一种文件解析方法及装置与流程
本申请涉及计算机技术领域,尤其涉及一种文件解析方法及装置。
背景技术:
相关技术中,对目标文件进行解析时,客户端常以文件字节流的方式下载待解析的文件,且文件字节流传输过程中存在文件丢失、第三方截获的风险;文件字节流丢失、文件不完整必然会导致解析失败,对于请求对文件进行解析的业务程序而言,在其文件解析请求正确的情况下,文件解析失败是无法预见的,且在对待解析的文件字节流未做保密措施的前提下,第三方可以截获文件并对其进行解析出可用数据,再使用这些数据进行信息攻击,当这类事件发生时,服务端以及客户端不能及时得知,进而使得解析文件的过程不安全。
技术实现要素:
本申请实施例提供一种文件解析方法及装置,用于提高文件解析过程中的安全。
本申请第一方面,提供一种文件解析方法,包括:
响应业务程序发送的文件解析请求,基于云服务获取所述文件解析请求对应的目标文件;
在沙箱中解析所述目标文件获得文件解析数据。
上述方法中,通过从云服务中获取目标文件,避免目标文件丢失,且防止第三方对目标文件进行不经授权的修改,另一方面,在沙箱提供的隔离环境中对目标文件进行解析,可以预防第三方传入的恶意木马文件等对目标文件的破坏以及篡改,保证了文件解析过程中的安全。
在一种可能的实现方式中,所述沙箱包括开源容器工具提供的容器组pod,所述在沙箱中解析所述目标文件获得文件解析数据,包括:
确定所述响应业务程序对应的pod的容器组访问微服务service,所述pod包括至少一个容器,所述至少一个容器中包括用于解析文件的镜像;
根据所述service提供的网络地址和端口访问所述pod,通过所述pod提供的容器调用所述用于解析文件的镜像,通过所述用于解析文件的镜像获得所述目标文件的文件解析数据。
上述方法中,利用pod作为解析文件的沙箱,且将解析文件用到的至少一个镜像放入对应的容器中进行隔离,一方面避免了多个镜像之间的相互影响或修改,另一方面,将至少一个镜像隔离在pod内,排除了镜像受第三方的木马文件侵害的可能。
在一种可能的实现方式中,所述在沙箱中解析所述目标文件获得文件解析数据之前,还包括:
从容器引擎中获取与所述文件解析请求对应的至少一个用于解析文件的镜像;
将获取的所述至少一个用于解析文件的镜像放入对应的容器获得所述pod,其中,一个容器对应一个镜像;以及
创建用于访问所述pod的service。
上述方法中,在创建pod时即拉取镜像,支持将用于解析文件的镜像自动拉入pod中进行隔离,且支持用不同的容器隔离不同的镜像,避免了不同的镜像的相互影响以及可能发生相互篡改的情况的出现。
在一种可能的实现方式中,所述基于云服务获取所述文件解析请求对应的目标文件之后,在沙箱中解析所述目标文件获得文件解析数据之前,还包括:
将所述目标文件保存到所述开源容器工具中的网络文件系统,并确定所述目标文件的存储路径;
所述通过所述用于解析文件的镜像获得所述目标文件的文件解析数据,包括:
通过所述用于解析文件的镜像对所述存储路径对应的目标文件进行解析,获取文件解析数据。
上述方法中,将获取的目标文件放在网络文件系统中与业务程序以及其他程序进行隔离,防止了目标文件被攻击者截取篡改,保证了目标文件的完整和正确。
在一种可能的实现方式中,所述文件解析请求还指示文件类型,所述在沙箱中解析所述目标文件获得文件解析数据,包括:
确定所述文件类型对应的解析方式;
在沙箱中根据确定的解析方式对所述目标文件进行解析,获得所述文件解析数据。
上述方法中,针对不同的文件类型提供不同的解析方式,解析出满足用户需求的个性化的文件解析数据,与不同的用户需求匹配,提升了文件解析的灵活度。
在一种可能的实现方式中,所述通过所述用于解析文件的镜像获得所述目标文件的文件解析数据时,还包括:
通过消息队列参数向所述业务程序通知所述目标文件的解析进度。
上述方法中,在解析文件的过程中会向业务程序反馈解析进度,便于业务程序及时得知目标文件的解析进度,以便准备后续工作。
在一种可能的实现方式中,所述文件解析请求还指示回调接口,所述在沙箱中解析所述目标文件获得文件解析数据之后,还包括:
通过所述回调接口将所述文件解析数据发送给所述业务程序。
上述方法中,解析文件之后将文件解析数据发送给业务程序,便于业务程序对文件解析数据进行其他处理。
在一种可能的实现方式中,所述基于云服务获取所述文件解析请求对应的目标文件之后,所述在沙箱中解析所述目标文件获得文件解析数据之前,还包括:
确定获取所述目标文件前所述目标文件的信息校验值和获取所述目标文件后所述目标文件的信息校验值一致。
上述方法中,通过目标文件的信息校验值确定获取的目标文件是未经篡改的文件,保证了目标文件的正确,进而保证解析目标文件获得的文件解析数据的正确。
本申请第二方面,提供一种文件解析装置,包括文件获取单元和文件解析单元,其中:
所述文件获取单元被配置为执行响应业务程序发送的文件解析请求,基于云服务获取所述文件解析请求对应的目标文件;
所述文件解析单元被配置为执行在沙箱中解析所述目标文件获得文件解析数据。
在一种可能的实现方式中,所述沙箱包括开源容器工具提供的容器组pod,所述文件解析单元具体被配置为执行:
确定所述响应业务程序对应的pod的容器组访问微服务service,所述pod包括至少一个容器,所述至少一个容器中包括用于解析文件的镜像;
根据所述service提供的网络地址和端口访问所述pod,通过所述pod提供的容器调用所述用于解析文件的镜像,通过所述用于解析文件的镜像获得所述目标文件的文件解析数据。
在一种可能的实现方式中,所述文件解析单元还被配置为执行:
在沙箱中解析所述目标文件获得文件解析数据之前,从容器引擎中获取与所述文件解析请求对应的至少一个用于解析文件的镜像;
将获取的所述至少一个用于解析文件的镜像放入对应的容器获得所述pod,其中,一个容器对应一个镜像;以及
创建用于访问所述pod的service。
在一种可能的实现方式中,所述文件解析单元还被配置为执行:
所述基于云服务获取所述文件解析请求对应的目标文件之后,在沙箱中解析所述目标文件获得文件解析数据之前,将所述目标文件保存到所述开源容器工具中的网络文件系统,并确定所述目标文件的存储路径;
通过所述用于解析文件的镜像获得所述目标文件的文件解析数据时,通过所述用于解析文件的镜像对所述存储路径对应的目标文件进行解析,获取文件解析数据。
在一种可能的实现方式中,所述文件解析请求还指示文件类型,所述文件解析单元还被配置为执行:
确定所述文件类型对应的解析方式;
在沙箱中根据确定的解析方式对所述目标文件进行解析,获得所述文件解析数据。
在一种可能的实现方式中,所述文件解析单元还被配置为执行:
通过所述用于解析文件的镜像获得所述目标文件的文件解析数据时,通过消息队列参数向所述业务程序通知所述目标文件的解析进度。
在一种可能的实现方式中,所述文件解析请求还指示回调接口,所述文件解析单元还被配置为执行:
在沙箱中解析所述目标文件获得文件解析数据之后,通过所述回调接口将所述文件解析数据发送给所述业务程序。
上述方法中,解析文件之后将文件解析数据发送给业务程序,便于业务程序对文件解析数据进行其他处理。
在一种可能的实现方式中,所述文件获取单元还被配置为执行:
基于云服务获取所述文件解析请求对应的目标文件之后,所述在沙箱中解析所述目标文件获得文件解析数据之前,确定获取所述目标文件前所述目标文件的信息校验值和获取所述目标文件后所述目标文件的信息校验值一致。
本申请第三方面,提供一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现第一方面及任一种可能的实施方式中任一所述的方法。
本申请第四方面,提供一种计算机可读存储介质,所述计算机可读存储介质存储有计算机指令,当所述计算机指令在计算机上运行时,使得计算机执行如第一方面及任一种可能的实施方式中任一所述的方法。
本申请第二方面至第四方面的有益效果可参见第一方面的描述,此处不再重复叙述。
附图说明
图1为本申请实施例提供的一种文件解析的流程示意图;
图2为本申请实施例提供的另一种文件解析的流程示意图;
图3为本申请实施例提供的一种文件解析中各模块的交互示意图;
图4为本申请实施例提供的另一种文件解析中各模块的交互示意图;
图5为本申请实施例提供的一种文件解析装置的结构示意图;
图6为本申请实施例提供的一种电子设备的结构示意图。
具体实施方式
为了更好的理解本申请实施例提供的技术方案,下面将结合说明书附图以及具体的实施方式进行详细的说明。
首先对本申请涉及到的部分名词进行解释。
fastdfs:一个开源的轻量级分布式文件系统,它对文件进行管理,功能包括:文件存储、文件同步、文件访问(文件上传、文件下载)等,能解决大容量存储和负载均衡的问题。
nas,网络附属存储,其英文全称为networkattachedstorage,连接在网络上,具备资料存储功能的装置,因此也称为“网络存储器”;它是一种专用数据存储服务器,以数据为中心,将存储设备与服务器彻底分离,集中管理数据。
kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理用户在网站中的所有动作流数据。
下面对本申请的设计思想进行说明。
相关技术中,一般在对文件进行解析时,常根据文件字节流通过apachepoijava插件解析目标文件导出数据,其存在如下几方面的问题:
1)文件字节流传输过程中存在文件丢失、第三方截获常以文件字节流的方式下载待解析的风险,进而导致解析失败,文件解析请求正确的情况下,文件解析失败无法预见,且文件字节流容易被攻击方截获并解析出可用数据,再使用这些数据做出信息攻击,进而使得解析文件的过程不安全。
2)以文件字节流作为用于解析文件的程序的解析接口的请求参数,攻击者可以利用恶意脚本、木马攻击文件解析服务,进而蔓延整个系统。
3)现有的文件解析格式比较单一,对所有待解析的文件以默认模式的解析方式解析输出特定形式的数据,与用户个性化的数据格式需求无法匹配。
鉴于此,发明人设计了一种文件解析方法及装置,该方法包括:
响应业务程序发送的文件解析请求,基于云服务获取上述文件解析请求对应的目标文件,进而在沙箱中解析上述目标文件获得文件解析数据。
进一步,上述沙箱可以但不局限于包括开源容器工具提供的容器组pod,进而可以在pod中解析目标文件。
上述开源容器工具可以但不局限于包括kubernetes或kubesphere或c2containerservice。
以下结合附图对本申请的方案进行详细叙述。
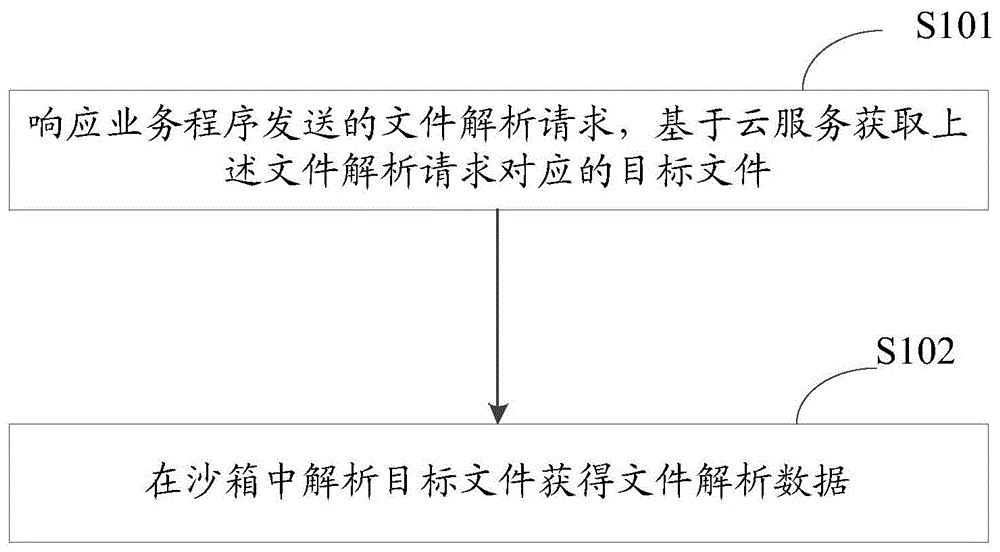
请参见图1,本申请实施例提供一种文件解析方法,具体包括如下步骤:
步骤s101,响应业务程序发送的文件解析请求,基于云服务获取上述文件解析请求对应的目标文件。
对上述文件解析请求的形式及内容不做过多限定,本领域的技术人员可根据实际需求设置。
可选地上述文件解析请求中可以包括目标文件的标识信息,进而根据该标识信息从云服务中获取对应的目标文件;上述标识信息可以但不局限于为目标文件的编码(identity,id),进而可以根据文件解析请求指示的id查询hbase(一个分布式的、面向列的开源数据库),获取目标文件的下载路径,根据获取的下载路径请求云服务下载待目标文件。
上述云服务可以但不局限于为oss(objectstorageservice,阿里云对象存储服务),还可以使用fastdfs、nas等分布式存储系统替代oss,本申请实施例中仅以oss为例进行说明。
进一步,为了保证下载的目标文件的完整性和正确性,下载目标文件后,在步骤s102之前,还可以按照下述方式对目标文件进行验证:
确定获取目标文件前目标文件的信息校验值和获取目标文件后目标文件的信息校验值一致。
上述信息校验值可以但不局限于是目标文件的哈希值md5,也可以是sha(securehashalgorithm,安全散列算法)算法获得的值;即确定下载目标文件前目标文件的md5值以及下载目标文件后目标文件的md5值一致。
在一种可能的情况中,若下载目标文件前目标文件的md5值和下载目标文件后目标文件的md5值不一致,则重新下载目标文件,并在下载目标文件后判断下载目标文件前目标文件的md5值以及下载目标文件后目标文件的md5值是否一致,若重复下载预设次数的目标文件后,对比的两个md5值仍不一致,则不再重复下载,可以向业务程序指示目标文件异常,或对最后一次下载的目标文件进行解析。
对上述预设次数不做过多限定,本领域的技术人员可根据实际需求设置,如可以但不局限于将其设置为3等。
步骤s102,在沙箱中解析目标文件获得文件解析数据。
请参见图2,可选地,上述沙箱包括开源容器工具提供的容器组pod,可以按照如下方式在沙箱中解析上述目标文件获得文件解析数据:
步骤s201,确定上述响应业务程序对应的pod的容器组访问微服务service,上述pod包括至少一个容器,上述至少一个容器中包括用于解析文件的镜像;
步骤s202,根据上述service提供的网络地址和端口访问上述pod,通过上述pod提供的容器调用上述用于解析文件的镜像,通过上述用于解析文件的镜像获得上述目标文件的文件解析数据。
进一步,在沙箱中解析上述目标文件获得文件解析数据之前,可以但不局限于按照如下方式创建上述pod和访问pod的service。
从容器引擎中获取与上述文件解析请求对应的至少一个用于解析文件的镜像;
将获取的上述至少一个用于解析文件的镜像放入对应的容器获得上述pod,其中,一个容器对应一个镜像;以及
创建用于访问上述pod的service。
pod创建完成后,每个pod都有自己的网络地址ip,而pod可能会被频繁第销毁和重建,因而pod的ip可能会发生变化,用pod的ip访问需要的pod容易出现错误,故而本申请实施例中在创建pod后创建用于访问pod的service,service定义了访问pod的方式,如service通过提供独立不变的网络地址和端口访问对应的pod。
进一步,由于一个pod可能被频繁地销毁和重启,在创建pod时还可以创建多个功能相同的pod,如此,当其中一个pod意外被销毁或出现其他错误时,还可以访问与其功能相同的其他的pod。
对应地,若创建了至少两个功能相同的pod,则可以将至少两个功能相同的pod看做一个集群,在创建访问pod使用的service时,service提供的网络地址和端口可以访问上述两个功能相同的pod中的任意一个。
因此,在步骤s202中根据上述service提供的网络地址和端口访问上述pod时,可以但不局限于根据上述service提供的网络地址和端口,随机访问上述至少两个功能相同的pod中任意一个pod。
可选地,在上述步骤s101之后,在步骤s102之前,还可以将上述目标文件保存到上述开源容器工具中的网络文件系统(networkfilesystem,nfs),并确定上述目标文件的存储路径;
在上述步骤s202中通过上述用于解析文件的镜像获得上述目标文件的文件解析数据时,可以通过上述用于解析文件的镜像对上述存储路径对应的目标文件进行解析,获取文件解析数据。
可选地,为了满足不同使用者的需求,提供多个对目标文件的解析方式,本申请实施例中文件解析请求还指示文件类型,在上述步骤s102中还可以确定上述文件类型对应的解析方式;
在沙箱中根据确定的解析方式对上述目标文件进行解析,获得上述文件解析数据。
可选地,为了及时让业务程序得知目标文件的解析进度,本申请实施例中在步骤s202中通过上述用于解析文件的镜像获得上述目标文件的文件解析数据时,还可以通过消息队列参数向上述业务程序通知上述目标文件的解析进度。
上述消息队列参数可以但不局限于为rabbitmq队列信息、kafka等,本申请实施例中仅以rabbitmq队列信息为例进行说明。
上述rabbitmq是支持持久化消息队列的消息中间件,其应用在上下游的层次级业务逻辑中,上级业务逻辑相当于生产者发布消息,下级业务逻辑相当于消费者接收到消息并且消费消息。
可选地,上述文件解析请求还指示回调接口,在步骤s102或步骤s202之后,还可以通过上述回调接口将上述文件解析数据发送给上述业务程序。
请参见图3和图4,本申请实施例还提供一个文件解析的具体示例,该示例中以开源容器工具作为上述方法的执行主体,在解析文件的过程中业务程序以及开源容器工具之间的交互具体如下:
请参见图3,具体包括如下步骤:
步骤1)业务程序可以通过http发起文件解析请求,该文件解析请求中指示有目标文件的编码id以及回调接口。
步骤2)文件解析执行体根据目标文件的编码id从云服务中获取目标文件。
步骤3)文件解析执行体将目标文件推送到nfs存储。
步骤4)文件解析执行体向k8smaster推送kubectl指令。
上述k8smaster为开源容器工具kubernetes管理者master的简称。
上述kubectl指令是一个用于操作kubernetes集群的命令行接口,通过利用kubectl的各种命令可以实现各种功能,是在使用kubernetes中非常常用的工具。
步骤5)k8smaster从docker镜像仓库中拉取至少一个用于解析文件的镜像,根据拉取的镜像创建创建容器pod和service。
步骤6)k8smaster根据service和pod对目标文件进行解析,将文件解析结果回执给rabbitmq队列执行体。
步骤7)rabbitmq队列执行体监听文件解析执行体。
步骤8)文件解析执行体通过回调接口将文件解析结果发送给业务程序。
上述除业务程序外的各模块可以在一个程序执行体中执行,也可以在多个程序执行体中执行。
请参见图4,以下对图3中出现的各模块之间的交互进行说明:
第一过程:
业务程序发送文件解析请求,该文件解析请求指示有目标文件的编码id、回调接口,将目标文件的编码id以及文件类型接入文件解析api(applicationprogramminginterface,应用程序接口),并指示回调接口。
由于目标文件的解析过程会耗费一定的时间,本申请实施例中在业务程序触发文件解析请求后,将对目标文件进行解析的任务放入与业务程序异步的线程中,且该线程可以在收到文件解析请求后即刻向业务程序反馈,因此,业务程序便可在发送文件解析请求后即刻收到正在对目标文件进行解析的响应。
第一过程具体包括如下步骤:
步骤s401,业务程序向文件解析api指示文件解析请求。
第二过程:
文件解析api创建文件解析任务,并根据指示的编码id查询hbase,获取目标文件的下载路径,并通过文件下载模块根据下载路径从云服务中下载目标文件、用于解析文件的镜像及指令,并将目标文件放入nfs,返回目标文件的存储地址。
在本步骤中,每次下载目标文件后,比对目标文件下载前的md5值和下载后的md5值是否一致,若一致,则进行下述步骤,若不一致,则重新下载上述目标文件至上述目标文件的下载此处达到设定次数如3次。
第二过程具体包括如下步骤:
步骤s402,文件解析api创建文件解析任务。
此步骤中,文件解析api向业务程序反馈文件解析执行中。
步骤s403,文件解析任务创建解析记录,获取目标文件的下载地址、镜像及指令。
步骤s404,文件解析任务创建下载任务并指示给文件下载模块。
步骤s405,文件下载模块从云服务oss中下载目标文件。
步骤s406,文件下载模块将目标文件放入nfs。
步骤s407,文件下载模块获取目标文件的存储路径并反馈给文件解析任务。
第三过程:
创建与文件解析请求对应的pod和service,可以将用于解析文件的程序接口通过maven打包成docker镜像,推送kubectl指令在k8s中启动一个容器pod,从容器引擎中docker镜像仓库中拉取与上述文件解析请求对应的至少一个用于解析文件的镜像;进而将获取的上述至少一个镜像放入对应的容器获得上述pod,其中,一个容器对应一个镜像;
之后推送kubectl指令创建用于访问上述pod的service并映射docker镜像端口与文件解析api互通。
第二过程具体包括如下步骤:
步骤s408,文件解析模块推送yml文件及执行kubectl指令,并指示k8smaster。
步骤s409,k8smaster创建pod并向k8s的执行者k8sworker指示。
步骤s410,k8sworker从docker镜像仓库中拉取用于解析文件的镜像。
第三过程:
根据service提供的网络地址和端口访问pod,通过pod提供的容器调用上述用于解析文件的镜像,通过用于解析文件的镜像获得目标文件的文件解析数据。
通过用于解析文件的镜像获得目标文件的文件解析数据时,可以通过上述用于解析文件的镜像对上述存储路径对应的目标文件,按照文件乐行对应的解析方式进行解析,获取文件解析数据。
还可以通过rabbitmq队列信息向业务程序通知目标文件的解析进度;以及通过文件解析请求指示的回调接口将获得的文件解析数据发送给业务程序,并推送kubectl指令删除上述创建的pod和service。
第三过程具体包括如下步骤:
步骤s411,k8sworker根据存储路径读取nfs中的目标文件并解析。
步骤s412,k8sworker向rabbitmq队列执行体反馈解析进度。
步骤s413,k8sworker解析完成后向rabbitmq队列执行体传递文件解析结果,该文件解析结果中可以包括目标文件的文件解析数据以及解析已完成的指示等。
步骤s414,rabbitmq队列执行体将解析进度和/或文件解析结果传递给文件解析任务。
步骤s415,文件解析任务将文件解析结果传递给hbase。
步骤s416,文件解析任务向k8smaster指示删除对应的pod。
步骤s417,文件解析任务调用回调接口并指示文件解析api。
步骤s418,文件解析api触发回调,反馈文件解析结果。
本申请提供的方法中,一方面基于云服务获取待解析的目标文件,能够保证目标文件的完整和正确,另一方面在沙箱中对目标文件进行解析,限制其他程序不能读取或篡改用于解析文件的镜像以及目标文件的信息,提升解析文件过程中的安全,且保证了获得的文件解析数据的正确和完整。
另一方面,将开源容器工具提供的容器组pod作为解析目标文件的沙箱,pod中禁止任何公网写入写出,仅开放文件推送单向通道以及仅开放kubectl指令单向通道,以及仅开放rabbitmq单向通道,镜像拉取的单向通道,保证了解析目标文件的过程中整个系统的安全;且可以对pod的生命周期进行控制,进一步避免了处理完业务请求的pod中的镜像对计算机中其他文件篡改的情况,保证了文件解析过程的安全。
请参照图5,基于同一发明构思,本申请实施例提供一种文件解析装置500,包括文件获取单元501和文件解析单元502,其中:
文件获取单元501被配置为执行响应业务程序发送的文件解析请求,基于云服务获取上述文件解析请求对应的目标文件;
文件解析单元502被配置为执行在沙箱中解析上述目标文件获得文件解析数据。
可选地,上述沙箱包括开源容器工具提供的容器组pod,上述文件解析单元502具体被配置为执行:
确定上述响应业务程序对应的pod的容器组访问微服务service,上述pod包括至少一个容器,上述至少一个容器中包括用于解析文件的镜像;
根据上述service提供的网络地址和端口访问上述pod,通过上述pod提供的容器调用上述用于解析文件的镜像,通过上述用于解析文件的镜像获得上述目标文件的文件解析数据。
可选地,上述文件解析单元502还被配置为执行:
在沙箱中解析上述目标文件获得文件解析数据之前,从容器引擎中获取与上述文件解析请求对应的至少一个用于解析文件的镜像;
将获取的上述至少一个用于解析文件的镜像放入对应的容器获得上述pod,其中,一个容器对应一个镜像;以及
创建用于访问上述pod的service。
可选地,上述文件解析单元502还被配置为执行:
上述基于云服务获取上述文件解析请求对应的目标文件之后,在沙箱中解析上述目标文件获得文件解析数据之前,将上述目标文件保存到上述开源容器工具中的网络文件系统,并确定上述目标文件的存储路径;
通过上述用于解析文件的镜像获得上述目标文件的文件解析数据时,通过上述用于解析文件的镜像对上述存储路径对应的目标文件进行解析,获取文件解析数据。
可选地,上述文件解析请求还指示文件类型,上述文件解析单元502还被配置为执行::
确定上述文件类型对应的解析方式;
在沙箱中根据确定的解析方式对上述目标文件进行解析,获得上述文件解析数据。
可选地,上述文件解析单元502还被配置为执行:
通过上述用于解析文件的镜像获得上述目标文件的文件解析数据时,通过消息队列参数向上述业务程序通知上述目标文件的解析进度。
可选地,上述文件解析请求还指示回调接口,文件解析单元602还被配置为执行:
在沙箱中解析上述目标文件获得文件解析数据之后,通过上述回调接口将上述文件解析数据发送给上述业务程序。
上述方法中,解析文件之后将文件解析数据发送给业务程序,便于业务程序对文件解析数据进行其他处理。
可选地,上述文件获取单元501还被配置为执行:
基于云服务获取上述文件解析请求对应的目标文件之后,上述在沙箱中解析上述目标文件获得文件解析数据之前,确定获取上述目标文件前上述目标文件的信息校验值和获取上述目标文件后上述目标文件的信息校验值一致。
请参见图6,基于相同的发明构思,本公开实施例还提供一种电子设备600,包括处理器601、用于存储上述处理器可执行指令的存储器602;
其中,上述处理器601被配置为执行如下过程:
响应业务程序发送的文件解析请求,基于云服务获取上述文件解析请求对应的目标文件;
在沙箱中解析上述目标文件获得文件解析数据。
可选地,上述沙箱包括开源容器工具提供的容器组pod,上述处理器具体用于:
确定上述响应业务程序对应的pod的容器组访问微服务service,上述pod包括至少一个容器,上述至少一个容器中包括用于解析文件的镜像;
根据上述service提供的网络地址和端口访问上述pod,通过上述pod提供的容器调用上述用于解析文件的镜像,通过上述用于解析文件的镜像获得上述目标文件的文件解析数据。
可选地,上述处理器还用于:
在沙箱中解析上述目标文件获得文件解析数据之前,从容器引擎中获取与上述文件解析请求对应的至少一个用于解析文件的镜像;
将获取的上述至少一个用于解析文件的镜像放入对应的容器获得上述pod,其中,一个容器对应一个镜像;以及
创建用于访问上述pod的service。
可选地,上述处理器还用于:
基于云服务获取上述文件解析请求对应的目标文件之后,在沙箱中解析上述目标文件获得文件解析数据之前,将上述目标文件保存到上述开源容器工具中的网络文件系统,并确定上述目标文件的存储路径;
上述通过上述用于解析文件的镜像获得上述目标文件的文件解析数据,包括:
通过上述用于解析文件的镜像对上述存储路径对应的目标文件进行解析,获取文件解析数据。
可选地,上述文件解析请求还指示文件类型,上述处理器具体用于:
确定上述文件类型对应的解析方式;
在沙箱中根据确定的解析方式对上述目标文件进行解析,获得上述文件解析数据。
可选地,上述处理器还用于:
通过上述用于解析文件的镜像获得上述目标文件的文件解析数据时,通过消息队列参数向上述业务程序通知上述目标文件的解析进度。
可选地,上述文件解析请求还指示回调接口,上述处理器还用于:
在沙箱中解析上述目标文件获得文件解析数据之后,通过上述回调接口将上述文件解析数据发送给上述业务程序。
可选地,上述处理器还用于,基于云服务获取上述文件解析请求对应的目标文件之后,上述在沙箱中解析上述目标文件获得文件解析数据之前,确定获取上述目标文件前上述目标文件的信息校验值和获取上述目标文件后上述目标文件的信息校验值一致。
基于同一技术构思,本申请实施例还一种计算机可读存储介质,该计算机可读存储介质存储有计算机指令,当上述计算机指令在计算机上运行时,使得计算机执行如前文论述的目标函数确定方法。
本领域内的技术人员应明白,本申请的实施例可提供为方法、系统、或计算机程序产品。因此,本申请可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本申请可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、cd-rom、光学存储器等)上实施的计算机程序产品的形式。
显然,本领域的技术人员可以对本申请进行各种改动和变型而不脱离本申请的精神和范围。这样,倘若本申请的这些修改和变型属于本申请权利要求及其等同技术的范围之内,则本申请也意图包含这些改动和变型在内。
- 还没有人留言评论。精彩留言会获得点赞!