研究hadoop的安全风险,也没有通过实验评估这些安全风险对hadoop的威胁。
论文“fux,gaoy,luob,etal.securitythreatstohadoop:dataleakageattacksandinvestigation[j].ieeenetwork,2017,31(2):67-71.”虽然针对数据泄露攻击进行了详细的分析,但是并没有给出攻击的具体实现方案,并且也没有和其他类型的攻击方案做对比。论文“wangj,wangt,yangz,etal.seina:astealthyandeffectiveinternalattackinhadoopsystems[c]//internationalconferenceoncomputing,networkingandcommunications(icnc2017).ieee,2017:525-530.”提出了一种hadoop内部的攻击方案,但它也同样没有对其他的安全漏洞进行分析,并且和其它的攻击方案进行对比。
本说明书中提到的文献来源于如下的期刊:
[1]fux,gaoy,luob,etal.securitythreatstohadoop:dataleakageattacksandinvestigation[j].ieeenetwork,2017,31(2):67-71。
[2]winty,tianfieldh,mairq.bigdatabasedsecurityanalyticsforprotectingvirtualizedinfrastructuresincloudcomputing[j].ieeetransactionsonbigdata,2018:11-25。
[3]yanghc.map-reduce-merge:simplifiedrelationaldataprocessingonlargeclusters[j].2007acmsigmodinternationalconfnerenceonmanagementofdata,2007:2019-1040。
[4]dasr,singhrp,patgirir.mapreducescheduler:a360-degreeview[j].2017:88-100。
[5]gaoy,fux,luob,etal.haddle:aframeworkforinvestigatingdataleakageattacksinhadoop.[c]//ieeeglobalcommunicationsconference.ieee,2015:1-6。
[6]khorshedmt,sharmana,duttav,etal.realtimeshuffleattackanalysisonhadoopecosystemusingmachinelearningalgorithms[c]//computerscience&engineering.ieee,2016,pp:1-7。
技术实现要素:
本发明的目的是针对上述不足之处提出针对大数据处理平台hadoop的攻击方法,该方法中包括四种攻击模型,以保证管理员在hadoop集群发生问题时可以根据问题的特征迅速定位到问题发生的原因;针对hadoop集群可能出现的安全进行了详细的分析,并从内部攻击和外部攻击两个部分系统的描述了hadoop集群可能出现的安全威胁,并且在此基础上设计了四种针对hadoop集群的攻击方法模型,为用户定位集群问题提供了一种有效的思路和方案。
本发明是采取以下技术方案实现的:
针对大数据处理平台hadoop的攻击方法的四种攻击模型,包括推测任务调度攻击模型、心跳攻击模型、数据攻击模型和shuffle攻击,这四种攻击模型是基于大数据处理框架hadoop的攻击模型。
所述推测任务调度攻击(mrspeculativeattack)模型,主要是针对hadoop集群中推测任务调度算法的攻击,hadoop集群将会为执行较慢的任务创建一个推测任务,通过该攻击方案,可以选取一部分正常的任务,暂缓这些任务的执行,直到hadoop集群将要为它们创建推测任务时再将它们唤醒。推测任务调度攻击模型可以拖慢个别任务的执行,进而拖慢整个作业的执行。
所述心跳攻击(heartbeatattack)模型,主要是针对hadoop集群中心跳机制的攻击。在hadoop集群中,namenode(文件系统目录节点)和datanode(文件系统数据节点)、jobtracker(作业跟踪器)和tasktracker(任务跟踪器)通过心跳机制进行通信,并且每3秒发送一次心跳,为了防止心跳时间过长,hadoop设置了一个超时时间,如果超过超时时间还没有发送心跳,则master节点(主节点)就会将该节点标记为dead节点(死亡节点)。心跳攻击模型可以将心跳的发送时间延长到超时时间,将会在很大程度上影响集群的性能。
所述数据攻击(dataattack)模型,是针对mapreduce任务执行过程中中间数据的攻击。hadoop集群将作业分为多个map(映射)任务和多个reduce(削减)任务,map任务产生中间结果,reduce任务利用这些中间结果生成最终的结果。该攻击方案可以对中间结果的内容进行修改、删除和增加等操作,从而影响整个作业的执行结果。
所述shuffle攻击(shuffleattack)模型,是针对hadoop集群在任务执行过程中shuffle(洗牌)阶段的攻击。在hadoop中,大多数map和reduce任务都在不同的节点上执行。reduce任务需要在其他节点上提取map任务的结果。map任务生成的数据需要通过网络i/o传输到reduce任务。这个过程叫做shuffle(洗牌)。shuffle(洗牌)阶段的时间占据执行时间的很大一部分。该攻击方案通过延长shuffle(洗牌)阶段的执行时间从而延长整个任务的执行时间。
推测任务调度攻击模型的攻击步骤如下:
m1-1)在节点管理器中内置一个slave节点(从节点)监测模块,该模块监测分配给节点的map和reduce任务;
m1-2)从上述map任务和reduce任务中选取一部分任务(task)作为攻击目标,保证不会被安全机制监测到,暂停这些任务的执行,将任务进入休眠状态,hadoop机制将会监测这些任务的执行进度;
m1-3)预估步骤m1-2)中的攻击目标任务和推测任务的完成时间,直到hadoop要开始执行推测任务代替这些攻击目标任务时,再唤醒这些攻击目标任务;所述推测任务指的是在hadoop集群中,如果一个任务执行的过慢,集群管理节点将会启动一个任务代替执行慢的任务,这个任务叫做推测任务,也叫speculative任务。
所述步骤m1-2)中选取的task(任务)数目应少于master节点将该slave节点标记为不可用的数目,保证不会被hadoop的安全机制发现。
步骤m1-3)中所述的攻击目标任务执行时间预估公式为公式1,
timecomplete=tnow+((1-p)*t)/p公式1;
其中tnow代表当前时间;p代表任务(task)完成的进度,它近似的等于任务读取的输入数据占整个输入数据的百分比;t代表任务已经执行的时间。
通过公式2预估如果开始推测任务,那么推测任务的结束时间stimecomplete;
stimecomplete=tnow+tmean公式2,
其中tnow代表当前时间;tmean代表与当前任务同种类型的任务平均执行时间。
通过公式3计算任务最长的延迟时间,
delaytime=t/(1/p-1)公式3,
其中t为同种类型任务的执行时间;p∈(0,1)。
将上述任务最长的延迟时间delaytime代入公式4计算任务最长能够暂停的时间,pausetime=delaytime+p*t公式4,其中t为同种类型任务的执行时间;p∈(0,1)。
心跳攻击模型包括两种,即针对namenode和datanode心跳机制的攻击、针对jobtracker和tasktracker心跳的攻击,心跳攻击的攻击步骤如下:
m2-1)在节点管理器中设置一个心跳监测模块和容器控制模块,心跳监测模块负责监测slave节点和master节点上次发送心跳的时间,容器监测模块将会触发心跳暂停命令来暂停心跳的执行;
m2-2)记录节点上次的心跳时间,暂停节点的通信,为了防止master节点将slave节点标记为dead节点,容器监测模块暂停心跳发送的时间不超过系统设置的超时时间。
步骤m2-2)中,记录节点上次的心跳时间的具体方法是从配置文件中分别读取namenode和datanode、jobtracker和tasktracker的心跳超时时间;
namenode和datanode心跳延迟时间的计算公式如下:
timeout=2*heartbeat.recheck.interval+10*dfs.heart.interval,公式5;
tdelay=α*timeoutα∈(0,1),公式6;
其中timeout代表hadoop系统默认的超时时间;tdelay代表可以暂停心跳的最长时间。
jobtracker和tasktracker心跳延迟时间的计算公式如下:
tdelay=β*mapreduce.task.timeoutβ∈(0,1),公式7
其中tdelay代表可以暂停心跳的最长时间。
数据攻击模型的攻击步骤如下:
m3-1)在slave节点的节点管理器中设置一个节点监测模块,负责监测分配给该节点的maptasks(map任务);
m3-2)通过监测的map任务可以获得这些任务的taskid和jobid;
m3-3)针对获得的taskid得到这些任务的执行结果,并增加、修改、删除这些结果,使得作业最终得到错误的结果。
例如:map任务在执行完成的时候,会产生[key,value]键值对,该节点会对所有map任务生成的键值对进行收集,在收集过程中,可以循环收集或者跳过收集,从而造成键值对的丢失,影响作业的执行结果,本过程可以在hadoop源代码maptask.java模块中的collect()函数中实现。
shuffle攻击(shuffleattack)模型的攻击步骤如下:
m4-1)在节点管理器中内置一个节点监测模块,用于监测节点网络状态,所述节点网络状态包括该节点的网络带宽;
m4-2)利用网络攻击工具限制该节点的网络带宽,延长该节点在hadoop集群中shuffle阶段的执行时间;网络攻击工具可采用wondershaper等。
步骤m4-2)中将集群的带宽限制为监测状态的80%,在数据量和执行任务不同的情况下,延长的时间有所差别,本发明在5gb的数据下实现hadoop的三个测试基准wordcount、wordmean、terasort,实验结果比正常时间延长了7%~15%左右。
本发明采用以上技术方案与现有技术相比,具有以下有益效果:
本发明四种攻击模型,可以有效地影响作业的执行,并且不会被系统的防御机制轻易发现。基本思想是在不违反大数据处理平台的数据处理协议的情况下攻击节点或系统,或者延长整个作业的执行时间,或者使某个节点的任务得到错误的结果,这将使它的最终结果不正确[3]。在正常情况下,本发明攻击实现的成本相对较小。
附图说明
以下将结合附图对本发明做进一步说明:
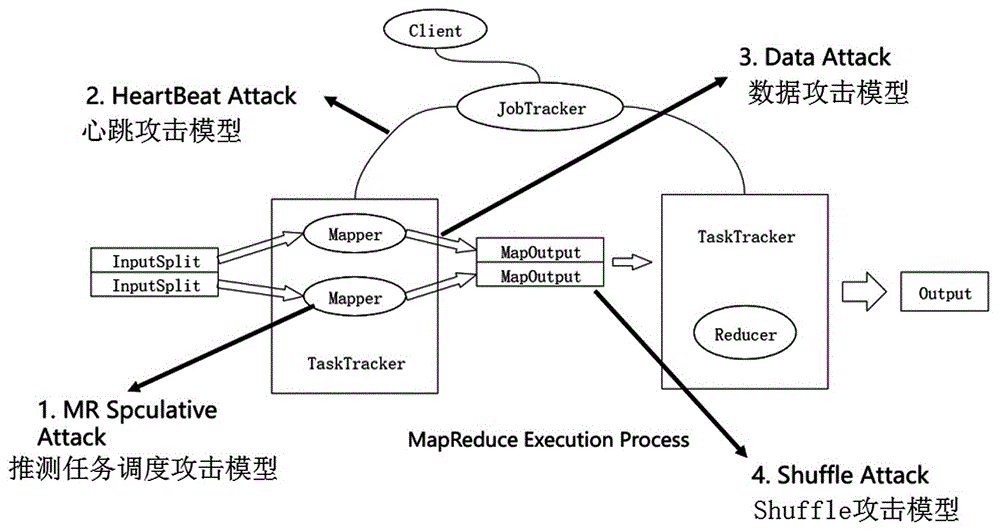
图1是四种攻击方案对应的hadoop任务执行阶段的示意图;
图2是推测任务调度攻击(mrspeculativeattack)示意图;
图3是心跳攻击(heartbeatattack)示意图;
图4是数据攻击(dataattack)示意图;
图5是shuffle攻击(shuffleattack)示意图。
具体实施方式
下面将结合附图和具体实施例对本发明做进一步说明。
本发明假设集群已经部署了一些防御机制,所提出的攻击将遵循集群设置的安全策略。在本发明中,使用hadoop数据处理框架作为攻击的目标平台,但攻击也可以应用于其他类似的框架。
第一种攻击模型mr推测任务调度攻击(mrspeculativeattack)是针对mapreduce推测任务的调度算法[4];利用hadoop调度方法的漏洞来延长作业的执行时间。
第二种攻击模型心跳攻击(heartbeatattack)是针对master节点和slave节点之间的通信机制;通过延长心跳时间来增加map和reduce任务的调度时间。
第三种攻击模型数据攻击(dataattack)是执行mapreduce任务期间针对中间数据的攻击;数据攻击通过破坏中间数据的正确性来影响作业的正确性。当采用该模型攻击数据时,会得到错误的结果[5]。
第四种攻击模型shuffle攻击(shuffleattack)是针对mapreduce任务的shuffle阶段;增加了reduce任务拉取中间数据的时间[6]。
下面结合附图对本发明做进一步详细说明。
如图2所示,推测任务调度攻击(mrspeculativeattack)模型的攻击步骤如下:
m1-1)在节点管理器中内置一个节点监测模块,该模块监测分配给节点的map和reduce任务;
m1-2)从分配给该节点的map任务和reduce任务中选取5%比例以下的任务,保证不会被安全机制监测到,暂停这些任务的执行,通过公式1预估这些任务的执行时间;
timecomplete=tnow+((1-p)*t)/p公式1;
m1-3)通过公式2预估如果开始推测任务的话,推测任务的结束时间;
stimecomplete=tnow+tmean公式2;
m1-4)判断推测任务的结束时间是否大于正常任务的结束时间;
m1-5)通过公式3计算任务最长的延迟时间;
delaytime=t/(1/p-1)公式3;
m1-6)通过公式4计算任务最长可以暂停的时间;
pausetime=delaytime+p*t公式4。
如图3所示,心跳攻击(heartbeatattack)模型的攻击步骤如下:
m2-1)在节点管理器中设置一个心跳监测模块和容器控制模块,心跳监测模块负责监测slave节点和master节点上次发送心跳的时间,容器监测模块将会触发心跳暂停命令来暂停心跳的执行;
m2-2)从配置文件中分别读取namenode(文件系统目录节点)和datanode(文件系统数据节点)、jobtracker(作业跟踪器)和tasktracker(任务跟踪器)的心跳超时时间;
m2-3)通过公式5和公式6计算文件系统目录节点和文件系统数据节点心跳的暂停时间;
timeout=2*heartbeat.recheck.interval+10*dfs.heart.interval,公式5;
tdelay=α*timeoutα∈(0,1),公式6;
m2-4)通过公式7计算作业追踪器和任务追踪器心跳的暂停时间;
tdelay=β*mapreduce.task.timeoutβ∈(0,1),公式7。
如图4所示,数据攻击(dataattack)模型的攻击步骤如下:
m3-1)在节点管理器中内置一个节点监测模块,该模块监测分配给节点的map任务;
m3-2)随机选取一部分任务,获取这些任务的taskid和jobid;
m3-3)获取这些任务执行的中间数据[key,value]键值对,增加、删除、或者修改这些键值对。
如图5所示,shuffle攻击(shuffleattack)模型的攻击步骤如下:
m4-1)在节点管理器中内置一个节点监测模块,该模块监测节点网络状态;
m4-2)利用网络攻击工具限制该节点在hadoop集群的带宽,当该节点执行任务进行shuffle阶段时,其发送给reduce任务节点的数据因带宽限制而变慢,在本攻击方案中将集群的带宽限制为监测状态的80%。
- 还没有人留言评论。精彩留言会获得点赞!