一种无线携能通信技术的资源分配方法与流程
【技术领域】
本发明属于无线携能通信领域,具体涉及到一种面向模式划分多址接入技术的无线携能下行链路通信场景中的资源分配方法。
背景技术:
无线携能通信技术是一种新型的无线通信类型,其将无线电能传输与无线信号传输结合,在实现信息可靠交互的同时,来传输能量。随着无线携能通信技术的快速发展,传统供电方式的很多弊端:电线容易老化、很难做到及时更换电池等被解决。但是,解决无线携能通信技术中的节能和频谱利用率问题在目前仍具有挑战性。
此外,非正交多址接入技术是非常有前景的5g技术,可以满足下一代移动通信系统低功耗、高吞吐量、低时延和广覆盖的需求。并且非正交多址接入技术中的高频谱效率和高接入量等优点,恰好符合了5g时代的爆炸性的数据增长和接入需求。另外,非正交多址接入技术中的模式划分多址接入技术可充分利用多维域处理,具有编码灵活性高、适用范围广、复杂度低等优点。并且,模式划分多址接入技术在无线携能通信技术中的应用可以有效提高频谱资源利用率和能量效率。此处所提的用户服务质量包含接收端用户的最小接收能量需求和最小数据速率需求。因此,有必要寻找一种有效的工具来应对严峻的挑战。
近年来,如何在无线携能通信系统中设计合理有效的资源分配方法被越来越多的讨论。有人提出了一种基于无线携能通信的资源分配方法,具体方法是通过拉格朗日对偶法迭代计算子载波传输集合及子载波传输功率来作为最优传输功率,该方法的优势是具有通用性且用户服务质量最优,但是劣势是无法使发射端的功耗最小。传统方法在求解面向模式划分多址接入技术的无线携能下行链路通信场景中的发射端传输总功率最小化问题时,具有高计算复杂度和许多约束。尤其是当接收端有多个用户时,每个用户的服务质量都要被满足。
技术实现要素:
本发明的目的是提供一种面向模式划分多址接入技术的无线携能下行链路通信场景中的资源分配方法,以解决在满足接收端用户的服务质量的同时,保证发射端传输总功率最小仍具有很大的计算复杂度的问题。
本发明采用的技术方案是,一种面向模式划分多址接入技术的无线携能下行链路通信场景中的资源分配方法,按照以下步骤实施:
步骤一、约束马尔可夫决策过程的制定:
将面向模式划分多址接入技术的无线携能通信场景中的资源分配问题描述为约束马尔可夫决策过程,使用拉格朗日对偶方法将其转化为无约束马尔可夫决策过程;
步骤二、使用强化学习的方法求解步骤一中的无约束马尔可夫决策过程,最终得到最优的资源分配策略;该策略的目标是在满足接收端每个用户的服务质量的前提下最小化发射端的传输总功率。
进一步的,将所述无线携能下行链路通信场景构建为系统模型,所述的系统模型具体为:
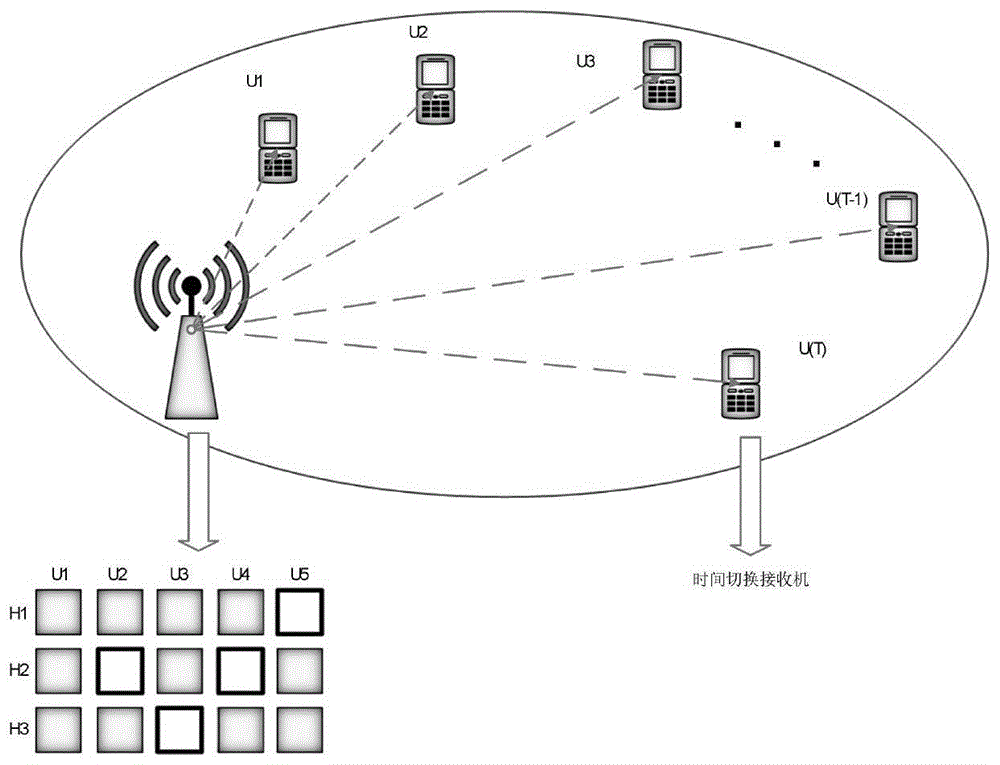
一个基站通过k个子载波对特定区域内的t个用户进行数据和能量的无线传输,其中发射端采用叠加编码,接收端采用串行干扰消除技术,且发射端的基站和接收端的用户均匹配单个天线;用户随机分布在以基站为中心,半径为r的圆内。
进一步的,步骤一具体为:
1)根据所述系统模型,定义系统的状态空间和动作空间:
所述系统的状态空间具体如下:
s=(sinrk,t,k=0,1,...k,t=0,1,...t)∈s=sinr(1),
其中,sinrk,t是第k个子载波加载到第t个用户时的信干噪比,状态集合sinr是属于信干噪比的有限集;
所述系统的动作空间具体如下:
其中,
2)约束马尔可夫决策过程具体如下:
其中,ptotal是发射端的传输总功率;公式(4)和公式(5)表示每个用户的服务质量的约束,即每个用户接收到的能量et和数据速率rt都要分别满足最小能量要求ereq和数据速率要求rreq;马尔可夫决策过程描述为通过调整动作
该马尔科夫决策过程可以放宽为无约束的马尔可夫过程,即:
其中,
进一步的,步骤二中,强化学习中的q值的更新公式具体如下:
其中,rk+1、γ和0<ρ<1分别是k+1时刻得到的奖赏、奖励折扣系数和学习率;
最优值函数表示如下:
其中,q*(s,a)是对于状态s和动作a遵循最优策略时给出的q值。
本发明的有益成果是:
1、本发明提出了一种面向模式划分多址接入技术的无线携能下行链路通信场景中的资源分配方法。以时间切换接收机为例,通过联合优化接收机分配给能量接收和数据速率的时隙比率、子载波映射矩阵及功率分配矩阵,获得发射端处最小传输总功率。
2、为了解决约束马尔可夫决策过程求解困难的问题,此处使用拉格朗日对偶理论将其转化为无约束的马尔可夫决策过程。最后,通过应用强化学习中的q学习算法来获取马尔可夫决策过程中的最优策略。
3、本发明通过实验验证了所提方法的有效性,该方法与其他方法相比,发射端可以获取更低的传输总功率。
【附图说明】
图1为本发明一种面向模式划分多址接入技术的无线携能下行链路通信场景中的系统模型图;
图2为实施例中在不同的迭代次数下,传输总功率的变化示意图;
图3为实施例中在不同的用户数据速率需求下,采用dbn算法和所提出的q学习算法的性能比较;
图4为实施例中在不同的用户接收能量需求下,采用dbn算法和所提出的q学习算法的性能比较;
图5为实施例中不同用户服务质量需求及不同用户数量下,发射端最小传输总功率的比较。
【具体实施方式】
下面结合附图和具体实施方式对本发明进行详细说明。
本发明为了保证面向模式划分多址接入技术的无线携能下行链路通信场景中发射端的传输总功率最小,研究了基于约束马尔可夫决策过程的资源分配方法。具体地,将面向模式划分多址接入技术的无线携能通信场景中的资源分配问题描述为约束马尔可夫决策过程,通过利用拉格朗日对偶理论将约束马尔可夫决策问题转化为无约束马尔可夫决策过程。最后,提出了一种q学习算法来求解无约束马尔可夫决策过程的最优解。以时间切换接收机为例:在满足每个用户服务质量的同时将上述场景中的功率分配矩阵、子载波映射矩阵和分配给信息解码和能量收集的时隙比率调整为最佳值以最小化发射机的传输总功率。
步骤一、构建系统模型:系统模型为基于模式划分多址接入技术的无线携能下行链路通信系统模型,是由一个基站和多个用户组成;
步骤一的具体方式为:
如附图1所示,假设存在一个基站通过k个子载波在特定区域内给t个用户无线传输数据和能量,其中
其中,hk,t=rk,tdk-β是通过子载波hk从基站到用户ut的信道增益,rk,t是满足瑞利分布的小规模衰落,
接收端采用串行干扰消除技术,按照
因此,第k个子载波加载到第t个用户时的信干燥比是:
其中,
rk,t=bklog2(1+sinrk,t)(4)
其中,η是能量收集效率。另外,αt和1-αt分别是分配给信息解码和能量收集的传输时隙比率,从而可以推出每一个用户收集的信息及能量分别是:
步骤二、约束马尔可夫决策问题的制定:将无线携能通信系统中的资源分配问题转换为约束马尔可夫决策问题,通过使用拉格朗日对偶理论来将其转化成无约束马尔可夫决策问题。
步骤二的具体实施方式如下:
决策者在满足接收端每个用户接收到的能量需求和数据速率需求时,最小化发射端的传输总功率。下面将带有用户服务质量约束的资源分配问题表示为约束马尔可夫决策问题,其为每个状态提供了相应的资源分配策略。接下来,系统的状态空间、动作空间、目标和约束将被分别描述。
1)状态空间:为了表征用户接收的能量和信号,我们定义状态空间为:
s=(sinrk,t,k=0,1,...k,t=0,1,...t)∈s=sinr(8)
其中,状态集合sinr是属于信干燥比的有限集。
2)动作空间:发射机通过控制功率分配及子载波映射,接收机通过控制分配给信息解码和能量收集的时隙比率,来使传输总功率最小。因此,动作空间是:
其中,
3)目标和约束:目标是寻找最优策略π,使得发射端的传输总功率,即ptotal最小;约束是满足每个用户最小的能量和数据速率需求。该资源分配问题可以转化成约束马尔可夫决策过程,即p1:
该问题在满足每个用户服务质量约束的同时,采取策略π自适应的调整所有接收机分配给信息解码的时隙比率、发射端的子载波映射及功率分配来使发射端的传输总功率最小。为了解决该约束马尔科夫问题,拉格朗日对偶理论将其转化为无约束的马尔科夫过程。下面将引入广义拉格朗日函数:
其中,λ={λ1,λ2,λ3,...,λt=t}、μ={μ1,μ2,μ3,...,μt=t}是拉格朗日算子集合,并且元素λ1,λ2,λ3,...,λt=t和μ1,μ2,μ3,...,μt=t分别是拉格朗日乘子分别对应于每个用户收获的能量和接收的数据速率的约束。考虑l(λ,μ,π)作为λ和μ的函数,被定义为:
当接收机满足用户服务质量约束时,θ(π)的值是ptotal。当约束不被满足时,使两组拉格朗日算子取正无穷大,则θ(π)的值趋于无穷大,导致函数无解。因此,θ(π)函数可以被描述为:
因此,约束马尔可夫决策过程可以放宽为无约束的马尔可夫决策过程,即:
其中,
l(π,λ*,μ*)≥l(π*,λ*,μ*)≥l(π*,λ,μ)(21)
由于信道转移概率难以估计,q学习算法被提出用来求解该无约束马尔可夫决策过程的最优解。
步骤三、使用强化学习的方法获取面向模式划分多址接入技术的无线携能通信场景中基于约束马尔可夫决策过程的资源分配的最优策略。
步骤三的具体实施方式如下:
强化学习算法被广泛应用于无模型mdp问题的最优控制策略的学习,这意味着信道转换等环境模型不需要考虑。因此,强化学习中的q学习算法被提出来求解上述资源分配问题。下面将分别给出q学习算法的q值计算公式、更新公式、ε-greedy策略及奖励函数。对于策略π,在状态s处执行动作a时的q值计算公式是:
qπ(s,a)=eπ[rk+1+γqπ(sk+1,ak+1)|sk=s,ak=a](22)
其中,rk+1和γ分别是k+1时刻得到的奖赏和奖励折扣系数。在q学习算法中,q值的更新公式是:
其中,0<ρ<1是学习率。在状态s时,行动a是根据ε-greedy的策略选择的,以便做出总体上的最佳决策。因此,动作的选择遵循:
其中,~u(a)函数是在均匀动作空间内随机选取任一动作。为了直接反映目标值的奖赏函数,其被定义为:
另外,使用次梯度法计算和更新拉格朗日乘子。计算和更新完q值之后,对问题的控制策略(p2)可以描述为:
在这里q*(s,a)是对于状态s和动作a遵循最优策略给出的q值。
实施例:
以下实例中所提供的图示以及模型中的具体参数值的设定主要是为了说明本发明的基本构想以及对本发明做仿真验证,具体的应用环境中,可视实际场景和需求进行适当调整。
本发明面向模式划分多址接入技术的无线携能通信场景,其中发射机和接收机都配备单个天线。通过仿真证明了所提方法的有效性:(1)比较了算法在不同学习率下的收敛性能;(2)随着用户接收能量需求的变化,发射端的传输总功率随算法的不同而变化。这里,将所提出的基于约束马尔可夫过程的q学习的算法与基于遗传算法的dbn算法进行了比较;(3)随着用户数据速率需求的变化,发射端的传输总功率随算法的不同而变化。这里,将所提出的基于约束马尔可夫过程的q学习的算法与基于遗传算法的dbn算法进行了比较;(4)随着接收端用户数量的变化,发射端的最小传输总功率随用户服务质量需求的不同而变化。
在仿真中,我们假设所有的用户分布在以基站为中心,半径为300米的圆内,即dk在(0meters,300meters)中被随机产生。路径损耗系数β被假设为3.76。为了满足接收端的能量需求,能量收集的接收机的功率转换效率被假设为η=30%。另外,假定最大可用发射功率和噪声值分别被设定为p=30%和σ2=0.01w。为了学习q值,设置满足约束(13)、(14)和(15)的动作集。因此,状态空间是对应动作空间的有限集合。除此之外,其他参数设定为:kmax=2500,ε=0.1和γ=0.8。在仿真过程中,三个性能指标是:发射端的传输总功率、接收端收获的能量和数据速率。资源分配策略的优缺点通过性能指标被表征。
如图2所示,研究了不同学习率下总发射功率的收敛性,确定了合适的算法学习率,其中ρ被分别设置为0.4、0.5和0.6。另外,用户数和子载波数均被设置为2。此外,获取的能量约束和数据速率约束分别被设置为ereq=0.1w和rreq=1mbit/s。可以观察到,在不同的学习速率下,传输总功率收敛到0.35w。显然,收敛速度和稳定性在不同的学习率下是不同的。考虑到收敛速度和稳定性两个因素,采用了学习率为0.6。由于算法采用贪婪策略,基于约束马尔可夫过程的资源分配方案的总传输功率将随着迭代次数的增加而略有变化,但总传输功率的总体趋势不受影响。
如图3和图4所示,算法的有效性被研究,其反映了所提出来的基于q学习算法和dbn算法在不同用户服务质量下的性能比较。在仿真参数设置中,接收端用户数目被设置为3。结果表明,该算法是有效的,可以显著降低总传输功率。
最后,图5展示了在不同用户数和不同用户服务质量约束下,所提出的q学习算法估计的发射端的最小传输总功率,其中接收机的用户数分别设置为2、3和4。如图5所示,观察到由于用户的服务质量的增加导致发射端的传输总功率有增加的趋势。此外,随着用户数的增加,发射端的最小传输总功率的增长趋势也逐渐显现出来。以上结果均验证了该算法的有效性和合理性。
- 还没有人留言评论。精彩留言会获得点赞!