背景知识引导的特征化定位隐私防泄露方法与流程
本发明涉及一种定位隐私防泄露方法,特别涉及一种背景知识引导的特征化定位隐私防泄露方法,属于用户定位隐私保护技术领域。
背景技术:
随着智能手机在全世界范围内的广泛使用,移动互联网呈现出井喷的发展态势,人们急切的希望能随时随地甚至是在不断移动时都能够便捷的从互联网获取所需要的各种信息,提供各种服务。随着移动互联网的大规模普及,用户可以随时随地通过各种手持定位设备连接到互联网,互联网与人们的生活联系更加紧密,用户们能够更好的享受互联网带来的诸多便利。移动互联网与传统互联网最大的区别就是具备良好的移动性,移动性的融入使得互联网中增加了关键的地理定位信息。地理定位信息的融入,丰富了人们的日常生活,比如随时随地知道自己和好友所处的位置,查找附近评价较高的餐馆,定位服务应用在移动互联网中是最受关注和欢迎的应用。虽然定位服务应用给人们生活的各方面带来了极大的便利,但还是有不少用户拒绝采用定位服务,担心自己的隐私被泄露是最主要原因,这也是阻碍定位服务安全持续有效发展的重要因素。
伴随定位服务在用户中日益大规模推广应用,人们越来越离不开定位服务应用带来的便利时,针对定位服务的一系列攻击也悄然出现。位置窃取者可通过研究用户的地理定位信息,判定出用户的生活规律和习惯,通过分析用户晚上最常出现的位置猜测用户的家庭住址,通过工作日白天最常出现的位置得出用户的工作地址,分析用户位置轨迹还可得到用户的重要生活信息,这些隐私信息被位置窃取者掌握后,用户的人身财产安全都会受到极大的威胁。定位服务应用容易泄露用户隐私信息的问题已成为一个急需解决的问题,若能有效的解决定位服务隐私信息泄露问题,将大幅推动定位服务应用的推广,开拓更加广阔的市场空间。
用户希望自己的隐私信息不被泄露的同时,又还希望能够享受到定位服务应用提供的各种便利和服务。就像鱼和熊掌不可兼得一样,一方面用户想把自己精准定位信息隐藏以免泄露给位置窃取者,另一方面还需要享受精准位置才能够提供的良好服务,用户需要在定位服务应用质量和位置隐私信息防护之间做出权衡。
定位服务系统通常由以下四部分组成,即移动终端、定位系统、通信网络、定位服务服务器。用户采用移动终端完成定位服务查询申请,需先向定位服务器发送包含其位置的查询申请,而用户的定位信息是通过定位系统提供的,通信网络传输用户的查询申请和返回查询结果,定位服务器根据用户的查询申请返回对应的查询结果。过程中有三处可泄露用户的隐私,一是用户的移动终端,若该设备已被捕获,那就会主动泄露用户的隐私信息;二是用户的查询结果通过通信网络返回到用户时,有可能被窃取,三是定位服务服务器的拥有者可采集定位信息,严重威胁用户隐私安全。
防止位置窃取者在用户不知情时获取用户过去或现在的定位信息的目的包括:一是增加用户身份的未知性,使得恶意位置窃取者不能确定用户的准确身份;二是增加用户位置的未知性,使位置窃取者也不能够确定用户的具体位置;三是消除用户身份与地理位置的关联性,使位置窃取者不能够把用户访问的位置与其准确身份关联起来。其次除了掩饰用户地理定位信息,还需要根据用户的实际情形提供隐私防泄露服务。每个人在不同的时间和地点对自己定位隐私防护需求也不相同。所以在设计移动互联网隐私防护机制时,还需兼顾数据的可用性及高效性。隐私防泄露机制需要在原有系统中融入复杂方法,处理用户的身份和位置数据,虽然提高了用户定位隐私的防护度,却降低了数据的可用性及高效性,势必会降低用户体验。因此,在设计位置隐私防泄露机制时,需在定位隐私防护与数据可用性、高效性之间确定一个平衡点。
现有技术的用户隐私信息防泄露技术主要有三种方法,一是用户身份的隐私防泄露,二是用户地理位置的隐私防泄露,三是数据发布中的隐私防泄露。从这三种方法引出的隐私防泄露技术分别为:假名,构造假地址和k-匿名隐私防泄露。假名是一种掩饰用户身份信息,兴趣爱好等隐私的一种重要的隐私防泄露技术手段,但匿名和假名技术的防泄露目标是用户的在线身份,随着数据挖掘技术的不断推进,位置窃取者已可以利用数据挖掘技术等手段来获取用户的隐私信息,所以仅仅用假名技术来掩饰用户的隐私信息已不再安全。
现有技术针对用户定位信息的隐私防护也提出了许多模型和方法,按照用户隐私信息的防防护手段主要可以分为二类:一是假地址技术,二是隐匿空间技术。假地址技术主要是当用户向定位服务服务器发送服务申请时,除发送自己的真实地理位置外,还发送一些随机生成的伪地址,这样即使窃取到了用户的定位信息,也无法判定到底哪个定位是真实的。而隐匿空间技术是将用户的真实位置泛化,用一个位置区域去替代用户精准的真实位置,让用户在距离自己真实位置的范围内选择合适的区域位置作为代理,把代理地址作为假地址向定位服务器提出服务申请。若假地址选取的范围较大,则会影响用户申请服务的质量,但若假地址范围过小,用户的真实位置得不到很好的防护,所以假地址的隐私防泄露方法的难点就在于如何平衡定位隐私和用户体验这对矛盾体。
现有技术把k-匿名隐私防护的思想融入到了定位应用服务中,主要集中在二个方面,即关于数据的隐私防泄露和基于位置服务的隐私防泄露,对原始数据进行处理,使得用户的敏感数据和个体之间的对应关系被切断,恶意位置窃取者无法通过掌握的敏感隐私信息对应到具体的用户,从而实现有效的隐私防泄露。
现有技术关于位置的隐私防泄露模型主要有三种匿名模型:一是位置k-匿名模型,二是位置l-多样性模型,三是其余位置k-匿名模型。这些模型都是采用可信的第三方来完成用户的匿名过程,但在用户比较稀疏的地理位置,会产生面积过大的模糊区域,导致用户获得的用户体验严重下降。现有技术的用户协作无匿名区域的定位隐私防泄露方法采用无中心服务器的系统结构,无需采用第三方来完成匿名过程,但该方法需要用户间的共同协作,若用户组中混入了位置窃取者,用户之间的可信度便难以保证,其余用户的隐私安全也会受到威胁。
针对现有技术存在的部分缺点,本发明拟解决以下问题:
一是伴随定位服务在用户中日益大规模推广应用,人们越来越离不开定位服务应用带来的便利时,针对定位服务的一系列攻击也悄然出现,位置窃取者可通过研究用户的地理定位信息,判定出用户的生活规律和习惯,通过分析用户晚上最常出现的位置猜测用户的家庭住址,通过工作日白天最常出现的位置得出用户的工作地址,分析用户位置轨迹还可得到用户的重要生活信息,这些隐私信息被位置窃取者掌握后,用户的人身财产安全都会受到极大的威胁,定位服务应用容易泄露用户隐私信息的问题已成为一个急需解决的问题,有效解决定位服务隐私信息泄露问题,将大幅推动定位服务应用的推广,开拓更加广阔的市场空间。
二是用户希望自己的隐私信息不被泄露的同时,又还希望能够享受到定位服务应用提供的各种便利和服务。就像鱼和熊掌不可兼得一样,一方面用户想把自己精准定位信息隐藏以免泄露给位置窃取者,另一方面还需要享受精准位置才能够提供的良好服务,需要一种方法在定位服务应用质量和位置隐私信息防护之间做出权衡。
三是现有技术的匿名和假名技术的防泄露目标是用户的在线身份,随着数据挖掘技术的不断推进,位置窃取者已可以利用数据挖掘技术等手段来获取用户的隐私信息,所以仅仅用假名技术来掩饰用户的隐私信息已不再安全。现有技术若假地址选取的范围较大,则会影响用户申请服务的质量,但若假地址范围过小,用户的真实位置得不到很好的防护,所以假地址的隐私防泄露方法的难点就在于如何平衡定位隐私和用户体验这对矛盾体。
四是现有技术关于位置的隐私防泄露模型都是采用可信的第三方来完成用户的匿名过程,但在用户比较稀疏的地理位置,会产生面积过大的模糊区域,导致用户获得的用户体验严重下降。现有技术的用户协作无匿名区域的定位隐私防泄露方法采用无中心服务器的系统结构,无需采用第三方来完成匿名过程,但该方法需要用户间的共同协作,若用户组中混入了位置窃取者,用户之间的可信度便难以保证,其余用户的隐私安全也会受到威胁。
五是现有技术的k-匿名技术也不能够满足用户位置隐私防泄露的需求,主要集中在以下方面,一是k-匿名技术在静态数据的发布过程中应用的很成熟,但是在动态数据的发布中,还是需要投入更多的研究精力提出更好的方法,二是k-匿名技术是通过降低数据质量来获取数据的隐私护,导致不可能同时获得高质量的数据和很安全的隐私防护效果,很难平衡这二者之间的矛盾,三是针对不同场景下的位置隐私防护也是一大新需求,用户在不同场景下对自己信息需要防泄露的程度不同,四是k-匿名技术在采用服务器结构的定位服务应用中需要可靠的第三方即匿名器,当前匿名器的发展成为了该技术在定位服务领域推广的瓶颈,匿名器很容易成为位置窃取者的目标,一旦匿名器被位置窃取者破解,用户的隐私信息和定位信息都会被泄露,五是在点对点的定位服务应用中,虽不像服务器结构模式的定位服务应用需要融入可靠的第三方,但在用户端需要完成匿名计算,会导致用户端的计算压力过大,若恶意位置窃取者混入用户组也会导致用户隐私信息的泄露,对用户安全造成重大威胁。
技术实现要素:
针对现有技术的不足,本发明提供的背景知识引导的特征化定位隐私防泄露方法,前提条件是用户不会信赖附近的普通用户和第三方服务器,并能根据用户的特征化需求提供不同级别的隐私防泄露服务。在用户相互分享定位信息时,不再分享自己的精准位置,而是采用一个经过精心计算得出的混杂区域替代用户的真实位置,用户的混杂区域生成基于其附近用户的混杂区域计算得到,并且区域内的用户数量是未知的,一个面积较大的混杂区域可提供更好的隐私防泄露效果,但也会导致用户体验下降,所以本发明从隐私防护效果和用户体验二个方面综合考虑权衡,得出的是面积较小的同时包含的用户数量尽量多的混杂区域,使得用户在自己的隐私信息不被泄露的同时,又还能够享受到定位服务应用提供的各种便利和服务,是解决定位服务隐私信息泄露问题综合效果最佳的方法之一,具有巨大是推广应用价值和广阔的市场空间。
为达到以上技术效果,本发明所采用的技术方案如下:
背景知识引导的特征化定位隐私防泄露方法,基于对象用户与邻近用户之间相互不信赖的前提,采用分布式点对点定位隐私防泄露体系结构,利用模糊法保护用户定位隐私,根据混杂区域生成的过程提出二种方法,第一种为枚举遍历取优法,遍历所有可能的矩形区域选择出最优解;第二种为贪婪扩张策略法,采用贪婪算法每次扩张混杂区域到当前最优单元格处;
本发明结合现实生活中的真实场景,将特征化位置语义、特征化时间、特征化面积融入混杂区域生成过程,提出特征化混杂区域定位隐私防泄露方法,特征化混杂区域生成方法包括特征化位置语义、特征化时间、特征化面积,在不同时间段的同一个位置区域位置语义系数j动态变化,根据这一情形融入时间系数a,同一位置区域在不同的时间段中在混杂区域中出现的概率不相同,利用特征化因素使得方法生成的混杂区域各处用户分布的概率相当,即各处的位置语义系数大致相等,抵御具有背景知识的恶意位置窃取者的位置语义攻击;
根据用户之间相互不信赖,采用混杂区域来替代自己的精准位置,对隐私防泄露方法中的混杂区域做基本定义;
定义一:混杂区域,用bx表示混杂区域,已知混杂区域是一个矩形,则混杂区域用下面的五元组定义:
bx=(xc,yc,xb,yb,ui)
坐标(xc,yc)和(xb,yb)分别表示矩形区域混杂的左下角和右上角的坐标,ui表示用户唯一的身份标识,不同用户之间的用户ui不同,每个混杂区域具有唯一性;
定义二:混杂区域面积大小,混杂区域的面积w(bx)表示为:
w(bx)=|xc-xb|×|yc-yb|。
背景知识引导的特征化定位隐私防泄露方法,进一步的,用户根据自己隐私防护度的需求通过二个自定义的参数限定混杂区域生成的面积范围,即dmax和dmin,确定混杂区域面积大小是在用户隐私防护程度和用户体验上做出权衡,较大dmin的混杂区域包含更多的邻近用户,用户数量的增多显著提高该区域的隐私防泄露能力,防止隐私信息被恶意位置窃取者获取,较大的dmax会大幅降低用户体验,较大的区域会导致较多的查询返回集合,用户必须花更多时间和资源在返回的查询集合中根据自己的真实位置进行筛选,并且传输包含较多查询结果的集合会占用大量的网络带宽,最后生成一个面积较大的混杂区域会占用用户端更多计算资源,产生过大的负载,设置合理的dmax值和dmin值对混杂区域的生成很关键;
用户之间的混杂区域可相互覆盖,且用户自己可出现在其混杂区域的任何位置,即使一个用户知道其自己的混杂区域和其余用户混杂区域的覆盖情形,该用户也无法判定其余用户是否出现在混杂区域公共部分,同样用户也无法判定自己的混杂区域到底包含多少个其余用户,根据以上定义对混杂区域的生成方法描述:
输入:1-根据用户自己隐私防护需求特征化定义dmax和dmin的限定,
2-用户采集到的其余邻近用户各自的混杂区域;
输出:对象用户的混杂区域;
约束:对象用户混杂区域的面积w(bx)满足dmax和dmin的限定。
背景知识引导的特征化定位隐私防泄露方法,进一步的,混杂区域生成的用户定位信息设置在网格化地图上,每个用户的真实位置用地图上的一个单元格表示,多个用户可属于同一单元格,这种基于网格化表示用户定位信息的地图定义为位置地图,一个混杂区域可被表示为一个矩形区域,(xc,yc)和(xb,yb)分别表示矩形区域混杂的左下角和右上角的坐标;
生成混杂区域的基本流程为:对象用户融入到分布式点对点体系结构中,该用户的定位设备通过点对点的通信协议搜索四周的邻近用户,并进行混杂区域的位置分享,当对象用户获取到一组邻近用户的混杂区域后,采用对应的混杂区域生成方法生成自己的混杂区域;在四周用户稀疏采集到的混杂区域不满足要求或根本搜索不到四周混杂区域的情形下,用户生成一个面积和位置都随机的混杂区域,采用生成的混杂区域替代自己的真实位置,向定位服务服务器发送查询申请。
背景知识引导的特征化定位隐私防泄露方法,进一步的,枚举遍历取优法遍历所有包含对象用户单元格的矩形区域,直至找到用户密度为最大值的矩形区域,将该矩形区域作为对象用户的混杂区域;
将枚举遍历取优法具体步骤为:
第一步,对位置地图中的每个单元格分别计算各自的赋值,
第二步,根据枚举遍历取优法分别在位置地图左侧和右侧选取单元格,若选取的左右单元格覆盖的区域不包括对象用户的真实位置单元格或者覆盖区域的面积不在dmin和dmax的范围内,舍弃该单元格;
第三步,直至计算出满足要求且用户密度的值最大的矩形区域。
背景知识引导的特征化定位隐私防泄露方法,进一步的,贪婪扩张策略法对于每个单元格的赋值,需要考虑其与对象用户所在单元格的距离,有如下定义:
定义四:距离相关单元格值,对某一个单元格,距离相关单元格值为该单元格与对象用户所在单元格覆盖的矩形区域内所有单元格的值与区域内单元格数量的比值;
贪婪扩张策略法的具体步骤为:对位置地图中的每个单元格分别计算其各自的赋值得到每个单元格的单元格值,然后根据定义四计算每个单元格的距离相关单元格值,用距离相关单元格值更新整个位置地图得到距离相关位置地图;贪婪扩张策略法在距离相关位置地图的基础上生成混杂区域,选择此时距离相关单元格值最大的单元格,将区域扩展至该单元格处;然后将粗线框中的单元格对应在位置地图中的单元格值均设为0,并且重新计算该地图单元格的距离相关单元格值,更新整个距离相关位置地图的值;根据新的距离相关位置地图选取当前新地图距离相关单元格值的最大值,将区域扩展至该单元格处;重新计算扩展后的地图单元格值和距离相关单元格值,又得到当前距离相关单元格值最大的单元格,不断重复以上过程,直至区域的面积达到最大值或没有距离相关单元格值大于0的单元格存在,最终生成的混杂区域图。
背景知识引导的特征化定位隐私防泄露方法,进一步的,特征化位置语义将地理位置的语义信息与混杂区域的生成方法相融合,加强抵御位置窃取者利用位置语义背景知识进行恶意攻击的能力;
定义基于特征化位置语义方法中的参数:
定义五:位置语义系数j,模拟现实生活的实际场景,对地图中的每个单元格指定一个具体的位置语义,每个用户可为不同的语义位置指定对应的位置语义系数,依据现实生活的场景,不同用户之间对位置的语义感知程度不同,语义位置系数根据不同用户的实际情形调整;
定义六:用户在某网格中出现的概率q,对于一个混杂区域n,生成该混杂区域的用户出现在n中某一个网格t的概率为:
j(t)表示的是网格t的位置语义系数,若某个混杂区域n中每个网格的位置语义都相同,则所有网格的j(t)相同,代表用户出现在每个网格的概率相等;某个单元格可能同时被多个用户的混杂区域覆盖,不同混杂区域覆盖同一单元格表明该单元格上用户出现的概率增加,于是定义为:
定义七:用户在某一个单元格出现的概率和q,对于一组混杂区域空间,记为n,即n={n1,n2,n3.....nm},假设n中的所有区域都覆盖单元格t,则用户在单元格t出现的概率为:
q(t)=q1(t)+q2(t)+......qm(t);
定义八:混杂区域密度a,已知一个混杂区域,记做n,区域n中的单元格记做t,则混杂区域密度由下式计算:
其中|n|表示的是区域n中单元格的数量,即表示n的面积;
特征化位置语义隐私防泄露方法应用步骤为:通过分布式点对点通信协议,用户之间分享各自的特征化位置语义混杂区域,对象用户接受来自其余邻近用户的特征化位置语义混杂区域,利用这些区域和对应的方法生成自己的特征化位置语义混杂区域,收到其余用户特征化位置语义混杂区域信息的基础上,根据定义六和定义七计算每个单元格的用户在该单元格出现的概率和,一个单元格的q(t)值越大说明用户在该单元格出现的概率越高;最后基于这些q(t)值再采用本发明的枚举遍历取优法或贪婪扩张策略法为用户计算其特征化混杂区域。
背景知识引导的特征化定位隐私防泄露方法,进一步的,特征化时间考虑时间因素,大幅加强该方法抵御位置攻击的能力,具体为:
定义九:时间因素融合语义位置系数j,将时间因素与定义五中的位置语义系数j相融合,通过(j,a)二元组定义不同位置单元格在当前时间a下的语义位置系数,时间因素a融合位置语义系数j的二元组(j,a)反应在某个区域上的a时刻用户存在的概率,该二元组的值根据不同时刻的不同区域人流量计算。
背景知识引导的特征化定位隐私防泄露方法,进一步的,特征化面积对混杂区域进行面积最大值dmax和面积最小值dmin的设定,设置合理的混杂区域的面积大小,在用户位置隐私防护程度和用户体验上做出权衡,对dmax和dmin进行设置调整以适应用户不同程度的隐私需求。
背景知识引导的特征化定位隐私防泄露方法,进一步的,由特征化位置语义,特征化时间和特征化面积可完整的定义特征化的混杂区域生成方法;
定义十:位置特征化系数f,位置特征化系数由位置语义系数j,时间系数a,以及区域最大面积dmax和区域最小面积dmin定义的四元组f={j,a,dmax,dmin}构成;
特征化混杂区域生成方法如下所示:
输入:其余邻近用户的一组特征化混杂区域,当前用户所处环境的位置语义系数j,当前时间a以及设定生成混杂区域的最大面积dmax和区域最小面积dmin;
输出:对象用户本身的特征化混杂区域n;
定义:zx=特征化混杂区域左下角单元格,
ys=特征化混杂区域右上角单元格,
uz=对象用户所在单元格,
maxa=混杂区域密度a中的最大值,
根据对象用户邻近用户的特征化混杂区域,采用当前时间a的位置语义系数j更新整个地图,然后根据定义六与定义七计算位置地图中每个单元格的q(a),
返回区域n。
与现有技术相比,本发明的贡献和创新点在于:
一是本发明提供的背景知识引导的特征化定位隐私防泄露方法,前提条件是用户不会信赖附近的普通用户和第三方服务器,并能根据用户的特征化需求提供不同级别的隐私防泄露服务。在用户相互分享定位信息时,不再分享自己的精准位置,而是采用一个经过精心计算得出的混杂区域替代用户的真实位置,用户的混杂区域生成基于其附近用户的混杂区域计算得到,并且区域内的用户数量是未知的,一个面积较大的混杂区域可提供更好的隐私防泄露效果,但也会导致用户体验下降,所以本发明从隐私防护效果和用户体验二个方面综合考虑权衡,得出的是面积较小的同时包含的用户数量尽量多的混杂区域,使得用户在自己的隐私信息不被泄露的同时,又还能够享受到定位服务应用提供的各种便利和服务,是解决定位服务隐私信息泄露问题综合效果最佳的方法之一,具有巨大是推广应用价值和广阔的市场空间。
二是本发明提供的背景知识引导的特征化定位隐私防泄露方法,针对位置隐私攻击特别是其中语义位置的被动攻击,现有技术都没有良好的抵御方法的问题。提出的特征化混杂区域位置隐私防泄露方法,对不同位置的语义赋予不同的位置系数j,解决语义位置被动攻击问题,在生成混杂区域的迭代过程中,避免覆盖一些几乎没有用户出现的网格,用户在分享混杂区域时倾向于把用户密度高的语义位置融入到自己的混杂区域内,恶意位置窃取者再想要利用位置语义特征去排除一些用户几乎不可能够出现的位置区域就变得非常困难,使得方法的定位隐私防泄露能力大幅提高,通过实验检验了本发明的有效性、实用性、先进性。
三是本发明提供的背景知识引导的特征化定位隐私防泄露方法,针对被动攻击的社会关系攻击需要采集用户的个人社会关系信息,通过采集的信息掌握与用户相关的其余人员的定位信息来推导出用户的精准位置的问题,提出的特征化混杂区域隐私防泄露方法中不需要用户之间分享精准的定位信息,而是分享一个模糊的混杂区域,即使恶意位置窃取者获取了与对象用户有社会关系的其余人员的定位信息,因为都是经过模糊化处理后的不准确信息,对位置窃取者来说也不具有较高价值,所以特征化混杂区域隐私防泄露方法也可以有效抵御社会关系攻击,大幅提高方法的定位隐私防泄露能力。方法局限性小,具有普适性和可移植性,市场推广应用潜力巨大。
四是本发明提供的背景知识引导的特征化定位隐私防泄露方法,结合现实生活中的真实场景,将特征化位置语义、特征化时间、特征化面积融入混杂区域生成过程,避免了具有背景知识的恶意位置窃取者从一个已知的混杂区域中缩小其攻击范围,通过背景知识显著提高预测对象用户真实精准位置的问题。利用特征化因素使得方法生成的混杂区域各处用户分布的概率相当,即各处的位置语义系数大致相等,抵御具有背景知识的恶意位置窃取者的位置语义攻击。方法复杂度低,很容易实现且效果明显定位隐私防泄露质量平稳,具有良好的质量控制能力和服务质量保障机制,使得定位隐私防泄露方法更具鲁棒性和高效性。
附图说明
图1是本发明的混杂区域的生成方法示意图。
图2是本发明混杂区域的生成结果示意图。
图3是本发明的单元格位置语义系数示意图。
图4是本发明的单元格位置语义概率示意图。
图5是本发明特征化时间的节假日白天位置语义系数示意图。
图6是本发明特征化时间的节假日晚上位置语义系数示意图。
图7是本发明特征化时间的工作日白天位置语义系数示意图。
图8是本发明特征化时间的工作日晚上位置语义系数示意图。
具体实施方式
下面结合附图,对本发明提供的背景知识引导的特征化定位隐私防泄露方法的技术系统进行进一步的描述,使本领域的技术人员可以更好的理解本发明并能够予以实施。
本发明提供的背景知识引导的特征化定位隐私防泄露方法,基于对象用户与邻近用户之间相互不信赖的前提,采用分布式点对点定位隐私防泄露体系结构,利用模糊法保护用户定位隐私,根据混杂区域生成的过程提出二种方法,第一种为枚举遍历取优法,遍历所有可能的矩形区域选择出最优解,第二种为贪婪扩张策略法,采用贪婪算法每次扩张混杂区域到当前最优单元格处;根据大量实验数据对比,枚举遍历取优法在用户密度和混杂区域面积大小二个指标上表现比贪婪扩张策略法好,但枚举遍历取优法因为要遍历所有可能出现的情形导致其方法效率较低。
本发明考虑位置语义攻击,并结合现实生活中的真实场景,将特征化位置语义、特征化时间、特征化面积融入混杂区域生成过程,提出特征化混杂区域定位隐私防泄露方法,具有背景知识的恶意位置窃取者很容易从一个已知的混杂区域中缩小其攻击范围,通过背景知识可显著提高预测对象用户真实精准位置的概率。特征化混杂区域生成方法包括特征化位置语义、特征化时间、特征化面积,在不同时间段的同一个位置区域位置语义系数j动态变化,根据这一情形在特征化混杂区域定位隐私防泄露方法中融入时间系数a,同一位置区域在不同的时间段中在混杂区域中出现的概率不相同,利用特征化因素使得方法生成的混杂区域各处用户分布的概率相当,即各处的位置语义系数大致相等,抵御具有背景知识的恶意位置窃取者的位置语义攻击。
一、缺陷分析
从分布式点对点隐私防泄露体系结构的工作流程可看出,若在用户相互分享精准定位信息的用户组中混入了位置窃取者,整个组内的用户隐私安全都会受到威胁,现有技术一些经典的方法如on-demand方法、proactive方法都是在基于用户之间相互信赖的关系下提出的,这些方法中用户可毫无顾忌的分享自己的真实位置给其余用户,并信赖其余用户不会做威胁整个用户组的行为。但这种假设在现实情形下很难实现,一个位置窃取者很容易冒充普通用户,在没有任何隐私防泄露措施的前提下,位置窃取者可轻而易举获得到对象用户的定位信息。
本发明的目的就是解决因为用户之间的相互信赖问题带来的位置隐私泄露威胁,本发明提出一种背景知识引导的混杂区域特征化定位隐私防泄露方法,该方法的前提条件是,用户不会信赖附近的普通用户和第三方服务器,并能根据用户的特征化需求提供不同级别的隐私防泄露服务。背景知识引导的特征化定位隐私防泄露方法是在用户相互分享定位信息时,不再分享自己的精准位置,而是采用一个经过精心计算得出的混杂区域替代用户的真实位置,用户的混杂区域生成基于其附近用户的混杂区域计算得到,并且区域内的用户数量是未知的,一个面积较大的混杂区域可提供更好的隐私防泄露效果,但也会导致用户体验下降,所以本发明中评价混杂区域特征化定位隐私防泄露方法从隐私防泄露效果和用户体验二个方面进行,一个好的混杂区域应该是面积较小的同时包含的用户数量尽量的多。
混杂区域特征化定位隐私防泄露方法中的特征化表现在根据用户对隐私防泄露的需求等级定义不同级别的隐私防护度,通过调节隐私防护度为用户提供不同的隐私防泄露强度,比如,当用户申请附近的餐馆位置时,与掩饰用户的真实位置和查询申请内容相比,用户更希望获得精准的定位服务,在此情形下若生成较大面积的混杂区域肯定会严重影响用户的体验,所以特征化的隐私防泄露方法此时应控制较小的混杂区域面积,以便更好的为用户提供位置服务;但是若当用户申请附近的专科医院时,用户希望能尽量保护自己的病情隐私和定位信息,此时特征化隐私防泄露方法则提供隐私防护程度较强的混杂区域,以防止用户的信息泄露。
二、方法定义
根据混杂区域特征化定位隐私防泄露方法中用户之间相互不信赖,不能够分享用户自己的精准位置,而是采用混杂区域来替代,对隐私防泄露方法中的混杂区域做基本定义。
定义一:混杂区域,用bx表示混杂区域,已知混杂区域是一个矩形,则混杂区域用下面的五元组定义:
bx=(xc,yc,xb,yb,ui)
坐标(xc,yc)和(xb,yb)分别表示矩形区域混杂的左下角和右上角的坐标,ui表示用户唯一的身份标识,不同用户之间的用户ui不同,每个混杂区域具有唯一性。
定义二:混杂区域面积大小,混杂区域的面积w(bx)表示为:
w(bx)=|xc-xb|×|yc-yb|
用户根据自己隐私防护度的需求通过二个自定义的参数限定混杂区域生成的面积范围,即dmax和dmin,确定混杂区域面积大小是在用户隐私防护程度和用户体验上做出权衡,较大dmin的混杂区域包含更多的邻近用户,用户数量的增多可显著提高该区域的隐私防泄露能力,防止隐私信息被恶意位置窃取者获取,较大的dmax会大幅降低用户体验,一个较大的区域会导致较多的查询返回集合,用户必须花更多时间和资源在返回的查询集合中根据自己的真实位置进行筛选,并且传输包含较多查询结果的集合会占用大量的网络带宽,最后生成一个面积较大的混杂区域会占用用户端更多计算资源,产生过大的负载,所以设置合理的dmax值和dmin值对混杂区域的生成很关键。
用户之间的混杂区域可相互覆盖,且用户自己可出现在其混杂区域的任何位置,因此即使一个用户知道其自己的混杂区域和其余用户混杂区域的覆盖情形,该用户也无法判定其余用户是否出现在混杂区域公共部分,同样用户也无法判定自己的混杂区域到底包含多少个其余用户,根据以上定义对混杂区域的生成方法描述:
输入:1-根据用户自己隐私防护需求特征化定义dmax和dmin的限定,
2-用户采集到的其余邻近用户各自的混杂区域;
输出:对象用户的混杂区域;
约束:对象用户混杂区域的面积w(bx)满足dmax和dmin的限定。
三、混杂区域的生成方法
混杂区域生成的用户定位信息设置在网格化地图上,每个用户的真实位置用地图上的一个单元格表示,多个用户可属于同一单元格,这种基于网格化表示用户定位信息的地图定义为位置地图,一个混杂区域可被表示为一个矩形区域,(xc,yc)和(xb,yb)分别表示矩形区域混杂的左下角和右上角的坐标。
生成混杂区域的基本流程为:对象用户融入到分布式点对点体系结构中,该用户的定位设备通过点对点的通信协议搜索四周的邻近用户,并进行混杂区域的位置分享,当对象用户获取到一组邻近用户的混杂区域后,采用对应的混杂区域生成方法生成自己的混杂区域;在四周用户稀疏采集到的混杂区域不满足要求或根本搜索不到四周混杂区域的情形下,用户生成一个面积和位置都随机的混杂区域,采用生成的混杂区域替代自己的真实位置,向定位服务服务器发送查询申请。
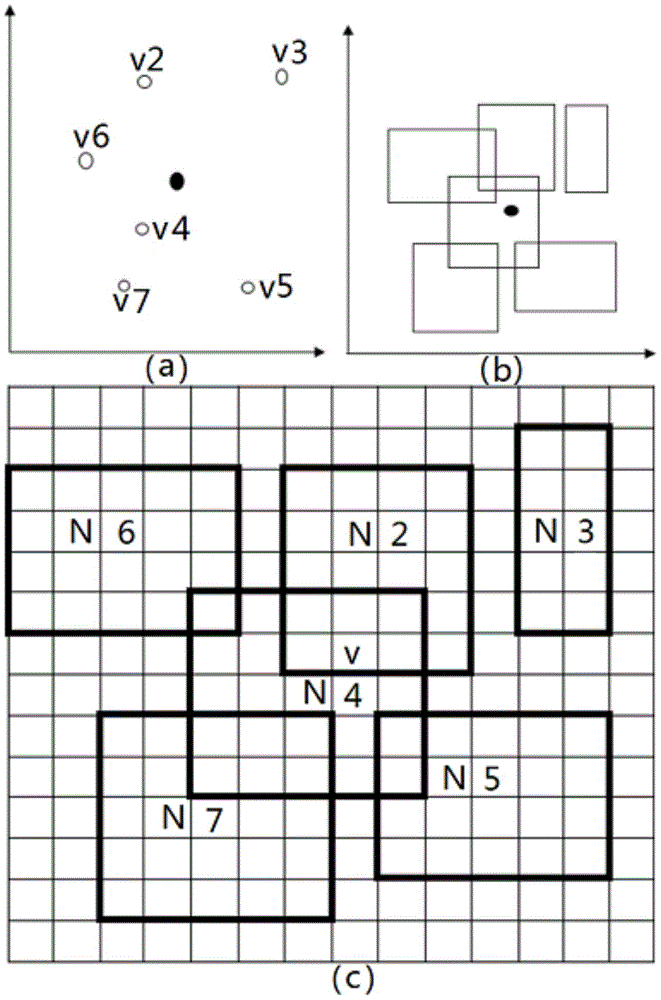
如图1为方法流程的示例,对象用户v1四周有五个邻近用户v2-v7,这些用户之间可通过点对点的通信协议相互分享各自的定位信息,但基于用户之间不信赖的前提,只能够分享自己的混杂区域给对象用户,如图1(b)所示,邻近用户v2-v7分享各自的混杂区域n2-n7给对象用户v1,图中1(c)看出n2-n7是面积大小不同的矩形区域,且相互间还有重叠区域,对象用户v1只能够从n2-n7区域中获取邻近用户的粗略位置,并不能够掌握他们的精准位置,从而有效避免了用户真实位置的泄露;然后对象用户v1准备开始通过邻近用户的混杂区域n2-n7生成自己的混杂区域,产生一个位置地图,该用户位置地图是一个以对象用户精准位置为中心并能覆盖所有邻近用户混杂区域的矩形区域,矩形区域的大小可根据用户需要调整,位置地图面积越小需要调用生成对象用户混杂区域的计算资源越少。
用户出现在该混杂区域中的任何位置的概率是相同的,基于这个前提对用户混杂区域内的单元格进行赋值。比如图中1(c)所示用户v2出现在n2区域中任何位置的概率相同,n2区域为4×5的矩形区域,用户出现在该矩形区域内任何一个单元格的概率为1/w(v2),即为5%,为方便计算将概率扩大100倍赋值给单元格,若一个用户以5%的概率出现在某个单元格时,单元格此时数值需要增加5,若某个单元格被多个混杂区域同时覆盖,则该单元格的值为每个混杂区域在该单元格的值之和;根据单元格的赋值方法,将图1(c)的单元格进行赋值。
对所有单元格赋值后,生成对象用户v1的混杂区域;首要定义混杂区域的用户密度,方法目标是混杂区域面积尽量小,但包含用户的数量尽量多。
定义三:用户密度,用户密度是用户数量和该区域面积的比值,某单元格的数值代表用户出现在该单元格的概率。
(一)枚举遍历取优法
枚举遍历取优法遍历所有包含对象用户单元格的矩形区域,直至找到用户密度为最大值的矩形区域,将该矩形区域作为对象用户的混杂区域。枚举遍历取优法很好的保证生成的矩形区域面积尽量小,用户数量尽量多,但采用枚举遍历取优法遍历的时间复杂度很高,枚举遍历取优法的效率较低。
将枚举遍历取优法应用到本发明的实施例中,具体步骤为:
第一步,对位置地图中的每个单元格分别计算各自的赋值,对于该实施例中15×15的矩形区域设定dmin=16,dmax=64;
第二步,根据枚举遍历取优法分别在位置地图左侧和右侧选取单元格,若选取的左右单元格覆盖的区域不包括对象用户v1的真实位置单元格或者覆盖区域的面积不在dmin和dmax的范围内,舍弃该单元格;
第三步,直至计算出满足要求且用户密度的值最大的矩形区域。
最后对象用户的混杂区域如图2中灰色区域所示。
(二)贪婪扩张策略法
枚举遍历取优法虽然生成矩形面积尽量小,包含用户尽量多的混杂区域,但其计算开销巨大,需要在隐私防护能力与计算开销方面做出折中选择,贪婪扩张策略法是兼顾二者的方法,虽然隐私防护能力不如枚举遍历取优法强,却可以有效降低计算开销,提高位置隐私防泄露方法的效率。
对所有位置地图中单元格赋值后可知,单元格值越高,该单元格出现用户的概率越高,但假如在离用户很远的距离出现一个赋值很高的单元格,无形中生成的混杂区域会往该单元格靠拢,但离对象用户越远的地方,对定位服务器申请服务时质量下降严重,对于每个单元格的赋值,需要考虑其与对象用户所在单元格的距离,有如下定义:
定义四:距离相关单元格值,对某一个单元格,距离相关单元格值为该单元格与对象用户所在单元格覆盖的矩形区域内所有单元格的值与区域内单元格数量的比值。
将贪婪扩张策略法应用到本发明的实施例中,具体步骤为:
与枚举遍历取优法相同,对位置地图中的每个单元格分别计算其各自的赋值得到每个单元格的单元格值,然后根据定义四计算每个单元格的距离相关单元格值,用距离相关单元格值更新整个位置地图得到距离相关位置地图;贪婪扩张策略法在距离相关位置地图的基础上生成混杂区域,选择此时距离相关单元格值最大的单元格,即单元格(8,8),将n区域扩展至该单元格处,如图粗线框所示;然后将粗线框中的单元格对应在位置地图中的单元格值均设为0,并且重新计算该地图单元格的距离相关单元格值,更新整个距离相关位置地图的值;根据新的距离相关位置地图选取当前新地图距离相关单元格值的最大值,即(4,4)被选中,将n区域扩展至该单元格处;重新计算扩展后的地图单元格值和距离相关单元格值,又得到当前距离相关单元格值最大的单元格,但是若将n区域扩展至该单元格处(10,2),n区域面积小于等于dmax=49;不断重复以上过程,直至n区域的面积达到最大值或没有距离相关单元格值大于0的单元格存在,最终生成的混杂区域图。
四、特征化混杂区域生成方法
(一)特征化位置语义
前面提出的混杂区域生成方法并没有与现实生活中的各种场景结合,生成混杂区域的枚举遍历取优法和贪婪扩张策略法都注重几何空间上实现匿名防位置泄露,但缺乏与生活实际的紧密联系,日常生活中的地理位置均为具有一定语义的区域,不同语义的区域之间有不同的背景知识,所以位置窃取者很容易利用这一点获取用户的真实位置,例如当位置窃取者截获到用户的混杂区域包含水面区域和住宅区域时,根据位置窃取者掌握的背景知识轻易分析出水面上不可能有对象用户,则大幅缩小了混杂区域的范围,使得前面提出的方法非常容易被攻破。因此将地理位置的语义信息与混杂区域的生成方法相融合非常必要,可大幅加强抵御位置窃取者利用位置语义背景知识进行恶意攻击的能力。
位置语义是某个位置区域在现实生活中具有的自然和社会属性,在不同的位置语义中分布的用户具有一定代表性,将不同的位置语义特点融入到混杂区域的生成方法中得出基于特征化位置语义的混杂区域生成方法,弥补此前方法的不足,使生成的混杂区域尽量少的包含用户不太可能出现的位置区域,如上学时间段内学生不太可能出现在商业区。
定义基于特征化位置语义方法中的参数:
定义五:位置语义系数j,模拟现实生活的实际场景,对地图中的每个单元格指定一个具体的位置语义,每个用户可为不同的语义位置指定对应的位置语义系数,依据现实生活的场景,不同用户之间对位置的语义感知程度不同,例如对于学生,学校的位置语义系数高于办公楼,因为学生出现在学校的概率普遍大于办公楼,但对于退休老人,出现在公园的概率大于出现在办公楼和学校,公园的语义位置系数高于办公楼和学校。语义位置系数根据不同用户的实际情形调整,满足不同用户特征化位置隐私防泄露的需求。
定义六:用户在某网格中出现的概率q,对于一个混杂区域n,生成该混杂区域的用户出现在n中某一个网格t的概率为:
j(t)表示的是网格t的位置语义系数,若某个混杂区域n中每个网格的位置语义都相同,则所有网格的j(t)相同,代表用户出现在每个网格的概率相等。如图3所示,代表混杂区域中不同单元格的位置语义系数不同。根据定义六计算用户在不同单元格分别出现的概率如图4所示。
某个单元格可能同时被多个用户的混杂区域覆盖,不同混杂区域覆盖同一单元格表明该单元格上用户出现的概率增加,于是定义为:
定义七:用户在某一个单元格出现的概率和q,对于一组混杂区域空间,记为n,即n={n1,n2,n3.....nm},假设n中的所有区域都覆盖单元格t,则用户在单元格t出现的概率为:
q(t)=q1(t)+q2(t)+......qm(t)
面积较大的混杂区域更容易包含较多的匿名用户,但过大的面积也会带来诸如定位应用质量下降和消耗网络带宽过多以及计算资源占用多的问题,选取面积大小合理的混杂区域在位置语义特征化防泄露方法中也很重要,既要考虑包含匿名用户的数量也要考虑混杂区域的面积,融入混杂区域密度衡量一个混杂区域的好坏。
定义八:混杂区域密度a,已知一个混杂区域,记做n,区域n中的单元格记做t,则混杂区域密度由下式计算:
其中|n|表示的是区域n中单元格的数量,即表示n的面积。
特征化位置语义隐私防泄露方法应用到本发明实施例中步骤为:通过分布式点对点通信协议,用户之间分享各自的特征化位置语义混杂区域,对象用户v1接受来自其余5个邻近用户的特征化位置语义混杂区域,利用这些区域和对应的方法生成自己的特征化位置语义混杂区域,收到其余用户特征化位置语义混杂区域信息的基础上,根据定义六和定义七计算每个单元格的用户在该单元格出现的概率和,一个单元格的q(t)值越大说明用户在该单元格出现的概率越高;最后基于这些q(t)值再采用本发明的枚举遍历取优法或贪婪扩张策略法为用户v1计算其特征化混杂区域。
(二)特征化时间
除位置语义背景知识在保护用户位置隐私方面作用很大之外,现实生活场景中,时间因素对加强混杂区域位置隐私防泄露能力也十分关键。比如位置窃取者在凌晨截获用户的混杂区域中包含住宅区和商场,因为凌晨商场会停业,位置窃取者很容易将用户范围缩小在住宅区。用户的位置隐私安全将会受到较大威胁,在设计用户位置隐私防泄露方法时,若能够考虑时间因素,将会大幅加强该方法抵御位置攻击的能力。
定义九:时间因素融合语义位置系数j,将时间因素与定义五中的位置语义系数j相融合,通过(j,a)二元组定义不同位置单元格在当前时间a下的语义位置系数,当时间因素a为周末或节假日的白天时,在住宅、道路、商场位置的语义系数分布如图5所示,在周末或节假日的白天商场区域和道路上出现用户的可能性更大,而白天住宅区域出现用户的可能性相对较小,符合现实生活的实际情形;当时间因素a为周末或节假日的夜晚时,在住宅、道路、商场位置的语义系数分布如图6所示,随着夜晚商场关门,商场区域出现用户的概率大幅下降,用户回到家中休息,住宅区域出现用户的概率随之增加,夜晚道路上行人数量减少,道路的语义位置系数j在夜晚也会有下降;当时间因素a为工作日的白天时,住宅、道路、商场、办公区域位置的语义系数分布如图7所示,工作日白天,办公区出现用户的概率大幅增加,此时办公区语义位置系数较高,白天随着人们外出工作,住宅区域的语义位置系数j会较夜晚下降,工作日白天在商场购物的人流量较周末节假日相比也会降低,所以语义位置系数j的值比周末的低;当时间因素a为工作日的夜晚时,住宅、道路、商场、办公区域位置的语义系数分布如图8所示,夜晚时办公区出现用户的概率比白天降低很多,除夜晚加班人员外基本不会人出现在办公区域,所以当a为工作日夜晚时,办公区域的语义位置系数j下降为0.1,时间因素a融合位置语义系数j的二元组(j,a)反应在某个区域上的a时刻用户存在的概率,该二元组的值根据不同时刻的不同区域人流量计算。
(三)特征化面积
对混杂区域进行面积最大值dmax和面积最小值dmin的设定,定义二中讨论了dmax和dmin对于生成混杂区域的重要性,设置合理的混杂区域的面积大小是在用户位置隐私防护程度和用户体验上做出一个权衡。对dmax和dmin进行设置调整以适应用户不同程度的隐私需求。
设置不同的dmax和dmin的值对生成的混杂区域影响很大,实施例中当dmax=25、dmin=16时生成的混杂区域由坐标单元格(6,6)和(8,12)组成的矩形区域构成,将混杂区域面积最大值由25调整至36后,生成的混杂区域由坐标单元格(6,4)和(9,12)组成的矩形区域构成,生成的混杂区域的面积也由21扩大至36,用户密度从5.58增加至5.86。当用户对用户体验要求较高时可选择dmax=25、dmin=16,生成面积较小的混杂区域以获取精准的位置服务,当用户对位置隐私防护度要求较高时,可选择dmax=36,dmin=16,生成较大的模糊区域面积更好防止泄露自己的精位置。
由特征化位置语义,特征化时间和特征化面积可完整的定义特征化的混杂区域生成方法。
定义十:位置特征化系数f,位置特征化系数由位置语义系数j,时间系数a,以及区域最大面积dmax和区域最小面积dmin定义的四元组f={j,a,dmax,dmin}构成。
特征化混杂区域生成方法如下所示:
输入:其余邻近用户的一组特征化混杂区域,当前用户所处环境的位置语义系数j,当前时间a以及设定生成混杂区域的最大面积dmax和区域最小面积dmin;
输出:对象用户本身的特征化混杂区域n;
定义:zx=特征化混杂区域左下角单元格,
ys=特征化混杂区域右上角单元格,
uz=对象用户所在单元格,
maxa=混杂区域密度a中的最大值,
根据对象用户邻近用户的特征化混杂区域,采用当前时间a的位置语义系数j更新整个地图,然后根据定义六与定义七计算位置地图中每个单元格的q(a),
返回区域n。
五、方法安全性解析
位置隐私攻击分为主动攻击和被动攻击,针对位置隐私攻击特别是其中语义位置的被动攻击,现有技术都没有良好的抵御方法。本发明提出的特征化混杂区域位置隐私防泄露方法对不同位置的语义赋予不同的位置系数j,解决语义位置被动攻击问题,在生成混杂区域的迭代过程中,避免覆盖一些几乎没有用户出现的网格,用户在分享混杂区域时倾向于把用户密度高的语义位置融入到自己的混杂区域内,恶意位置窃取者再想要利用位置语义特征去排除一些用户几乎不可能够出现的位置区域就变得非常困难了。
属于另外一种被动攻击的社会关系攻击需要采集用户的个人社会关系信息,通过采集的信息掌握与用户相关的其余人员的定位信息来推导出用户的精准位置,但本发明提出的特征化混杂区域隐私防泄露方法中不需要用户之间分享精准的定位信息,而是分享一个模糊的混杂区域,即使恶意位置窃取者获取了与对象用户有社会关系的其余人员的定位信息,因为都是经过模糊化处理后的不准确信息,对位置窃取者来说也不具有较高价值,所以特征化混杂区域隐私防泄露方法也可以有效抵御社会关系攻击。
本发明首先对特征化混杂区域隐私防泄露方法的参数进行定义,然后提出了二种混杂区域的生成方法,即枚举遍历取优法与贪婪扩张策略法,然后根据现实生活场景中的实际情形在原有的混杂区域生成方法中又融入不同参数定义特征化混杂区域隐私防泄露方法,详细讨论不同参数对方法的作用,和融入特征化因素后的方法流程,最后讨论特征化混杂区域隐私防泄露方法抵御位置被动攻击的能力。
- 还没有人留言评论。精彩留言会获得点赞!