一种基于深度学习的去除视频水印的方法与流程
本发明涉及图像处理技术,具体是一种基于深度学习的去除视频水印的方法。
背景技术:
随着网络技术的快速发展,各种各样的视频在互联网上的传播。企业为了保护视频中的版权,在视频中叠加水印是一种常规的做法。在很多时候,使用者需要使用没有水印的视频,方便对接自己的业务。通常市面上的水印处理软件是对单张水印图片进行去除,这种做法对于处理视频不仅耗时耗力,而且水印区域也有比较明显的痕迹,效果也不佳。因此如何实现高效处理视频中的水印已经成为业界亟待解决的问题。
技术实现要素:
本发明的目的是针对现有技术的不足,而提供一种基于深度学习的去除视频水印的方法。这种方法利用深度学习对带水印的视频进行去除处理,能够有效提高处理海量视频水印的效率,能快速批量清除视频中水印,去除水印不留踪迹以及去除水印后原画质不丢失帧的优点。
实现本发明目的的技术方案是:
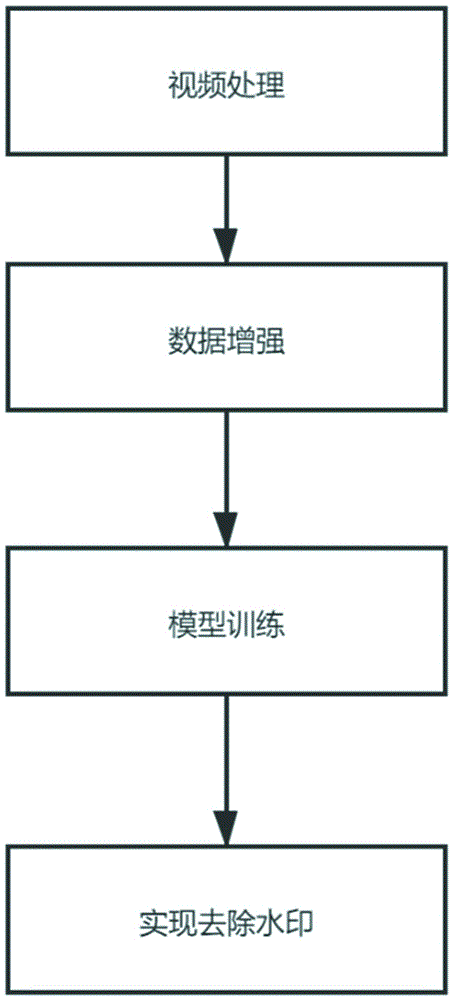
一种基于深度学习的去除视频水印的方法,包括如下步骤:
1)视频处理:采用视频处理opencv工具把视频转换为图片,将处理后的训练图片分为有带水印的图片和不带水印的图片;
2)数据增强:数据增强能提高数据的多样性,增强模拟的鲁棒性,降低模型对参数的敏感度,提升模型的泛化能力,采用mosaic数据增强,能提高去除水印的能力,其过程是:随机添加水印噪声,每次读取4张图片,对带水印的图片和不带水印图片同时做出翻转、缩放、旋转变化相同的变换,并且按照四个方向位置摆好,进行图片的组合和框的组合,合成一张图片,这样丰富检测物体的背景,在一个batch计算时可以计算4张图片的数据,更好地利用了batch,使gpu得到了更好运用,大大减少了对大批量生产的需求,增加背景的复杂度;
3)模型训练:将经过数据增强的图片传入改进后的unet特征提取网络中进行训练,在改进后的unet特征提取网络中,采用注意力机制和强化学习,以及采用l2loss的计算方式,进行图片的训练,unet特征提取网络采用强化学习找到合适的通道数,过程如下:首先设定搜索的unet的通道数为1-30;初始化dqn的记忆库memoryd,设置它的容量为200;初始化q估计网络,随机生成权重ωω;初始化targetq网络,权重为ω-=ωω-=ω;初始化最初状态initialstates1s1;循环遍历step=1,2,…,100,策略生成actionatat,at=maxaq(st,a;ω)at=maxaq(st,a;ω);其中st代表loss的值,a代表行为选择的通道数,执行actionatat,接收rewardrtrt及新的statest+1st+1;rewardrtrt表示接收的奖励,将(st,at,rt,st+1)(st,at,rt,st+1)存入d中;从d中随机抽取一个minibatch的transitions(sj,aj,rj,si+1)(sj,aj,rj,sj+1);令yj=rjyj=rj,如果j+1j+1步是terminal的话,否则,令yj=rj+γmaxa′q(st+1,a′;ω-)yj=rj+γmaxa′q(st+1,a′;ω-);对(yj-q(st,aj;ω))2(yj-q(st,aj;ω))2关于ωω使用梯度下降法进行更新;每隔csteps更新targetq网络,ω-=ωω-=ω,最终找到合适的通道数;
4)实现去除水印:最终保存的训练loss值最低的模型权重,进行模型权重加载,对视频进行去除水印操作,训练好的网络通过改进后的unet提取视频中的水印特征,最大程度达到保留视频中的语义信息,在实施过程中将视频提取出带水印和不带水印的图片作为训练样本,以训练后去除水印后的样本和无水印的样本作为像素级别对比,对比准确度和平均误差mse,在进行多次的训练后,使准确率和平均误差都达到最优,能够得到训练好的预设权重,加载出预设权重,对带水印的视频进行处理。
步骤3)中所述的l2loss的计算方式为:在去除水印视频方法时损失函数计算的时候,采用对于l2损失函数计算,该函数的最优解在被估计真实平均值处取得z,z=ey{y},计算损失值的函数为l(z,y)=(z-y)2,在网络中输入目标对(xi,yi)优化,主要是优化argminθe(x,y){l(fθ(x),y)},其中,网络函数为fθ(x),θ为网络参数,网络会学习到输出所有可能结果的平均值,当给定的训练数据无限多时,目标函数的解与原目标函数的解相同,当训练数据有限多时,估计的均方误差等于目标中的噪声的平均方差除以训练样例的数目,即:
步骤3)中所述的改进后的unet特征提取网络为:u-net特征提取网络特征提取是用于图像分割,分割出图像中所需要物体一个完整准确的轮廓,它全程采用valid来进行卷积下采样,然后提取出一层又一层的特征,利用这一层又一层的特征,再进行上采样,允许更多原图片的纹理信息在高分辨率层进行传播,在上采样部分会融合一部分特征,这样做实际是将多尺度特征融合在了一起,增强了网络的特征提取能力,最后得出一个每个像素点对应其种类的图像。在改进的unet部分,采用强化学习dqn的方法,搜索最优通道参数,减少unet的通道数量,使它的参数原本从1200w减少到了200w,同时采用注意力机制,对一些需要重点特征的区域,投入更多的权重,抑制了图片中与水印无关的其它特征,加强特征提取能力,弥补一些减少参通道数的不足。
所述强化学习dqn方法为:dqn中采用卷积神经网络来逼近行为值函数,一个是采用targetqnetwork来更新target,还有一个是采用经验回放experiencereplay,dqn中经验回放即用一个memory来存储经历过的数据,每次更新参数的时候从memory中抽取一部分数据来用于更新,以此来打破数据间的关联,最终来找到最优路径。
本技术方案带来的有益效果是:
1.可配置强,采用强化学习dqn,学习unet算法参数,使unet的参数总量减少,预测时间变短,无需手动调整参数,使视频中去除水印算法更广的利用与其他特征不同的水印场景;
2.利用修改后注意力机制、数据增强和l2loss计算,使去除水印视频算法,在减少通参数的情况下,更好的去除视频中的水印;
3.灵活方便的扩展与更新,这种方法能提高处理海量视频水印的效率,不仅减少了处理视频水印的速度,减小了gpu和cpu的使用率,能够移植到更小的设备上,而且能够达到更好的去除水印效果。
这种方法能提高处理海量视频水印的效率,能快速批量清除视频水印,去除水印不留踪迹以及去除水印后原画质不丢失帧的优点。
附图说明
图1为实施例的方法流程示意图;
图2为实施例中强化学习方法的流程示意图;
图3为实施例中unet训练预测特征提取流程示意图。
具体实施方案
下面结合附图和实施例对本发明的内容作进一步的阐述,但不是对本发明的限定。
实施例:
参照图1,一种基于深度学习的去除视频水印的方法,包括如下步骤:
1)视频处理:采用视频处理opencv工具把视频转换为图片,将图片分为有带水印的图片和不带水印的图片;
2)数据增强:数据增强能提高数据的多样性,增强模拟的鲁棒性,降低模型对参数的敏感度,提升模型的泛化能力,采用mosaic数据增强,能提高去除水印的能力,其过程:随机添加水印噪声,每次读取4张图片,对带水印的图片和不带水印图片同时做出翻转、缩放、旋转变化相同的变换,并且按照四个方向位置摆好,进行图片的组合和框的组合,合成一张图片,这样丰富检测物体的背景,在batch计算时可以计算4张图片的数据,更好的利用了batch,使gpu得到了更好运用,大大减少了对大批量生产的需求,增加背景的复杂度;
3)模型训练:将经过数据增强的图片传入改进后的unet特征提取网络中进行训练,在改进后的unet特征提取网络中,采用注意力机制和强化学习,采用l2loss的计算方式,进行图片的训练,unet特征提取网络采用强化学习找到合适的通道数,过程如下:首先设定搜索的unet的通道数为1-30;初始化dqn的记忆库memoryd,设置它的容量为200;初始化q估计网络,随机生成权重ωω;初始化targetq网络,权重为ω-=ωω-=ω;初始化最初状态initialstates1s1;循环遍历step=1,2,…,100,策略生成actionatat,at=maxaq(st,a;ω)at=maxaq(st,a;ω);其中st代表loss的值,a代表行为选择的通道数,执行actionatat,接收rewardrtrt及新的statest+1st+1;rewardrtrt表示接收的奖励,将(st,at,rt,st+1)(st,at,rt,st+1)存入d中;从d中随机抽取一个minibatch的transitions(sj,aj,rj,sj+1)(sj,aj,rj,sj+1);令yj=rjyj=rj,如果j+1j+1步是terminal的话,否则,令yj=rj+γmaxa′q(st+1,a′;ω-)yj=rj+γmaxa′q(st+1,a′;ω-);对(yj-q(st,aj;ω))2(yj-q(st,aj;ω))2关于ωω使用梯度下降法进行更新;每隔csteps更新targetq网络,ω-=ωω-=ω,最终找到合适的通道数;
4)实现去除水印:最终保存的训练loss值最低的模型权重,进行模型权重加载对视频进行去除水印操作,训练好的网络通过改进后的unet提取视频中的水印特征,最大程度达到保留视频中的语义信息,在实施过程中将视频提取出带水印和不带水印的图片作为训练样本,以去除水印后的样本和无水印的样本作为像素级别对比,对比准确度和平均误差mse,在进行多次的训练后,使准确率和平均误差都达到最优,能够得到训练好的预设权重,加载出预设权重,对带水印的视频进行处理。
步骤3)中所述的l2loss的计算方式为:在去除水印视频方法时损失函数计算的时候,采用对于l2损失函数计算,该函数的最优解在被估计真实平均值处取得z,,z=ey{y},计算损失值的函数为l(z,y)=(z-y)2,在网络中输入目标对(xi,yi)优化,主要是优化argminθe(x,y){l(fθ(x),y)},其中,网络函数为fθ(x),θ为网络参数,网络会学习到输出所有可能结果的平均值,当给定的训练数据无限多时,目标函数的解与原目标函数的解相同,当训练数据有限多时,估计的均方误差等于目标中的噪声的平均方差除以训练样例的数目,即:
步骤3)中所述的改进后的unet特征提取网络为:如图3所示,u-net特征提取网络特征提取是用于图像分割,分割出图像中所需要物体一个完整准确的轮廓,它全程采用valid来进行卷积下采样,然后提取出一层又一层的特征,利用这一层又一层的特征,再进行上采样,允许更多的原图片的纹理信息在高分辨率层进行传播,在上采样部分会融合一部分特征,这样做实际是将多尺度特征融合在了一起,增强了网络的特征提取能力,最后得出一个每个像素点对应其种类的图像。改进的unet部分,采用强化学习dqn方法,搜索最优通道参数,减少unet的通道数量,使它的参数原本从1200w减少到了200w,同时采用注意力机制,对一些需要重点特征的区域,投入更多的权重,抑制了图像中跟水印无关的特征,加强特征提取能力,弥补一些减少参通道数的不足。
所述强化学习dqn实现步骤为:如图2所示,dqn中采用卷积神经网络来逼近行为值函数,一个是采用targetqnetwork来更新target,还有一个是采用经验回放experiencereplay,dqn中经验回放即用一个memory来存储经历过的数据,每次更新参数的时候从memory中抽取一部分数据来用于更新,以此来打破数据间的关联,最终来找到最优路径。
本例中,在训练图片的时候,对图片大小进行等比例缩放或者利用填充,把图片大小变为512*512,传入unet里面,利用卷积、池化和激活函数操作进行特征提取。构造卷积层计算公式:conv=σ(imgw+b),其中,σ表示激活函数,img表示图像矩阵,w表示学习的权重值,b表示偏置值,激活函数的计算方式主要是
- 还没有人留言评论。精彩留言会获得点赞!