一种基于PCIe的多端口网络报文收发方法与流程
一种基于pcie的多端口网络报文收发方法
技术领域
1.本发明涉及计算机网络技术领域,特别涉及一种基于pcie的多端口网络报文收发方法。
背景技术:
2.在嵌入式网络设备中,对于需要多个网口的场景,一般arm处理器原生网口是不够的,此时可以通过arm的pcie通道和fpga来扩展网口。对于成本比较敏感的嵌入式设备,fpga不带有sr
‑
iov功能,因此多个网口需要通过虚拟网络设备和修改原始网络报文的方式来实现。当网络报文收发比较频繁时,需要保证报文的收发效率,同时还需要兼顾报文较少时的实时性,因此设计一套高效实时的基于pcie的网络报文收发方法是体现设备网络性能的关键。
技术实现要素:
3.本发明的目的在于提供一种基于pcie的多端口网络报文收发方法,以克服现有技术中的不足。
4.为实现上述目的,本发明提供如下技术方案:本发明公开了一种基于pcie的多端口网络报文收发方法,包括以下步骤:s1:arm和fpga虚拟若干个网络设备,对原始网络报文添加端口号,在单路pcie通道上实现多个网络端口同时收发数据的功能;s2:arm采用发送网络报文页合并、多页聚合发送和超时发送机制,在发送报文页合并和合并页发送过程中采用两个独立线程和两个无锁缓存进行操作;s3:arm对网络报文发送和接收的处理线程进行cpu绑核处理。
5.作为优选,所述步骤s1包括以下子步骤:s11:arm在网络驱动程序中创建若干个虚拟网络设备,fpga创建与虚拟网络设备数量相同的对外网口的网络设备,通过pcie通道进行数据交互;s12:arm根据虚拟网络设备在发送网络报文中添加端口号,然后插入网络原始发送报文无锁缓存队列中,包含以下子步骤:s121:arm创建可存储m个报文结构体地址的网络原始发送报文无锁缓存队列;s122:arm根据虚拟网络设备确定发送网络报文的端口号,利用报文结构体sk_buff中的vlan_cfi字段,将端口号填写到该字段中;s123:修改后的报文结构体地址插入到网络原始发送报文无锁缓存队列;s13:arm接收fpga的网络报文,解析获取端口号,根据端口号把原始报文发送给相应的虚拟网络设备,包含以下子步骤:s131:arm申请包含n个页的报文接收页缓存,并将缓存的物理地址发送给fpga;s132:fpga接收外部网口数据,在网络报文的头部加上端口号,写入到缓存并更新发送引擎的状态,每页中只写一个报文便于arm读取;
s133:arm创建网络报文接收线程,循环读取fpga的发送引擎的状态,检测到有报文到达,获取缓存中包含报文的页头和页尾,依次读取报文,解析得到端口号,将剥除端口号的原始报文发送给相应的虚拟网络设备。
6.作为优选,所述步骤s2包括以下子步骤:s21:arm创建可存储p个页的网络报文合并页无锁缓存队列,p<m;s22:arm申请可存储p个unsigned char的数组pkg_delay_times,存储对应页合并延时时间,申请可存储p个unsigned short的数组page_data_len,存储对应页的有效数据长度,定义页合并超时时间阈值pkg_delay_threshold_times;s23:arm创建网络发送原始报文合并线程,对网络原始发送报文无锁缓存队列进行页合并处理,插入网络报文合并页无锁缓存队列;s24:定义报文合并页发送触发阈值:page_threshold_nums,page_threshold_nums<p,定义报文合并页延时触发阈值:delay_threshold_times;s25:arm创建网络报文合并页发送线程,处理网络报文合并页无锁缓存队列中的报文合并页,通过dma将数据传输到fpga。
7.作为优选,所述步骤s24中定义的报文合并页延时触发阈值:delay_threshold_times大于所述步骤s22中定义的页合并超时时间阈值:pkg_delay_threshold_times。
8.作为优选,所述步骤s23包括以下子步骤:s231:检测网络报文合并页无锁缓存队列是否已满,直至检测到网络报文合并页无锁缓存队列未满,获取当前网络报文合并页,并检测网络原始报文发送无锁缓存队列是否有待发送报文,若队列中没有待发送的报文,执行步骤s232,若队列中有待发送的报文,执行步骤s235;s232:检测当前网络报文合并页对应的页有效数据长度:page_data_len是否为0,若页有效数据长度:page_data_len=0,重新回到步骤s231,否则执行步骤s233;s233:当前网络报文合并页对应的页合并延时时间pkg_delay_times加1us,网络发送原始报文合并线程执行udelay(1)函数休眠1us,检测当前网络报文合并页对应的页合并延时时间pkg_delay_times是否大于页合并超时时间阈值pkg_delay_threshold_times,若页合并延时时间pkg_delay_times大于页合并超时时间阈值pkg_delay_threshold_times,执行步骤s234,否则重新回到步骤s231;s234:当前网络报文合并页插入网络报文合并页无锁缓存队列,重新回到步骤s231;s235:读取网络原始发送报文无锁缓存队列中最老报文的长度信息,检测当前当前网络报文合并页是否有足够的剩余缓存存储该报文,若剩余缓存不够,执行步骤s236,若剩余缓存足够,执行步骤s237;s236:将当前网络报文合并页插入网络报文合并页无锁缓存队列,检测网络报文合并页无锁缓存队列是否已满,直至检测到网络报文合并页无锁缓存队列未满,获取当前网络报文合并页,执行步骤s237;s237:将报文结构体sk_buff中vlan_cfi字段、data_len字段和报文数据分别拷贝到网络报文合并页中的报文数据长度字段、端口号字段和的报文数据内容部分,更新当前
网络报文合并页中报文个数字段,更新相对应的页有效数据长度page_data_len的信息,释放网络报文sk_buff缓存和该报文在网络原始发送报文无锁缓存队列中的资源;s238:检测网络原始发送报文无锁缓存队列是否有待发送的报文,若队列中有待发送的报文,回到步骤s237,若队列中没有待发送的报文,重新回到步骤s231。
9.作为优选,所述步骤s25包括以下子步骤:s251:检测网络报文合并页无锁缓存队列是否有待发送的报文合并页,直至检测到队列中有待发送的报文合并页,执行s252;s252:计算得到待发送报文合并页的个数page_nums,判断合并页的个数page_nums是否大于文合并页发送触发阈值page_threshold_nums,若合并页的个数page_nums大于文合并页发送触发阈值page_threshold_nums,执行步骤s255,否则执行步骤s253;s253:将待发送报文合并页相对应的页合并延时时间pkg_delay_times相加,并与线程延时时间kthread_delay_times相加,得到总延时时间all_delay_times,判断总延时时间all_delay_times是否大于报文合并页延时触发阈值delay_threshold_times,若总延时时间all_delay_times大于报文合并页延时触发阈值delay_threshold_times,执行步骤s255,否则执行步骤s254;s254:线程执行udelay(1)函数延时1us,线程延时时间kthread_delay_times值加1,重新回到步骤s251;s255:将待发送报文合并页组合,通过dma传输,将报文发送到fpga,将相对应的页有效数据长度page_data_len和页合并延时时间pkg_delay_times均置0,将线程延时时间kthread_delay_times置0,释放此次发送的报文合并页在网络报文合并页无锁缓存队列的资源,重新回到步骤s251。
10.作为优选,arm采用六核处理器,分别为处理器cpu1
‑
cpu6。
11.作为优选,所述步骤s3包括以下子步骤:s31:网络原始发送报文合并线程绑定在cpu4运行;s32:网络报文合并页发送线程绑定在cpu5运行;s33:网络报文接收线程绑定在cpu6运行。
12.本发明的有益效果:1、本发明通过arm和fpga虚拟四个网络设备及修改原始网络报文,在单路pcie通道上实现四个网络端口同时收发数据的功能,有效降低成本;2、由于arm的dma传输以页(4096 bytes)为单位,arm创建两个无锁缓存和处理线程,对网络发送报文进行页合并处理,并通过页聚合发送和超时发送机制有效减少dma传输,提高了网络传输效率,同时保证网络报文较少时的实时性;3、arm将网络原始发送报文合并线程、网络报文合并页发送线程和网络报文接收线程分别绑定在固定的cpu上,有效提升了网络报文的收发性能。
13.本发明的特征及优点将通过实施例结合附图进行详细说明。
附图说明
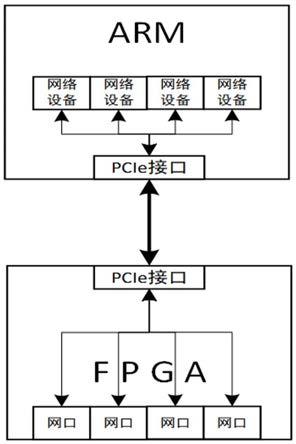
14.图1为本发明基于pcie的多端口网络的总体架构图;图2为本发明网络报文合并页数据结构图;
图3为本发明原始报文发送接口流程图;图4为本发明网络原始发送报文合并线程流程图;图5为本发明网络报文合并页发送线程流程图。
具体实施方式
15.为使本发明的目的、技术方案和优点更加清楚明了,下面通过附图及实施例,对本发明进行进一步详细说明。但是应该理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限制本发明的范围。此外,在以下说明中,省略了对公知结构和技术的描述,以避免不必要地混淆本发明的概念。
16.如图1所示为本发明的总体框架,本发明基于pcie的多端口网络报文收发方法,具体包括以下处理方法:s1:arm和fpga虚拟四个网络设备,对原始网络报文添加端口号,在单路pcie通道上实现四个网络端口同时收发数据的功能,具体步骤如下:s11:arm在网络驱动程序中创建四个虚拟网络设备,fpga创建四个对外网口的网络设备,通过pcie通道进行数据交互;s12:arm根据虚拟网络设备在发送网络报文中添加端口号,然后插入网络原始发送报文无锁缓存队列中,具体步骤如下:s121:arm创建可存储m个报文结构体地址的网络原始发送报文无锁缓存队列;s122:arm根据虚拟网络设备确定发送网络报文的端口号,利用报文结构体sk_buff中的vlan_cfi字段,将端口号填写到该字段中;s123:修改后的报文结构体地址插入到网络原始发送报文无锁缓存队列。
17.s13:arm接收fpga的网络报文,解析获取端口号,根据端口号把原始报文发送给相应的虚拟网络设备,具体步骤如下:s131:arm申请包含n个页(4096 bytes)的报文接收页缓存,并将缓存的物理地址发送给fpga;s132:fpga接收外部网口数据,在网络报文的头部加上端口号,写入到缓存并更新发送引擎的状态,每页中只写一个报文便于arm读取;s133:arm创建网络报文接收线程,循环读取fpga的发送引擎的状态,检测到有报文到达,获取缓存中包含报文的页头(rx_head)和页尾(rx_tail),依次读取报文,解析得到端口号,将剥除端口号的原始报文发送给相应的虚拟网络设备,具体流程如图3所示。
18.此步骤通过arm和fpga虚拟四个网络设备及修改原始网络报文,在单路pcie通道上实现四个网络端口同时收发数据的功能,有效的降低了成本。
19.s2:arm采用发送网络报文页合并、多页聚合发送和超时发送机制,在发送报文页合并和合并页发送过程中采用两个独立线程和两个无锁缓存进行操作,具体步骤如下:s21:arm创建可存储p个页(4096 bytes)的网络报文合并页无锁缓存队列,p<m;s22:arm申请可存储p个unsigned char的数组pkg_delay_times,存储对应页合并延时时间,申请可存储p个unsigned short的数组page_data_len,存储对应页的有效数据长度,定义页合并超时时间阈值:pkg_delay_threshold_times;s23:arm创建网络发送原始报文合并线程,对网络原始发送报文无锁缓存队列进
行页合并处理,插入网络报文合并页无锁缓存队列,如图4所示,具体步骤如下:s231:检测网络报文合并页无锁缓存队列是否已满,队列已满继续执行s231,队列未满 执行s232;s232:获取当前当前网络报文合并页id,标记为i,检测网络原始报文发送无锁缓存队列是否有待发送报文,没有则执行s233,有则执行s236;s233:检测当前网络报文合并页对应的page_data_len[i],page_data_len[i]=0则执行s231,否则执行s234;s234:当前网络报文合并页对应的pkg_delay_times[i]加1,网络发送原始报文合并线程执行udelay(1)函数延时1us,检测pkg_delay_times[i], pkg_delay_times[i]>pkg_delay_threshold_times则执行s235,否则执行s231;s235:当前网络报文合并页(id为i)插入网络报文合并页无锁缓存队列,执行s231;s236:获取网络原始发送报文无锁缓存队列中最老的报文id,标记为j,检测当前当前网络报文合并页是否有足够的空间存储该报文,没有则执行s237,有则执行s2310;s237:当前网络报文合并页(id为i)插入网络报文合并页无锁缓存队列,然后执行s238;s238:检测网络报文合并页无锁缓存队列是否已满,队列已满继续执行s238,队列未满 执行s239;s239:获取当前当前网络报文合并页id,标记为k,然后执行s2310;s2310:标记为j的网络原始报文结构sk_buff的vlan_cfi、data_len、报文数据分别拷贝到当前网络报文合并页(id为i或k)的数据长度字段、端口号字段和报文数据内容处,更新当前网络报文合并页的报文个数字段,处理后的页数据结构如图2所示,更新相对应的page_data_len[i]或page_data_len[k]的值,释放标记为j网络原始报文sk_buff缓存和在网络原始发送报文无锁缓存队列的资源,然后执行s2311;s2311:检测网络原始发送报文无锁缓存队列是否有待发送的报文,没有则执行s231,有则执行s236。
[0020]
s24:定义报文合并页发送触发阈值:page_threshold_nums,page_threshold_nums<p,定义报文合并页延时触发阈值:delay_threshold_times,delay_threshold_times> pkg_delay_threshold_times;s25:arm创建网络报文合并页发送线程,处理网络报文合并页无锁缓存队列中的报文合并页,通过dma将数据传输到fpga,如图5所示,具体步骤如下:s251:检测网络报文合并页无锁缓存队列是否有待发送的报文合并页,没有则执行s251,有则执行s252;s252:计算得到待发送报文合并页的个数page_nums,page_nums>page_threshold_nums则执行s255,否则执行s253;s253:将待发送报文合并页相对应的pkg_delay_times相加,并与线程延时时间kthread_delay_times相加,得到总延时时间all_delay_times, all_delay_times>delay_threshold_times则执行是s255,否则执行s254;s254:线程执行udelay(1)函数延时1us,kthread_delay_times值加1us,然后执行
s251;s255:将待发送报文合并页组合,通过dma传输,将报文发送到fpga,将相对应的page_data_len和pkg_delay_times均置0,将kthread_delay_times置0,释放此次发送的报文合并页在网络报文合并页无锁缓存队列的资源,执行s251。
[0021]
在此步骤内arm创建两个无锁缓存和处理线程,对网络发送报文进行页合并处理,并通过页聚合发送和超时发送机制有效减少dma传输,提高了网络传输效率,同时保证网络报文较少时的实时性。
[0022]
s3:arm对网络报文发送和接收的处理线程进行cpu绑核处理,arm采用六核处理器,分别为处理器cpu1
‑
cpu6,具体步骤如下:s31:网络原始发送报文合并线程绑定在cpu4运行;s32:网络报文合并页发送线程绑定在cpu5运行;s33:网络报文接收线程绑定在cpu6运行。
[0023]
在此步骤内arm将网络原始发送报文合并线程、网络报文合并页发送线程和网络报文接收线程分别绑定在固定的cpu上,有效提升了网络报文的收发性能。
[0024]
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换或改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1