抓包装置以及方法与流程
1.本发明涉及对通信网络中流动的数据包进行捕获,并记录到次级存储装置的抓包装置以及方法。
背景技术:
2.为了应对以太网(注册商标)等通信网络中的通信障碍,而需要一种能够长期地对通信网络中流动的所有的数据包进行捕获的抓包装置。因此,需要对发生的数据包不会疏漏地快速记录到次级存储装置。
3.作为以往的快速记录到次级存储装置的技术,提出了采用了并行次级存储装置的数据写入方法(例如参照专利文献1)。在专利文献1中,使次级存储装置并行,当有写入请求时,将数据记录到多个次级存储装置中的最小负载量的次级存储装置中。据此,可以在不发生接入负载量的偏倚的状态下,使并行次级存储装置快速地进行数据的输入输出。
4.(现有技术文献)
5.(专利文献)
6.专利文献1日本特开平9-54658号公报
7.然而在专利文献1的技术中,对以200gbps这种非常快的速度在通信网络中流动的所有的数据包不疏漏地连续捕获,并记录到次级存储装置是困难的。
技术实现要素:
8.于是,本发明的目的在于提供一种能够对以200gbps在通信网络中流动的所有的数据包不疏漏地连续捕获,并记录到次级存储装置的抓包装置以及方法。
9.为了实现上述的目的,本发明的一个形态所涉及的抓包装置对在通信网络中流动的数据包进行捕获,并记录到次级存储装置,所述抓包装置具备:捕获部,对以200gbps在所述通信网络中流动的数据包,无疏漏地连续地进行捕获;控制部,暂时保持由所述捕获部捕获的数据包;以及接口部,将所述控制部中暂时保持的数据包记录到所述次级存储装置,所述控制部具有构成numa架构的2个numa节点,所述2个numa节点分别为,由第1处理器和第1存储器构成的第1numa节点、以及由第2处理器和第2存储器构成的第2numa节点,所述numa是指,non-uniform memory access即非统一内存访问,所述捕获部具有:第1捕获部,与所述第1numa节点连接,对所述通信网络中流动的数据包进行捕获,并将捕获的数据包存放到所述第1存储器;以及第2捕获部,与所述第2numa节点连接,与所述第1捕获部的捕获并行地对所述通信网络中流动的数据包进行捕获,并将捕获的数据包存放到所述第2存储器,所述接口部具有:第1接口部,与所述第1numa节点连接,将所述第1存储器中存放的数据包记录到所述次级存储装置;以及第2接口部,与所述第2numa节点连接,与所述第1接口部的记录并行地将所述第2存储器中存放的数据包记录到所述次级存储装置。
10.并且,为了实现上述的目的,本发明的一个形态所涉及的抓包方法对通信网络中流动的数据包进行捕获,并记录到次级存储装置,所述抓包方法包括:捕获步骤,对以
200gbps在所述通信网络中流动的数据包,无疏漏地连续地进行捕获;以及记录步骤,将在所述捕获步骤捕获的数据包记录到所述次级存储装置,所述捕获步骤包括:第1捕获步骤,对所述通信网络中流动的数据包进行捕获,并将捕获的数据包存放到构成numa架构的第1numa节点所具有的第1存储器,所述numa是指,non-uniform memory access即非统一内存访问;以及第2捕获步骤,与所述第1捕获步骤的捕获并行,对所述通信网络中流动的数据包进行捕获,并将捕获的数据包存放到构成所述numa架构的第2numa节点所具有的第2存储器,所述记录步骤包括:第1记录步骤,将所述第1存储器中存放的数据包记录到所述次级存储装置;以及第2记录步骤,与所述第1记录步骤的记录并行,将所述第2存储器中存放的数据包记录到所述次级存储装置。
11.通过本发明,提供了一种能够对以200gbps在通信网络中流动的所有的数据包不疏漏地连续捕获,并记录到次级存储装置的抓包装置以及方法。
附图说明
12.图1是示出实施方式所涉及的抓包装置的构成的方框图。
13.图2是示出图1所示的抓包装置的详细构成的方框图。
14.图3是示出实施方式所涉及的抓包装置的工作(抓包方法)的流程图。
15.图4a示出了图3的捕获步骤中的数据包的流动。
16.图4b示出了图3的记录步骤中的数据包的流动。
17.图5是示出实施方式所涉及的抓包装置的详细工作的(通过多线程的并行处理)的数据流程图。
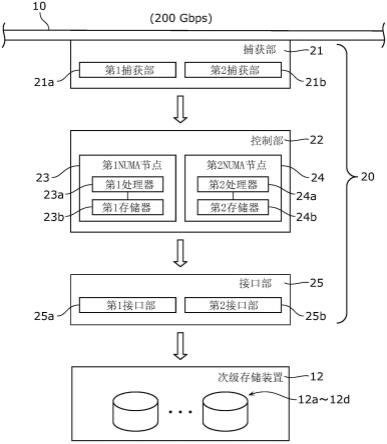
18.图6是实验中所使用的本实施方式所涉及的抓包装置的外观图。
19.图7a示出了通过图5所示的抓包装置的实验结果。
20.图7b示出了通过比较例所涉及的抓包装置的实验结果。
具体实施方式
21.以下利用附图对本发明的实施方式进行详细说明。另外,以下将要说明的实施方式均为示出本发明的一个具体例子。以下的实施方式所示的数值、形状、制造公司、型号、构成要素、构成要素的配置位置以及连接方式、步骤、步骤的顺序等均为一个例子,其主旨并非是对本发明进行限定。并且各个图并非严谨的图示。在各个图中对于实质上相同的构成赋予相同的符号,并省略或简化重复的说明。
22.图1是示出实施方式所涉及的抓包装置20的构成的方框图。另外,在该图中也示出了成为抓包的对象的通信网络10、以及捕获的数据包的记录目的地即次级存储装置12。
23.抓包装置20是对通信网络10中流动的数据包进行捕获,并记录到次级存储装置12的装置,其具备:捕获部21,对以200gbps在通信网络10中流动的数据包进行不疏漏地连续地捕获;控制部22,暂时保持由捕获部21捕获的数据包;以及接口部25,将控制部22中暂时保持的数据包记录到次级存储装置12。
24.控制部22具有构成numa(non-uniform memory access:非统一内存访问)架构的2个numa节点,这2个numa节点是并行工作的第1numa节点23以及第2numa节点24。第1numa节点23由第1处理器23a和第1存储器23b构成。第2numa节点24由第2处理器24a和第2存储器
24b构成。
25.另外,numa架构是共享存储器型多处理器计算机系统的架构之一,处理器与存储器的配对(将此称为节点)存在多个,这些以互连的方式来连接。通过numa架构,从处理器来看,向同一个节点的存储器(也称为本地内存)的接入为低延迟(low latency),向其他的节点的存储器(也称为远程内存)的接入为高延迟(high latency)。另外作为一个参考,与numa架构不同的uma(uniform memory access:统一内存访问)架构是共享存储器型多处理器计算机系统的架构之一,是各处理器共享总线,且所有的处理器针对任意的存储器能够以相同的时间进行接入的架构。在本实施方式中采用具有多处理器中的向本地内存的接入为低延迟这一特征的numa架构。
26.捕获部21具有并行工作的第1捕获部21a以及第2捕获部21b。第1捕获部21a与第1numa节点23连接,对通信网络10中流动的数据包进行捕获,并将捕获的数据包存放到第1存储器23b。即第1存储器23b作为由第1捕获部21a捕获的数据包的缓冲存储器来发挥作用。第2捕获部21b与第2numa节点24连接,与第1捕获部21a的捕获并行地对通信网络10中流动的数据包进行捕获,并将捕获的数据包存放到第2存储器24b。即第2存储器24b作为由第2捕获部21b捕获的数据包的缓冲存储器来发挥作用。
27.接口部25具有并行工作的第1接口部25a以及第2接口部25b。第1接口部25a与第1numa节点23连接,将第1存储器23b中存放的数据包记录到次级存储装置12。第2接口部25b与第2numa节点24连接,与第1接口部25a的记录并行地将第2存储器24b中存放的数据包记录到次级存储装置12。
28.次级存储装置12是用于保持数据包的非易失性存储装置(外部存储装置),是由ssd(solid state drive:固态硬盘)或hdd(hard disk drive:硬盘驱动器)等构成的多个次级存储装置12a~12d的集合。
29.图2是示出图1所示的抓包装置20的详细构成的方框图。另外在该图中也示出了,构成一个通信网络10的用于上行的通信网络10a以及用于下行的通信网络10b、构成次级存储装置12的多个次级存储装置12a~12d、以及存放有os(operating system:操作系统)的次级存储装置14。
30.如该图所示,构成第1numa节点23的第1处理器23a与构成第2numa节点24的第2处理器24a由qpi(quick path interconnect:快速通道互联)来连接,能够相互通信。
31.第1处理器23a具有3个pci(peripheral component interconnect:外设组件互连标准)插槽#1~#3,利用其中的2个pci插槽#1以及#2,经由pci-e(pci express)总线与第1接口部25a连接,利用其中的1个pci插槽#3,经由pci-e总线与第1捕获部21a连接。
32.构成第1numa节点23的第1存储器23b例如是ddr4sdram(double-data-rate4 synchronous dynamic random access memory:第四代双倍数据率同步动态随机存取存储器)。
33.第1捕获部21a是针对构成通信网络10的用于上行的通信网络10a,通过网络分流器对第1类数据包即以100gbps流动的上行的数据包进行分流,并利用收发器进行检测并捕获,将捕获的数据包存放到第1存储器23b的nic(network interface card:网卡)。
34.第1接口部25a具有并行工作的2个raid(redundant arrays of inexpensive disks:独立磁盘冗余阵列)控制器26a以及26b。2个raid控制器26a以及26b分别对构成raid
的次级存储装置12a以及12b,进行数据的输入输出以及管理。
35.次级存储装置14存放os(operating system:操作系统),与第1处理器23a连接。另外,os中包括用于使抓包装置20工作的程序,即包括以后将要说明的成为由第1处理器23a并行处理的多个第1线程、以及由第2处理器24a并行处理的多个第2线程的程序。
36.第2处理器24a具有3个pci插槽#1~#3,利用其中的2个pci插槽#1以及#2,经由pci-e总线与第2接口部25b连接,利用其中的1个pci插槽#3,经由pci-e总线与第2捕获部21b连接。
37.构成第2numa节点24的第2存储器24b例如是ddr4 sdram。
38.第2捕获部21b是针对构成通信网络10的用于下行的通信网络10b,通过网络分流器对第2类数据包即以100gbps流动的下行的数据包进行分流,并利用收发器进行检测并捕获,将捕获的数据包存放到第2存储器24b的nic(网卡)。
39.第2接口部25b具有并行工作的2个raid控制器27a以及27b。2个raid控制器27a以及27b分别对构成raid的次级存储装置12c以及12d,进行数据的输入输出以及管理。
40.接着,对具有以上这样的构成的本实施方式所涉及的抓包装置20的工作进行说明。
41.图3是示出实施方式所涉及的抓包装置20的工作(即抓包方法)的流程图。
42.首先,捕获部21在控制部22的控制下,对以200gbps在通信网络10中流动的数据包不疏漏地进行连续地捕获(捕获步骤s10)。图4a示出了图3的捕获步骤s10中的数据包的流动。黑色粗箭头表示被捕获的数据包的流动。
43.在该捕获步骤s10中,第1捕获步骤s10a与第2捕获步骤s10b并行执行。即在第1捕获步骤s10a中,第1捕获部21a通过第1numa节点23的控制,对以100gbps在通信网络10a中流动的数据包进行捕获,将捕获的数据包存放到第1numa节点23所具有的本地内存即第1存储器23b。并且,在第2捕获步骤s10b中,第2捕获部21b通过第2numa节点24的控制,对以100gbps在通信网络10b中流动的数据包进行捕获,将捕获的数据包存放到第2numa节点24所具有的本地内存即第2存储器24b。
44.接着,接口部25通过控制部22的控制,将在捕获步骤s10捕获的数据包记录到次级存储装置12(图3的记录步骤s11)。图4b示出了图3的记录步骤s11中的数据包的流动。黑色粗箭头表示捕获的数据包的流动。
45.在该记录步骤s11中,第1记录步骤s11a与第2记录步骤s11b并行执行。即在第1记录步骤s11a中,第1接口部25a通过第1numa节点23的控制,将第1存储器23b中存放的数据包记录到次级存储装置12a以及12b。并且,在第2记录步骤s11b中,第2接口部25b通过第2numa节点24的控制,将第2存储器24b中存放的数据包记录到次级存储装置12c以及12d。
46.图5是示出实施方式所涉及的抓包装置20的详细工作的(即通过多线程的并行处理)的数据流程图。在此示出了,捕获的数据包被记录时的数据包的流动。图5的(a)示出了经过第1numa节点23的数据包的流动,图5的(b)示出了经过第2numa节点24的数据包的流动。
47.如图5的(a)所示,在经过第1numa节点23的数据包的流动中,首先,通过由第1处理器23a执行的多个线程(捕获线程30a~30c)的并行传输,由第1捕获部21a捕获的数据包被存放到第1存储器23b。接着,第1存储器23b中存放的多个数据包经过负载均衡31之后,通过
由第1处理器23a执行的多个线程(持有队列33a~33c的存储线程32a~32c)的并行传输,经由第1接口部25a(未图示),而被记录到次级存储装置12a以及12b。另外,捕获线程30a~30c以及存储线程32a~32c是由第1处理器23a进行并行处理的多个第1线程的一个例子。并且,通过线程的数据包的传输以规定量的数据即数据块为单位而被执行。
48.负载均衡31是进行将第1存储器23b中存放的多个数据包记录到次级存储装置12a以及12b的负载分散到多个存储线程32a~32c的控制的程序,由第1处理器23a执行。另外,捕获线程30a~30c、存储线程32a~32c以及负载均衡31是次级存储装置14中存放的程序经由第1处理器23a,被加载到第1存储器23b并被保持的软件。
49.如图5的(b)所示,在经由第2numa节点24的数据包的流动中,首先,通过由第2处理器24a执行的多个线程(捕获线程40a~40c)的并行传输,由第2捕获部21b捕获的数据包被存放到第2存储器24b。接着,第2存储器24b中存放的多个数据包经过负载均衡41之后,通过由第2处理器24a执行的多个线程(持有队列43a~43c的存储线程42a~42c)的并行传输,经过第2接口部25b(未图示)而被记录到次级存储装置12c以及12d。另外,捕获线程40a~40c以及存储线程42a~42c是由第2处理器24a进行并行处理的多个第2线程的一个例子。并且,通过线程的数据包的传输以规定量的数据即数据块为单位而被执行。
50.负载均衡41是进行将第2存储器24b中存放的多个数据包记录到次级存储装置12b以及12d的负载分散到多个存储线程42a~42c的控制的程序,由第2处理器24a执行。另外,捕获线程40a~40c、存储线程42a~42c以及负载均衡41是次级存储装置14中存放的程序经过第1处理器23a以及第2处理器24a被加载到第2存储器24b并被保持的软件。
51.这样,在本实施方式所涉及的抓包装置20中,经过第1numa节点23的数据包的流动、与经过第2numa节点24的数据包的流动被完全分离,并且被并行执行,据此,从整体上来看,实现了由抓包装置20进行快速地捕获。
52.接着,对利用本实施方式所涉及的抓包装置20进行的实验进行说明,该实验是由抓包装置20对以200gbps在太网(注册商标)中流动的数据包进行连续地捕获。
53.图6是实验中使用的本实施方式所涉及的抓包装置20的外观图。该抓包装置20作为可携带型系统而被构筑,该可携带型系统将键盘和显示器等用户接口以及次级存储装置合为一体,其主要的硬件构成如以下所示。
54.第1处理器23a以及第2处理器24a均为intel公司的型号xeon e5-2637v3(基本工作频率为3.5ghz、核心数为4个、线程数为8个)。
55.第1存储器23b以及第2存储器24b均由8个8gb的dimm(dual inline memory module:双列直插式存储模块、速度为ddr4-2133、合计存储容量为64gb)构成。
56.第1捕获部21a以及第2捕获部21b均为napatech公司的型号nt200a01-2x100。
57.第1接口部25a以及第2接口部25b均由2个microsemi adaptec公司的型号asr-81605zq raid阵列卡构成。
58.次级存储装置12(次级存储装置12a~12d)由32个seagate公司的型号nytro3530(容量为3.2tb、类型为sas的ssd)构成。
59.图7a示出了通过图5所示的抓包装置20的实验结果。图7b示出了通过比较例所涉及的抓包装置的实验结果。比较例所涉及的抓包装置是不具备numa架构的(即具备uma架构)抓包装置。
60.在图7a以及图7b中,横轴表示时间(秒)。图7a的(a)以及图7b的(a)的纵轴表示向次级存储装置12(具体而言是8个次级存储装置中的一个(次级存储装置12a等))的写入速度(mb/s),图7a的(b)以及图7b的(b)的纵轴表示向次级存储装置12进行输入输出的时间的比例(%)。在图7a以及图7b中以对反复进行取样得到的测量值以曲线连接来示出。
61.在比较例所涉及的图7b中,如记载了“发生丢包”的位置所示,可以看到间歇地且断续地写入速度降低(图7b的(a))、且进行输入输出的时间的比例降低(图7b的(b))的现象。从写入速度和进行输入输出的时间的比例同时降低中可以知道,不是次级存储装置的间歇性的写入性能的劣化,而是用于写入的充分的数据本身没能到达次级存储装置。即直到次级存储装置的途中的路径成为原因,而造成写入速度降低。更详细而言,每隔1~2个小时发生了丢包。即比较例所涉及的抓包装置不能无疏漏地将以200gbps流动的数据包连续地记录到次级存储装置。
62.对此,在本实施方式所涉及的图7a中没有观察到写入速度的大幅度地降低(图7a的(a)),也没有观察到输入输出的时间的大幅度地降低(图7a的(b))。更详细而言,在连续48个小时以上没有发生丢包的状态下进行了捕获。即本实施方式所涉及的抓包装置20能够无疏漏地,将以200gbps流动的数据包连续地记录到次级存储装置。这是因为,本实施方式所涉及的抓包装置20与比较例所涉及的抓包装置不同,具有由独立地且并行地进行数据传输的2个numa节点构成的numa架构的缘故。即在实施方式所涉及的抓包装置20中,明确地指定属于各个numa节点内的cpu的次级存储装置,按各个numa节点独立地进行了直到并行写入为止的处理。据此,可以不必经由成为数据传输的瓶颈的qpi,通过多处理器的并行处理,就能够将捕获的数据包记录到次级存储装置12。
63.如以上所述,本实施方式所涉及的抓包装置20是对在通信网络10中流动的数据包进行捕获,并记录到次级存储装置12的装置,抓包装置20具备:捕获部21,对以200gbps在通信网络10中流动的数据包,无疏漏地连续地进行捕获;控制部22,暂时保持由捕获部21捕获的数据包;以及接口部25,将控制部22中暂时保持的数据包记录到次级存储装置12。控制部22具有构成numa架构的2个numa节点,该2个numa节点分别为,由第1处理器23a和第1存储器23b构成的第1numa节点23、以及由第2处理器24a和第2存储器24b构成的第2numa节点24。捕获部21具有:第1捕获部21a,与第1numa节点23连接,对在通信网络10中流动的数据包进行捕获,并将捕获的数据包存放到第1存储器23b;以及第2捕获部21b,与第2numa节点24连接,与第1捕获部21a的捕获并行地对通信网络10中流动的数据包进行捕获,并将捕获的数据包存放到第2存储器24b。接口部25具有:第1接口部25a,与第1numa节点23连接,将第1存储器23b中存放的数据包记录到次级存储装置12;以及第2接口部25b,与第2numa节点24连接,与第1接口部25a的写入并行地将第2存储器24b中存放的数据包记录到次级存储装置12。
64.据此,通过numa架构,由于通过第1numa节点23的抓包以及数据包向次级存储装置12的记录、与通过第2numa节点24的抓包以及数据包向次级存储装置12的记录,能够按各个numa节点并行地且独立的进行,因此能够对以200gbps在通信网络中流动的所有的数据包,无疏漏地进行连续地捕获,并记录到次级存储装置12。
65.在此,第1捕获部21a对以100gbps在通信网络10中流动的第1类数据包进行捕获,并将捕获的数据包存放到第1存储器23b,第2捕获部21b与第1捕获部21a的捕获并行,对以100gbps在通信网络10中流动的第2类数据包进行捕获,并将捕获的数据包存放到第2存储
器24b。据此,以200gbps在通信网络中流动的数据包的捕获负载被均等地分散到2个numa节点,无疏漏地被连续地捕获。
66.并且,第1类数据包是通信网络10中的上行的数据包,第2类数据包是通信网络10中的下行的数据包。据此,以200gbps在通信网络中流动的数据包被分为上行的数据包和下行的数据包,其负载被分散到2个numa节点。
67.并且,第1存储器23b保持由第1处理器23a并行处理的多个第1线程,多个第1线程中包括:将由第1捕获部21a依次捕获的数据包存放到第1存储器23b的多个捕获线程30a~30c;以及将第1存储器23b中存放的多个数据包,经由第1接口部25a记录到次级存储装置12的多个存储线程32a~32c,第2存储器24b保持由第2处理器24a并行处理的多个第2线程,多个第2线程中包括:将由第2捕获部21b依次捕获的数据包存放到第2存储器24b的多个捕获线程40a~40c;以及将第2存储器24b中存放的多个数据包,经由第2接口部25b记录到次级存储装置12的多个存储线程42a~42c。
68.据此,通过第1处理器23a进行的多线程,由第1捕获部21a无疏漏地连续捕获的数据包被记录到次级存储装置12,并且与此并行,通过第2处理器24a进行的多线程,由第2捕获部21b无疏漏地连续捕获的数据包被记录到次级存储装置12。
69.并且,本实施方式所涉及的抓包方法对通信网络10中流动的数据包进行捕获,并记录到次级存储装置12,该抓包方法包括:捕获步骤s10,对以200gbps在通信网络10中流动的数据包,无疏漏地连续地进行捕获;以及记录步骤s11,将在捕获步骤s10捕获的数据包记录到次级存储装置12。捕获步骤s10中包括:第1捕获步骤s10a,对通信网络10中流动的数据包进行捕获,并将捕获的数据包存放到构成numa架构的第1numa节点23所具有的第1存储器23b;以及第2捕获步骤s10b,与第1捕获步骤s10a的捕获并行,对通信网络10中流动的数据包进行捕获,并将捕获的数据包存放到构成numa架构的第2numa节点24所具有的第2存储器24b。记录步骤s11包括:第1记录步骤s11a,将第1存储器23b中存放的数据包记录到次级存储装置12;以及第2记录步骤s11b,与第1记录步骤s11a的记录并行,将第2存储器24b中存放的数据包记录到次级存储装置12。
70.据此,通过numa架构,由于通过第1numa节点23的抓包以及数据包向次级存储装置12的记录、与通过第2numa节点24的抓包以及数据包向次级存储装置12的记录,能够按各个numa节点并行且独立地进行,因此,能够对以200gbps在通信网络流动的所有的数据包,无疏漏地连续地进行捕获,并记录到次级存储装置12。
71.以上基于实施方式对本发明所涉及的抓包装置以及方法进行了说明,本发明并非受这些实施方式所限。在不脱离本发明的主旨的范围内,将本领域技术人员所能够想到的各种变形执行于本实施方式而得到的形态、对实施方式中的一部分的构成要素进行组合而构成的其他的形态均包括在本发明的范围内。
72.本发明能够作为对通信网络中流动的数据包进行捕获并记录到次级存储装置的抓包装置来利用,并且能够作为为了应对200gbps的以太网(注册商标)中的通信障碍,而长期地对通信网络中流动的所有的数据包进行捕获的抓包装置来利用。
73.例如上述的实施方式所涉及的抓包装置20虽然具有2个numa节点,也可以具有3个以上的numa节点,并且可以对超过200gbps的通信速度的通信网络中流动的所有的数据包长期地进行捕获。例如,在将与一个numa节点对应的捕获部、numa节点以及接口部用作一个
系统的情况下,抓包装置20也可以具备3个以上的系统。
74.并且,在上述的实施方式所涉及的抓包装置20中,虽然作为用于向次级存储装置12的输入输出的接口部25而具备了raid控制器,不过并非受这种类型的控制器所限,例如也可以具备非raid控制器。
75.并且,在实施方式所涉及的抓包装置20中,虽然是针对2个numa节点,将负载分散为针对上行的数据包的捕获和针对下行的数据包的捕获,不过负载分散并非受此所限。例如,针对由能够以200gbps来捕获的一个捕获卡捕获且被暂时保存的数据包,可以以块为单位,将记录到次级存储装置12的路径分散到2个numa节点。
76.并且,本发明不仅能够作为抓包装置以及方法来实现,而且可以作为构成抓包装置20的程序(即线程以及任务)来实现,而且还可以作为记录了该程序的计算机可读取的记录介质来实现。
77.符号说明
78.10、10a、10b 通信网络
79.12、12a~12d、14 次级存储装置
80.20 抓包装置
81.21 捕获部
82.21a 第1捕获部
83.21b 第2捕获部
84.22 控制部
85.23 第1numa节点
86.23a 第1处理器
87.23b 第1存储器
88.24 第2numa节点
89.24a 第2处理器
90.24b 第2存储器
91.25 接口部
92.25a 第1接口部
93.25b 第2接口部
94.26a、26b、27a、27b raid控制器
95.30a~30c、40a~40c捕获线程
96.31、41 负载均衡
97.32a~32c、42a~42c 存储线程
98.33a~33c、43a~43c 队列
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1