基于MMU的网络监测方法和装置与流程
基于mmu的网络监测方法和装置
技术领域
[0001]
本发明涉及网络技术领域,特别是涉及一种基于mmu的网络监测方法和装置。
背景技术:
[0002]
随着软件系统升级以及漏洞修补方案的成熟,直接入侵主机进行破坏的病毒攻击方式逐渐减少,继而转为恶意消耗有限的网络资源,造成网络拥塞,以此破坏系统对外提供服务的能力。网络数据流检测协议(netflow)技术可实现对高速转发的ip数据流进行测量和统计,成为了当今互联网领域公认的最主要的ip/mpls流量分析、统计和计费行业标准。netflow技术能对ip/mpls网络的通信流量进行详细的行为模式分析和计量,并提供网络运行的详细统计数据。netflow系统包括探测器、采集器和分析报告系统三个部分。
[0003]
基于流的技术被越来越广泛地应用于网络领域,但网络管理员却缺少一种输出数据流的标准格式。ip数据流信息输出(ip flow information export,ipfix)就是为了满足这一需求提出的流信息测量的标准协议。ipfix是一种针对数据流特征分析,基于模板格式输出的协议,一般采用源ip地址、目的ip地址、tcp/udp源端口、tcp/udp目的端口、三层协议类型、服务类型和输入端口七元组作为关键字匹配ip报文,记录网络中这些流量的特征,如流量持续时间、报文个数、平均包长等,我们可以根据这些统计信息了解当前网络的应用情况,并根据这些信息对网络进行优化,安全检测和流量计费。
[0004]
现有交换芯片一般都支持报文入方向和出方向的报文信息统计,但是不能将报文在队列中的情况反馈给用户。报文在入方向处理引擎(ingress process engine,ipe)或出方向处理引擎(egress process engine,epe)处理时,会将报文转发过程中的一些统计信息送入ipfix引擎。ipfix可以将这些统计信息(如报文个数、报文长度、时延、抖动等)写入统计信息表,并上报给上层用户。但通过ipfix来实现对网络流量的监测,当网络中出现拥塞时,不能及时做出调整,从而导致仍然无法有效地提升网络质量。
技术实现要素:
[0005]
本发明实施例所要解决的技术问题是如何解决现有技术中存在的无法有效监测网络拥塞的问题。
[0006]
为了解决上述问题,本发明提供的技术方案如下:
[0007]
一种基于mmu的网络监测方法,其中,包括:报文进入流量管理模块;获取报文出方向的目的端口所对应的队列长度;ipfix判断所述目的端口对应的队列长度是否大于预设阈值;如果大于,则发出上报信息,且上报原因为出现流量burst;否则不发出上报信息。
[0008]
为了解决上述的技术问题,本发明还公开了另一种基于mmu的网络监测方法,其中,包括:报文进入流量管理模块;通过检测交换芯片的缓冲资源,判定报文是否丢包;如发生丢包,记录丢包原因;ipfix检测是否产生丢包原因;如果产生丢包原因,则发出上报信息,且上报原因为mmu丢包,并将丢包原因放在所述上报信息中;否则不发出上报信息。
[0009]
较优的,上述的基于mmu的网络监测方法中,所述检测交换芯片的缓冲资源包括进
口资源管理,出口资源管理;所述丢包原因包括:port buffer资源丢包,队列buffer资源丢包,总buffer资源丢包。
[0010]
为了解决上述的技术问题,本发明还公开了再一种基于mmu的网络监测方法,其中,包括上述的两种基于mmu的网络监测方法。
[0011]
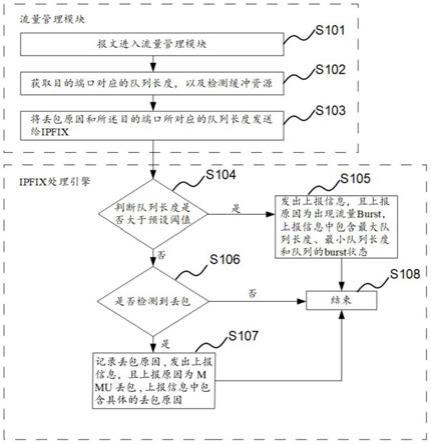
较优的,上述的基于mmu的网络监测方法中,所述发出上报信息包括:将mmu统计表中的信息通过dma上报给用户。
[0012]
为了解决上述的技术问题,本发明还公开了一种基于mmu的网络监测装置,其中,包括:流量管理模块,用于报文进入后,获取报文出方向的目的端口所对应的队列长度;ipfix处理引擎,用于判断所述目的端口对应的队列长度是否大于预设阈值;如果大于,则发出上报信息,且上报原因为出现流量burst;否则不发出上报信息。
[0013]
为了解决上述的技术问题,本发明还公开了另一种基于mmu的网络监测装置,其中,包括:流量管理模块,用于报文进入后,通过检测交换芯片的缓冲资源,判定报文是否丢包;如发生丢包,记录丢包原因;ipfix处理引擎,用于检测是否产生丢包原因;如果产生丢包原因,则发出上报信息,且上报原因为mmu丢包,并将丢包原因放在所述上报信息中;否则不发出上报信息。
[0014]
较优的,上述的基于mmu的网络监测装置中,所述检测交换芯片的缓冲资源包括进口资源管理,出口资源管理;所述丢包原因包括:port buffer资源丢包,队列buffer资源丢包,总buffer资源丢包。
[0015]
为了解决上述的技术问题,本发明还公开了再一种基于mmu的网络监测装置,其中,包括上述的两种基于mmu的网络监测装置。
[0016]
较优的,上述的基于mmu的网络监测装置中,所述发出上报信息包括:将mmu统计表中的信息通过dma上报给用户。
[0017]
与现有技术相比,本发明的技术方案具有以下优点:
[0018]
本发明中,本发明提出了一种基于内存管理单元(memory management unit,mmu)的网络监测方法,为了统计和计量mmu中的丢包和队列信息,增加了mmu的ipfix统计信息表的功能。报文在流量管理模块(taffic manager,tm)处理时,通过获取队列长度,在tm丢包时获取丢包原因,送往ipfix处理引擎,在ipfix处理引擎做记录,因此补充传统基于出入方向统计报文信息的不足,解决了现有技术中一则不能统计mmu的丢包情况,二则用户无法获取报文在队列中处理情况以及队列的状态信息的问题。通过将信息流在队列中处理情况上报给用户,真正实现网络可视化。
附图说明
[0019]
图1是本发明实施例所应用的ipfix的基本架构示意图;
[0020]
图2是本发明实施例1的一种基于mmu的网络监测方法的流程示意图。
具体实施方式
[0021]
现有交换芯片一般都支持报文入方向和出方向的报文信息统计,但是不能将报文在队列中的情况反馈给用户。报文在入方向处理引擎或出方向处理引擎处理时,会将报文转发过程中的一些统计信息送入ipfix引擎。ipfix可以将这些统计信息(如报文个数、报文
长度、时延、抖动等)写入统计信息表,并上报给上层用户。但通过ipfix来实现对网络流量的监测,当网络中出现拥塞时,不能及时做出调整,从而导致仍然无法有效地提升网络质量。
[0022]
本发明实施例为了统计和计量mmu中的丢包和队列信息,增加了mmu的ipfix统计信息表的功能。报文在流量管理模块(taffic manager,tm)处理时,获取队列长度,在tm丢包时获取丢包原因,送往ipfix处理引擎,在ipfix处理引擎做记录,因此补充传统基于出入方向统计报文信息的不足,解决了现有技术中一则不能统计mmu的丢包情况,二则用户无法获取报文在队列中处理情况以及队列的状态信息的问题。通过将信息流在队列中处理情况上报给用户,真正实现网络可视化。
[0023]
为使本发明的上述目的、特征和优点能够更为明显易懂,下面结合附图对本发明的具体实施例做详细的说明。
[0024]
实施例1
[0025]
本实施例公开了一种基于mmu的网络监测方法,应用于ipfix标准中。相对于传统ipfix仅支持ipe和epe的报文信息统计的处理,本实施例基于mmu的ipfix芯片实现方法,可以记录队列的状态,当出现突发流量burst或丢包时及时上报给用户。
[0026]
如图1所示,本实施例的一种基于mmu的网络监测方法包括:
[0027]
步骤s101,报文进入流量管理模块。
[0028]
报文在ipe ipfix engine处理完后,根据关键域匹配,分配相应的flowid,并携带所述flowid,进入流量管理模块处理。
[0029]
步骤s102,获取报文出方向的目的端口所对应的队列长度,以及检测交换芯片的缓冲资源,判定报文是否丢包;如发生丢包,记录丢包原因。
[0030]
网络拥塞造成丢包率上升的原因很多,主要是网路资源被大量占用造成的。应用中遇到的造成网络拥塞的情况有很多,如大量的udp流量,大量的组播流、广播包穿越路由器等。上述情况造成网络拥塞后,系统会采取流量控制,丢弃不能传输的包。所述检查芯片缓冲资源情况包括:进口资源管理和出口资源管理。通过对芯片缓冲资源的检查,可以检测当前报文是否存在丢包的情况,并进一步地输出资源丢包原因,是因为哪种资源检查丢的包。例如,port buffer资源丢包,队列buffer资源丢包,总buffer资源丢包等。mmu将上述丢包原因记录到mmu统计表中。同时,流量管理模块也会检测并记录报文的目的端口(即在本网络设备上出方向上下一跳的端口地址)的队列长度。
[0031]
步骤s103,将丢包原因和所述目的端口所对应的队列长度发送给ipfix处理引擎。
[0032]
步骤s104,ipfix判断所述目的端口对应的队列长度是否大于预设阈值。
[0033]
所述预设阈值存储在寄存器中。通过检测目的端口对应的队列长度是否大于预设阈值,可以判断目前在目的端口是否存在网络拥塞,即流量burst。如果大于,进入步骤s105,否则进入步骤s106。
[0034]
步骤s105,发出上报信息,且上报原因为出现流量burst。
[0035]
在mmu的统计信息表中保存当前目的端口的队列长度后,将mmu统计表中的信息通过直接存储器访问(direct memory access,dma)上报给用户,上报原因为出现流量burst。上报信息中包含最大队列长度、最小队列长度和队列的burst状态等。
[0036]
步骤s106,ipfix是否检测到丢包。
[0037]
ipfix检测所述记录的丢包原因数量是否大于0,如果丢包原因数量不大于0,则说明报文未发生丢包情况,否则说明已发生丢包。如果大于0,则进入步骤s107,否则进入步骤s108,网络监测结束。
[0038]
步骤s107,发出上报信息,且上报原因为mmu丢包。
[0039]
判定出现丢包后,ipfix记录丢包原因,报文在流量管理模块被丢弃。此时,需要上报给用户,将mmu统计表中的信息,如丢包原因等,通过dma上报给用户,上报原因为mmu丢包。上报信息中包含具体的丢包原因。
[0040]
步骤s108,结束。
[0041]
报文在队列中的排队时延及当前队列的拥塞情况直接反映网络的服务质量,因此根据该队列信息及时调整网络部署,优化网络结构能够显著提升网络质量。本实施例通过计量和统计mmu丢包情况和队列burst状态,提出了基于mmu的ipfix的方法,通过记录mmu产生的包丢原因,包括进、出口buffer资源,以及基于mmu记录报文队列的将网络拥塞状态,记录最大队列长度,最小队列长度,队列的突发burst状态,从而便于运维人员对网络进行调整和优化。
[0042]
实施例2
[0043]
本实施例公开了一种与实施例1相对应的基于mmu的网络监测装置,包括流量管理模块和ipfix处理引擎。其中,
[0044]
流量管理模块用于报文进入后,获取报文出方向的目的端口所对应的队列长度,以及通过检测交换芯片的缓冲资源,判定报文是否丢包;如发生丢包,记录丢包原因。所述检测交换芯片的缓冲资源包括进口资源管理,出口资源管理;所述丢包原因包括:port buffer资源丢包,队列buffer资源丢包,总buffer资源丢包。
[0045]
ipfix处理引擎用于判断所述目的端口对应的队列长度是否大于预设阈值,以及用于检测所述记录的丢包原因数量是否大于0。如果所述目的端口对应的队列长度大于所述预设阈值,则发出上报信息,且上报原因为出现流量burst;否则不发出上报信息。如果所述记录的丢包原因数量大于0,则发出上报信息,且上报原因为mmu丢包;否则不发出上报信息。所述发出上报信息包括:将mmu统计表中的信息(包括但不限于,最大队列长度,最小队列长度,队列的突发burst状态,和产生丢包时的丢包原因等)通过dma上报给用户。
[0046]
可以理解的是,本实施例的一种基于mmu的网络监测装置和实施例1的一种基于mmu的网络监测方法为基于同一发明构思。本领域技术人员可以理解的是,本实施例的相应实施可以参照实施例1的相应内容,此处不再赘述。
[0047]
以上是对本发明的实现方式的具体说明,但是本领域的技术人员将理解的是,前面实施方案是示例性的并且是出于清晰和理解的目的,而不限于本发明的范围,所意图的是,本领域的技术人员在阅读了数码说并研究了附图之后,会明了其所有置换形式,增强形式,等同形式,组合形式,改进形式都被包括在本发明的实质范围内。
[0048]
本领域普通技术人员可以理解上述实施例的各种方法中的全部或部分步骤是可以通过程序和指令相关的硬件来完成,该程序可以存储于一计算机可读存储介质中,存储介质可以包括:rom、ram、磁盘或光盘等。
[0049]
虽然本发明披露如上,但本发明并非限定于此。任何本领域技术人员,在不脱离本发明的精神和范围内,均可作各种更动与修改,因此本发明的保护范围应当以权利要求所
限定的范围为准。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1