一种虚拟直播系统和方法与流程
1.本发明涉及直播技术领域,特别是涉及一种虚拟直播系统和方法。
背景技术:
2.虚拟现实技术是一种可以创建和体验虚拟世界的计算机仿真系统,利用计算机生成一种模拟环境,是一种多源信息融合的交互式的三维动态视景和实体行为的系统仿真使用户沉浸到该环境中。通过虚拟现实技术,用户能够获得与在实景现场的其他用户几乎相同的环境体验。既丰富了用户获取的场景、环境信息,又大大提高了用户的体验。
3.直播技术现在广泛应用在教育、销售等领域,采集老师或者销售人员的音视频数据直播给学生或者顾客观看,现有的直播大多采用2d直播的形式进行展示,展示方式较为单一,不能满足所有的教学需求和销售展示需求,另外观看人数较多,互动信息也会相应增加,个人比较难以查看所有的互动信息,也很难从中筛选出有效信息并针对有效信息作出回应。
技术实现要素:
4.针对现有技术中存在的缺陷,本发明的目的在于提供一种虚拟直播系统和方法,解决了现有的直播大多采用2d直播的形式进行展示,展示方式较为单一,不能满足所有的教学需求和销售展示需求,另外观看人数较多,互动信息也会相应增加,个人比较难以查看所有的互动信息,也很难从中筛选出有效信息并针对有效信息作出回应的问题。
5.为了达到上述目的,本发明所采用的具体技术方案如下:
6.一种虚拟直播系统,包括音视频采集模块、ar/vr仿真模块、云端直播管理模块和直播互动管理模块;
7.所述音视频采集模块用于获取音视频数据并对视频数据进行预处理,对音频数据进行降噪处理,并将视频数据和音频数据传输至所述云端直播管理模块;
8.所述ar/vr仿真模块用于采集ar/vr图像,并传输至所述云端直播管理模块;
9.所述云端直播管理模块用于ar/vr图像叠加至所述视频数据上,封装成带有ar/vr图像的ts流媒体,并传输至用户端进行直播;
10.所述直播互动管理模块用于获取用户端发出的互动信息,通过人工智能学习训练得到互动信息处理模型,将互动信息输入互动信息处理模型,输出处理后的互动信息,并根据处理后的互动信息反馈对应的音视频数据或者ar/vr图像或者自定义回复模板给用户端。
11.作为本发明优选的一种虚拟直播系统,所述直播互动管理模块用于获取用户端发出的互动信息具体指的是所述直播互动管理模块用于获取用户端发出的评论信息和/或弹幕信息。
12.作为本发明优选的一种虚拟直播系统,通过人工智能学习训练得到互动信息处理模型,将互动信息输入互动信息处理模型,输出处理后的互动信息,具体指的是
13.利用语义信息训练样本和语义信息规则样本对人工神经网络模型进行学习训练得到用于识别语义的互动信息处理模型,将互动信息输入互动信息处理模型,输出互动信息及其重复次数。
14.作为本发明优选的一种虚拟直播系统,通过人工智能学习训练得到互动信息处理模型,将互动信息输入互动信息处理模型,输出处理后的互动信息,具体指的是
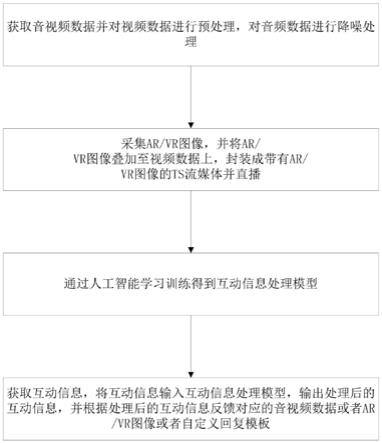
15.利用语义信息训练样本和语义信息规则样本对人工神经网络模型进行学习训练得到用于识别语义的互动信息处理模型,将互动信息输入互动信息处理模型,输出互动信息的语义识别结果。
16.一种虚拟直播方法,具体包括以下步骤:
17.s1,获取音视频数据并对视频数据进行预处理,对音频数据进行降噪处理;
18.s2,采集ar/vr图像,并将ar/vr图像叠加至视频数据上,封装成带有ar/vr图像的ts流媒体并直播;
19.s3,通过人工智能学习训练得到互动信息处理模型;
20.s4,获取互动信息,将互动信息输入互动信息处理模型,输出处理后的互动信息,并根据处理后的互动信息反馈对应的音视频数据或者ar/vr图像或者自定义回复模板。
21.作为本发明优选的一种虚拟直播方法,步骤s4中的互动信息包括但不限于文字评论和文字弹幕。
22.作为本发明优选的一种虚拟直播方法,步骤s3通过人工智能学习训练得到互动信息处理模型具体指的是利用语义信息训练样本和语义信息规则样本对人工神经网络模型进行学习训练得到用于识别语义的互动信息处理模型。
23.作为本发明优选的一种虚拟直播方法,步骤s4中反馈对应的音视频数据具体指的是在原有窗口上增加悬浮窗口的形式播放音视频数据。
24.本发明的有益效果在于:封装成带有ar/vr图像的ts流媒体,并传输至用户端进行直播,通过人工智能学习训练得到互动信息处理模型,将互动信息输入互动信息处理模型,输出处理后的互动信息,并根据处理后的互动信息反馈对应的音视频数据或者ar/vr图像或者自定义回复模板给用户端,实现了对互动信息的自动化处理,解决了现有的直播大多采用2d直播的形式进行展示,展示方式较为单一,不能满足所有的教学需求和销售展示需求,另外观看人数较多,互动信息也会相应增加,个人比较难以查看所有的互动信息,也很难从中筛选出有效信息并针对有效信息作出回应的问题。
附图说明
25.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
26.图1是本发明实施例提供的一种虚拟直播系统的结构示意图;
27.图2是本发明实施例提供的一种虚拟直播方法的流程图。
具体实施方式
28.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的其他实施例,都属于本发明保护的范围。
29.在本发明的描述中,需要说明的是,术语“竖直”、“上”、“下”、“水平”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制。
30.在本发明的描述中,还需要说明的是,除非另有明确的规定和限定,术语“设置”、“安装”、“相连”、“连接”应做广义理解,例如,可以是固定连接,也可以是可拆卸连接,或一体地连接;可以是机械连接,也可以是电连接;可以是直接相连,也可以通过中间媒介间接相连,可以是两个元件内部的连通。对于本领域的普通技术人员而言,可以根据具体情况理解上述术语在本发明中的具体含义。
31.如图1所示,本发明提出了一种虚拟直播系统,包括音视频采集模块、ar/vr仿真模块、云端直播管理模块和直播互动管理模块;
32.所述音视频采集模块用于获取音视频数据并对视频数据进行预处理,对音频数据进行降噪处理,并将视频数据和音频数据传输至所述云端直播管理模块;
33.所述ar/vr仿真模块用于采集ar/vr图像,并传输至所述云端直播管理模块;
34.所述云端直播管理模块用于ar/vr图像叠加至所述视频数据上,封装成带有ar/vr图像的ts流媒体,并传输至用户端进行直播;
35.所述直播互动管理模块用于获取用户端发出的互动信息,通过人工智能学习训练得到互动信息处理模型,将互动信息输入互动信息处理模型,输出处理后的互动信息,并根据处理后的互动信息反馈对应的音视频数据或者ar/vr图像或者自定义回复模板给用户端。
36.具体的,音视频采集模块可以用于采集老师或者销售主播的音视频数据,音视频采集模块包括摄像头、麦克风和音视频处理主机,摄像头、麦克风用于获取同步的音视频数据,音视频处理主机用于将获取的音视频数据进行初步处理,初步处理包括但不限于对音频数据和视频数据进行压缩处理,压缩后同步处理。音频数据的压缩参数为压缩类型,采样频率,单点位深,声道数目等等,视频数据的压缩参数为采集源,尺寸,颜色深度,采集帧率,压缩格式等等,音视频处理主机运行压缩函数,摄像头和麦克风将采集到的的音视频数据传递给压缩函数。视频编码器对采集到的视频帧进行运动图像压缩以减小网络传输的数据量,音频编码器通过设定的编码格式进行编码,同样地减小网络传输的数据量,加快直播数据的传播速度。
37.音视频处理主机运行压缩函数的过程中,还可为不同用户端绘制相应的用户画像,并根据用户画像设置对应的压缩参数,用户使用频率越高,压缩参数越符合用户的喜好。
38.ar/vr图像具体指的是帮助教学或者展示销售产品的ar/vr图像,ar/vr仿真模块可以用于产生或者获取ar/vr图像,其可以为带有ar/vr图像产生软件、获取图像的摄像头
和数据通信芯片的智能终端。教学或者展示销售产品的过程中,大部分场景是固定的,ar/vr图像与教学内容和产品相关。
39.在具体实施过程中,云端直播管理模块还可用于根据ts流媒体的内容(老师授课的知识点或者销售主播介绍的产品)进行分割,并为分割后的ts流媒体添加关键词标签,用户端可根据关键词标签查看对应的ts流媒体,与直播互动管理模块进行互动,获取对应的音视频数据或者ar/vr图像。
40.ar/vr图像产生软件可采用unity3d,unity3d是由unity technologies开发的一个让玩家轻松创建诸如ar与vr内容、建筑可视化、实时三维动画、三维视频游戏等类型互动内容的多平台的综合型开发工具。利用unity3d实现ar与vr场景,可以为用户提供更加逼真生动的感受。
41.云端直播管理模块和直播互动管理模块均基于云端服务器运行,实现相应的功能。
42.作为本发明优选的一种虚拟直播系统,所述直播互动管理模块用于获取用户端发出的互动信息具体指的是所述直播互动管理模块用于获取用户端发出的评论信息和/或弹幕信息。
43.作为本发明优选的一种虚拟直播系统,通过人工智能学习训练得到互动信息处理模型,将互动信息输入互动信息处理模型,输出处理后的互动信息,具体指的是
44.利用语义信息训练样本和语义信息规则样本对人工神经网络模型进行学习训练得到用于识别语义的互动信息处理模型,将互动信息输入互动信息处理模型,输出互动信息及其重复次数。
45.在该实施例中,若用于教学,直播互动管理模块用于获取学生在直播学习过程中发出的互动信息,将互动信息分类为文字信息、表情信息、数字信息,从文字信息中剔除与直播学习无关的信息,从而获取有效的文字信息,输出有效的提问信息的重复次数,显示提问信息的重复次数。在直播学习的问题解答过程中,教师对显示的提问信息进行解答和答复,解答完毕后手动删除显示的提问信息或者移动终端获取教师的解答语音,从解答语音中提取关键词,将关键词与提问信息进行匹配,匹配成功后自动删除对应的提问信息,直至所有的提问信息已经回复完毕。
46.在该实施例中,若用于直播销售,直播互动管理模块用于获取顾客在销售主播在直播过程中发出的评论和弹幕,可以多少顾客对几号产品感兴趣,销售主播可以根据顾客对产品的感兴趣程度实时改变介绍产品的顺序。
47.作为本发明优选的一种虚拟直播系统,通过人工智能学习训练得到互动信息处理模型,将互动信息输入互动信息处理模型,输出处理后的互动信息,具体指的是
48.利用语义信息训练样本和语义信息规则样本对人工神经网络模型进行学习训练得到用于识别语义的互动信息处理模型,将互动信息输入互动信息处理模型,输出互动信息的语义识别结果。
49.在该实施例中,获得互动信息的语义识别结果后,可以反馈对应的音视频数据或者ar/vr图像或者自定义回复模板。
50.如图2所示,本发明还提出了一种虚拟直播方法,具体包括以下步骤:
51.s1,获取音视频数据并对视频数据进行预处理,对音频数据进行降噪处理;
52.s2,采集ar/vr图像,并将ar/vr图像叠加至视频数据上,封装成带有ar/vr图像的ts流媒体并直播;
53.s3,通过人工智能学习训练得到互动信息处理模型;
54.s4,获取互动信息,将互动信息输入互动信息处理模型,输出处理后的互动信息,并根据处理后的互动信息反馈对应的音视频数据或者ar/vr图像或者自定义回复模板。
55.步骤s1中获取音视频数据并对视频数据进行预处理,具体指的是摄像头、麦克风用于获取同步的音视频数据,音视频处理主机用于将获取的音视频数据进行初步处理,初步处理包括但不限于对音频数据和视频数据进行压缩处理,压缩后同步处理。音频数据的压缩参数为压缩类型,采样频率,单点位深,声道数目等等,视频数据的压缩参数为采集源,尺寸,颜色深度,采集帧率,压缩格式等等,音视频处理主机运行压缩函数,摄像头和麦克风将采集到的的音视频数据传递给压缩函数。视频编码器对采集到的视频帧进行运动图像压缩以减小网络传输的数据量,音频编码器通过设定的编码格式进行编码,同样地减小网络传输的数据量,加快直播数据的传播速度。
56.步骤s2中ar/vr图像具体指的是帮助教学或者展示销售产品的ar/vr图像,ar/vr图像由带有ar/vr图像产生软件、获取图像的摄像头和数据通信芯片的智能终端产生或者采集。
57.ar/vr图像产生软件可采用unity3d,unity3d是由unity technologies开发的一个让玩家轻松创建诸如ar与vr内容、建筑可视化、实时三维动画、三维视频游戏等类型互动内容的多平台的综合型开发工具。利用unity3d实现ar与vr场景,可以为用户提供更加逼真生动的感受。
58.作为本发明优选的一种虚拟直播方法,步骤s4中的互动信息包括但不限于文字评论和文字弹幕。
59.作为本发明优选的一种虚拟直播方法,步骤s3通过人工智能学习训练得到互动信息处理模型具体指的是利用语义信息训练样本和语义信息规则样本对人工神经网络模型进行学习训练得到用于识别语义的互动信息处理模型。
60.在该实施例的基础上,还可统计相同语义的互动信息的数量,若用于教学,获取学生在直播学习过程中发出的互动信息,将互动信息分类为文字信息、表情信息、数字信息,从文字信息中剔除与直播学习无关的信息,从而获取有效的文字信息,输出有效的提问信息的重复次数,显示提问信息的重复次数。在直播学习的问题解答过程中,教师对显示的提问信息进行解答和答复,解答完毕后手动删除显示的提问信息或者移动终端获取教师的解答语音,从解答语音中提取关键词,将关键词与提问信息进行匹配,匹配成功后自动删除对应的提问信息,直至所有的提问信息已经回复完毕。在直播销售过程中,获取顾客在销售主播在直播过程中发出的评论和弹幕,可以多少顾客对几号产品感兴趣,销售主播可以根据顾客对产品的感兴趣程度实时改变介绍产品的顺序。
61.作为本发明优选的一种虚拟直播方法,步骤s4中反馈对应的音视频数据具体指的是在原有窗口上增加悬浮窗口的形式播放音视频数据。
62.本发明的有益效果在于:封装成带有ar/vr图像的ts流媒体,并传输至用户端进行直播,通过人工智能学习训练得到互动信息处理模型,将互动信息输入互动信息处理模型,输出处理后的互动信息,并根据处理后的互动信息反馈对应的音视频数据或者ar/vr图像
或者自定义回复模板给用户端,实现了对互动信息的自动化处理,解决了现有的直播大多采用2d直播的形式进行展示,展示方式较为单一,不能满足所有的教学需求和销售展示需求,另外观看人数较多,互动信息也会相应增加,个人比较难以查看所有的互动信息,也很难从中筛选出有效信息并针对有效信息作出回应的问题。
63.以上述依据本发明的理想实施例为启示,通过上述的说明内容,本领域技术人员完全可以在不偏离本发明技术思想的范围内,进行多样的变更以及修改。本发明的技术性范围并不局限于说明书上的内容,必须要根据权利要求书范围来确定其技术性范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1