一种基于程序分析的数据资源的管控方法与流程
本发明涉及区块链
技术领域:
,特别是涉及一种基于程序分析的数据资源的管控方法。
背景技术:
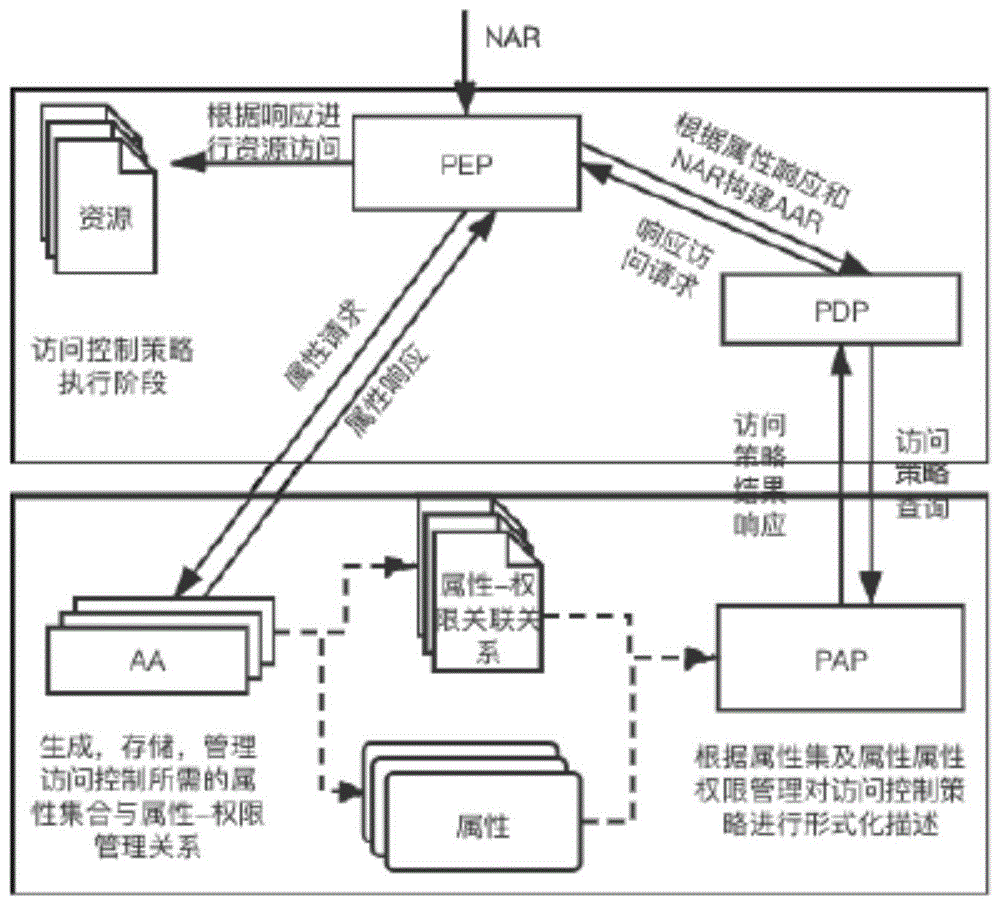
:区块链起源于中本聪的比特币,本质上是通过去中心化和去信任的方式集体维护一个可靠数据库的技术方案。它依靠密码学和数学巧妙的分布式算法,在无法建立信任关系的互联网上、无需任何信任中心的情况下,使得参与者达成共识,完成信任与价值的可靠传递。而运行于区块链上的程序,即智能合约,正是通过一种冗余计算的方式提供了可信计算的服务。典型的提供可信计算的区块链平台都是面向金融场景,包括以太坊、超级账本等。可信计算一般包括四个维度:可用性、可靠性、效率和安全性。这些典型的面向金融场景的区块链着重解决了可用性、可靠性和对数字货币交易的安全性,然而,大数据场景对安全性和效率提出了新的要求。随着云计算、大数据的普及,大多数的企业、单位甚至个人都有着大量的、多维的数据。通过大数据技术去发挥这些数据的价值的时代已经到来。然而,当数据的产生、数据的存储和数据的使用涉及到不同的实体时,数据的接入和使用就面临着信任的问题。例如,当前大量的个人的数据产生于移动应用的使用过程中。这些数据的生产者,是个人和应用提供商,而存储则分布于个人手机和云端服务器。对于一个普通用户而言,他的数据分散在各个不同的应用提供商之间。当有一个特定的大数据应用需要用到同一个用户的多维的、分散的数据时,就会遇到各个参与者之间的可信问题:大数据应用如何向用户和数据提供方证明自己的行为是符合预期,不会泄漏数据或将数据二次转手。要解决大数据场景下的可信计算问题我们必须应对以下挑战:即分布式环境下数据资源的访问控制,在大数据场景下,各种不同的参与者有的提供数据资源、有的提供计算资源,为了保障各类资源的安全与隐私,这就需要对这些资源进行访问控制。而数据资源因其可复制性,一旦到了数据使用者手里就可能失控。因此,如何在分布式、弱信任环境下实现数据资源的访问控制就成为当前的重大难点。技术实现要素:鉴于上述问题,提出了本发明实施例以便提供一种克服上述问题或者至少部分地解决上述问题的一种基于程序分析的数据资源的管控方法。针对上述技术问题,本发明实施例公开了一种基于程序分析的数据资源的管控方法,所述方法包括:预先构建的p2p网络中的第一节点向预设数量个第二节点发起针对智能合约的调用任务,以使所述第二节点执行所述智能合约;所述第一节点为所述p2p网络中的任意节点,所述第二节点为所述p2p网络中事先启动了所述智能合约的节点;所述第二节点根据所述调用任务,构建由多个基本块构成的控制流图;其中,部分基本块中包括获取数据的代码,该基本块通过所述代码获取数据提供者提供的原始数据;所述第二节点将获取的原始数据保存在预先定义的变量中,并以变量为粒度,对所述控制流图进行控制依赖分析和/或数据依赖分析,以构建控制依赖图和/或数据依赖图;所述第二节点依据最新获取的原始数据,对所述控制依赖图和/或所述数据依赖图进行迭代,直至迭代稳定获得变量关系结果;所述第二节点将所述变量关系结果返回给所述第一节点,以使得所述第一节点将所述变量关系结果作为属性输入,执行基于属性的访问控制方法。进一步的,每个获取数据的代码对应一个特定的分支指令,令所述控制流图中分支指令的集合为branches={b1,b2,..bi},bi表示分支指令,i为大于等于1的正整数;所述第二节点将获取的原始数据保存在预先定义的变量中,并以变量为粒度,对所述控制流图进行控制依赖分析,以构建控制依赖图,包括:所述第二节点将获取的原始数据保存在预先定义的变量中,并以变量为粒度,通过数据流方程对branches={b1,b2,..bk}进行控制依赖分析,以构建分支指令内的变量与基本块之间的控制依赖图,所述数据流方程为:outn=inn-killn;killn={bij|j=0,1,…,如果分支指令bi在该基本块};上式中,n是表示序号,outn表示第n个基本块的输出集合,inn表示第n个基本块的输入集合,killn表示在第n个基本块kill掉某些变量相关的沾染情况。进一步的,所述第二节点依据最新获取的原始数据,对所述控制依赖图进行迭代,直至迭代稳定获得变量关系结果,包括:所述第二节点依据最新获取的原始数据,使用广度优化算法对所述控制依赖图进行迭代;在最终迭代之后,判断inn是否不包含{bi1,bi2,..bij}中的所有元素;若所述inn不包含{bi1,bi2,..bij}中的所有元素,则确定所述分支指令bi控制了基本块n,表明所述分支指令bi内的变量与基本块n具有控制依赖关系;所述第二节点将所述变量关系结果返回给所述第一节点,以使得所述第一节点将所述变量关系结果作为属性输入,执行基于属性的访问控制方法,包括:所述第二节点将所述分支指令bi内的变量与基本块n的控制依赖关系返回给所述第一节点,以使得所述第一节点将所述分支指令bi内的变量与基本块n的控制依赖关系作为属性输入,执行基于属性的访问控制方法。进一步的,令所述控制流图中获取数据的代码的集合为orig={arg,executecontrac1,…executecontractk};所述第二节点将获取的原始数据保存在预先定义的变量中,并以变量为粒度,对所述控制流图进行数据依赖分析,以构建数据依赖图,包括:所述第二节点将获取的原始数据保存在预先定义的变量中,并以变量为粒度,通过数据流方程对orig={arg,executecontrac1,…executecontractk}进行数据依赖分析,以构建获取数据的代码对应的变量间的数据依赖图,所述数据流方程为:outn=interpreterexec(inn)上式中,n是表示序号,outn表示第n个基本块的输出集合,inn表示第n个基本块的输入集合;interpreterexec是去符号执行的基本块,以inn作为初始状态,得出计算之后栈桢中的变量与。进一步的,每个获取数据的代码对应一个特定的分支指令,所述第二节点依据最新获取的原始数据,对所述数据依赖图进行迭代,直至迭代稳定获得变量关系结果,包括:所述第二节点将最新获取的原始数据作为污点源添加到所述控制流图起始块的分析结果中,遍历所述控制流图,不断更新分析结果,同时记录所述控制流图中的控制依赖关系,直至迭代稳定获得不同分支指令对应的变量间的数据依赖关系;所述方法还包括:在所述控制流图的遍历中,符号执行包括以下操作:(1)实例化操作,用于符号执行new-instance指令;(2)复制操作,用于符号执行xload/xstore/dup/swap指令;(3)一元操作,用于符号执行仅有1个变量的指令;(4)二元操作,用于符号执行仅有2个变量的指令;(5)三元操作,用于符号执行仅有3个变量的指令;(6)函数调用操作,用于符号执行不定变量的指令。进一步的,在所述第一节点向预设数量个第二节点发起针对智能合约的调用任务前,所述方法还包括:所述p2p网络中的任一节点在接收到数据提供者发送的合约启动请求时,该节点作为主节点启动所述智能合约,并在所述p2p网络中随机选择多个从节点,以使所述从节点启动所述智能合约,其中,所述智能合约存储于预先设置的可信分布式账本中;所述主节点和所述从节点在启动所述智能合约后,生成一组公私钥;其中,所述从节点将所述公私钥中的公钥返回给所述主节点,将所述公私钥中的私钥存储在本地;所述主节点将所有从节点返回的公钥与所述智能合约的元信息存证到所述可信分布式账本中,并将所述可信分布式账本返回的哈希值作为合约校验地址返回给所述数据提供者;预先构建的p2p网络中的第一节点向第二节点发起针对智能合约的调用任务,包括:所述第一节点在接收到数据使用者发送的针对所述智能合约的执行请求时,向所述p2p网络中所有的所述第二节点发起针对所述智能合约的调用任务,所述第二节点为所述主节点或所述从节点;所述方法还包括:所述第二节点针对该调用任务执行所述智能合约的执行请求,并根据所述智能合约的状态向所述第一节点返回相应的执行结果,所述执行结果包括所述p2p网络中所有的所述第二节点基于自身私钥的签名;所述第一节点依据预先设置的结果统计策略,将所述执行结果返回给所述数据使用者;所述数据使用者以所述数据提供者提供的合约校验地址来获取所述公钥,并根据所述公钥对所述执行结果中的签名进行验证。进一步的,所述第二节点针对该调用任务执行所述智能合约的执行请求,并根据所述智能合约的状态向所述第一节点返回相应的执行结果,所述执行结果包括所述p2p网络中所有的所述第二节点基于自身私钥的签名,包括:当所述智能合约无计算状态时,所述第二节点在执行所述执行请求时,直接执行所述智能合约的逻辑,向所述第一节点返回相应的执行结果;当所述智能合约有计算状态时,所述第二节点在执行所述执行请求时,保持相互之间的合约状态的同步、合约执行顺序的同步、合约输入数据的同步以及合约输出数据的同步,向所述第一节点返回相应的执行结果。进一步的,针对所述合约状态的同步,所述方法还包括:每个第二节点执行所述智能合约的过程中,对所述智能合约的执行进行记录;当任一第二节点故障或不能同步执行所述智能合约时,所选取的新的第二节点或不能同步执行所述智能合约的第二节点确定所述预设数量个第二节点中当前处于最新状态的目标节点,并获取所述目标节点对所述智能合约的执行记录;其中,所述新的第二节点为除所述预设数量个第二节点外,在所述p2p网络中随机选择的一个节点;所述新的第二节点或不能同步执行所述智能合约的第二节点将所述目标节点对所述智能合约的执行记录在本地进行回放。进一步的,针对所述合约执行顺序的同步,所述方法还包括:所述第一节点针对所接收到的执行请求,采用实用拜占庭容错pbft算法对所述执行请求进行定序,以保证所述p2p网络中所有的所述第二节点采用同样的顺序依次执行所有的执行请求;其中,在所述pbft算法中,每个执行请求会经历如下的阶段:请求request:所述数据使用者向所述第一节点发送执行请求;预先准备pre-prepare:所述第一节点为所述执行请求分配序列号,并向所有的所述第二节点广播pre-prepare请求;已准备prepare:所述第二节点接收pre-prepare请求后,验证pre-prepare请求的正确性,若验证无误则广播prepare消息,并将pre-prepare请求和prepare消息记录到本地日志中;存储commit:若所述第二节点接收到多于2f+1个与自己一致且有效的prepare消息,则确定定序成功,在本地依次执行已定序的所述智能合约的执行请求,并将执行结果通过自身私钥签名后发送给所述第一节点;答复reply:所述第二节点在接收到2f+1个一致且有效的commit消息后,在本地执行所述执行请求,并将reply消息通过所述第一节点发送给所述数据使用者;所述数据使用者用于在接收到f+1个不同节点一致且有效的reply消息时,对所述第一节点返回的执行结果进行确认。进一步的,所述结果统计策略为all、most或first,所述第一节点依据预先设置的结果统计策略,将所述执行结果返回给所述数据使用者,包括:all,等待所述p2p网络中所有的所述第二节点的执行结果均返回后,所述第一节点将所述执行结果返回给所述数据使用者,并附上所述p2p网络中所有的所述第二节点的公钥缩写;most,当所述第一节点接收到所述p2p网络中大于半数的所述第二节点的执行结果后,将所述执行结果返回给所述数据使用者,并附上已返回执行结果的节点的公钥缩写;first,当所述第一节点接收到所述p2p网络中第一个所述第二节点返回的执行结果后,将所述执行结果返回给所述数据使用者,并附上该节点的公钥缩写。本发明实施例包括以下优点:在本发明实施例中,p2p网络中的第一节点向第二节点发起针对智能合约的调用任务,以使所述第二节点执行所述智能合约,第二节点根据调用任务,构建由多个基本块构成的控制流图;其中,部分基本块中包括获取数据的代码,该基本块通过所述代码获取数据提供者提供的原始数据;所述第二节点将获取的原始数据保存在预先定义的变量中,并以变量为粒度,对所述控制流图进行控制依赖分析和/或数据依赖分析,以构建控制依赖图和/或数据依赖图,再依据最新获取的原始数据,对所述控制依赖图和/或所述数据依赖图进行迭代,直至迭代稳定获得变量关系结果,以此代替了典型属性(如主体与主体属性、客体与客体属性、环境属性)的复杂属性关系,能够在数据分析智能合约的代码量大、结构复杂时,以一种简单、直观的方式展示输入数据与返回结果关系;第二节点将所述变量关系结果返回给所述第一节点后,所述第一节点将所述变量关系结果作为属性输入,执行基于属性的访问控制方法,降低了人工代码审计的成本与难度,最终实现了在分布式、弱信任环境下实现数据资源的访问控制。本发明实施例将数据生命周期中的各项活动抽象为智能合约的开发、部署(启动)、执行,并对智能合约执行结果进行校验,实现了大数据场景下的可信计算;在此过程中,本发明实施例采用了独特的随机多点执行的模式提升了可信计算过程的吞吐量和执行效率,从而能够更好地支持大数据场景的高并发,高吞吐的数据需求;本发明实施例针对合约状态的同步,通过在多节点同步调用的过程中对合约的执行进行记录,当需要同步时,就从最新状态的节点中获取所需的合约调用的执行记录并在本地进行回放,保障了副本数量,以此可在随机多节点状态不同步时将其快速恢复,实现高可用,以满足低响应时间的数据分析场景。附图说明图1是基于属性的访问控制方法的关系模型图;图2是本发明实施例一种基于程序分析的数据资源的管控方法的步骤流程图;图3是本发明实施例随机多点的智能合约执行示意图;图4是pbft算法的示意图;图5是本发明实施例的依赖运算表;图6是本发明实施例的污点分析算法流程图。具体实施方式为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图和具体实施方式对本发明作进一步详细的说明。为便于本领域技术人员理解本发明的发明点,在阐述具体本发明实施例前,先对相关现有技术进行介绍:访问控制可分为身份认证(authentication)、授权(authorization)和验证(verification)这三个部分(sandhu,1994)。身份认证是实现系统保护的基础,基于身份认证,系统可以识别用户的合法性;而授权是系统管理员对已认证用户授予对特定资源的访问的权限;而验证则是对于合法用户再次验证其是否可以对特定资源进行访问。一般地,访问控制由三个主要元素组成:主体、客体和策略:主体(subject)是访问本系统的实体,一般是用户,也可以是其他系统或者子系统;客体(object)是被访问的实体,也是系统需保护的资源。如文件、数据库表、cpu资源等等;策略(访问控制策略,或称为权限permission)是操作行为规则的集合,代表某种授权行为,即允许主体用户以何种策略访问客体资源;访问控制的实现即实现上述的身份认证、授权和验证,具体而言就是1)阻止非法用户访问系统;2)允许授权的用户登录系统,并对系统中受保护的资源进行合法的访问;3)阻止合法用户登录系统后对系统中未授权的资源进行非法的访问,非法访问即为用户对受保护的资源没有相应的访问权限。基于属性的访问控制(attributebasedaccesscontrol,abac)则是对主体、客体进行进一步特征提取,提取出主体属性、客体属性。除此之外,还考虑了操作相关联的属性以及环境属性(huvc,2013)。通过不同属性的组合,可以实现细粒度访问控制,在复杂的分布式系统中有着良好的应用。典型的属性包括:主体与主体属性(subject):主体是对资源进行访问的实体,一个用户、子系统模块等都可以是主体,属于主体的属性可以是姓名、设备id等。客体与客体属性(object):客体也被称作资源,系统中的一条数据、一条记录都属于客体,数据的大小、创建时间等等都属于客体属性。环境属性(environment):即访问控制过程发生时的环境信息,环境是独立于主体与客体的动态因素,例如访问时的时间、系统所处的地点、是否有对同一信息的并发访问等信息。如图1所示,基于属性的访问控制(attributebasedaccesscontrol,abac)的过程可分为策略管理阶段和策略执行阶段。策略管理阶段主要负责收集构建访问控制系统所需的属性集合以及对访问控制策略进行描述、匹配,而策略执行阶段主要负责对访问请求进行响应。在策略管理阶段中,属性权威(attributeauthority,aa)首先预先收集、存储和管理构建安全的访问控制所需的所有属性以及属性-权限之间的对应关系。在策略执行阶段中,当接收到原始访问请求(nar)之后,策略实施点(policyenforcementpointpep)向aa请求主体属性、客体属性以及相关的环境属性,并根据所返回的属性结果集构建基于属性的访问请求(aar)并将aar传递给策略决策点(policydecisionpointpdp)。pdp根据aa所提供的主体属性、客体属性以及相关的环境属性,对用户的身份信息进行判定。通过与pap进行交互,根据pap提供的策略查询结果对pep转发来的访问请求进行判定,决定是否对访问请求授权,并将判定结果传给pep。最终由pep执行判定结果。因此为了构建安全的abac,首先需要从海量的类型各异的访问主体和访问客体挖掘出独立、完备的主体属性、客体属性、权限属性和环境属性集合,并构建这些属性同相关实体之间的关联关系。当获得属性集合后,对属性与权限之间的对应关系进行分析。传统的访问控制机制大多通过专家分析企业的业务流程,抽象并完成属性-权限的分配关系,但是由于属性的收集依赖专家对环境的了解,人工依赖性较强。且面对开放性极强的新型计算环境,特别是当数据分析智能合约的代码量大、结构复杂时,这种典型的属性表示关系过于复杂,需要收集的数据量过大,使得人工代码审计的难度更大,对审计人员的专业水平要求更高。此外,abac在定义权限时,不能直观看出属性的关系规则。一旦权限复杂,或者设计混乱,就会给管理者维护和追查带来麻烦。基于此,本发明实施例所提供的基于程序分析的数据资源的管控方法通过静态分析提取智能合约的数据使用属性,以此来替代典型的属性关系,能够在数据分析智能合约的代码量大、结构复杂时,以一种简单、直观的方式展示输入数据与返回结果关系,然后再基于属性的访问控制来实现降低人工代码审计的成本和难度。由于数据资源是可复制的,本发明实施例对数据的保护的主要思想在于在分布式的网络中运行数据的分析逻辑,只将结果返回给数据使用者的方式,来保护数据。因此,返回结果与输入数据的关系就成为本文需要分析的关键,也是数据资源访问控制的重点。参照图2,示出了本发明实施例一种基于程序分析的数据资源的管控方法的步骤流程图,该方法可以包括以下步骤:(1)以智能合约的方式使用数据:步骤s201,预先构建的p2p网络中的第一节点向预设数量个第二节点发起针对智能合约的调用任务,以使所述第二节点执行所述智能合约;所述第一节点为所述p2p网络中的任意节点,所述第二节点为所述p2p网络中事先启动了所述智能合约的节点;步骤s202,所述第二节点根据所述调用任务,构建由多个基本块构成的控制流图;其中,部分基本块中包括获取数据的代码,该基本块通过所述代码获取数据提供者提供的原始数据;(2)对数据的使用以程序的方式进行:步骤s203,所述第二节点将获取的原始数据保存在预先定义的变量中,并以变量为粒度,对所述控制流图进行控制依赖分析和/或数据依赖分析,以构建控制依赖图和/或数据依赖图;(3)对数据的使用逻辑以程序分析的方式进行分析:步骤s204,所述第二节点依据最新获取的原始数据,对所述控制依赖图和/或所述数据依赖图进行迭代,直至迭代稳定获得变量关系结果;(4)对数据的使用的访问控制以程序分析的结果作为输入:步骤s205,所述第二节点将所述变量关系结果返回给所述第一节点,以使得所述第一节点将所述变量关系结果作为属性输入,执行基于属性的访问控制方法。本发明实施例面向大数据场景,建立了一套理论和可信计算框架,假设框架系统由多个参与者共同组成一个可信计算网络,包括:数据提供者、节点提供者和数据使用者三种角色,数据使用者通过共同组成的网络来使用数据提供者的数据。可信计算框架可以帮助数据提供者和数据使用者在无需互相信任的情况下完成数据接入、数据使用的可信管控。向上对数据提供者、节点提供者提供智能合约的开发、启动、调用等服务,向下管理数据提供者的数据资源。各个参与者(包括数据提供者、节点提供者、数据使用者)通过p2p网络连接,形成一个网络,网络中的每个节点都对应于一台普通的个人电脑或是虚拟机。数据接入智能合约和数据分析智能合约就运行于这个网络中的节点之上。由于本发明实施例是针对数据使用者对智能合约调用,由跑在第二节点上代码来使用原始数据的。为便于理解本发明实施例,在所述第一节点向所述第二节点发起针对智能合约的调用任务前,本发明实施例先对智能合约的开发、启动、调用过程进行说明,该过程包括以下几个部分:智能合约的开发:在开发阶段,用户在用户端通过操作智能合约执行器以及合约编辑器即可便捷地在线编辑合约,实现对智能合约的开发。智能合约的启动,该启动过程包括以下几个步骤:步骤a1:所述p2p网络中的任一节点在接收到数据提供者发送的合约启动请求时,该节点作为主节点启动所述智能合约,并在所述p2p网络中随机选择多个从节点,以使所述从节点启动所述智能合约,其中,所述智能合约存储于预先设置的可信分布式账本中;步骤a2:所述主节点和所述从节点在启动所述智能合约后,生成一组公私钥;其中,所述从节点将所述公私钥中的公钥返回给所述主节点,将所述公私钥中的私钥存储在本地;步骤a3:所述主节点将所有从节点返回的公钥与所述智能合约的元信息存证到所述可信分布式账本中,并将所述可信分布式账本返回的哈希值作为合约校验地址返回给所述数据提供者。其中,合约启动请求的获得方式如下:数据提供者在开发完所述智能合约时,将所述智能合约保存至所述可信分布式账本上,并将所述可信分布式账本返回的哈希值作为所述合约代码地址;所述数据提供者针对所述合约代码地址,生成所述合约启动请求,并采用自身私钥对所述合约启动请求进行签名。主节点为数据提供者在p2p网络中随机选择的任意节点,主节点在接收到合约启动请求后,可采用oraclejavatmplatform,standardedition8的java.security.securerandom类进行网络节点的随机选取。该算法采用密码学安全伪随机数生成器(cryptographicallysecurepseudo-randomnumbergenerator,通称csprng)。该随机数生成器相较于java.lang.math.random()采用的线性同余公式,具有额外的伪随机属性,能够保证所选取节点的随机性,具有较高的安全性。选取了多个网络节点,得到了节点列表后,主节点会将合约启动消息分发给节点列表中的所有节点,即本发明实施例所指的从节点。从节点再依据合约启动请求,启动所述智能合约,以此完成了智能合约的部署过程在本发明实施例中,为了便于智能合约的调用,通过数字对象体系等标识与解析技术可以对合约地址进行分布式的标识和解析。其中合约的调用地址就是一个标识,而该标识保存了合约校验地址等信息。这个标识解析系统可视为账本数据的一个高速缓存,可提升合约寻址的效率。智能合约的执行:预先构建的p2p网络中的第一节点向第二节点发起针对智能合约的调用任务,包括:步骤b1:所述第一节点在接收到数据使用者发送的针对所述智能合约的执行请求时,向所述p2p网络中所有的所述第二节点发起针对所述智能合约的调用任务,所述第二节点为所述主节点或所述从节点;步骤b2:所述第二节点针对该调用任务执行所述智能合约的执行请求,并根据所述智能合约的状态向所述第一节点返回相应的执行结果,所述执行结果包括所述p2p网络中所有的所述第二节点基于自身私钥的签名;在本发明实施例中,随机多点的智能合约启动后,p2p网络中的任意节点均可作为请求节点(第一节点)接收数据使用者的执行请求,发起多点(第二节点)的智能合约调用,并校验结果,将结果返回给数据使用者。参照图3,示出了随机多点的智能合约执行示意图,通过这种方式,可在实现智能合约高并发和高可用性的基础上提升智能合约的执行效率,从而能够更好地支持大数据场景的高并发,高吞吐的数据需求。对于随机多点的智能合约,其执行流程根据智能合约有无计算状态而有所不同。实际执行时,步骤b2可以包括以下执行方式:当所述智能合约无计算状态时,所述第二节点在执行所述执行请求时,直接执行所述智能合约的逻辑,向所述第一节点返回相应的执行结果;当所述智能合约有计算状态时,所述第二节点在执行所述执行请求时,保持相互之间的合约状态的同步、合约执行顺序的同步、合约输入数据的同步以及合约输出数据的同步,向所述第一节点返回相应的执行结果。其中,所谓有计算状态是指该智能合约的执行结果不仅与该次执行的输入参数有关,还可能与执行时间、此前执行、外部数据等有关,也就是说该合约可能含有全局变量、动态的外部数据等状态数据。反之,所谓无状态是指该智能合约的执行结果仅与该次执行的输入参数有关,与执行时间、此前执行、外部数据等无关,也就是说,该合约不含有全局变量、动态的外部数据等状态数据。因此,在不同状态下执行会获得不同的结果。其中,保持合约状态的同步是指所有的第二节点在执行同一个智能合约时,需要保证该智能合约状态的同步。考虑到网络分区、节点宕机等因素是影响多节点状态同步执行的一大难题,针对所述合约状态的同步,本发明实施例提供了以下同步方法:每个第二节点执行所述智能合约的过程中,对所述智能合约的执行进行记录;当任一第二节点故障或不能同步执行所述智能合约时,所选取的新的第二节点或不能同步执行所述智能合约的第二节点确定所述预设数量个第二节点中当前处于最新状态的目标节点,并获取所述目标节点对所述智能合约的执行记录;其中,所述新的第二节点为除所述预设数量个第二节点外,在所述p2p网络中随机选择的一个节点;所述新的第二节点或不能同步执行所述智能合约的第二节点将所述目标节点对所述智能合约的执行记录在本地进行回放。在本发明实施例中,合约状态的同步是通过“记录-回放”实现的。“记录-回放”算法的主要流程是在每次合约执行的过程中对合约的执行进行记录。当需要同步时,就从最新状态的第二节点中获取所需的合约执行的执行记录并在本地进行回放。实际执行时,每个第二节点可能执行的智能合约为多个,即每个第二节点中存储有执行记录列表,所述执行记录列表中记录有多个智能合约的执行记录。上述故障的节点是指该节点无法再执行针对任何智能合约的执行,即无法执行智能合约,该节点已经不可用,此时就需要在p2p网络中重新选择一个节点来替代该节点,即本发明实施例所指的新的节点。不能同步执行所述智能合约的节点指可能突然出现短暂宕机,但是还能继续执行智能合约的节点。智能合约可以为io密集型合约、cpu密集型合约、内存密集型合约等不同类型的合约,不同的节点的执行记录列表所记录的智能合约的执行记录可能部分不同,新的节点或不能同步执行所述智能合约的节点以自身需要同步智能合约为目标智能合约,然后在目标节点的执行记录列表中查找所述目标节点对目标智能合约的执行记录,并提取相应的执行记录。其中,针对所述合约执行顺序的同步,第一节点针对所接收到的执行请求,采用实用拜占庭容错pbft算法对所述执行请求进行定序,以保证所述p2p网络中所有的所述第二节点采用同样的顺序依次执行所有的执行请求。pbft是一种状态机副本复制算法,所有的副本在一个视图(view)轮换的过程中操作,主节点通过视图编号以及节点数集合来确定:p=vmod|r|;其中v为视图编号,|r|为节点个数,p为主节点编号。在一个视图内,pbft算法的流程如图4所示。在pbft算法中,每个执行请求会经历如下的阶段:request:所述数据使用者向所述第一节点发送执行请求;pre-prepare:所述第一节点为所述执行请求分配序列号,并向所有的所述第二节点广播pre-prepare请求;prepare:所述第二节点接收pre-prepare请求后,验证pre-prepare请求的正确性,若验证无误则广播prepare消息,并将pre-prepare请求和prepare消息记录到本地日志中;commit:若所述第二节点接收到多于2f+1个与自己一致且有效的prepare消息,则确定定序成功,在本地依次执行已定序的所述智能合约的执行请求,并将执行结果通过自身私钥签名后发送给所述第一节点;reply:所述第二节点在接收到2f+1个一致且有效的commit消息后,在本地执行所述执行请求,并将reply消息通过所述第一节点发送给所述数据使用者;所述数据使用者用于在接收到f+1个不同节点一致且有效的reply消息时,对所述第一节点返回的执行结果进行确认。其中,针对合约输入数据的同步以及合约输出数据的同步,由于是通过其他智能合约去产生输出与输入,因此,这些冗余的调用会在相应的智能合约中去重,只产生一次真正的外部输入、输出,并将结果返回,从而保证所有随机节点(第二节点)使用相同的数据,也避免了数据冗余读写的问题。智能合约执行结果的校验:步骤c1:所述第一节点依据预先设置的结果统计策略,将所述执行结果返回给所述数据使用者;步骤c2:所述数据使用者以所述数据提供者提供的合约校验地址来获取所述公钥,并根据所述公钥对所述执行结果中的签名进行验证。为了满足大数据时代高并发,高吞吐的数据需求,本发明实施例的可信合约引擎在保持较高的安全性和可靠性的前提下,采用了随机多点的智能合约执行模式来提高执行效率,所选取的节点数可由用户根据需求进行配置。为进一步满足对于正确性和执行效率这两个互斥因素的权衡,本随机多点的智能合约执行模式还采用了可配置的执行结果统计策略,来满足不同类型合约及不同需求数据使用者的特定要求。本发明实施例所提及的结果统计策略可分为all、most或first,在相应的结果统计策略下,步骤c1的执行方式不同,具体如下:all,等待所述p2p网络中所有的所述第二节点的执行结果均返回后,所述第一节点将所述执行结果返回给所述数据使用者,并附上所述p2p网络中所有的所述第二节点的公钥缩写;most,当所述第一节点接收到所述p2p网络中大于半数的所述第二节点的执行结果后,将所述执行结果返回给所述数据使用者,并附上已返回执行结果的节点的公钥缩写;first,当所述第一节点接收到所述p2p网络中第一个所述第二节点返回的执行结果后,将所述执行结果返回给所述数据使用者,并附上该节点的公钥缩写。本发明实施例的数据使用者在接收到执行结果后,可通过公钥缩写从所述合约校验地址获取相应的公钥,由于公私钥中的私钥仅该节点拥有,用于数据签名;而公钥所有节点都拥有,用于校验数据的可信性。因此,节点不能伪装其它节点发送消息从而干扰结果的统计,以此在保障执行效率的同时,能实现相对不互信环境下的执行结果的可验证。基于上述智能合约的开发、启动、执行以及校验过程,接下来,对步骤s201~步骤s205进行详细说明。步骤s101中的名词的解释参照上述,在此不多叙述。在数据资源访问控制中,是以智能合约的方法为粒度来进行基于属性的访问控制的。智能合约的每一个方法的属性表示的是它的返回结果与它的输入数据的关联,体现为最终迭代获得的变量间的依赖关系。从单条语句来看,变量与变量之间的关系有两种,访问控制一是数据依赖,即两个变量之间存在赋值、运算后赋值等关系;一是控制依赖,即某一变量的赋值取决于另一变量控制的某条分支语句。本发明实施例按指令的类型将依赖类型分为五种,如表1所示。表1:依赖类型定义由于在智能合约执行过程中,会有多个变量参与运算,变量与变量之间存在多次的运算,因此,本发明实施例在静态分析过程中,为了简化分析结果,且降低其迭代次数,定义了这些依赖类型的运算关系,参照图5,示出了本发明实施例的依赖运算表。例如,对于变量a属于原始数据,变量b=a+1,变量c=b+1。那么,b与a的关系为b与变量c的关系因此,变量c与变量a的关系为根据依赖运算表,在这个例子中,可以看出c=a+2,实际上与a算法运算关系。从图5的依赖运算表中可看出,基于静态分析的属性自动化提取可转化为一个污点分析算法。本发明实施例的污点分析算法流程如图6所示。在本发明实施例中,控制依赖分析旨在计算某个参与分支指令的变量是否“控制”了某一基本块。对于任意一个分支语句所在的基本块b1,以及其直接后继块b2,b3,..bi,对于基本块bj,若b1的所有后续块都可达bj,则bj与b1的分支语句无控制依赖。具体实现时,每个获取数据的代码对应一个特定的分支指令,令所述控制流图中分支指令的集合为branches={b1,b2,..bi},bi表示分支指令,i为大于等于1的正整数;在步骤s203中,所述第二节点将获取的原始数据保存在预先定义的变量中,并以变量为粒度,对所述控制流图进行控制依赖分析,以构建控制依赖图,包括:所述第二节点将获取的原始数据保存在预先定义的变量中,并以变量为粒度,通过数据流方程对branches={b1,b2,..bk}进行控制依赖分析,以构建分支指令内的变量与基本块之间的控制依赖图,所述数据流方程为:outn=inn-killn;killn={bij|j=0,1,…,如果分支指令bi在该基本块};上式中,n是表示序号,outn表示第n个基本块的输出集合,inn表示第n个基本块的输入集合,killn表示在第n个基本块kill掉某些变量相关的沾染情况。在步骤s204中,所述第二节点依据最新获取的原始数据,对所述控制依赖图进行迭代,直至迭代稳定获得变量关系结果,包括:所述第二节点依据最新获取的原始数据,使用广度优化算法对所述控制依赖图进行迭代;在最终迭代之后,判断inn是否不包含{bi1,bi2,..bij}中的所有元素;若所述inn不包含{bi1,bi2,..bij}中的所有元素,则确定所述分支指令bi控制了基本块n,表明所述分支指令bi内的变量与基本块n具有控制依赖关系;在步骤s205中,所述第二节点将所述变量关系结果返回给所述第一节点,以使得所述第一节点将所述变量关系结果作为属性输入,执行基于属性的访问控制方法,包括:所述第二节点将所述分支指令bi内的变量与基本块n的控制依赖关系返回给所述第一节点,以使得所述第一节点将所述分支指令bi内的变量与基本块n的控制依赖关系作为属性输入,执行基于属性的访问控制方法。在本发明实施例中,数据依赖分析旨在分析出变量与原始数据集合内的原始数据之间关系。令所述原始数据集合为orig={arg,executecontrac1,…executecontractk};关系集该分析也是一个正向的、基于并集操作的数据流分析算法,在具体实现过程中,主要工作是围绕不同的指令生成不同的变量之间的关系。令所述控制流图中获取数据的代码的集合为orig={arg,executecontrac1,…executecontractk};在步骤s203中,所述第二节点将获取的原始数据保存在预先定义的变量中,并以变量为粒度,对所述控制流图进行数据依赖分析,以构建数据依赖图,包括:所述第二节点将获取的原始数据保存在预先定义的变量中,并以变量为粒度,通过数据流方程对orig={arg,executecontrac1,…executecontractk}进行数据依赖分析,以构建获取数据的代码对应的变量间的数据依赖图,所述数据流方程为:outn=interpreterexec(inn)上式中,n是表示序号,outn表示第n个基本块的输出集合,inn表示第n个基本块的输入集合;interpreterexec是去符号执行的基本块,以inn作为初始状态,得出计算之后栈桢中的变量与。在具体实现中,inn一共拥有最多stackmax/localmax个变量槽(slot),每个变量槽符号执行通过taintinterpreter实现。在所述控制流图的遍历中,符号执行包括以下操作:(1)实例化操作,用于符号执行new-instance指令;(2)复制操作,用于符号执行xload/xstore/dup/swap指令;(3)一元操作,用于符号执行仅有1个变量的指令;如xneg/i2l/ifnull等。(4)二元操作,用于符号执行仅有2个变量的指令;如iaload/faload等数据加载指令。(5)三元操作,用于符号执行仅有3个变量的指令;如iastore等数组保存操作。(6)函数调用操作,用于符号执行不定变量的指令,主要包括invoke-dynamic等。对于inn集合,本发明实施例将其实现为taintresult类,其中,inn的操作主要包括进符号执行的merge方法、实现基本块分析结果的合并的mergeresult方法、判断分析结果是否应该继续迭代的covers方法、分析结果的复制clone方法。而taintresult的成员变量如表2所示。表2:taintresult类的成员变量及其含义(inn)变量名变量类型含义frameframe<taintvalue>栈帧rettaintvalue被污点源标记后的分析结果nlocalsint局部变量表的大小nstackint栈的大小printerinsnprinter字节码指令访问器interpretertaintinterpreter字节码指令解释器在步骤s204中,每个获取数据的代码对应一个特定的分支指令,所述第二节点依据最新获取的原始数据,对所述数据依赖图进行迭代,直至迭代稳定获得变量关系结果,包括:所述第二节点将最新获取的原始数据作为污点源添加到所述控制流图起始块的分析结果中,遍历所述控制流图,不断更新分析结果,同时记录所述控制流图中的控制依赖关系,直至迭代稳定获得不同分支指令对应的变量间的数据依赖关系;在步骤s105中,所述第二节点将所述变量关系结果返回给所述第一节点,以使得所述第一节点将所述变量关系结果作为属性输入,执行基于属性的访问控制方法,包括:所述第二节点将所述不同分支指令对应的变量间的数据依赖关系返回给所述第一节点,以使得所述第一节点将所述不同分支指令对应的变量间的数据依赖关系作为属性输入,执行基于属性的访问控制方法。针对上述依赖关系,本发明实施例采用一例子进行说明。数据使用者通过第一节点在发起调用任务时,提交一段代码如下:获取数据的语句就是executecontract("xxdatasource"....;if(a.sex=="male")是个分支指令;分支指令里的变量是“a.sex=="male"”,这句与a(原始数据)的关系是个算术运算的关系;而total.male++与这个“a.sex=="male"”是控制依赖关系,“a.sex=="male"这个变量与a就是数据依赖关系。综上,本发明实施例通过在分布式的网络中采用多个第二节点运行数据的分析逻辑,得到变量(存储的原始数据)之间的数据依赖关系和/或控制依赖关系,该依赖关系作为返回结果可以表示与它的输入数据(获取数据的代码)的关联,代替了典型属性(如主体与主体属性、客体与客体属性、环境属性)的复杂属性关系,能够在数据分析智能合约的代码量大、结构复杂时,以一种简单、直观的方式展示输入数据与返回结果关系,然后再由第一节点执行现有的基于属性的访问控制方法,降低了人工代码审计的成本与难度,最终实现了在分布式、弱信任环境下实现数据资源的访问控制。需要说明的是,对于方法实施例,为了简单描述,故将其都表述为一系列的动作组合,但是本领域技术人员应该知悉,本发明实施例并不受所描述的动作顺序的限制,因为依据本发明实施例,某些步骤可以采用其他顺序或者同时进行。其次,本领域技术人员也应该知悉,说明书中所描述的实施例均属于优选实施例,所涉及的动作并不一定是本发明实施例所必须的。本说明书中的各个实施例均采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似的部分互相参见即可。本领域内的技术人员应明白,本发明实施例的实施例可提供为方法、装置、或计算机程序产品。因此,本发明实施例可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本发明实施例可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、cd-rom、光学存储器等)上实施的计算机程序产品的形式。本发明实施例是参照根据本发明实施例的方法、终端设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理终端设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理终端设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理终端设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。这些计算机程序指令也可装载到计算机或其他可编程数据处理终端设备上,使得在计算机或其他可编程终端设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程终端设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。尽管已描述了本发明实施例的优选实施例,但本领域内的技术人员一旦得知了基本创造性概念,则可对这些实施例做出另外的变更和修改。所以,所附权利要求意欲解释为包括优选实施例以及落入本发明实施例范围的所有变更和修改。最后,还需要说明的是,在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者终端设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者终端设备所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括所述要素的过程、方法、物品或者终端设备中还存在另外的相同要素。以上对本发明所提供的一种基于程序分析的数据资源的管控方法,进行了详细介绍,本文中应用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想;同时,对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改变之处,综上所述,本说明书内容不应理解为对本发明的限制。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1