基于随机森林非均匀量化特征提取的安全中继选择方法
本发明属于无线通信技术领域,特别是物理层安全技术领域,特别涉及一种基于随机森林非均匀量化特征提取的安全中继选择方法。
背景技术:
由于无线信号的开放性,保障数据的安全传输是无线通信系统应用的重要前提。wyne于1975年首次提出一种新型的安全保障技术,物理层安全技术。如信息论和密码学表明,通过有效地利用无线信道内在的随机特性,如环境衰落、路径损耗以及环境噪声、用户间干扰等,可以降低恶意用户窃听到的信号质量,并通过信号设计和信号处理技术实现无密钥的信息安全传输。
中继技术是最常用的物理层安全技术之一,它可以通过扩展通信范围来对抗衰落。在中继系统中,适当的中继选择方案可以提高主信道的可达容量,提高系统的安全性能。传统的中继选择方案主要依靠端到端最大化算法和精确信道状态信息实现,当系统环境更为复杂时,例如涉及多跳中继或快速变化的csi环境时,传统的中继选择方案会导致较高资源消耗和处理延迟。
机器学习(machinelearning,ml)是一种高效的人工智能技术,它利用智能算法和经验提高系统性能。采用机器学习技术时,中继选择的训练阶段可以离线进行,可以减少实时决策的时延,快速适应信道变化。集成学习算法集成了多个个体分类算法,克服了个体分类算法精确度不高以及过度拟合的固有缺陷。随机森林(randomforest,rf)是由breiman设计的一种有效的集成学习算法。该方法利用装袋法和随机子空间方法,形成多个不同的决策树模型,并通过组合和投票来确定最终的预测结果。
技术实现要素:
因此,提出一种基于随机森林非均匀量化特征提取的安全中继选择方法,所述方法目的是在具有多个中继节点的全双工中继系统中,将安全中继选择建模为一个多类分类问题,通过构建随机森林(randomforest,rf)集成学习算法模型,选择最优中继以提升系统安全性能。由于随机森林要求描述待分类对象的输入特征是离散值,提出了基于非均匀量化的信道状态信息(channelstateinformation,csi)离散特征值提取方法。为达到上述目的,本发明提供如下技术方案。
基于随机森林非均匀量化特征提取的安全中继选择方法,所述方法包括以下步骤:
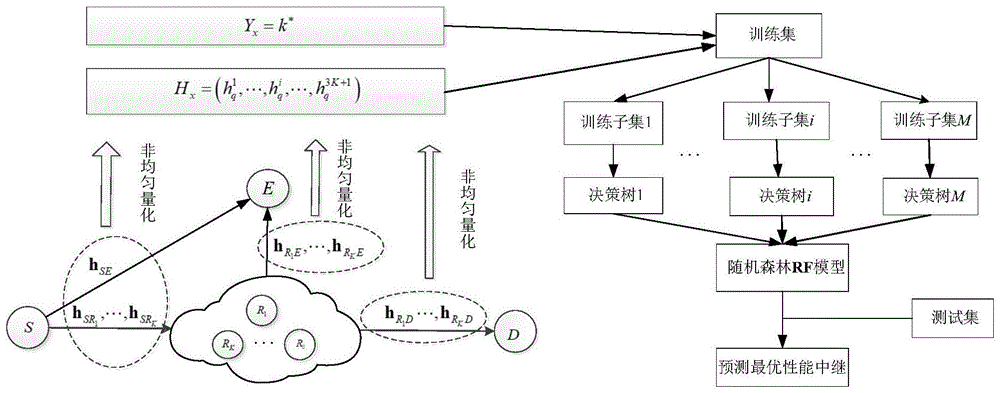
s1、构建全双工多中继系统模型,其包括源节点s、目的节点d、窃听节点e和k个全双工中继节点r1,…,ri,…,rk;
s2、分别获取中继节点、目的节点以及窃听节点的可达容量,计算在这些可达容量下系统的安全容量,并找出使系统安全性能最优的中继节点索引k*;
s3、研究基于rf集成学习方法的全双工中继系统安全中继选择方案。;
s4、提出了非均匀量化算法来提取rf算法所需的离散csi特征值。
进一步的,在构建的全双工多中继系统模型时隙t中,中继节点处ri的接收信号表示为:
进一步的,使系统安全性能最优的中继节点索引k*表示为:
其中,k为中继节点数量;
进一步的,基于非均匀量化算法来提取随机森林集成学习算法所需的离散csi特征值包括:
将主信道和窃听信道的csi集合表示为:
若csi量化后的特征值huq为1到n之间的整数,hx为集合ω中原始的csi值,则csi量化后的特征值huq表示为:
其中,
进一步的,若csi区域的长度为[0,t],将该区域分成n个间隔,则特征值j所在区间的下边界
特征值j所在区间的上边界
进一步的,构建基于rf集成学习方法的全双工中继系统安全中继选择模型时,其训练集数据集定义为:d={(h1,y1),(h2,y2),…,(hx,yx)},(hx,yx)表示训练样本x,其输入值为hx,表示为
本发明其目的是在多个中继节点的全双工中继系统中,将安全中继选择建模为一个多类分类问题,通过构建rf集成学习算法模型,选择最优中继以提升系统安全性能。基于rf集成学习最优中继选择算法的实现分为三个阶段:训练数据准备、模型建立和选择结果预测。由于随机森林要求描述待分类对象的输入特征是离散值,进一步提出了基于非均匀量化算法的csi离散特征值提取方法。最后,通过仿真验证给出优化设计方案的性能。
附图说明
图1为本发明采用的算法流程图;
图2为cep随着量化区间数量n增加的变化情况;
图3为cep随着中继节点数k增加的变化情况;
图4为随机森林、支持向量机、决策树算法的cep对比情况;
图5为随机森林、支持向量机、决策树算法系统安全容量对比情况;
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。
实施例1
如图1所示,本发明采用的系统模型由源节点s、目的节点d、窃听节点e和具有多个全双工中继节点r1,…,ri,…,rk组成。
在时隙t,源节点s传输数据xs(t)到中继节点ri,中继点ri再解码转发到目的节点d。为更符合实际情况,考虑了一个时隙的延迟来进行中继节点的对接收信息解码和自干扰抑制处理。ri点的接收信号可表示为:
目的节点d处接收到的信息数据表示为:
窃听节点在时隙t-1和t均能收到传输的信息,可表示为:
此外,假设所有信道系数在一个传输块内保持不变,w为一个传输块内数据包的数量,式(3)可以被重写为:
ye=hxs+ne(4)
ye=(ye[w+1],ye[w],…,ye[1])t(5)
xs=(xs[w],…,xs[1])t(6)
ne=(ne[w+1],ne[w],…,ne[1])t(7)
窃听节点的可达速率表示为:
对矩阵hhh进行特征分解,式(9)可以被重写为:
θw为矩阵hhh的第w个特征值,由于矩阵h是一个toeplitz矩阵,根据[9]中toeplitz矩阵特征值表示方式的详细推导,θw可以表示为:
将公式(11)代入(10),窃听可达容量可以表示为:
假设当w足够大时,式(12)中的第二项趋近于0,因此,ce可以表示为:
相应的,中继点r和目的点d的可达容量为:
由之前推导的系统模型中可知,源节点s和目的地节点d之间的链路包括两个部分,即源节点s到中继节点ri和中继节点ri到目的地节点d。因此,主信道的可达速率是这两个链路中较小的一个,则系统的安全容量
最优安全中继选择方案是从多个中继节点中寻找出使系统的安全容量最大化的中继节点索引。该索引可表示为:
rf算法比个体分类算法具有更好的泛化和分类性能,能有效地减少过拟合,可将中继选择优化问题建模为多类分类问题。基于rf的中继选择优化方案包括训练数据准备、模型建立和选择结果预测三个阶段。
(1)训练数据准备
将训练数据集定义为:d={(h1,y1),(h2,y2),…,(hx,yx)},(hx,yx)表示训练样本x,其输入值为hx,输出值为yx。其中
随机森林算法输入特征值hx需采用离散变量,因此,需要利用特征提取方法将主信道和窃听信道的csi集合
huq为采用非均匀特征提取法量化后的特征值,为1到n之间的整数。hx为集合ω中原始的csi值,huq与hx之间的映射关系可以表示为:
(2)模型建立阶段
在这个阶段,通过训练集d={(h1,y1),(h2,y2),…,(hx,yx)}来生成rf模型。通过以下步骤实现:
1)利用装袋法从原始集合中产生训练子集;
2)利用随机子空间方法从hx中随机产生特征子集;
3)在特征子集中选取分割准则最高的最佳特征,通过特征值检验对当前训练子集进行分割。通过这种方法迭代生成决策树,直达满足停止标准为准,叶子节点代表了候选中继节点的索引。
4)重复步骤1)—3)m次,产生m棵决策树以构建随机森林模型;
5)rf通过基于多数投票原则输出最终的选择结果。
rf模型完成后,中央控制器(centralcontroller,cc)将其存储起来,除非修改网络拓扑结构,否则rf模型不会任何变化。
(3)结果预测阶段
对于每个预测,cc首先采集合法信道和窃听信道的瞬时csi并进行量化,然后将量化后的特征值代入训练的rf模型中,输出最优中继的选择指标。中央控制器将此结果广播到所有节点,同时被选定的中继节点准备中继工作。前两个阶段,训练数据准备和模型建立,可视为初始化,在实际传输之前离线进行,减少了实时传输时的决策时延。
本实施例给出了仿真结果来验证本发明所提出的优化设计方案。仿真过程中,随机产生服从瑞利分布的10000个合法信道和非法信道的csi,其中的70%形成训练集,30%形成测试集。利用matlab中的机器学习工具箱建立了rf模型。系统仿真的参数可以设定为
首先讨论采用非均匀量化方法时,量化区间个数n对算法性能的影响。图2表示cep随着n的增加的变化情况。从图2中可以看出,分类错误概率cep随着n的增加而增加,但分类错误概率增加的程度很小,分类性能受量化间隔n的取值影响较小。
图3为cep随中继点个数k增加而变化的情况。从图3中可以看出,分类错误概率cep随着中继节点数k的增加而增加。为进一步说明本算法的性能,将其与2种典型的个体分类算法,支持向量机(supportvectormachine,svm)和决策树算法进行对比。图4表示了分别采用三种机器学习算法进行安全中继选择时cep的情况。图5表示了分别采用三种机器学习算法进行安全中继选择时系统的平均安全容量。图4和图5显示了相对于2种个体分类算法,运用随机森林算法可达到更高的系统安全容量以及最低的分类错误率。
本领域普通技术人员可以理解上述实施例的各种方法中的全部或部分步骤是可以通过程序来指令相关的硬件来完成,该程序可以存储于计算机可读存储介质中,存储介质可以包括:rom、ram、磁盘或光盘等。
以上所举实施例,对本发明的目的、技术方案和优点进行了进一步的详细说明,所应理解的是,以上所举实施例仅为本发明的优选实施方式而已,并不用以限制本发明,凡在本发明的精神和原则之内对本发明所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!