一种基于TextCNN的加密恶意流量检测模型及其构建方法
一种基于textcnn的加密恶意流量检测模型及其构建方法
技术领域
1.本发明涉及恶意流量检测技术领域,特别是涉及一种基于textcnn的加密恶意流量检测模型及其构建方法。
背景技术:
2.随着网络技术的飞速发展,互联网成为了人们生活中不可或缺的一部分,网络数据的安全性和完整性,成为了工业界和学术界共同关注的重要课题。在这样的背景下,ssl(secure socket layer安全套接层)和tls(transport layer security传输层安全)等网络安全协议运营而生。ssl/tls协议,工作在tcp/ip的传输层之上,具有模糊应用数据、验证终端身份和数据完整性检验等功能,从而为应用数据提供隐私和完整性保障。
3.经过ssl/tls协议加密后的网络流量,只有通信双方才能够读取其中的信息。中间的通信设备收到ssl/tls加密后的数据,由于没有密钥,无法识别其真实信息。因此,合法用户使用ssl/tls协议对数据加密,保护数据的隐私,防止中间人窃听。恶意软件的作者也使用ssl/tls协议,对恶意软件在通信过程中产生的流量进行加密,产生加密的恶意流量。该流量能够躲避安全设备的检查,对合法用户实施攻击。因此,需要提供一种技术进行恶意流量监测。
4.常见的恶意流量检测方法包括以下四种:
5.第一种是基于端口号的流量检测方法,该方法利用传输层端口号与应用层的应用协议一一对应原理(例如:ssh协议对应22端口,telnet协议对应23号端口,tls协议对应443端口等等),对流量进行分类和检测;
6.但是基于端口的方法存在容易被攻击者绕过的缺点,攻击者可以通过将恶意软件产生的流量的端口号进行修改,使用众所周知的端口号来掩盖其流量,避免使用标准的注册端口号,从而绕过检测。
7.第二种是深度包检测方法,该方法通过读取网络数据包应用层的数据,对应用数据特征进行分析,从而推测所承载的应用数据是否为恶意的;
8.这种深度包检测方法,虽然能够对应用层数据进行分析,具有较高的准确率,但是只能处理未加密的流量,无法处理加密流量。如果要对加密流量进行分析,则需要先对流量进行解密,然后再分析其中的内容。但是,解密数据需要大量的计算资源,增加通信设备的负担,同时解密tls协议加密的数据几乎是不可能的。
9.第三种是基于传统机器学习的恶意流量检测方法,该方法通过人工分析,并提取的网络数据包的字段、数据包长度,发送时间等特征,通过学习这些特征,模型能够在不解密的情况下,对加密的恶意流量和良性流量进行分类;
10.这种基于机器学习的恶意流量的检测方法,在特征工程阶段,依赖专家经验寻找、分析恶意流量和良性流量之间存在明显差异的特征,需要大量人工,消耗大量时间;同时,专家经验的不足,或者专家经验的片面性将会极大的影响模型的泛化能力和检测效果。
11.第四种是基于深度学习的恶意流量检测方法,常见的做法是将pcap文件转换为
28*28*1的灰度图像,通过传统的卷积神经网络自动提取图像中的特征,训练好的模型能够检测加密的恶意流量。
12.上述基于深度学习的恶意流量检测方法,将pcap文件转换为28*28*1的灰度图片,以手写数字识别数据集的格式进行保存,因此,在模型训练阶段,需要将灰度图片读取,按照手写数字识别数据集的数据预处理方式对数据进行处理后,数据才能够输入模型中,因此数据预处理方式复杂。另外,由于需要将pcap文件转换为28*28*1的灰度图片,在数据预处理时,需要将数据包修剪为784字节大小。如果,数据集中有大量的数据包大于784字节,同时所有数据包都只取前784字节,这将会导致数据集中的大量信息丢失。
技术实现要素:
13.为克服上述现有技术存在的不足,本发明之一目的在于提供一种基于textcnn的加密恶意流量检测模型及其构建方法,以实现一种加密恶意流量检测模型,可在不解密的前提下,检测出加密流量中的恶意网络数据。
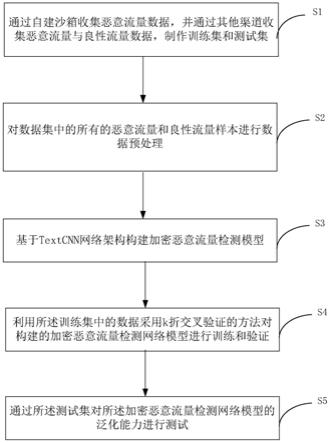
14.为达上述目的,本发明提出一种基于textcnn的加密恶意流量检测模型的构建方法,包括如下步骤:
15.步骤s1,通过自建沙箱收集恶意流量数据,并通过其他渠道收集恶意流量与良性流量数据,制作训练集和测试集;
16.步骤s2,对数据集中的所有的恶意流量和良性流量样本进行数据预处理;
17.步骤s3,基于textcnn网络架构构建加密恶意流量检测模型;
18.步骤s4,利用所述训练集中的数据采用k折交叉验证的方法对构建的加密恶意流量检测网络模型进行训练和验证;
19.步骤s5,通过所述测试集对所述加密恶意流量检测网络模型的泛化能力进行测试。
20.优选地,步骤s1进一步包括:
21.步骤s100,通过于自建的沙箱环境中运行恶意软件收集恶意流量数据,并从开源网站收集恶意流量和良性流量数据,以及在校园网和企业网络的dmz区域收集良性流量数据;
22.步骤s101,将收集到的恶意流量和良性流量数据分为两部分,一部分数据作为训练集,另一部分作为测试集。
23.优选地,于收集良性流量数据过程中,对于收集到的良性流量数据,还需进行评估,如果为恶意流量数据,则进行删除,以确保收集的数据都为良性流量数据。
24.优选地,步骤s2进一步包括:
25.步骤s200,对包含恶意流量和良性流量样本的pcap文件中的网络数据包根据会话进行切分,切割后的pcap文件,一个文件对应一个会话;
26.步骤s201,删除数据集中没有携带关键特征的数据样本;
27.步骤s202,将经过切分清洗后的数据集中的pcap文件,以二进制的模式进行读取,然后,以8bit为一组进行进制转换,转换后的数据为十进制的一维数组;
28.步骤s203,将数据集中所有的十进制一维数组数据裁剪为统一长度。
29.优选地,所述加密恶意流量检测网络模型的网络层次包括:输入层、词嵌入层、n对
并行的一维卷积和一维全局最大池化层、dropout层、批标准化层、全连接层、dropout层、批标准化层、全连接层、dropout层、批标准化层和输出层。
30.优选地,所述加密恶意流量检测网络模型包括:
31.输入层,用于获取经预处理后转换为十进制的一维数组的恶意流量和良性流量,并传递至词嵌入层;
32.词嵌入层,从多个维度对单词进行描述,将一个单词转换为对应的一维向量,多个不同种类的单词组合在一起,形成词嵌入表;
33.n对并行的一维卷积和一维全局最大池化层,利用n个不同卷积核的一维卷积层对词嵌入层输出的词嵌入表进行特征提取,并经过全局最大池化层,提取特征图中的最大值作为输出,最后将n对一维卷积层和全局最大池化层分别得到的输出整合在一起;
34.dropout层,用于让模型在训练时,随机选择部分的神经元不参与训练;
35.批标准化层,用于对数据进行标准化处理;
36.全连接层,用于将卷积和池化操作后得到的特征图进一步进行特征提取后到达输出层。
37.优选地,于步骤s4中,将所述训练集的数据切分为k份,随机选择其中的k-1份作为训练集,剩下的一份作为验证集;模型通过训练集对进行训练,通过验证集对训练好的模型的泛化能力进行验证,得到k个验证结果,最后对k个验证结果取平均,作为最终验证结果。
38.优选地,于步骤s5,通过所述测试集对所述加密恶意流量检测网络模型的泛化能力进行测试,若测试效果好,则保存该模型作为最终的加密恶意流量检测模型,如果测试效果不好,则反馈迭代,重新设计网络结构、调整超参数。
39.为达到上述目的,本发明还提供一种基于textcnn的加密恶意流量检测模型,从上至下依次包括:输入层、词嵌入层、n对并行的一维卷积和一维全局最大池化层、dropout层、批标准化层、全连接层、dropout层、批标准化层、全连接层、dropout层、批标准化层和输出层。
40.优选地,所述模型包括:
41.输入层,用于获取经预处理后转换为十进制的一维数组的恶意流量和良性流量,并传递至词嵌入层;
42.词嵌入层,从多个维度对单词进行描述,将一个单词转换为对应的一维向量,多个不同种类的单词组合在一起,形成词嵌入表;
43.n对并行的一维卷积和一维全局最大池化层,利用n个不同卷积核的一维卷积层对词嵌入层输出的词嵌入表进行特征提取,并经过全局最大池化层,提取特征图中的最大值作为输出,最后将n对一维卷积层和全局最大池化层分别得到的输出整合在一起;
44.dropout层,用于让模型在训练时,随机选择部分的神经元不参与训练;
45.批标准化层,用于对数据进行标准化处理;
46.全连接层,用于将卷积和池化操作后得到的特征图进一步进行特征提取后到达输出层。
47.与现有技术相比,本发明具有如下有益效果:
48.1)数据收集方面,本发明在自建的沙箱环境运行恶意软件,收集恶意流量数据。在校园网和企业网络的dmz区域收集良性流量数据,在开源网站收集恶意流量和良性流量数
据,数据集更具有代表性;
49.2)数据预处理方面,本发明将收集到的pcap文件,根据会话进行分割。分割之后,一个pcap文件对应一个会话,然后将pcap文件转换为长度为l的十进制一维数组,数据预处理的方式更加简单,同时处理后的数据能够携带更多的信息;
50.3)特征提取方面,本发明采用textcnn的网络架构,通过n个不同尺寸的卷积核自动提取数据包特征,充分的学习十进制一维数组的上下文信息,泛化能力强,具有较高的检测精度和检出率;
51.4)本发明能够在不对流量进行解密的前提下,检测恶意流量,适用于各种ssl/tls版本加密的数据流。
附图说明
52.图1为本发明一种基于textcnn的加密恶意流量检测模型的构建方法的步骤流程图;
53.图2为本发明具体实施例中良性流量收集示意图;
54.图3为本发明具体实施例中恶性流量与良性流量数据的文件目录示意图;
55.图4为本发明具体实施例中数据预处理过程图;
56.图5为本发明提出的基于textcnn网络结构的加密恶意流量检测模型结构图;
57.图6为本发明具体实施例中基于textcnn网络结构的加密恶意流量检测模型数据处理流程图。
具体实施方式
58.以下通过特定的具体实例并结合附图说明本发明的实施方式,本领域技术人员可由本说明书所揭示的内容轻易地了解本发明的其它优点与功效。本发明亦可通过其它不同的具体实例加以施行或应用,本说明书中的各项细节亦可基于不同观点与应用,在不背离本发明的精神下进行各种修饰与变更。
59.图1为本发明一种基于textcnn的加密恶意流量检测模型的构建方法的步骤流程图。如图1所示,本发明一种基于textcnn的加密恶意流量检测模型的构建方法,包括如下步骤:
60.步骤s1,通过自建沙箱收集恶意流量数据,并通过其他渠道收集恶意流量与良性流量数据,制作训练集和测试集。
61.具体地,步骤s1进一步包括:
62.步骤s100,通过于自建的沙箱环境中运行恶意软件收集恶意流量数据,并从开源网站收集恶意流量和良性流量数据,在校园网和企业网络的dmz区域收集良性流量数据。
63.具体地说,数据集要包含足够有代表性的流量,才能让模型学习到可靠的特征,因此需要包括具有代表性的恶意流量和良性流量数据。具体地说,本发明的恶意流量数据从自建沙箱环境中收集,在本发明中,该沙箱环境是在ubuntu操作系统之上搭建的,与现有的虚拟机不同,沙箱能够模拟真实的网络访问,自带捕获数据包的功能。在恶意软件运行过程中,沙箱会自动的对交互的报文信息进行收集,当运行结束后,用户能够在沙箱界面点击下载pcap文件,获得恶意流量数据。在沙箱环境中运行恶意软件收集的数据包,都为恶意流
量。
64.为了让模型学习到良性流量的特征,本发明通过在校园网和企业网络的dmz区域收集良性流量。dmz区域中服务器提供给内网和外网用户访问,在出口防火墙使用端口镜像技术,将去往dmz区域的数据镜像到探针服务器,如图2所示,在探针服务器上部署wireshark抓包软件,对数据包进行收集,同样,收集到的数据包也以pcap文件的形式保存。
65.优选地,在本发明中,对于收集到的良性流量数据,还需先进行评估,如果为恶意流量数据,则进行删除,以确保收集的数据都是良性流量。virustotal是一个全面的威胁分析平台,在学术界和工业界广泛应用于恶意样本的分析,因此本发明中,对于收集到的良性流量数据,先通过virustotal平台进行评估,如果为恶意流量,则进行删除,从而确保收集的数据都是良性流量。
66.另外,为了保证数据具有代表性,本发明的恶意流量和良性流量数据还来源于开源网站(canadian institute for cybersecurity),在开源网站下载的数据集都为pcap文件,每个文件都做好了恶意流量和良性流量的标注。
67.步骤s101,将收集到的恶意流量和良性流量数据分为两部分,一部分数据作为训练集,另一部分作为测试集。为了更好的验证模型的泛化能力,在本发明具体实施例中,60%的数据作为训练集,40%的数据作为测试集。
68.在本发明具体实施例中,将收集到的恶意流量数据和良性流量数据分别放入到不同的文件夹中,如图3所示,例如恶意流量数据放入malware文件夹中,在该文件夹中包含自建沙箱环境收集的恶意流量样本,以及开源网站下载的恶意流量样本;良性流量数据放入benign文件夹中,该文件夹中包含开源网站下载的良性流量样本,以及校园网和企业网的dmz区域收集的良性流量样本。将数据集随机划分为两个部分,其中60%的数据作为训练集,40%的数据作为测试集。
69.步骤s2,对数据集中的所有的恶意流量和良性流量样本进行数据预处理。
70.在本发明中,预处理主要是对包含恶意流量和良性流量的pcap文件根据会话进行切分;然后,以二进制的方式读取收集到的恶意流量和良性流量数据;最后,将二进制序列按8bit为一组进行分组,将每组序列转换为对应的10进制数值,得到十进制的一维数组。
71.具体地,如图4所示,步骤s2进一步包括:
72.步骤s200,对pcap文件中的网络数据包根据会话进行切分。
73.在本发明具体实施例中,使用pcap文件处理工具splitcap,在对流量进行切分时,可以有以下几种不同的依据:a.ip地址,b.mac地址,c.flow(流),d.session(会话)等等。flow由五元组决定,五元组包括源ip、目的ip、源端口、目的端口和协议号,也就是说flow是由所有具有相同五元组的数据包组成,是单向的。session由双向的flow构成,也就是说源ip和目的ip,源端口和目的端口两两互换。
74.由于一个会话代表着客户端和服务器的一次完整通信,携带的特征数量较多,因此,本发明根据会话对pcap文件进行分割。切分后的pcap文件,一个pcap文件中包含某一客户端和某一服务器之间的某一次会话的通信信息。
75.在分割pcap文件时,可以选择从数据包中提取所有层的信息,或者仅提取应用层的信息。由于所有层的信息中,包含传输层字段信息、tls报文头部信息和应用层有效负载。因此,比仅提取应用层信息得到的数据包特征更加丰富。因此,本发明在对数据包进行处理
切分时,提取数据包中所有层的信息。
76.根据上述要求,对原始pcap文件进行切分之后,会得到多个小的pcap文件,每个小的pcap文件对应一个会话,即每个小的pcap文件中包含某一客户端和某一服务器之间的某一次会话的所有通信数据。
77.步骤s201,清洗,即从数据集中删除没有携带关键特征的数据样本。
78.经过上述的处理流程,不同的pcap文件转换为了相同粒度的数据单元。但是,部分pcap文件中可能丢失了对异常流量和正常流量进行区分的关键信息。而这一部分的数据,如果输入到模型中进行训练,将会极大的影响模型的分类性能。因此,还需要从数据集中清除缺失关键信息的数据。
79.为了解决这个问题,首先需要了解什么样的通信是完整的。假设,一个客户端和一个服务器之间进行通信,在通信过程中使用tls协议对数据进行加密。以目前常用的tlsv1.2为例,该会话将会包括以下三个阶段,第一个阶段,tcp三次握手,建立tcp连接通道。第二个阶段,tls握手,该阶段会交互tls协议报文,包括client hello、server hello、certificate、server key exchange和client key exchange报文等等,对服务器身份进行验证,对密钥信息进行协商。第三阶段,交互应用数据,该数据使用tls协议进行加密。
80.综上所述,一个完整的tls通信会话的标志是完成了tls握手,互相进行了应用数据的交互。因此,需将没有完成tls握手,或者没有交互应用数据的会话进行丢弃,从而实现数据的清洗。
81.步骤s202,转换,将经过切分清洗后的pcap文件,以二进制的模式进行读取,然后,以8bit为一组进行进制转换,转换后的数据为十进制的一维数组。
82.具体地,为了还原和保留数据包在网络中的原始状态,需将pcap文件转换为一维序列的形式,作为模型的输入。恶意流量和良性流量的pcap文件经过切分之后,变成多个小的pcap文件。将小的pcap文件以二进制的形式进行读取,以8bit为一组进行分组。然后,将8bit的二进制数转换为对应的十进制数值,得到元素为十进制数值的一维数组。例如,二进制的0000 0000,对应十进制的0。二进制的1111 1111,对应十进制的255。因此,该十进制一维数组中每个元素都在[0,255]之间。
[0083]
步骤s203,裁剪,将所有的十进制一维数组数据裁剪为统一长度。
[0084]
由于不同的通信会话中,传递的网络数据包数量和大小存在差异,使得转换后得到的十进制一维数组的长度存在差异。由于,网络结构是固定的,输入网络的数据的形状也是固定的。因此,需要将所有的十进制一维数组转换为相同长度。
[0085]
固定长度的取值l,通过对切分后的数据包的长度进行统计获得,如果十进制一维数组的长度小于或等于l的数量n,占所有样本数量m的比例为71%。同时,在l之上,长度增加200,增加5次,每次增加数据包长度时,占比的增加均小于1%。则将所有数据的长度都转换为l。上述方法的好处有:(1)保存了尽可能多的数据信息。(2)确保较短的数据,不会被大量的0填充。(3)避免输入数据长度过大,导致模型训练速度慢的问题。
[0086]
最后,根据pcap文件所在的文件夹,对数据打上不同的标签,malware文件夹中的恶意流量数据,对应标签为1。benign文件夹中的良性流量,对应标签为0。
[0087]
步骤s3,基于textcnn网络架构构建加密恶意流量检测模型,
[0088]
具体地,本发明采用textcnn网络架构搭建加密恶意流量检测网络模型,如图5所
示,该加密恶意流量检测网络模型的网络层次包括:输入层、词嵌入层、n对并行的一维卷积和一维全局最大池化层、dropout、批标准化、全连接层、dropout、批标准化、全连接层、dropout、批标准化和输出层,具体如下:
[0089]
输入层,用于获取经预处理后转换为十进制的一维数组的恶意流量和良性流量,即获取经预处理后转换为十进制的一维数组的恶意流量和良性流量。
[0090]
具体地说,pcap文件经过根据会话进行切分后,一个文件对应一个会话,将每个pcap文件(每个会话)转换为十进制的一维数组,并将其输入到该加密恶意流量检测模型的输入层。
[0091]
词嵌入层,从多个维度对单词进行描述,将一个单词转换为对应的一维向量,多个不同种类的单词组合在一起,就形成了词嵌入表,这里的单词指的是网络数据包中某一个字段的取值,其数值的范围在0~255之间。输入层将每个pcap文件seq送入词嵌入层,则词嵌入层将输入的一个数值,转换为一个一维向量,该一维向量中包含多个数值,例如:字段值41,经过词嵌入层之后,变成[1,10,50,200,100,
…
,240],则一个数值变成了一个一维向量,可见原本的一个数值,被多个数值描述,也就是从多个角度去描述一个数值(单词),本发明通过从多个维度去对一个数值进行描述,可以体现出不同数值之间的关系,即数据包中不同字段之间的关系。
[0092]
由于词嵌入表能够很好的表示不同单词之间的关系,在文本分类任务中,能够很好的表示词与词之间的上下文关系。在加密恶意流量检测领域中,本发明利用词嵌入层的优点,对数据包各个层次、各个字段之间的上下文关系进行描述。由于十进制一维数组的每个元素取值范围都在0到255之间,一共256种取值。因此,本发明中建立了张词嵌入表,其单词种类数为256,每个单词的维度为256。
[0093]
n对并行的一维卷积和一维全局最大池化层,利用n个不同卷积核的一维卷积层对词嵌入层输出的词嵌入表进行特征提取,并经过全局最大池化层,提取特征图中的最大值作为输出,最后将n对一维卷积层和全局最大池化层分别得到的输出整合(concatenate)在一起。
[0094]
在本发明中,textcnn通过不同高度的卷积核提取词嵌入表中的关键信息,利用n个不同高度的一维卷积核,对词嵌入表进行上下文信息提取。在对词嵌入表进行特征提取时,卷积核从上至下移动进行卷积运算(即对应位置相乘,然后相加,得到的值作为卷积运算的输出)。
[0095]
由于一个单词的词嵌入维度是固定的,因此卷积核的宽度必须是固定的,宽度大小等于词嵌入的维度。不同卷积核的高度不同,不同的高度从词嵌入表中提取到不同特征值。假设卷积核的高度为h,词嵌入的高度为h,则卷积运算后得到的特征图为(h-h+1)*1。全局最大池化层对特征进行降维,从特征图中选取最大值作为输出。
[0096]
在本发明具体实施例中,五对并行的一维卷积层和全局最大池化层分别得到的输出整合(concatenate)在一起,构成textcnn网络的核心部分,将上述textcnn的工作原理运用于恶意流量检测中,能够充分提取恶意样本和良性样本的字段和有效负载中存在明显差异的上下文信息。
[0097]
dropout层,用于使模型在训练时,随机选择部分的神经元不参与训练,有助于防止过拟合。
[0098]
批标准化,用于将数据进行归一化处理,使其平均值接近于0,标准偏差将接近于1,使得数据分布更有规律,提升模型的训练速度。
[0099]
全连接层,用于将卷积和池化操作后得到的特征图进一步进行特征提取后到达输出层。
[0100]
在本发明中,全连接层是标准的神经网络,主要的参数是神经元的个数。将卷积和池化运算后得到的特征图,输入到全连接层中,进一步的特征提取。本发明将神经元个数为2的全连接层作为输出层,选择softmax作为激活函数。最终,得到输入样本属于恶意流量概率值p1,以及良性流量的概率值p2,p1和p2之和为1,取值较大者将作为输出结果。
[0101]
需说明的是,由于一个dropout层只对一层网络起作用,因此,在模型训练时,在每个全连接层之后,可根据需要设置dropout层与批标准化层。
[0102]
在本发明具体实施例中,假设将所有十进制一维数组的长度填充为g,一维卷积的高度分别为[a,b,c,d,e],卷积核个数为f,有三个全连接层,全连接层的神经元个数分别为[h,i,2],最后一个全连接层作为输出层,使用的激活函数为softmax,数据处理流程如图6所示。
[0103]
步骤s4,利用k折交叉验证的方法对构建的加密恶意流量检测网络模型进行训练和验证。
[0104]
具体地,将训练数据切分为k份,随机选择其中的k-1份作为训练集,剩下的一份作为验证集。模型通过训练集对进行训练,通过验证集对训练好的模型的泛化能力进行验证,会得到k个验证结果,对k个验证结果取平均,作为最终验证结果。本发明通过k折交叉验证得到的验证结果,能够更加稳定、可靠的衡量模型的训练效果。
[0105]
步骤s5,通过测试集对所述加密恶意流量检测网络模型的泛化能力进行测试,如果测试效果好,则保存该模型,如果测试效果不好,则反馈迭代,重新设计网络结构、调整超参数。
[0106]
一般来说,测试效果好坏的衡量指标有精度(accuracy)、查准率(precision)、召回率(recall)、f1值(f1 score)和真正例率(true positive rate)和假正例率,其中重点观测指标为真正例率和假正例率,通过测试集对所述加密恶意流量检测网络模型的泛化能力进行测试,确保模型能够检测出足够多的恶意样例,同时不会错误的将良性流量认为是恶意流量。最后,如果测试效果好,则保存该模型作为最终的加密恶意流量检测网络模型,如果测试效果不好,则反馈迭代,重新设计网络结构、调整超参数,直至得到测试效果好的模型作为最终的加密恶意流量检测网络模型。
[0107]
可见,本发明一种基于textcnn的加密恶意流量检测模型及其构建方法,该方法将恶意流量和良性流量的分类任务,转换为文本分类任务进行处理。结合网络数据包按照tcp/ip协议栈的格式进行封装的领域知识,将网络流量根据会话切分,然后进行清洗、转换和裁剪,处理为等长的十进制一维数组。通过词嵌入层,充分描述网络流量中的上下文关系,通过多组一维卷积,从原始的流量中自动的学习上下文特征。将多组一维卷积中学习到的特征结合起来,对流量进行分类。
[0108]
在实际的网络流量数据上训练后,能够在未知数据集上表现出较高的真正例率和较低的假正例率,模型泛化能力强。
[0109]
上述实施例仅例示性说明本发明的原理及其功效,而非用于限制本发明。任何本
领域技术人员均可在不违背本发明的精神及范畴下,对上述实施例进行修饰与改变。因此,本发明的权利保护范围,应如权利要求书所列。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1