基于监督学习的多普勒扩展估计的制作方法
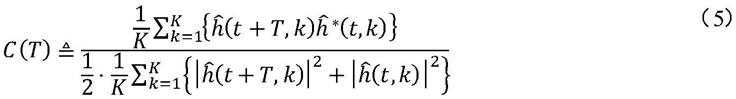
基于监督学习的多普勒扩展估计
1.本技术要求于2020年4月3日向美国专利商标局提交的美国临时专利申请no.63/004,894的优先权和权益,其全部公开内容通过引用并入本文。
技术领域
2.本公开的实施例的各方面涉及无线通信和基于监督学习的多普勒扩展估计。
背景技术:
3.在无线通信领域中,无线电收发机监测通信信道的特性,以便适应电磁环境中的变化的信号传播条件。这些特性通常被称为信道状态信息(csi),并且可包括诸如散射、衰落、功率衰减和多普勒扩展的效应。无线电收发机的信道估计(ce)块可用于估计接收到的无线电收发机的工作频率范围内的无线电信号的各种信道的csi。
4.在无线通信领域中,当无线电发射机和无线电接收机相对于彼此移动时,无线电接收机可接收多普勒频移版本的发送信号。例如,在蜂窝陆地移动无线电系统的情况下,基站(例如,蜂窝塔)通常是固定的,而与基站通信的一个或更多个移动站(例如,智能电话)可以是静止的或移动的。通常,当移动站朝向基站移动时,接收信号的频率将被上移(增大),并且当移动站远离基站移动时,接收信号的频率将被下移(降低)。例如,当移动站在快速移动的汽车中时,观察到的多普勒频移f
d
的幅度通常大于当移动站被搁在办公室的桌面上时的多普勒频移的幅度。由于多普勒频移的变化率引起的发送信号的频谱的加宽被称为多普勒扩展d
s
。
5.多普勒扩展通常用于无线电的信道估计块中的时间插值以及一些软件控制,作为用于无线电的系统的一部分以使传输适应当前信道条件以便实现可靠的通信。
技术实现要素:
6.本公开的实施例的各方面涉及用于基于监督机器学习来估计多普勒扩展的系统和方法。
7.根据本公开的一个实施例,一种用于估计无线信道的多普勒扩展的方法包括:由无线电接收机的处理电路从接收信号提取一个或更多个特征,其中,所述一个或更多个特征包括当前时隙中的估计的信道相关性,所述估计的信道相关性指示所述无线信道随时间的变化率;以及由所述处理电路通过将所述一个或更多个特征提供给在跨训练信噪比(snr)范围且跨训练多普勒频移范围的训练数据上训练的一个或更多个多普勒频移预测器来计算所述无线信道的多普勒扩展,其中,每个多普勒频移预测器是在与所述训练数据的不同部分相应的一部分训练数据上被训练的。所述估计的信道相关性可包括单个经无限脉冲响应滤波的信道相关性。
8.所述一个或更多个特征可包括基于一个或更多个先前时隙中的一个或更多个参考信号的一个或更多个估计的信道相关性。
9.所述参考信号可以是跟踪参考信号。
10.所述一个或更多个多普勒频移预测器中的每个多普勒频移预测器可基于所述训练snr范围的不同子范围被训练,每个子范围具有下限和上限,并且所述方法还可包括:确定所述接收信号的当前snr;以及基于所述当前snr从所述一个或更多个多普勒频移预测器中选择多普勒频移预测器,其中,所选择的多普勒频移预测器的相应子范围的下限高于所述当前snr。
11.所选择的多普勒频移预测器的相应子范围的下限在高于所述当前snr的子范围的下限中可最接近于所述当前snr。
12.所述一个或更多个多普勒频移预测器中的每个多普勒频移预测器可基于所述训练多普勒频移范围的不同子范围被训练,并且所述方法还可包括:由所述处理电路通过将所述一个或更多个特征提供给多普勒频移分类器网络来计算一个或更多个分类概率,其中,所述一个或更多个分类概率中的每个分类概率与所述一个或更多个多普勒频移预测器中的不同多普勒频移预测器相应,所述一个或更多个特征可被提供给所述一个或更多个多普勒频移预测器以计算一个或更多个预测多普勒频移,并且计算所述多普勒扩展的步骤可包括:根据所述一个或更多个分类概率对所述一个或更多个预测多普勒频移进行组合。
13.对所述一个或更多个预测多普勒频移进行组合的步骤可包括:对所述一个或更多个预测多普勒频移乘以所述一个或更多个分类概率中的相应分类概率的一个或更多个乘积进行求和。
14.对所述一个或更多个预测多普勒频移进行组合的步骤可包括:输出所述一个或更多个预测多普勒频移中的与所述一个或更多个分类概率中的最高分类概率相应的最高概率的预测多普勒频移。
15.所述训练数据的训练snr范围可大于所述无线电接收机的工作snr范围。
16.所述一个或更多个多普勒频移预测器中的每个多普勒频移预测器可被训练为基于回归模型计算预测多普勒频移。
17.所述一个或更多个多普勒频移预测器中的每个多普勒频移预测器可被训练为通过计算所述一个或更多个特征与多普勒频移的一个或更多个范围中的每个范围相应的一个或更多个概率来对所述一个或更多个特征进行分类。
18.所述一个或更多个多普勒频移预测器中的每个多普勒频移预测器可以是多层感知机(mlp)。
19.根据本公开的一个实施例,一种无线电接收机包括信道估计器处理电路,其中,所述信道估计器处理电路包括:特征提取器,被配置为从接收信号提取一个或更多个特征,其中,所述一个或更多个特征包括当前时隙中的估计的信道相关性,所述估计的信道相关性指示无线信道随时间的变化率;以及多普勒扩展估计器,被配置为通过将所述一个或更多个特征提供给在跨训练信噪比(snr)范围且跨训练多普勒频移范围的训练数据上训练的一个或更多个多普勒频移预测器来估计所述无线信道的多普勒扩展,其中,每个多普勒频移预测器是在与所述训练数据的不同部分相应的一部分训练数据上被训练的。所述估计的信道相关性可包括单个经无限脉冲响应滤波的信道相关性。
20.所述一个或更多个特征可包括基于一个或更多个先前时隙中的一个或更多个参考信号的一个或更多个估计的信道相关性。
21.所述参考信号可以是跟踪参考信号。
22.所述一个或更多个多普勒频移预测器中的每个多普勒频移预测器可基于所述训练snr范围的不同子范围被训练,每个子范围具有下限和上限,并且所述信道估计器处理电路还可包括:snr提取器,被配置为提取所述接收信号的当前snr;以及预测器选择器,被配置为基于所述当前snr从所述一个或更多个多普勒频移预测器中选择多普勒频移预测器,其中,所选择的多普勒频移预测器的相应子范围的下限高于所述当前snr。
23.所选择的多普勒频移预测器的相应子范围的下限在高于所述当前snr的子范围的下限中可最接近于所述当前snr。
24.所述一个或更多个多普勒频移预测器中的每个多普勒频移预测器可基于所述训练多普勒频移范围的不同子范围被训练,并且所述多普勒扩展估计器可包括多普勒频移分类器网络,其中,所述多普勒频移分类器网络被配置为计算输入特征属于与所述一个或更多个多普勒频移预测器相应的类别的一个或更多个分类概率,所述多普勒扩展估计器可被配置为将所述一个或更多个特征提供给所述一个或更多个多普勒频移预测器以计算一个或更多个预测多普勒频移,并且所述多普勒扩展估计器可被配置为通过根据所述一个或更多个分类概率对所述一个或更多个预测多普勒频移进行组合来计算所述多普勒扩展。
25.所述多普勒扩展估计器可被配置为通过对所述一个或更多个预测多普勒频移乘以所述一个或更多个分类概率中的相应分类概率的一个或更多个乘积进行求和来对所述一个或更多个预测多普勒频移进行组合。
26.所述多普勒扩展估计器可被配置为通过输出所述一个或更多个预测多普勒频移中的与所述一个或更多个分类概率中的最高分类概率相应的最高概率的预测多普勒频移来对所述一个或更多个预测多普勒频移进行组合。
27.所述训练数据的训练snr范围可大于所述无线电接收机的工作snr范围。
28.所述一个或更多个多普勒频移预测器中的每个多普勒频移预测器可被训练为基于回归模型计算预测多普勒频移。
29.所述一个或更多个多普勒频移预测器中的每个多普勒频移预测器可被训练为通过计算所述一个或更多个特征与多普勒频移的一个或更多个范围中的每个范围相应的一个或更多个概率来对所述一个或更多个特征进行分类。
30.所述一个或更多个多普勒频移预测器中的每个多普勒频移预测器可以是多层感知机。
附图说明
31.附图与说明书一起示出了本公开的示例性实施例,并且与描述一起用于解释本公开的原理。
32.图1是移动站的示意框图。
33.图2是基站向移动站发送信号的无线通信系统的示意框图。
34.图3是根据本公开的一个实施例的多普勒扩展预测器的框图。
35.图4是比较当使用贝塞尔函数或当使用根据本公开的实施例的多层感知机作为映射函数时的信道相关性和多普勒频移之间的关系的曲线图。
36.图5是根据本公开的一个实施例的多普勒频移估计器的框图。
37.图6是示出根据本公开的一个实施例的用于使用一个或更多个多普勒频移预测器
估计多普勒扩展的方法的流程图。
38.图7a是示出根据本公开的一个实施例的用于在两个不同多普勒频移预测器之间选择一个多普勒频移预测器的方法的流程图。
39.图7b是示出根据本公开的一个实施例的用于在一个或更多个不同多普勒频移预测器之间选择至少一个多普勒频移预测器的方法的流程图。
40.图8是根据本公开的一个实施例的多普勒频移估计器的框图,其中,该多普勒频移估计器被配置成通过组合来自一个或更多个多普勒频移预测器的预测来估计多普勒频移。
41.图9是根据本公开的一个实施例的多普勒频移估计器的框图,其中,该多普勒频移估计器被配置为通过根据多普勒频移预测器中的置信度组合来自一个或更多个多普勒频移预测器的预测来估计多普勒频移。
42.图10是根据本公开的一个实施例的使用iir滤波器来组合一个或更多个信道相关性的多普勒频移预测器的示意图。
43.图11是根据本公开的一个实施例的多普勒频移预测器的示意图,其中,在该多普勒频移预测器中,来自trs时隙的窗口的一个或更多个信道相关性作为输入被提供给多层感知机。
具体实施方式
44.在以下详细描述中,通过说明的方式仅示出和描述了本公开的某些示例性实施例。如本领域技术人员将认识到的,本公开可以以许多不同的形式实现,并且不应被解释为限于本文阐述的实施例。
45.为了清楚起见,本文将在蜂窝调制解调器的无线电收发机的上下文中描述本公开的实施例的各方面。然而,本公开的实施例不限于此,并且本领域普通技术人员在本技术的有效申请日之前将理解,本公开的实施例也可应用于在其他上下文中估计多普勒扩展。
46.在一些无线电传输标准(诸如5g新无线电(nr)标准)中,蜂窝无线电收发机可使用从基站接收到的跟踪参考信号(trs)来估计多普勒扩展d
s
。例如,一种技术计算与两个跟踪参考信号相应的信道之间的估计的信道相关性,然后将估计的信道相关性提供给逆贝塞尔函数以获得多普勒扩展d
s
。
47.然而,该方法假设信道相关性和多普勒扩展之间的关系遵循逆贝塞尔函数。实际上,信道并不总是在信道相关性和多普勒扩展之间呈现逆贝塞尔函数关系。另外,当计算信道相关性时,需要从信道功率中去除噪声功率,因此信道相关性的估计的准确度对噪声方差的估计敏感。此外,在一些情况下,每trs周期可能仅存在一个trs时隙(两个trs符号(symbol)),因此仅一个相关值可用于多普勒扩展估计,从而导致多普勒扩展估计的低分辨率。例如,在5g nr标准下,当在fr2(频率范围2,包括24ghz至100ghz的毫米波范围中的频段)工作时,每trs周期可能仅发送1个trs时隙。
48.因此,本公开的实施例的各方面涉及使用机器的监督学习来估计多普勒扩展。更详细地,本公开的实施例的一些方面涉及使用监督学习(例如,使用诸如多层感知机(mlp)神经网络或其他神经网络的机器学习模型)来学习从估计的信道相关性到多普勒扩展的映射函数(或“多普勒扩展预测器”),其中,该映射函数是在收集的将信道相关性与多普勒扩展相关的实验数据上训练的。在在线预测期间,估计的相关性被提供给学习出的映射函数
(多普勒扩展预测器)以生成估计的多普勒扩展。
49.根据本公开的实施例的映射函数(或多普勒扩展预测器)是根据从运行的无线电通信系统收集的数据被训练的,并且因此匹配这些工作系统的实际行为,而不是依赖于关于运行环境和那些系统的行为的特定假设。另外,给定足够大且多样化的训练数据集,根据本公开的实施例的经过训练的多普勒扩展预测器能够在不同工作条件的范围(例如,在训练信噪比(snr)范围上扩展的不同snr)上总结并产生多普勒扩展的稳健(例如,准确)估计,从而使得本公开的实施例能够补偿噪声方差。根据本公开的实施例的一些方面,多普勒扩展预测器还利用一个或更多个先前估计的信道相关性(例如,来自先前的trs周期)来改进当前trs周期处的多普勒扩展的估计。
50.图1是移动站的示意框图。如图1所示,移动站10可包括被配置为接收(例如,由基站发送的)电磁信号30的天线11。所接收的信号可被提供给接收滤波器12(例如,带通滤波器),并且经滤波的信号可被提供给检测器14和信道估计器16。信道估计器16可生成用于控制检测器14以及移动站10的其他组件的信道状态信息(csi),以适应环境中的变化的条件,诸如移动站10相对于基站的移动和/或电磁信号30传播所经过的环境中的变化。根据本公开的一些实施例,信道估计器16与多普勒扩展估计器100通信或包括多普勒扩展估计器100。信道估计器16的输出(可包括多普勒扩展估计器100的输出或者可包括基于多普勒扩展估计器的输出计算的信息)被提供给使用信道估计来执行符号检测的检测器14。解码器18可被配置为从检测器14接收检测到的符号,并且将检测到的符号解码为数据50(诸如数字比特流),以供移动站10中的应用(诸如语音呼叫、数据分组等)消费。在本公开的各种实施例中,移动站10的组件(诸如滤波器12、检测器14、信道估计器16、多普勒扩展估计器100和解码器18)可在数字无线电的一个或更多个处理电路(例如,无线电基带处理器(bp或bpp)、中央处理器(cpu)、微控制器、数字信号处理器(dsp)、现场可编程门阵列(fpga)或专用集成电路(as ic))中实现,其中,各种块的各个部分可在同一电路(例如,在相同的管芯上或在相同的封装中)中实现,或可在不同的电路(例如,在不同的管芯上或在不同的封装中,通过通信总线连接)中实现。
51.图2是基站20向移动站10发送信号30的通信系统的示意性框图,其中,移动站10包括多普勒扩展估计器100。由移动站10接收的信号中的多普勒频移的幅度可取决于移动站10相对于基站20的相对运动(例如,速度),并且因此由基站20接收的信号中的多普勒扩展也可取决于移动站10相对于基站20的相对运动。
52.如上所述,一些比较系统基于信道统计遵循jakes模型的假设,使用逆贝塞尔函数从估计的信道相关性计算多普勒扩展。例如,基于jakes模型,信道自相关函数具有等式1的形式:
53.r(τ,f
d
)=j0(2πf
d
τ)
ꢀꢀ
(1)
54.其中,τ表示时间差,f
d
表示最大多普勒频移,如下面在等式2中所定义的:
[0055][0056]
其中,c表示光速,f表示发送信号30的频率,v是移动站10的速度。形式上,多普勒扩展被定义为d
s
=f
d
‑
(
‑
f
d
)=2f
d
。如本文所使用的,术语多普勒扩展估计与最大多普勒频移估计可互换地使用,两者都表示上述f
d
的估计。j0(
·
)表示第一类零阶贝塞尔函数,如等
式3所示:
[0057][0058]
注意,上述信道自相关函数r(τ,f
d
)是基于假设jakes信道模型推导出的,因此,当使用逆贝塞尔函数来描述信道相关性和多普勒频移f
d
之间的关系时,隐含地假设jakes信道模型。该jakes信道模型假设对于一些类型的信道模型(诸如扩展行人a模型(epa)、扩展车辆a模型(eva)、扩展典型城市模型(etu)和抽头延迟线(tdl)模型)可能是有效的,但是对于一些其他类型的信道模型(例如,集群延迟线(cdl)模型)可能是无效的。实际上,由于例如信道相关性的非理想估计,逆贝塞尔函数可能无法准确地描述所估计的信道相关性与多普勒扩展之间的关系。例如,实际上,参考信号元素的数量可能不足以计算信道相关性的准确平均值,或者噪声方差计算可能太不准确。
[0059]
图3是根据本公开的一个实施例的多普勒扩展估计器100的框图。如图3所示,根据本公开的一个实施例,多普勒扩展估计器100被配置为接收输入估计信道。特征提取器110被配置为从提供的信道中提取特征,其中,特征可包括例如估计的信道相关性。所提取的特征被提供给经过训练的多普勒频移预测器120,其中,经过训练的多普勒频移预测器120被配置为基于所提取的特征来计算估计的多普勒频移300值。根据本公开的实施例的经过训练的多普勒频移预测器120是根据从真实的物理系统或实际链路级仿真器收集的训练数据构造的,并且因此可被训练为比逆贝塞尔函数更准确地对系统的行为进行建模。
[0060]
根据本公开的一些实施例,特征提取器110被配置为从输入估计信道中提取特征。特定特征包括从输入估计信道的各种特性解码或计算的信息。在本公开的一些实施例中,特征提取器110被配置为从输入估计信道提取信道相关性c(t)。可基于接收信号中的一个或更多个trs时隙的trs信号来计算这些信道相关性。通常,估计的信道的信道相关性c(t)由等式4给出:
[0061][0062]
其中,表示在符号时间t和子载波k处估计的信道,σ2表示包含在估计的信道中的噪声方差,γ∈[0,1]是用于调整减去多少噪声的可配置参数。t表示trs时隙内或跨两个trs时隙的两个trs符号之间的时间差。如果给每trs周期分配两个trs时隙,则可在给定trs时隙内的或者跨两个连续trs时隙的trs符号对之间计算信道相关性。
[0063]
实际上,可能难以准确地估计噪声方差σ2,并且也可能难以为噪声减参数γ选择适当的值。根据本公开的一些实施例,γ被设置为0(零)以消除噪声方差估计的影响。此外,在一些情况下,使用样本平均值来实现期望运算e{
·
}更实用。因此,在本公开的一些实施例中,根据等式5实现信道相关性c(t):
[0064][0065]
其中,k是子载波的数量。
[0066]
除了基于当前trs时隙的trs符号来计算当前信道相关性之外,特征提取器110还
可计算附加特征。例如,在本公开的一些实施例中,特征提取器110进一步基于从先前trs周期估计的信道相关性来计算特征(例如,特征提取器110可包括存储先前针对较早trs周期计算的信道相关性的窗口的存储器)。
[0067]
根据本公开的一些实施例,基于来自运行的无线通信系统或来自实际链路级仿真器的实际测量数据来训练多普勒扩展预测器。因此,在本公开的一些实施例中,训练数据可包括从具有各种不同参数(诸如信噪比(snr)、信道(例如,epa、eva、tdl
‑
a、tdl
‑
d)、数字端口配置(例如,1x2、1x4、1x8)、模拟天线配置(例如,2、4、8)、多普勒频移f
d
、调制编码方案(mcs)、子载波间隔(scs)和快速傅里叶变换(fft)大小)的发射机和接收机之间的传输捕获的数据。对于这些参数的每个具体组合(例如,对于每个具体的传输设置集合),在传输期间记录训练数据。训练数据中的每个样本包括输入和输出,其中,输入包括由特征提取器110提取的特征,并且输出包括发生传输的多普勒频移f
d
(例如,在运行的系统的情况下测量的多普勒频移f
d
或在仿真器的情况下配置的多普勒频移f
d
)。最终训练数据集包含不同参数的各种组合下从传输收集的大量训练数据。
[0068]
多普勒频移预测器120可包括神经网络(例如,多层感知机(mlp)、递归神经网络(rnn)、长短期记忆(lstm)网络等)或其他形式的机器学习模型。为了说明的目的,将关于使用多层感知机(mlp)作为机器学习模型来更详细地描述本公开的实施例,但是本公开的实施例不限于此。
[0069]
当应用监督学习时,通常通过调整模型的多个参数(例如,神经网络的神经元之间的连接的权重)来训练机器学习模型,以最小化由模型基于模型的输入(例如,由特征提取器110从输入估计信道提取的特征)计算的值与地面真值(例如,与信道h相关联的测量或配置的多普勒频移f
d
)之间的代价函数。在神经网络的情况下,训练过程可包括应用具有梯度下降的反向传播算法来迭代地更新模型的参数以最小化代价函数。
[0070]
所收集的训练数据包含成对的许多数据样本,其中,每对包含一些输入(例如,c(t)(或一些其他输入特征))以及输出(地面真实多普勒扩展f
d
)。在多普勒频移预测器120(例如,多层感知机)的离线训练期间,多普勒频移预测器120被训练为将输入(例如,由特征提取器110从信号提取的信道相关性c(t))映射到输出(地面真实多普勒扩展f
d
)。在在线预测期间(例如,当多普勒频移预测器120被部署在移动站10中用于计算信道状态信息时),计算当前信道相关性c(t)并将c(t)输入到多普勒频移预测器120以计算估计的多普勒扩展
[0071]
更详细地,当在学习框架内考虑时,至少因为估计的多普勒频移f
d
是单个连续值,多普勒扩展估计可被公式化为回归问题。因此,当将多普勒频移预测器100的训练视为回归问题时,可通过最小化关于参数θ的平方和误差来执行基于回归模型训练机器学习模型的优化过程,如方程式6所示:
[0072][0073]
其中,多普勒扩展预测函数可被表示为f
θ
,θ表示多普勒扩展预测函数的学习参数,输入特征被表示为g和真实多普勒扩展被表示为f
d
。在上文中,假设训练数据集包含n对输入/输出对{g
n
,f
d,n
},n=1,...,n。
[0074]
然而,多普勒扩展可跨越宽范围,可能在fr2(例如,毫米波频率)达到数千赫兹。因此,估计的多普勒频移f
d
也可跨越宽范围,例如,f
d
∈[0,2000]。如果机器学习模型的训练基于求解上述平方和误差最小化函数,则与小多普勒扩展相应的训练样本将被削弱,这是因为针对小f
d,n
的误差(f
θ
(g
n
)
‑
f
d,n
)2通常小于针对大f
d,n
的误差(f
θ
(g
n
)
‑
f
d,n
)2。当真实多普勒扩展小时,这将导致非常不准确的多普勒扩展估计。
[0075]
因此,在本公开的一些实施例中,可通过最小化关于参数θ的归一化的平方和误差来执行基于回归模型训练机器学习模型的过程,如方程式7所示:
[0076][0077]
通过使用上述归一化的平方和误差作为代价函数,与大多普勒扩展相应的训练样本将被削弱,因为误差(f
θ
(g
n
)
‑
f
d,n
)2除以因此使针对大f
d,n
的代价更小(例如,代价函数相对于f
d,n
被归一化)。
[0078]
在本公开的一些实施例中,通过将多普勒扩展范围量化为多个小区域或范围,多普勒扩展预测被视为分类问题,而不是回归问题。多普勒扩展的每个区域被认为是一个类别,并且由单个多普勒扩展(例如,该区域的中值多普勒扩展)表示。然后训练多普勒扩展预测器以将输入特征g映射到每个类别的概率或置信度(例如,计算多个概率,其中,每个概率表示输入特征映射到多普勒扩展的多个区域中的相应一个区域的置信度)。在一些实施例中,随后通过基于每个类别的概率组合表示每个类别的多普勒扩展来计算最终多普勒扩展估计,如下面更详细地讨论的。
[0079]
下面的表1呈现了将多普勒频移范围划分为m个不同类别的一个示例。更详细地,假设训练数据的多普勒频移的整个范围是f
d
∈[r0,r
m
],则该整个范围可被划分为针对总共m个类别的m个非重叠的连续区域。例如,第m个区域与多普勒频移范围[r
m
‑1,r
m
)相应。每个类别由相应的多普勒频移表示,其中m=1,
…
,m,其中,)。当准备训练数据集时,与每个训练数据样本相关联的多普勒频移(例如,f
d,n
)被分箱到所述m个区域中的相应一个区域中(例如,找到第m个区域,使得f
d,n
∈[r
m
‑1,r
m
)),使得该训练样本将被分类为类别m。在训练期间,交叉熵被用作代价函数。
[0080]
表1
[0081][0082][0083]
给定输入特征,被训练为分类器的多普勒频移预测器将输出满足
的m维向量[c1,...,c
m
]
t
,其中,c
m
表示输入特征属于类别m的概率(或置信度)。代价函数可表示如下,其中,由系数θ表征的映射函数或多普勒频移预测器f
θ
将第n个训练数据样本的输入特征g
n
映射到m维向量[c
n,1
,c
n,2
,...,c
n,m
],第n个训练数据属于类别v
n
,使得如方程式8所示:
[0084][0085]
当执行推断或预测时,被训练为分类器的多普勒频移预测器生成针对m个类别c1,...,c
m
中的每个类别的预测概率。给定每个类别的代表性多普勒频移最终的多普勒频移估计可通过基于每个代表性多普勒频移乘以其相应的预测概率的乘积之和计算的“平均组合”来获得,如等式9所示:
[0086][0087]
或通过选择与最高预测概率相应的代表性多普勒扩展的“最大组合”来表示,如等式10所示:
[0088][0089]
其中,i(
·
)表示如等式11所示的指示函数:
[0090]
i(true)=1
ꢀꢀꢀꢀ
(11)
[0091]
i(false)=0
[0092]
然而,如上所述,在本公开的一些实施例中,当特征提取器110计算估计的信道相关性c(r)时,γ被设置为0。因此,由特征提取器110计算的估计的信道相关性可小于真实信道相关性(因为在等式4中将γ设置为零使得分母更大)。估计的信道相关性c(t)小于真实信道相关性的程度在较低snr下更明显(例如,在较低snr下,估计的信道相关性与真实信道相关性之间存在更大的差异)。这是因为较低的snr与较大的噪声方差σ2相应,因此由于将项
‑
γ
·
σ2设置为零,snr越低,分母的增加越大(例如,应该从分母中的估计信道功率中减去了更多的噪声方差σ2,但是设置γ=0导致分母甚至更大)。结果,如果在线预测期间的工作snr与训练数据集的snr不同,则即使对于相同的真实多普勒扩展f
d
,在线预测期间的估计的信道相关性c(t)也将与针对训练集的c(t)的不同。换句话说,由于操作期间的snr与离线训练数据集的snr之间的不匹配,基于离线训练数据学习的映射函数可能不适合于在线预测。
[0093]
图4是示出当使用贝塞尔函数或当使用根据本公开的实施例的多层感知机作为映射函数时,信道相关性和多普勒频移之间的关系的曲线图。参照图4,假设从一组训练数据中学习mlp,使得与多普勒频移f
d
相应的信道相关性为c
′
。然后,在在线估计期间,如果工作snr高于训练数据集的snr范围,则估计的信道相关性(表示为)将大于c
′
。结果,估计的多普勒频移(表示为)将小于真实多普勒频移f
d
。另一方面,如果工作snr低于训练数据集的snr范围,则估计的信道相关性(表示为)将小于c
′
,并且相应的估计的多普勒频移(表示
为)将大于真实多普勒频移f
d
。如图4所示,由于训练数据集的snr与在线预测之间的不匹配,估计的多普勒频移(例如,和)可能偏离真实f
d
。因此,当实际snr接近用于训练多普勒频移预测器120的数据的snr时,由多普勒频移预测器120计算的预测出的估计的多普勒频移f
d
更准确。
[0094]
实际上,无线收发机的工作snr范围可能是宽的,并且可能难以训练可在整个工作snr上操作的单个多普勒频移预测器。因此,在本公开的一些实施例中,将训练数据划分为多个子集(例如,r个子集或子范围),每个子集与训练数据的整个snr范围(或训练snr范围)的不同部分相应,并且训练数据的每个子集或子范围被用于(例如,以基本上类似于上面讨论的方式)针对工作snr范围的相应第r部分训练单独的多普勒频移预测器p
r
(每个多普勒频移预测器可具有相同的架构或不同的架构)。
[0095]
在本公开的一些实施例中,每个子集具有相同的大小,或者可以以其他方式沿着训练数据的训练snr范围以线性尺度或对数尺度均匀地间隔开。在本公开的其他实施例中,子集具有不同的大小(例如,沿着训练snr范围不均匀地间隔开)。例如,训练数据可被划分成子集,使得存在更多的被训练为针对工作作snr范围的实际上更频繁地观察到的部分提供预测多普勒频移的预测器(例如,使得多普勒频移估计器更频繁地产生更准确的结果)。作为另一示例,训练数据可被划分为子集,使得在工作snr范围的对估计的多普勒频移或估计的多普勒扩展的不准确性更敏感的区域中存在更多预测器。
[0096]
图5是根据本公开的一个实施例的多普勒扩展估计器100的框图。图5的多普勒扩展估计器100基本上类似于图3所示的多普勒频移估计器,但是还包括信噪比(snr)提取器130和预测器选择器140。图6是示出根据本公开的一个实施例的用于使用多个多普勒频移预测器估计多普勒扩展的方法的流程图。参照图6,在操作610,特征提取器110从输入估计信道提取特征,如上所述,并且如下面更详细描述的。在操作630,snr提取器130提取接收信号的snr,并将提取的信号的snr提供给预测器选择器140,其中,预测器选择器140被配置为从r个经过训练的多普勒频移预测器p(例如,多普勒频移预测器p1,p2,...,pr)中选择特定多普勒频移预测器pr。例如,针对每个多普勒频移预测器p的训练snr范围可如下表2所示设置:
[0097]
表2
[0098][0099]
通常,因为更准确的信道状态信息(cis)允许无线电调谐其参数以匹配信道的实际条件,所以更准确的cis导致无线电接收机的更高性能。然而,由于各种环境条件,信道估计器可能过度估计或低估cis的各种参数,包括多普勒扩展。
[0100]
基于实验观察,多普勒扩展的过度估计比多普勒扩展的低估导致更好的误块率
(bler)性能(例如,更低的错误率)。在一些实验中,当真实多普勒频移为900hz时,将估计的多普勒频移设置为高25%(1.25*900hz=1,125hz)的bler性能具有比真实f
d
的稍好的性能,而将估计的多普勒频移设置为低25%(0.75*900hz=675hz)导致更高的错误率。
[0101]
另外,如图4所示,当工作snr低于训练数据集的snr范围(与估计的信道相关性相应)时,估计的多普勒扩展将大于真实多普勒扩展fd。换句话说,在具有比所提供的输入信道的snr更高的snr的数据上训练的多普勒扩展预测器将导致多普勒扩展的过度估计。
[0102]
因此,在本公开的一些实施例中,多普勒扩展估计器100的预测器选择器140选择多普勒频移预测器122,其中,该多普勒频移预测器122偏向于多普勒扩展的过度估计(或过估计)并且远离多普勒扩展的低估(或低估计),以便改善无线电的bler性能。在一些实施例中,通过从r个多普勒频移预测器中选择一多普勒频移预测器来实现偏置,其中,该多普勒频移预测器在具有与如由snr提取器130所确定的当前工作snr相邻且高于当前工作sn r的snr范围(例如,具有比当前估计的snr高的下限的下一snr范围)的一部分数据集上被训练。
[0103]
图7a是示出根据本公开的一个实施例的用于在两个不同多普勒频移预测器之间选择一个多普勒频移预测器的方法的流程图。图7a与r=2的情况相应,其中,第一多普勒频移预测器p
low
是在低snr数据(例如,利用范围[snr1,snr2]中的低snr信号收集的一部分数据)上训练的,第二多普勒频移预测器p
high
是在高snr数据(例如,利用范围[snr2,snr3]中的高snr信号收集的一部分数据)上训练的。假设针对无线电的工作snr范围小于针对在高snr范围上训练的第二多普勒频移预测器p
high
的snr范围的下端(例如,snr2)。因此,参照图7a,在操作651,预测器选择器140确定当前估计的是否小于阈值snr(snr
thr
)。基于上面给出的示例范围,在一些实施例中,snr
thr
=snr1,换句话说,阈值snr是用低snr信号训练的预测器的snr范围的下端。当当前估计的小于阈值snr(snrthr)时,随后在操作652,预测器选择器140选择在低snr数据上训练的第一多普勒频移预测器p
low
(因为这是在最接近当前估计的snr的数据上训练的预测器,同时也是在具有高于当前估计的snr的snr的数据上训练的预测器)。当当前估计的不小于阈值snr(snr
thr
)(例如,大于或等于阈值snr snr
thr
)时,随后在操作653,预测器选择器140选择在高snr上训练的第二多普勒频移预测器p
high
。
[0104]
图7b是示出根据本公开的一个实施例的用于在多个不同多普勒频移预测器(例如,r个不同多普勒频移预测器)之间选择至少一个多普勒频移预测器的方法的流程图。如上所述,假设系统(例如,无线电接收机)的工作snr范围是从snr0到snr
r
,并且整个工作snr范围被划分为r个区域。在操作654,预测器选择器140确定当前估计的是否在第一snr范围([snr0,snr1),或者是否)内。如果是,则在操作655,预测器选择器140选择基于来自与第一snr范围[snr
o
,snr1)相邻且高于第一snr范围[snr0,snr1)的第二snr范围[snr1,snr2)的训练数据训练的第一预测器p1。如果当前估计的不在第一snr范围([snr0,snr1))内,则在操作656,预测器选择器140确定当前估计的是否落在第二snr范围[snr1,snr2)内。如果是,则在操作657,预测器选择器140选择基于来自与第二snr范围[snr1,snr2)相邻且高于第二snr范围[snr1,snr2)的第三snr
范围[snr2,snr3)的训练数据训练的第二预测器p2。总之,如果当前估计的不在第一snr范围([snr0,snr1))内,则预测器选择器140通过将当前估计的与工作snr范围的r个区域的其余区域中的每个区域进行比较来以类似的方式继续进行,以选择预测器中的相应一个预测器,在操作658最后的snr范围是[snr
r
‑1,snr
r
),并且在操作659选择(基于来自最后的snr范围[snr
r
,∞)的训练数据训练的)最后的多普勒频移预测器p
r
。如上所述,假设工作范围是从snr0到snr
r
,并且因此大于snr
r
的snr将不会被观察到或将超出操作规范。
[0105]
返回参照图5和图6,在预测器选择器140已经在操作650中选择预测器之后,在操作670中使用所选择的多普勒频移预测器pr来在操作670中估计多普勒频移以计算估计的多普勒频移如上所述,在一些实施例中,估计的多普勒扩展限据而与最大的估计的多普勒频移相关。因此,本公开的实施例的各方面涉及能够基于从输入估计信道中提取的输入特征来估计多普勒频移的多普勒扩展估计器100。
[0106]
在本公开的一些实施例中,通过组合由基于来自多普勒频移范围的不同部分的训练数据训练(与在snr范围的不同部分上训练形成对照,如在上面关于图5、6、7a和7b描述的实施例的情况下)的多个多普勒频移预测器进行的预测来估计单个估计的多普勒频移(或多普勒扩展)。例如,可通过将整个多普勒频移范围划分成r个不同子范围来将如上文所描述的训练数据划分成r个不同子集,其中,训练数据的每个子集包括来自多普勒频移范围的不同子范围中的相应一个子范围的数据。例如,针对每个多普勒频移预测器p的训练多普勒频移范围可如下表3所示设置:
[0107]
表3:
[0108][0109][0110]
如表3所示,r个多普勒频移预测器中的每个多普勒频移预测器被配置为基于输入特征计算相应的输出多普勒频移f
′
。例如,第r个预测器p
r
从其相应的训练多普勒频移范围内计算预测多普勒频移f
′
r
(例如,其中,f
′
r
∈[f
dr
,f
d(r+1)
])。虽然表3示出了多普勒频移子范围不重叠的实施例,但是本公开的实施例不限于此。例如,在一些实施例中,与相邻预测器相应的相邻多普勒频移子范围具有一些重叠(例如,可在来自范围[f
d1a
,f
d1b
]的数据上训练预测器p1,并且可在来自范围[f
d2a
,f
d2b
]的数据上训练预测器p2,其中,f
d2a
<f
d1b
)。
[0111]
图8是根据本公开的一个实施例的多普勒频移估计器的框图,其中,该多普勒频移估计器被配置为通过组合来自在多普勒频移范围的不同部分上训练的多个多普勒频移预
测器的预测来估计多普勒频移。在图8所示的实施例中,多普勒频移预测器120包括r个经过训练的多普勒频移预测器。输入特征被提供给所述r个经过训练的多普勒频移预测器中的每个多普勒频移预测器以计算r个预测多普勒频移f
′1,...,f
′
r
。另外,输入特征被提供给被训练以计算输入特征属于r个类别中的每个类别的概率(例如,计算输入特征落入多普勒频移的r个子范围中的每个子范围的概率、或针对给定输入特征预测r个多普勒频移预测器中的哪个多普勒频移预测器将预测出最准确的多普勒频移)的多普勒频移预测器分类器网络(或多普勒频移分类器网络)p0。基于分类的网络p0的输出是r维向量[c1,...,c
r
],其中,每个值c
r
表示输入特征与第r个类别相应(例如,与第r个多普勒频移预测器相应)的概率或置信度。r个多普勒频移预测器的输出随后由组合器810使用例如基于每个预测多普勒频移f
′
乘以其相应的预测概率的乘积的总和而计算的平均组合(如等式12中所示)、或通过使用选择与最高预测概率相应的预测多普勒频移的最大组合(如等式13中所示)来组合。
[0112][0113][0114]
其中,i(
·
)表示指示函数。
[0115]
图9是根据本公开的一个实施例的多普勒频移估计器的框图,其中,该多普勒频移估计器被配置为通过使用平均组合对来自多个多普勒频移预测器的预测进行组合来估计多普勒频移。如图9所示,将r个预测多普勒频移f
′1,f
′2,...,f
′
r
乘以其相应的概率或置信度c1,c2,...,c
r
,并且对乘积求和以计算估计的多普勒频移
[0116]
如上所述,从输入估计信道提取的输入特征可包括如基于从接收的trs符号估计的信道计算的当前信道相关性c(t)。
[0117]
如上所述,在用于估计多普勒扩展的比较系统中,估计的信道相关性被提供给逆贝塞尔函数以获得估计的多普勒扩展。实际上,为了获得信道相关性c(t)的更稳定的估计,无限脉冲响应(iir)滤波器被应用在每个trs周期中估计的信道相关性上,导致经iir滤波的信道相关性。因为信道相关性直接测量信道h的变化,所以在本公开的一些实施例中,经iir滤波的信道相关性作为输入特征被提供给多普勒频移预测器p(例如,多个多普勒频移预测器中的当前选择的一个多普勒频移预测器)。
[0118]
类似地,可应用iir滤波器来稳定估计的信道相关性,因此多普勒频移预测器的最终输入特征仅是一个值一经iir滤波的估计的信道相关性。在本公开的一些实施例中,多普勒频移预测器是多层感知机(mlp)。图10是根据本公开的一个实施例的使用iir滤波器来组合多个信道相关性的多普勒频移预测器的示意图。例如,如图10所示,假设当前trs周期是第n个trs周期,则存在作为输入提供给无限脉冲响应(iir)滤波器1010的n个估计的信道相关性c1(t),c2(t),...,c
n
(t),然后这n个输入的信道相关性的经iir滤波的信道相关性可被表示为在图10的实施例中,多普勒频移预测器被实现为被配置为执行回归的多层感知机,其中,mlp具有输入层123,该输入层123具有单个节点,该输入层123被配置为接收
输入的经iir滤波的信道相关性并将经滤波的信道相关性提供给隐藏层125,该隐藏层125具有与多个权重(或参数)相关联的多个节点。在每个节点处,输入的经iir滤波的信道相关性乘以相应的权重,并且乘积通过激活函数(例如,sigmoid函数或整流线性单元(relu))。具有单个节点的输出层127被配置为接收来自隐藏层的多个节点的输入并对其进行组合(例如,将隐藏层的节点的激活函数的输出与权重相乘,对结果求和并通过激活函数以计算预测的多普勒频移f
d,n
)。
[0119]
因为iir滤波器系数被设置为固定值,所以特征提取器110组合先前估计的信道相关性和当前估计的信道相关性的方式在设计特征提取器110时是固定的,并且可能无法适应变化的条件或其他因素。此外,尽管在每个trs周期中估计信道相关性,但是在该设置中,多普勒频移预测器的最终输入仅是一个经iir滤波的信道相关性,因此丢失了可能包含在先前估计的信道相关性中的一些信息。
[0120]
因此,本公开的实施例的一些方面涉及将当前估计的信道相关性c
n
(t)以及来自多个先前trs周期的窗口的信道相关性作为输入特征提供给多普勒频移预测器。
[0121]
图11是根据本公开的一个实施例的多普勒频移预测器的示意图,其中,在该多普勒频移预测器中,来自trs时隙的窗口的多个信道相关性作为输入被提供给多层感知机。在图11所示的实施例中,将来自先前trs周期c
n
‑
δ
(t),...,c
n
‑2(t),c
n
‑1(t)(其中,δ是先前trs周期的数量,或者等效地,以trs周期为单位的窗口的大小)的因果窗口的多个信道相关性与在当前trs周期c
n
(t)中估计的信道相关性进行组合,以获得包括在提供给多层感知机的输入层123的输入特征中的总共δ+1个信道相关性,其中,输入层123包括用于所述δ+1个信道相关性中的每个信道相关性的单独节点。信道相关性c(t)中的每个信道相关性乘以相应的权重(例如,在训练过程期间学习的权重)从输入层123的节点被提供给隐藏层125的节点中的每个节点。在隐藏层125中的每个节点处,所有传入乘积(例如,信道相关性和权重的乘积)被求和并通过激活函数(例如,sigmoid函数)。隐藏层125的节点中的每个节点将来自激活函数的输出提供给输出层127,其中,输出层127对隐藏层125的激活函数的输出进行组合以计算预测多普勒频移f
d,n
,其中,该组合操作将隐藏层的节点中的每个节点的激活函数的输出与它们的相应权重(权重是通过训练过程学习的)相乘,对加权乘积求和并将总和通过激活函数(例如,sigmoid函数或整流线性单元(relu))。
[0122]
通过包括先前δtrs周期的估计的信道相关性,本公开的这些实施例向多普勒频移预测器提供关于信道如何随时间改变的更多信息。此外,训练过程训练多普勒频移预测器以使用学习出的参数集合或系数集合来组合这些估计的信道相关性,而不是根据iir滤波器固定那些系数。因为学习出的参数能够计算与iir滤波器相同的结果(例如,学习出的系数可能将导致iir滤波器),所以预期使用来自先前trs周期的因果窗口的多个信道系数的经过训练的多普勒频移预测器的性能不比iir滤波器差。
[0123]
本领域技术人员将理解,可修改图10和图11的实施例中所示的用于执行回归的架构,以通过使用输出层127中的m个节点并使用独热编码对训练数据的正确类别进行编码来执行分类为如上所述的多普勒频移范围的m个类别中的一个类别。
[0124]
如上所述,本公开的一些实施例涉及使用多层感知机作为神经网络的多普勒频移预测器来基于所提供的输入特征(诸如当前信道相关性c
n
(t)和来自多个先前trs周期c
n
‑
δ
(t),...,c
n
‑2(t),c
n
‑1(t)的窗口的信道相关性)预测多普勒频移。然而,本公开的实施例不限于此。例如,在本公开的一些实施例中,当前信道相关性c
n
(t)和来自多个先前trs周期c
n
‑
δ
(t),...,c
n
‑2(t),c
n
‑1(t)的窗口的信道相关性作为输入特征被提供给递归神经网络(rnn)或长短期记忆(lstm)神经网络。
[0125]
因此,本公开的实施例的各方面涉及用于基于来自输入估计信道的信息(包括基于参考信号计算的信道相关性)来计算估计的多普勒扩展的系统和方法。根据一些实施例,基于一个或更多个经过训练的多普勒频移预测器来计算估计的多普勒扩展,其中,所述多普勒频移预测器是基于从实际物理无线电接收机或从实际链路级仿真器收集的测量训练的。本公开的实施例的一些方面涉及基于当前估计的snr从多个多普勒频移预测器中选择一多普勒频移预测器,其中,所述多个多普勒频移预测器中的每个多普勒频移预测器在如通过训练数据的snr范围的多个部分进行分组的不同部分的训练数据上被训练。本公开的实施例的一些方面涉及基于计算输入特征与在训练数据中的来自多普勒频移范围的不同部分的数据上训练的多普勒频移预测器中的每个多普勒频移预测器相应的一个或更多个概率来组合多个多普勒频移预测器的输出。
[0126]
术语“处理电路”在本文中用于表示用于处理数据或数字信号的硬件、固件和软件的任意组合。处理电路硬件可包括例如无线电基带处理器(bp或bbp)、专用集成电路(asic)、通用或专用中央处理器(cpu)、数字信号处理器(dsp)、图形处理单元(gpu)、诸如现场可编程门阵列(fpga)的可编程逻辑器件。在处理电路中,如本文中所使用的,每个功能由被配置(即,硬连线)为执行所述功能的硬件执行,或由被配置为执行存储于非暂时性存储介质中的指令的更通用的硬件(诸如cpu)执行。处理电路可被制造在单个印刷电路板(pcb)上或者分布在若干互连的pcb上。处理电路可包含其他处理电路;例如,处理电路可包括在pcb上互连的两个处理电路,fpga和cpu。
[0127]
应当理解,尽管本文可使用术语“第一”、“第二”、“第三”等来描述各种元件、组件、区域、层和/或部分,但是这些元件、组件、区域、层和/或部分不应受这些术语的限制。这些术语仅用于将一个元件、组件、区域、层或部分与另一个元件、组件、区域、层或部分区分开。因此,在不脱离本公开的精神和范围的情况下,本文讨论的第一元件、组件、区域、层或部分可被称为第二元件、组件、区域、层或部分。
[0128]
本文使用的术语仅用于描述特定实施例的目的,并不旨在限制本公开。如本文所用,术语“基本上”、“约”和类似术语用作近似术语而不是程度术语,并且旨在考虑本领域普通技术人员将认识到的测量值或计算值的固有偏差。
[0129]
如本文所使用的,除非上下文另有明确说明,否则单数形式旨在也包括复数形式。将进一步理解,当在本说明书中使用时,术语“包括”和/或“包括
…
的”指明存在所陈述的特征、整数、步骤、操作、元件和/或组件,但不排除存在或添加一个或更多个其他特征、整数、步骤、操作、元件、组件和/或其组合。如本文所使用的,术语“和/或”包括相关联的所列项中的一个或更多个项的任何和所有组合。诸如
“……
中的至少一个”的表达在一列元素之前时修饰整列元素,而不是修饰列的各个元素。此外,在描述本公开的实施例时使用“可”是指“本公开的一个或更多个实施例”。此外,术语“示例性”旨在指示例或说明。如本文所使用的,术语“使用”、“使用...的”以及“被使用”可被认为分别与术语“利用”、“利用...的”以及“被利用”同义。
[0130]
应当理解,当元件或层被称为在另一元件或层“上”、“连接到”、“耦合到”或“相邻于”另一元件或层时,它可直接在所述另一元件或层上、连接到、耦合到或相邻于所述另一元件或层,或者可存在一个或更多个中间元件或层。相反,当元件或层被称为“直接在另一元件或层上”、“直接连接到”、“直接耦合到”或“紧邻”另一元件或层时,不存在中间元件或层。
[0131]
本文所述的任何数值范围旨在包括归入所述范围内的相同数值精度的所有子范围。例如,“1.0至10.0”的范围旨在包括所述最小值1.0和所述最大值10.0之间(并且包括所述最小值1.0和所述最大值10.0)的所有子范围,即,具有等于或大于1.0的最小值和等于或小于10.0的最大值,诸如,例如2.4至7.6。本文所述的任何最大数值限度旨在包括归入其中的所有较低数值限度,并且本说明书中所述的任何最小数值限度旨在包括归入其中的所有较高数值限度。
[0132]
虽然已经结合某些示例性实施例描述了本公开,但是应当理解,本公开不限于所公开的实施例,而是相反,旨在覆盖包括在所附权利要求及其等同物的精神和范围内的各种修改和等同布置。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1