一种基于图卷积神经网络的邻区关系预测方法及系统与流程
本发明涉及移动通信领域,具体地说是一种基于图卷积神经网络的邻区关系预测方法及系统。
背景技术:
无线网络知识图谱作为一种新的基站信息管理方法、知识图谱在通信领域的一种典型应用得到了越来越多的关注。其中,知识图谱的自动构建中的一项重要任务就是实体关系的识别与校准。进一步地,如何从海量数据中自动识别出小区实体间的邻区关系、对已有邻区关系列表(ncl,neighborcelllist)中删除冗余或错配邻区关系并增加漏配邻区关系是构建无线网络知识图谱的重要工作之一。
在传统的移动网络规划优化工作中,邻区关系规划优化同样也是无线网络规划优化中的一个重要环节。其主要目的是保证小区边缘用户能及时切换到信号最佳的邻小区,以保证通话质量和整网的性能。只有在基站(4glte系统中指enb,5g系统中指gnb)端对各小区的邻区关系进行配置之后,用户从一个小区进入另外一个小区时,才会完成切换。因此准确的邻区关系配置是保证移动网络性能的基本要求。
若邻区关系配置得太少或配置错误,会造成大量掉话、掉线;若邻区关系配置得过多,则导致测量报告的精确性降低、增加终端测量和空口信令交互的负担。而在网络运营过程中,随着新基站的建立、基站停用或搬迁以及干扰环境的变化,则需要不断对邻区关系进行更新。
现有技术手段主要有两种:
(1)人工路测:传统的网规网优工作是一项技术复杂、需要专业人员和工具的工作,主要通过大量的路测进行。然而路测需要消耗大量的时间和人力,而且由于测试本身不能遍历所有的覆盖区域和使用时间,所以对邻区优化的指导意义有限。从运营商的角度而言,要求更低的建网和运营成本,以便为广大用户提供更低价格的网络服务来赢得市场。
(2)anr(自动邻区关系):这是一种自动完成邻区关系配置的方法,属于自组织网络(son)技术中一个重要组成部分,自动化程度高。但是目前现网中一般并不会完全依赖这个功能,一般新网开一段时间后就会关闭,然后采用人工方式进一步优化。主要原因包括:(a)anr未考虑基站的实际覆盖能力,没有充分利用或考虑各基站的覆盖质量信息,会导致配置的邻区过多,带来太多的不必要邻区关系(其实是冗余或超远的邻区关系);(b)会带来大量的终端测量和空口信令交互负担。有人也提出了一些改进,例如当移动终端检测到列表之外小区的rsrp比当前服务小区的rsrp高,而且差值大于该值时,移动终端才会上报测量的结果到服务enb。anr功能包括三个模块:邻区检测模块、邻区删除模块和邻区关系表管理模块(如下图所示)。主要的工作步骤包括:
(a)enb向ue下发anr相关的测量配置,可以包括同技术(intra-rat)同频、异频测量或异技术(inter-rat)测量,ue收到测量配置后执行pci(physicalcellidentity,邻区物理小区标识)的测量,并将测到的邻区的pci信息按照测量报告的格式上报给enb;
(b)enb收到邻区的pci信息后,选取特定的ue下发报告cgi(cellglobalidentity,小区全局标识)、测量配置,ue收到此测量配置后,读取邻区的广播信息,获取邻区的cgi等信息;
(c)enb收到ue上报的邻区的cgi等信息后,将信息上报给o&m(操作和维护)系统,由o&m决策是否添加该邻区。注意:enb并不关心是哪些移动终端上报的测量结果,而是关注是哪些小区被上报给了自己,并统计各个小区被上报的次数,根据预先设定的门限值,enb仅仅把上报次数超过门限值的小区添加到邻区关系列表中去。
现有技术手段的主要缺点在于:
(1)人工路测:路测需要消耗大量的时间和人力,而且由于测试本身不能遍历所有的覆盖区域和使用时间,会漏掉很多有效的邻区关系,所以对邻区优化的指导意义有限。
(2)anr(自动邻区关系):因为未考虑基站的实际覆盖能力,一般会导致配置的邻区过多,出现大量的冗余邻区关系,或者由于越区覆盖带来的超远的邻区关系,会带来大量的终端测量和空口信令交互负担、或导致频繁切换影响业务的连续性甚至导致掉线掉话。因此,目前在4g现网中并不会完全依赖这个功能,一般情况下仅在新建网络的初期开启一段时间的基站anr功能,然后关闭并通过人工路测等方式进行优化。
技术实现要素:
为了解决上述的技术问题,本发明提出的基于图卷积神经网络的邻区关系预测方法及系统,有效保障邻区关系信息的有效性、完整性和时效性,是自动构建无线网络知识图谱的重要步骤。该方法可以作为现有人工路测和anr技术的补充甚至替代,指导运营商网络运维部门更高效、及时、方便地对无线网络中的基站邻区关系的配置和管理,为提高用户在网内小区间的切换成功率、提高业务连续性和保障良好的业务体验提供有力支撑。
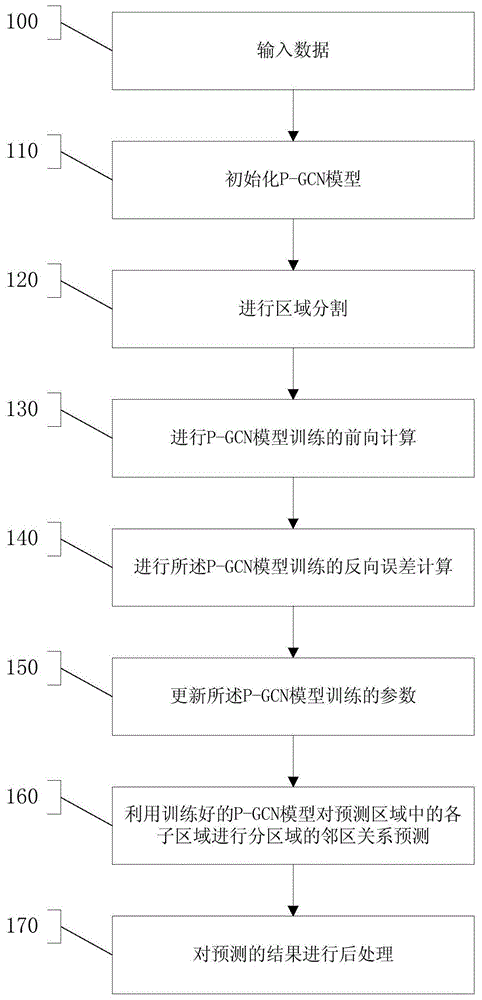
本发明的第一目的是提供一种基于图卷积神经网络的邻区关系预测方法,包括输入数据,还包括以下步骤:
步骤1:初始化p-gcn模型;
步骤2:进行区域分割;
步骤3:进行p-gcn模型训练的前向计算;
步骤4:进行所述p-gcn模型训练的反向误差计算;
步骤5:更新所述p-gcn模型训练的参数;
步骤6:利用训练好的所述p-gcn模型对预测区域中的各子区域st+1~sk进行分区域的邻区关系预测,其中,t为训练区域所包含的子区域个数,k为子区域的总个数;
步骤7:对所述预测的结果进行后处理。
优选的是,所述数据包括mcs或mr覆盖采样数据集d、初步构建的目标区域s的无线网络知识图谱g=(v,e)和目标区域的小区邻接矩阵ac=[nca*nca],其中,v表示实体集合,e表示关系集合,nca为区域s内的小区总数。
在上述任一方案中优选的是,所述步骤1包括以下子步骤:
步骤11:初始化节点特征矩阵x[n*d],从无线网络知识图谱数据库中提取各实体及其属性信息存入所述节点特征矩阵x[n*d],其中,n是子区域的实体节点数,d是最大特征维数;
步骤12:初始化节点类型向量f[n*1]:与x中的节点排序顺序相同,且小区节点对应项为1,其他为0,用于识别小区节点;
步骤13:初始化邻接矩阵a[n*n]:邻接矩阵,表征两两节点间的边是否存在,包括小区-基站、采样-小区、终端-小区、采样-终端和小区-小区,其中,1为存在,0为不存在或未知;
步骤14:随机初始化卷积窗权重矩阵w1=[d*c1]、w2=[c1*1]和w4=[nc(nc-1)/2*2],对l1和l2两个卷积层,同层各神经元共享相同的卷积窗权重,其中,c1为卷积窗w2的窗长,nc为每个子区域内的小区节点数。
在上述任一方案中优选的是,所述步骤2为将目标区域s按空间分割为k个矩形子区域s1,s2,...,si,...,sk,每个子区域内保证小区节点数固定为nc、总节点数为n,并相邻子区域保持一定程度的重叠。
在上述任一方案中优选的是,所述步骤2包括基于d、g、ac得到各子区域si的特征矩阵xi、节点类型向量fi、邻接矩阵ai和小区对关系指示向量pi,其中,i=1~k。
在上述任一方案中优选的是,所述邻接矩阵ai中包含所有的隶属关系、驻留关系、关联关系和已标记的邻区关系。
在上述任一方案中优选的是,所述子区域s1~st成为训练区域,所述训练区域的邻区关系完全已知,随机取部分邻区关系作为训练时的输入信息,其余部分邻区关系用于测试。
在上述任一方案中优选的是,所述子区域st+1~sk成为预测区域,所述预测区域的邻区关系仅部分已知并作为正向计算时的输入,其余部分为未知或待预测。
在上述任一方案中优选的是,所述步骤3包括以下子步骤:
步骤31:构造输入层l0;
步骤32:计算第1图卷积层l1的输出;
步骤33:计算第2图卷积层l2的输出;
步骤34:计算池化层l3的输出。
在上述任一方案中优选的是,所述步骤31包括对于所述子区域si,令h0=xi=[n*d],共n*d个神经元节点,每个节点为某个对应实体的某个对应特征,其中,h0为l0层到l1层的输入。
在上述任一方案中优选的是,所述卷积层l1的输出h1=[n*c1],公式为h1=relu(aih0w1),神经元激活前的输入值为:z1=aih0w1,共n*c1个神经元节点,每个节点均是包含了全部输入实体的全部特征的某种线性组合,其中,w1为第1卷积层的卷积窗权重矩阵。
在上述任一方案中优选的是,所述卷积层l2的输出h2=[n*1],公式为h2=relu(aih1w2),神经元激活前的值为:z2=aih1w2,本层共n个神经元节点,其中,w2为第2卷积层的卷积窗权重矩阵。
在上述任一方案中优选的是,所述步骤34包括利用fi节点类型矢量对h2进行下采样,仅保留小区节点,得到h3=f(h2,fi)=[nc*1],本层共nc个神经元节点。
在上述任一方案中优选的是,所述步骤35包括将所述池化层l3的nc个神经元的输出两两连接,得到共nc*(nc-1)/2个小区对神经元节点。
在上述任一方案中优选的是,所述小区对神经元节点分为a类神经元、b类神经元和c类神经元。
在上述任一方案中优选的是,所述a类神经元是指对于小区对间存在已知关系的神经元,不做任何处理,也不做bp参数更新,直接将输出置为0,所述a类神经元共n1个。
在上述任一方案中优选的是,所述b类神经元是指对于小区对间关系未知、但站间距超过2倍平均站间距的神经元,强置其预测结果为0,需要利用bp进行参数迭代更新,所述b类神经元共n2个。
在上述任一方案中优选的是,所述c类神经元是指对于小区对间关系未知、但站间距小于2倍平均站间距的神经元,需要预测其正例概率,并需要计算损失函数、进行bp参数迭代。所述c类神经元共n3个。
在上述任一方案中优选的是,对每个所述c类神经元的输入取logistic回归分类函数得到输出神经元向量
其中,
在上述任一方案中优选的是,所述步骤4包括以下子步骤:
步骤41:计算所述输出层的预测误差loss、神经元残差δ4和参数梯度;
步骤42:计算所述池化层l3的神经元残差δ3;
步骤43:计算所述第2图卷积层l2的神经元激活后残差j2、神经元残差δ2和参数梯度;
步骤44:计算所述第1图卷积层l1的神经元残差δ1和参数梯度。
在上述任一方案中优选的是,所述步骤41包括对所述b类神经元和c类神经元,比较各神经元输出的邻区关系正例概率yj与真实值
该神经网络的总预测误差为:
神经元j的残差
计算输出层参数
在上述任一方案中优选的是,所述步骤42为将输出层各神经元的残差δ4的值按照与池化层神经元的连接权重反向分配给所连接的两个池化层神经元,每个池化层神经元的残差δ3等于其所连接的所有输出层神经元分配过来的残差δ4的加权和。
在上述任一方案中优选的是,所述步骤43为根据池化层神经元与第2图卷积层神经元的连接关系,将池化层神经元的残差δ3赋给相连的l2神经元即为该l2神经元的激活后残差,即j2=δ3,
将损失函数对l2层relu函数求偏导,即得l2神经元的残差δ2:
其中,⊙为哈达玛积。
在上述任一方案中优选的是,所述步骤44为将损失函数先对l2层卷积求偏导,再对l1层relu函数求偏导,即得l1层神经元的残差δ1:
计算该层的卷积窗参数w1的梯度:
其中,rot180是对矩阵进行左右和上下翻转操作,*为卷积运算。
在上述任一方案中优选的是,所述步骤5包括以下子步骤:
步骤51:更新输出层参数;
步骤52:更新第2图卷积层l2的卷积窗权重,w2=w2-α(aih1)′·δ2;
步骤53:更新第1图卷积层l1的卷积窗权重,w1=w1-α(aih0)′·δ1。
在上述任一方案中优选的是,所述步骤51为更新输出层的神经元j的反向连接权重:
其中,α为学习率。
在上述任一方案中优选的是,所述步骤6为利用训练好的p-gcn模型对预测区域中的各子区域st+1~sk进行分区域的邻区关系预测,对子区域si,i=(t+1)~k,依次进行以下子步骤:
步骤61:根据所述p-gcn模型训练的前向计算方法计算得到h4;
步骤62:如果h4的值大于门限阈值,则推断该小区对之间存在邻区关系,否则不存在。
在上述任一方案中优选的是,所述步骤7包括以下子步骤:
步骤71:更新ncl;
步骤72:重叠区域的处理。
在上述任一方案中优选的是,所述步骤71为根据前面的预测结果相应更新ac矩阵,并同时更新ncl,即增加ncl中漏配的邻区,删除ncl中错配的邻区。
在上述任一方案中优选的是,所述步骤72为对同一个小区对,如果多个子区域均有相应的预测输出,则通过投票法确定其最终的预测结果。
本发明的第二目的是提供一种基于图卷积神经网络的邻区关系预测系统,包括用于输入数据的数据输入模块,包括以下模块:
初始化模块:用于初始化p-gcn模型;
分割模块:用于进行区域分割;
计算模块:用于进行p-gcn模型训练的前向计算和反向误差计算;
更新模块:用于更新所述p-gcn模型煦联得参数
预测模块:用于利用训练好的所述p-gcn模型对预测区域中的各子区域st+1~sk进行分区域的邻里关系预测,其中,t为训练区域所包含的子区域个数,k为子区域总个数后处理模块:用于对所述预测的结果进行后处理。
所述系统按照如权利要求1所述的方法进行基于图卷积神经网络的邻区关系预测。
本发明提出了一种基于图卷积神经网络的邻区关系预测方法,能够基于海量的终端感知覆盖数据和基站测量报告数据提取数据中的各类邻区关系,对当前邻区关系列表中的错配或冗余邻区进行校正、并补充漏配的邻区关系,从而实现更高效、智能的邻区关系管理。
附图说明
图1为按照本发明的基于图卷积神经网络的邻区关系预测方法的一优选实施例的流程图。
图1a为按照本发明的基于图卷积神经网络的邻区关系预测方法的如图1所示实施例的模型初始化方法流程图。
图1b为按照本发明的基于图卷积神经网络的邻区关系预测方法的如图1所示实施例的前向计算方法流程图。
图1c为按照本发明的基于图卷积神经网络的邻区关系预测方法的如图1所示实施例的反向误差计算方法流程图。
图1d为按照本发明的基于图卷积神经网络的邻区关系预测方法的如图1所示实施例的参数更新计算方法流程图。
图1e为按照本发明的基于图卷积神经网络的邻区关系预测方法的如图1所示实施例的预测方法流程图。
图1f为按照本发明的基于图卷积神经网络的邻区关系预测方法的如图1所示实施例的后处理方法流程图。
图2为按照本发明的基于图卷积神经网络的邻区关系预测系统的一优选实施例的模块图。
图3为按照本发明的基于图卷积神经网络的邻区关系预测方法的另一优选实施例的流程图。
图4为按照本发明的基于图卷积神经网络的邻区关系预测方法的如图3所示实施例的p-gcn网络结构图。
具体实施方式
下面结合附图和具体的实施例对本发明做进一步的阐述。
实施例一
如图1、2所示,执行步骤100,使用数据输入模块200输入数据。数据包括mcs或mr覆盖采样数据集d、初步构建的目标区域s的无线网络知识图谱g=(v,e)和目标区域的小区邻接矩阵ac=[nca*nca],其中,v表示实体集合,e表示关系集合,nca为区域s内的小区总数。
执行步骤110,初始化模块210初始化p-gcn模型。如图1a所述,执行步骤111,初始化节点特征矩阵x[n*d],从无线网络知识图谱数据库中提取各实体及其属性信息存入所述节点特征矩阵x[n*d],其中,n是子区域的实体节点数,d是最大特征维数。执行步骤112,初始化节点类型向量f[n*1]:与x中的节点排序顺序相同,且小区节点对应项为1,其他为0,用于识别小区节点。执行步骤113,初始化邻接矩阵a[n*n]:邻接矩阵,表征两两节点间的边是否存在,包括小区-基站、采样-小区、终端-小区、采样-终端和小区-小区,其中,1为存在,0为不存在或未知。执行步骤114,随机初始化卷积窗权重矩阵w1=[d*c1]、w2=[c1*1]和w4=[nc(nc-1)/2*2],对l1和l2两个卷积层,同层各神经元共享相同的卷积窗权重,其中,c1为卷积窗w2的窗长,nc为每个子区域内的小区节点数。
执行步骤120,分割模块220进行区域分割。基于d、g、ac得到各子区域si的特征矩阵xi、节点类型向量fi、邻接矩阵ai和小区对关系指示向量pi,其中,i=1~k。所述邻接矩阵ai中包含所有的隶属关系、驻留关系、关联关系和已标记的邻区关系。所述子区域s1~st成为训练区域,所述训练区域的邻区关系完全已知,随机取部分邻区关系作为训练时的输入信息,其余部分邻区关系用于测试。所述子区域st+1~sk成为预测区域,所述预测区域的邻区关系仅部分已知并作为正向计算时的输入,其余部分为未知、待预测。
执行步骤130,计算模块230进行p-gcn模型训练的前向计算。如图1b所述,执行步骤131,构造输入层l0。对于所述子区域si,令h0=xi=[n*d],共n*d个神经元节点,每个节点为某个对应实体的某个对应特征,其中,h0为l0层到l1层的输入。执行步骤132,计算第1图卷积层l1的输出。卷积层l1的输出h1=[n*c1],公式为h1=relu(aih0w1),神经元激活前的输入值为:z1=aih0w1,共n*c1个神经元节点,每个节点均是包含了全部输入实体的全部特征的某种线性组合,其中,w1为第1卷积层的卷积窗权重矩阵。执行步骤133,计算第2图卷积层l2的输出。卷积层l2的输出h2=[n*1],公式为h2=relu(aih1w2),神经元激活前的值为:z2=aih1w2,本层共n个神经元节点,其中,w2为第2卷积层的卷积窗权重矩阵。执行步骤134,计算池化层l3的输出。利用fi节点类型矢量对h2进行下采样,仅保留小区节点,得到h3=f(h2,fi)=[nc*1],本层共nc个神经元节点。执行步骤135,计算输出层l4的输出。将所述池化层l3的nc个神经元的输出两两连接,得到共nc*(nc-1)/2个小区对神经元节点。小区对神经元节点分为a类神经元、b类神经元和c类神经元。a类神经元是指对于小区对间存在已知关系的神经元,不做任何处理,也不做bp参数更新,直接将输出置为0,所述a类神经元共n1个。b类神经元是指对于小区对间关系未知、但站间距超过2倍平均站间距的神经元,强置其预测结果为0,需要利用bp进行参数迭代更新,所述b类神经元共n2个。c类神经元是指对于小区对间关系未知、但站间距小于2倍平均站间距的神经元,需要预测其正例概率,并需要计算损失函数、进行bp参数迭代。所述c类神经元共n3个。对每个所述c类神经元的输入取logistic回归分类函数得到输出神经元向量
其中,
执行步骤140,计算模块230进行所述p-gcn模型训练的反向误差计算。如图1c所示,执行步骤141,计算所述输出层的预测误差loss、神经元残差δ4和参数梯度。对所述b类神经元和c类神经元,比较各神经元输出的邻区关系正例概率yj与真实值
该神经网络的总预测误差为:
=∑,
神经元j的残差4即为预测误差对该神经元输入值的导数,即
计算输出层参数4,4的梯度:
执行步骤142,计算所述池化层l3的神经元残差3。将输出层各神经元的残差δ4的值按照与池化层神经元的连接权重反向分配给所连接的两个池化层神经元,每个池化层神经元的残差3等于其所连接的所有输出层神经元分配过来的残差4的加权和。执行步骤143,计算所述第2图卷积层l2的神经元激活后残差j2、神经元残差2和参数梯度。根据池化层神经元与第2图卷积层神经元的连接关系,将池化层神经元的残差3赋给相连的l2神经元即为该l2神经元的激活后残差,即2=3,
将损失函数对l2层relu函数求偏导,即得l2神经元的残差2:
其中,⊙为哈达玛积。执行步骤144,计算所述第1图卷积层l1的神经元残差1和参数梯度。将损失函数先对l2层卷积求偏导,再对l1层relu函数求偏导,即得l1层神经元的残差1:
计算该层的卷积窗参数1的梯度:
其中,180是对矩阵进行左右和上下翻转操作,*为卷积运算。
执行步骤150,更新模块240更新所述p-gcn模型训练的参数。如图1d所示,执行步骤151,更新输出层参数。更新输出层的神经元j的反向连接权重:
4=4-(-^)3,4=4-(-^),
其中,为学习率。执行步骤153,更新第2图卷积层l2的卷积窗权重,2=2-(1)′·2。执
行步骤153,更新第1图卷积层l1的卷积窗权重,1=1-(0)′·1。
执行步骤160,预测模块250利用训练好的所述p-gcn模型对预测区域中的各子区域+1~进行分区域的邻区关系预测,其中,为训练区域所包含的子区域个数,为子区域的总个数。如图1e所示,对子区域si,i=(t+1)~k,依次进行以下子步骤:步骤161,根据所述p-gcn模型训练的前向计算方法计算得到4。步骤162,判断4的值是否大于门限阈值。如果4的值大于门限阈值,则执行步骤163,推断该小区对之间存在邻区关系。如果4的值不大于门限阈值,则执行步骤164,推断该小区对之间不存在邻区关系。
执行步骤170,后处理模块260对所述预测的结果进行后处理。如图1f所示,执行步骤171,更新ncl。根据前面的预测结果相应更新ac矩阵,并同时更新ncl,即增加ncl中漏配的邻区,删除ncl中错配的邻区。执行步骤172,重叠区域的处理。对同一个小区对,如果多个子区域均有相应的预测输出,则通过投票法确定其最终的预测结果。
实施例二
知识图谱领域中的一个重要技术是知识预测,是指从知识库(知识图谱)中已有的实体关系数据出发,经过计算预测,建立实体间的新关联或发现实体间的错误关联,从而拓展丰富和校准知识网络。知识预测是知识图谱构建的重要手段和关键环节。主要分为两种方法:基于逻辑的预测(一阶谓词逻辑、描述逻辑、基于规则的预测)、基于图的预测(基于nn模型或pathranking方法等)。本发明主要采用基于图的知识预测方法。通过对已经初步构建完成的4g/5g无线网络知识图谱中已有的各类实体、属性和实体关系(不包含小区实体间的邻区关系)的分析和预测,预测出各小区实体间的邻区关系,并对系统中维护的已有ncl进行相应的校准(包括增加新的邻区关系、删除冗余或错配的邻区关系)。
本发明要解决的问题是如何基于海量的终端感知覆盖数据和基站测量报告数据提取数据中的各类邻区关系,对当前邻区关系列表中的错配或冗余邻区进行校正、并补充漏配的邻区关系,从而实现更高效、智能的邻区关系管理。
本发明的实施将有效保障邻区关系信息的有效性、完整性和时效性,是自动构建无线网络知识图谱的重要步骤。该方法可以作为现有人工路测和anr技术的补充甚至替代,指导运营商网络运维部门更高效、及时、方便地对无线网络中的基站邻区关系的配置和管理,为提高用户在网内小区间的切换成功率、提高业务连续性和保障良好的业务体验提供有力支撑。
本发明提出了一种基于图卷积神经网络的邻区关系预测方法,如图3所示,具体步骤详细描述如下:
输入数据:
(1)mcs或mr覆盖采样数据集d:mcs数据是有从海量用户终端上采集的数据构成,mr数据是指由基站设备上采集的该基站下各终端设备上报的测量信息所构成。两类数据所包含的属性(特征)字段:终端id(对mr数据,一般指imsi),采样日期,采样时间,经度,纬度,运营商,网络制式,大区id(4g和5g网络下为tac,即跟踪区码),基站id(4g网络下enbid,5g网络下为gnbid),小区id(cellid),物理小区id(pci),频点号(earfcn),导频信号强度(4g网络下rsrp,5g网络下的csi-rsrp),导频信号质量(4g网络下rsrq,5g网络下的csi-rsrq),导频信干噪比(4g网络下sinr,5g网络下的csi-sinr),邻区信息列表(包括该终端所测量的各邻近小区的网络制式、大区id、基站id、小区id、物理小区id、频点号、导频信号强度)。有些情况下部分字段有缺失。
(2)初步构建的目标区域s的无线网络知识图谱g=(v,e):v表示实体(节点)集合,e表示关系(边)集合。v至少包括小区实体集合vc、终端实体集合vt、采样实体vs集合、基站实体集合vb(可选)、栅格实体集合vr(可选),以及驻留关系(终端-小区)、关联关系(采样-小区,采样-终端)、隶属关系(小区-基站),但不包括邻区关系。
小区实体至少包括小区id、运营商、网络制式、大区id、基站id、站址经度、站址纬度、基站类型、方向角、倾角、物理小区id、频点号、覆盖率等属性(特征)字段;终端实体至少包括终端id、品牌、型号、运营商、网络制式等属性(特征)字段;采样实体至少包括终端id、采样日期、采样时间、经度、纬度、运营商、网络制式、大区id、基站id、小区id、物理小区id、频点号、导频信号强度、导频信号质量等属性(特征)字段;图谱数据存储于图谱数据库中。设置小区最低样本数约束,不满足最低样本数的小区从实体中剔除,不做处理。
(3)目标区域的小区邻接矩阵ac:ac=[nca*nca],nca为区域s内的小区总数。其中各元素为对应的小区对间邻区关系的标记值,1表示小区对间存在真实邻区关系,0表示小区对间不存在真实邻区关系,2表示未知(待预测)。该矩阵可由目标区域各基站当前的实际邻区列表(ncl)处理得到,其字段至少包括nclid,头小区id,尾小区id,标记。
步骤1:p-gcn模型初始化
p-gcn网络模型结构如图4所示。共包括5层,即输入层(l0层,n*d个神经元)、第1卷积层(l1层,n*c1个神经元)、第2卷积层(l2层,n个神经元)、池化层(l3,nc个神经元)、输出层(成对连接层,l4层,包含nc(nc-1)/2个神经元)。
(1.1)初始化节点特征矩阵x[n*d]:n是子区域的实体节点数(即图谱数据库中对应一个子区域si内的实体个数,其中nc是si内小区节点的数量),d是最大特征维数。从无线网络知识图谱数据库中提取各实体及其属性信息存入该矩阵。本发明中的无线网络知识图谱属于异质网络,即图谱中有不同的(实体)节点类型,各节点的特征维数亦不同,d可取为各节点中的最大特征维数,其他节点的特征维数不足者则在其缺失的特征项上补0;
(1.2)初始化节点类型向量f[n*1]:与x中的节点排序顺序相同,且小区节点对应项为1,其他为0,用于识别小区节点。
(1.3)初始化邻接矩阵a[n*n]:邻接矩阵,表征两两节点间的边是否存在(包括小区-基站,采样-小区,终端-小区,采样-终端,小区-小区。1为存在,0为不存在或未知)。
(1.4)随机初始化卷积窗权重矩阵w1=[d*c1],w2=[c1*1],w4=[nc(nc-1)/2*2]。对l1和l2两个卷积层,同层各神经元共享相同的卷积窗权重。
步骤2:区域分割
将目标区域s按空间分割为k个矩形子区域s1,s2,…sk,每个子区域内保证小区节点数固定为nc、总节点数为n(可通过对采样节点进行随机下采样控制总节点数为n),并相邻子区域保持一定程度的重叠。相应地,基于d、g、ac得到各子区域si的特征矩阵xi,节点类型向量fi,邻接矩阵ai,i=1~k,以及小区对关系指示向量pi(取值0/1/2分别对应各小区对是否为已知关系、未知关系但站间距超过2倍平均站间距、未知关系且站间距不超过2倍平均站间距)。ai中包含所有的隶属关系、驻留关系、关联关系、已标记的邻区关系(即ac中0、1对应的元素)。
其中部分子区域(记为s1~st,共t个)合并称为训练区域:该区域下的邻区关系完全已知,并随机取部分邻区关系作为训练时的输入信息,其余部分邻区关系用于测试。
其余子区域(记为st+1~sk,共k-t个)合并称为预测区域:该区域下的邻区关系仅部分已知并作为正向计算时的输入,其余部分为未知、待预测。
对每个训练子区域si,i=1~t按以下步骤3~5逐个处理,得到训练后的p-gcn模型。
步骤3:p-gcn模型训练的前向计算
(3.1)构造输入层l0:
对子区域si,令h0=xi=[n*d]。共n*d个神经元节点,每个节点为某个对应实体的某个对应特征值。
(3.2)计算第1图卷积层(l1)的输出:
根据下式计算本层神经元的输出h1=[n*c1]
h1=relu(aih0w1)(1)
其中神经元激活前的输入值为:z1=aih0w1。共n*c1个神经元节点,每个节点均是包含了全部输入实体的全部特征的某种线性组合。
(3.3)计算第2图卷积层(l2)的输出:
根据下式计算本层神经元的输出h2=[n*1]
h2=relu(aih1w2)(2)
其中神经元激活前的值为:z2=aihiw2。本层共n个神经元节点。
(3.4)计算池化层(l3)的输出:
利用fi节点类型矢量对h2进行下采样,仅保留小区节点,得到h3=f(h2,fi)=[nc*1]。本层共nc个神经元节点。
(3.5)计算输出层(成对连接层)(l4)的输出:
将l3的nc个神经元的输出两两连接,得到共nc*(nc-1)/2个小区对神经元节点。其中进一步分为三类神经元:
(1)a类神经元:对于小区对间存在已知关系(邻区、非邻区)的神经元,不做任何处理,也不做bp参数更新,直接将输出置为0。设该类神经元共n1个。
(2)b类神经元:对于小区对间关系未知,但站间距超过2倍平均站间距的神经元,强置其预测结果为0(即“非邻区”,不存在邻区关系)。需要利用bp进行参数迭代更新。设该类神经元共n2个。
(3)c类神经元:对于小区对间关系未知,但站间距小于2倍平均站间距的神经元,需要预测其正例概率。并需要计算损失函数、进行bp参数迭代。设该类神经元共n3个。
对每个c类神经元的输入取logistic回归分类函数得到输出神经元向量
其中
步骤4:p-gcn模型训练的反向误差计算
(4.1)计算输出层的预测误差loss、神经元残差δ4、参数梯度:
对b、c类神经元,比较各神经元输出的邻区关系正例概率yj与真实值
该神经网络的总预测误差为:
loss=∑jlossj(5)
神经元j的残差
进一步,计算输出层参数
(4.2)计算池化层(l3)的神经元残差δ3:
将输出层各神经元的残差δ4的值按照与池化层神经元的连接权重反向分配给所连接的两个池化层神经元,每个池化层神经元的残差δ3即等于其所连接的所有输出层神经元分配过来的残差δ4的加权和。
(4.3)计算第2图卷积层(l2)的神经元激活后残差j2、神经元残差δ2、参数梯度:
根据池化层神经元与第2图卷积层神经元的连接关系,将池化层神经元的残差δ3赋给相连的l2神经元即为该l2神经元的激活后残差,即j2=δ3。
将损失函数对l2层relu函数求偏导,即得l2神经元的残差δ2:
其中⊙为哈达玛积。
进一步,计算该层的卷积窗参数
(4.4)计算第1图卷积层(l1)的神经元残差δ1、参数梯度:
将损失函数先对l2层卷积求偏导,再对l1层relu函数求偏导,即得l1层神经元的残差δ1:
其中rotl80是对矩阵进行左右和上下翻转操作,*为卷积运算。
进一步,计算该层的卷积窗参数w1的梯度:
步骤5:p-gcn模型训练的参数更新
(5.1)更新输出层参数:
根据下式更新输出层的神经元j的反向连接权重:
其中α为学习率(全局超参数)。
(5.2)更新第2图卷积层l2的卷积窗权重:
w2=w2-α(aih1)′·δ2(14)
(5.3)更新第1图卷积层l1的卷积窗权重:
w1=w1-α(aih0)′·δ1(15)
步骤6:邻区关系预测
利用训练好的p-gcn模型对预测区域中的各子区域st+1~sk进行分区域的邻区关系预测。具体地,对子区域si,i=(t+1)~k,依次进行:
(6.1)根据步骤3计算得到h4。
(6.2)如果h4的值大于门限(默认0.5),则推断该小区对之间存在邻区关系,否则不存在。
步骤7:后处理
(7.1)更新ncl:根据前面的预测结果相应更新ac矩阵;并同时更新ncl,即增加ncl中漏配的邻区、删除ncl中错配的邻区;
(7.2)重叠区域的处理:对同一个小区对,如果多个子区域均有相应的预测输出,则通过投票法确定其最终的预测结果。
为了更好地理解本发明,以上结合本发明的具体实施例做了详细描述,但并非是对本发明的限制。凡是依据本发明的技术实质对以上实施例所做的任何简单修改,均仍属于本发明技术方案的范围。本说明书中每个实施例重点说明的都是与其它实施例的不同之处,各个实施例之间相同或相似的部分相互参见即可。对于系统实施例而言,由于其与方法实施例基本对应,所以描述的比较简单,相关之处参见方法实施例的部分说明即可。
- 还没有人留言评论。精彩留言会获得点赞!