一种考虑主用户信号随机到达和离开的频谱感知方法
1.本发明涉及一种认知无线电技术,尤其是涉及一种考虑主用户信号随机到达和离开的频谱感知方法。
背景技术:
2.随着第五代移动通信技术(5g)和计算机技术的快速发展,越来越多的设备接入频谱,这就需要越来越多的频谱资源。现有的频谱资源固定分配的频谱分配方式使得频谱资源利用率低下且分配不均衡,认知无线电技术(cognitive radio,cr)允许次级用户(secondary user,su)机会性地访问主用户(primary user,pu)的未使用频谱,其对于解决频谱资源利用率低下是一项十分重要的技术。频谱感知技术作为认知无线电技术中一项十分关键的技术,其可以通过检测主用户的活动状态,使次级用户机会主义的接入授权信道,对提高频谱资源利用率具有至关重要的作用。
3.过去几十年间,大量的频谱感知算法被提出。传统的频谱感知算法,如:能量检测(energy detection,ed)法、最大特征值检测(maximum eigenvalues detection,med)法、循环平稳特征检测(cyclostationary feature detection,cfd)法等通过对检验统计量进行建模后与门限值相比较,进而得到检测概率(probability of detection,pd)和虚警概率(probability of false alarm,pf),这类方法的检测性能依赖于模型驱动的检验统计量的建模准确性,且容易受到噪声不确定性(noise power uncertainty,nu)的影响。
4.随着近几年来深度学习(deep learning,dl)的广泛应用,许多学者提出了大量基于深度学习的频谱感知方案。与传统的频谱感知算法过分依赖检验统计量的建模不同,基于深度学习的频谱感知算法采用的是数据驱动的检验统计量,其不需要对检验统计量进行建模,并且对噪声不确定性具有很好的鲁棒性。
5.不论是传统的频谱感知算法,还是基于深度学习的频谱感知算法,它们都没有考虑主用户信号的随机到达和离开,然而在实际中主用户信号在感知周期内会发生随机到达和离开的情况,主用户信号随机到达时会发生主用户信号和次级用户信号的通信碰撞,主用户信号随机离开时会造成信道空闲,造成频谱资源浪费。基于此,部分学者提出了加权的能量检测法,如加权能量法(weighted-energy detection,w-ed)、似然比检测法(average likelihood ratio,avellr),这些方法在一定程度上解决了上述技术问题,但是这些方法随着信噪比的增大,加权效果会逐渐减小,检测性能会呈现出一个不再上升的趋势,导致检测结果不够精确。
技术实现要素:
6.本发明所要解决的技术问题是提供一种考虑主用户信号随机到达和离开的频谱感知方法,其能够准确估计出主用户信号的到达和离开,检测结果更为精确。
7.本发明解决上述技术问题所采用的技术方案为:一种考虑主用户信号随机到达和离开的频谱感知方法,其特征在于该方法在认知无线电系统中考虑一个感知周期内最多存
在一次主用户信号的随机到达或一次主用户信号的随机离开,设定一个感知周期内授权信道忙碌的持续时间为tb、授权信道空闲的持续时间为ti,且tb服从均值为μ的超指数分布,ti服从均值为ν的超指数分布,μ与ν相等;该方法具体包括以下步骤:
8.步骤1:设定有n
snr
个不同的信噪比和n
μ
个不同的μ值,并将n
snr
个不同的信噪比和n
μ
个不同的μ值两两组合成n
snr
×nμ
种场景情况;其中,n
snr
≥3,n
μ
≥3;
9.步骤2:针对每一种场景情况,任意选取一个感知周期作为第1个感知周期;然后从第1个感知周期开始选定连续的k个感知周期;接着对选定的每个感知周期内的次级用户接收信号进行n次采样,得到每个感知周期内的次级用户接收信号的n个采样值,将第k个感知周期内的次级用户接收信号的第n个采样值记为xk(n),若第k个感知周期内授权信道空闲,则若第k个感知周期内授权信道忙碌,则之后将每个感知周期内的次级用户接收信号的各个采样值的实部和虚部分开;紧接着将每个感知周期内的次级用户接收信号的n个采样值的实部和虚部构成一个样本矩阵,将第k个感知周期内的次级用户接收信号的n个采样值的实部和虚部构成的样本矩阵记为xk,再对每个感知周期内授权信道的状态打标签,将第k个感知周期内授权信道的状态标签记为zk,zk的值为0或1,zk的值为0时表示第k个感知周期内授权信道空闲,zk的值为1时表示第k个感知周期内授权信道忙碌;其中,k≥1000,n=ts×fs
,ts表示每个感知周期的时长,fs表示采样频率,k为正整数,1≤k≤k,n为正整数,1≤n≤n,lk(n)表示第k个感知周期内的主用户发射信号即主用户信号的第n个采样值,lk(n)服从均值为0方差为的复高斯分布,ωk(n)表示第k个感知周期内的加性高斯白噪声的第n个采样值,ωk(n)服从均值为0方差为的复高斯分布,lk(n)与ωk(n)是相互独立的,n0表示主用户信号离开的时刻,n1表示主用户信号到达的时刻,xk的维数为2
×
n,re()表示取实部操作,im()表示取虚部操作,xk(1)表示第k个感知周期内的次级用户接收信号的第1个采样值,xk(2)表示第k个感知周期内的次级用户接收信号的第2个采样值,xk(n)表示第k个感知周期内的次级用户接收信号的第n个采样值;
10.步骤3:从针对每一种场景情况共得到的k个样本矩阵中随机选择n
train
个样本矩阵,将从n
snr
×nμ
种场景情况共得到的n
snr
×nμ
×
k个样本矩阵中随机选择出的n
snr
×nμ
×ntrain
个样本矩阵及对应的授权信道的状态标签构成训练集,记为y
train
,将n
snr
×nμ
种场景情况共得到的n
snr
×nμ
×
k个样本矩阵中剩余的n
snr
×nμ
×
(k-n
train
)个样本矩阵构成测试集,记为y
test
,其中,其中,表示训练集中的第j个样本矩阵,表示所对应的授权信道的状态标签,表示测试集中的第j'个样本矩阵;
11.步骤4:构建卷积神经网络,其包括三个卷积层、三个最大池化层及两个全连接层,第1个卷积层的输入端为该卷积神经网络的输入端,第1个卷积层的输出端输出的特征数据经过“relu”激活函数后输入到第1个最大池化层的输入端,第1个最大池化层的输出端输出的特征数据经过“relu”激活函数后输入到第2个卷积层的输入端,第2个卷积层的输出端输出的特征数据经过“relu”激活函数后输入到第2个最大池化层的输入端,第2个最大池化层的输出端输出的特征数据经过“relu”激活函数后输入到第3个卷积层的输入端,第3个卷积层的输出端输出的特征数据经过“relu”激活函数后输入到第3个最大池化层的输入端,第3个最大池化层的输出端输出的特征数据经过“relu”激活函数后输入到第1个全连接层的输入端,第1个全连接层的输出端输出的特征数据经过“relu”激活函数后再经过dropout操作输入到第2个全连接层的输入端,第2个全连接层的输出端输出的特征数据经过“softmax”激活函数后作为该卷积神经网络的输出端输出的特征数据;其中,第1个卷积层的卷积核大小为3
×
3、卷积核深度为32、卷积步长为1,第2个卷积层的卷积核大小为3
×
3、卷积核深度为64、卷积步长为1,第3个卷积层的卷积核大小为3
×
3、卷积核深度为128、卷积步长为1,第1个最大池化层、第2个最大池化层和第3个最大池化层的池化窗大小为2
×
2、池化步长为2,第1个全连接层的神经元个数为128,第2个全连接层的神经元个数为2,dropout率设置为0.5;
12.步骤5:将训练集中的每个样本矩阵及对应的授权信道的状态标签输入到构建的卷积神经网络中对卷积神经网络进行训练,训练的batch size设置为大于或等于100,训练的优化器采用adam,训练的损失函数采用交叉熵函数,训练的结束条件为交叉熵函数的值收敛到0附近或迭代次数设置为大于或等于20;训练结束后得到训练好的卷积神经网络模型及训练集中的每个样本矩阵对应的输出向量,输出向量包含两个元素,分别为授权信道空闲的概率和授权信道忙碌的概率;
13.步骤6:找出训练集中对应的授权信道的状态标签的值为0的所有样本矩阵;然后计算找出的每个样本矩阵对应的输出向量的概率比值,将找出的任一个样本矩阵对应的输出向量的概率比值记为b,接着对找出的所有样本矩阵对应的输出向量的概率比值进行降序排序;再从排序结果中选择第int(s
×
pf)个概率比值作为判决门限,记为λ;其中,p1表示该样本矩阵对应的输出向量中的授权信道忙碌的概率,p0表示该样本矩阵对应的输出向量中的授权信道空闲的概率,p1+p0=1,int()为取整函数,s表示训练集中对应的授权信道的状态标签的值为0的样本矩阵的总个数,pf表示给定的虚警概率,pf∈[0,1];
[0014]
步骤7:将测试集中的每个样本矩阵输入到训练好的卷积神经网络模型中进行测试,得到测试集中的每个样本矩阵对应的输出向量;然后计算测试集中的每个样本矩阵对应的输出向量的概率比值,将测试集中的任一个样本矩阵对应的输出向量的概率比值记为b',其中,p1'表示测试集中的任一个样本矩阵对应的输出向量中的授权信道忙碌的概率,p0'表示测试集中的任一个样本矩阵对应的输出向量中的授权信道空闲的概率,p1'+p0'=1;
[0015]
步骤8:将测试集中的每个样本矩阵对应的输出向量的概率比值作为检验统计量;然后将每个检验统计量与λ进行比较,对于任一个检验统计量,如果该检验统计量大于λ,则判定该检验统计量对应的样本矩阵所对应的感知周期内主用户信号到达,即授权信道忙
碌;否则,判定该检验统计量对应的样本矩阵所对应的感知周期内主用户信号离开,即授权信道空闲。
[0016]
与现有技术相比,本发明的优点在于:
[0017]
1)本发明方法不需要对检验统计量进行建模,通过神经网络学习数据的隐藏特征而得到的数据驱动的检验统计量使得本发明方法可以更好地适应不同的场景,在不同的场景都能实现比现有方法更好的检测性能。
[0018]
2)本发明方法通过学习数据的分布特征,使得噪声功率的变化并不能对本发明方法造成较大影响,从而对噪声不确定性具有较高的鲁棒性。
附图说明
[0019]
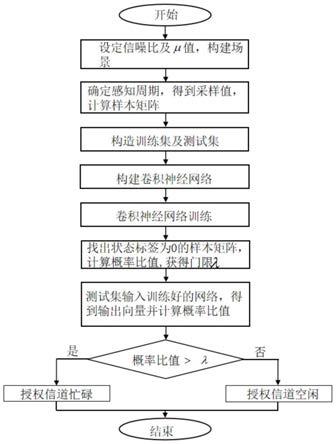
图1为本发明方法的总体实现框图;
[0020]
图2为本发明方法中构建的卷积神经网络的组成结构示意图;
[0021]
图3为本发明方法与现有方法在信噪比为-10db并且μ=2ms时对比的roc曲线图;
[0022]
图4为本发明方法与现有方法在噪声不确定性存在的情况下对比的roc曲线图。
具体实施方式
[0023]
以下结合附图实施例对本发明作进一步详细描述。
[0024]
本发明提出的一种考虑主用户信号随机到达和离开的频谱感知方法,其总体实现框图如图1所示,该方法在认知无线电系统中考虑一个感知周期内最多存在一次主用户信号的随机到达或一次主用户信号的随机离开,设定一个感知周期内授权信道忙碌的持续时间为tb、授权信道空闲的持续时间为ti,且tb服从均值为μ的超指数分布,ti服从均值为ν的超指数分布,μ与ν相等,tb和ti、μ和ν的值可自行设定,如μ和ν的值为2ms或5ms或10ms,即tb和ti满足均值为2ms或5ms或10ms;该方法具体包括以下步骤:
[0025]
步骤1:设定有n
snr
个不同的信噪比和n
μ
个不同的μ值,并将n
snr
个不同的信噪比和n
μ
个不同的μ值两两组合成n
snr
×nμ
种场景情况;其中,n
snr
≥3,n
μ
≥3,在本实施例中取n
snr
=n
μ
=3,3个不同的信噪比分别为-10db、-5db、0db,3个不同的μ值分别为2ms、5ms、10ms。
[0026]
步骤2:针对每一种场景情况,任意选取一个感知周期作为第1个感知周期;然后从第1个感知周期开始选定连续的k个感知周期;接着对选定的每个感知周期内的次级用户接收信号进行n次采样,得到每个感知周期内的次级用户接收信号的n个采样值,将第k个感知周期内的次级用户接收信号的第n个采样值记为xk(n),若第k个感知周期内授权信道空闲,则若第k个感知周期内授权信道忙碌,则之后采用现有技术将每个感知周期内的次级用户接收信号的各个采样值的实部和虚部分开;紧接着将每个感知周期内的次级用户接收信号的n个采样值的实部和虚部构成一个样本矩阵,将第k个感知周期内的次级用户接收信号的n个采样值的实部和虚部构成的样本矩阵记为xk,
再对每个感知周期内授权信道的状态打标签,将第k个感知周期内授权信道的状态标签记为zk,zk的值为0或1,zk的值为0时表示第k个感知周期内授权信道空闲,zk的值为1时表示第k个感知周期内授权信道忙碌;其中,k≥1000,在本实施例中取k=40000,n=ts×fs
,ts表示每个感知周期的时长,在本实施例中取ts为1ms,fs表示采样频率,在本实施例中取fs为1mhz,k为正整数,1≤k≤k,n为正整数,1≤n≤n,lk(n)表示第k个感知周期内的主用户发射信号即主用户信号的第n个采样值,lk(n)服从均值为0方差为的复高斯分布,ωk(n)表示第k个感知周期内的加性高斯白噪声的第n个采样值,ωk(n)服从均值为0方差为的复高斯分布,lk(n)与ωk(n)是相互独立的,由于次级用户接收信号包括主用户发射信号和加性高斯白噪声,或仅包括加性高斯白噪声,因此对次级用户接收信号进行采样,意味着同时对主用户发射信号和加性高斯白噪声进行了相同的采样,n0表示主用户信号离开的时刻,n1表示主用户信号到达的时刻,xk的维数为2
×
n,re()表示取实部操作,im()表示取虚部操作,xk(1)表示第k个感知周期内的次级用户接收信号的第1个采样值,xk(2)表示第k个感知周期内的次级用户接收信号的第2个采样值,xk(n)表示第k个感知周期内的次级用户接收信号的第n个采样值。
[0027]
步骤3:从针对每一种场景情况共得到的k个样本矩阵中随机选择n
train
个样本矩阵,将从n
snr
×nμ
种场景情况共得到的n
snr
×nμ
×
k个样本矩阵中随机选择出的n
snr
×nμ
×ntrain
个样本矩阵及对应的授权信道的状态标签构成训练集,记为y
train
,将n
snr
×nμ
种场景情况共得到的n
snr
×nμ
×
k个样本矩阵中剩余的n
snr
×nμ
×
(k-n
train
)个样本矩阵构成测试集,记为y
test
,其中,其中,表示训练集中的第j个样本矩阵,表示所对应的授权信道的状态标签,表示测试集中的第j'个样本矩阵。
[0028]
步骤4:考虑到卷积神经网络(convolutional neural network,cnn)强大的特征提取能力,本发明使用卷积神经网络作为分类器,同样考虑到分类的复杂情况,本发明构建的卷积神经网络的结构如图2所示,构建卷积神经网络,其包括三个卷积层(convolutional layer,cl)、三个最大池化层(pooling layer,pl)及两个全连接层(fully connect layer,fcl),第1个卷积层的输入端为该卷积神经网络的输入端,第1个卷积层的输出端输出的特征数据经过“relu”激活函数后输入到第1个最大池化层的输入端,第1个最大池化层的输出端输出的特征数据经过“relu”激活函数后输入到第2个卷积层的输入端,第2个卷积层的输出端输出的特征数据经过“relu”激活函数后输入到第2个最大池化层的输入端,第2个最大池化层的输出端输出的特征数据经过“relu”激活函数后输入到第3个卷积层的输入端,第3个卷积层的输出端输出的特征数据经过“relu”激活函数后输入到第3个最大池化层的输入端,第3个最大池化层的输出端输出的特征数据经过“relu”激活函数后输入到第1个全连接层的输入端,第1个全连接层的输出端输出的特征数据经过“relu”激活函数后再经过dropout操作输入到第2个全连接层的输入端,第2个全连接层的输出端输出的特征数据经过“softmax”激活函数后作为该卷积神经网络的输出端输出的特征数据;其中,第1个卷积
层的卷积核大小为3
×
3、卷积核深度为32、卷积步长为1,第2个卷积层的卷积核大小为3
×
3、卷积核深度为64、卷积步长为1,第3个卷积层的卷积核大小为3
×
3、卷积核深度为128、卷积步长为1,第1个最大池化层、第2个最大池化层和第3个最大池化层的池化窗大小为2
×
2、池化步长为2,第1个全连接层的神经元个数为128,第2个全连接层的神经元个数为2,dropout率设置为0.5。
[0029]
步骤5:将训练集中的每个样本矩阵及对应的授权信道的状态标签输入到构建的卷积神经网络中对卷积神经网络进行训练,训练的batch size设置为大于或等于100,训练的优化器采用adam,训练的损失函数(loss function,lf)采用交叉熵函数(cross-entropy function),训练的结束条件为交叉熵函数的值收敛到0附近或迭代次数设置为大于或等于20,在本实施例中训练的batch size设置为1500,迭代次数设置为50;训练结束后得到训练好的卷积神经网络模型及训练集中的每个样本矩阵对应的输出向量,输出向量包含两个元素,分别为授权信道空闲的概率和授权信道忙碌的概率。
[0030]
步骤6:找出训练集中对应的授权信道的状态标签的值为0的所有样本矩阵;然后计算找出的每个样本矩阵对应的输出向量的概率比值,将找出的任一个样本矩阵对应的输出向量的概率比值记为b,接着对找出的所有样本矩阵对应的输出向量的概率比值进行降序排序;再从排序结果中选择第int(s
×
pf)个概率比值作为判决门限,记为λ;其中,p1表示该样本矩阵对应的输出向量中的授权信道忙碌的概率,p0表示该样本矩阵对应的输出向量中的授权信道空闲的概率,p1+p0=1,int()为取整函数,s表示训练集中对应的授权信道的状态标签的值为0的样本矩阵的总个数,pf表示给定的虚警概率(false alarm probability,pf),pf∈[0,1]。
[0031]
步骤7:将测试集中的每个样本矩阵输入到训练好的卷积神经网络模型中进行测试,得到测试集中的每个样本矩阵对应的输出向量;然后计算测试集中的每个样本矩阵对应的输出向量的概率比值,将测试集中的任一个样本矩阵对应的输出向量的概率比值记为b',其中,p1'表示测试集中的任一个样本矩阵对应的输出向量中的授权信道忙碌的概率,p0'表示测试集中的任一个样本矩阵对应的输出向量中的授权信道空闲的概率,p1'+p0'=1。
[0032]
步骤8:将测试集中的每个样本矩阵对应的输出向量的概率比值作为检验统计量;然后将每个检验统计量与λ进行比较,对于任一个检验统计量,如果该检验统计量大于λ,则判定该检验统计量对应的样本矩阵所对应的感知周期内主用户信号到达,即授权信道忙碌;否则,判定该检验统计量对应的样本矩阵所对应的感知周期内主用户信号离开,即授权信道空闲。
[0033]
通过以下仿真来进一步说明本发明方法的可行性和有效性。
[0034]
在本发明方法的仿真中,数据集的数据包含信噪比-10db情况下μ=2ms时的40000组数据、信噪比-10db情况下μ=5ms时的40000组数据、信噪比-10db情况下μ=10ms时的40000组数据、信噪比-5db情况下μ=2ms时的40000组数据、信噪比-5db情况下μ=5ms时的40000组数据、信噪比-5db情况下μ=10ms时的40000组数据、信噪比0db情况下μ=2ms时的40000组数据、信噪比0db情况下μ=5ms时的40000组数据、信噪比0db情况下μ=10ms时的
40000组数据,采样频率设置为1mhz,每个感知周期持续时间长度为1ms,每个感知周期的样本数n设置为1000;第1个卷积层的卷积核大小为3
×
3、卷积核深度为32、卷积步长为1,第1个最大池化层的池化窗大小为2
×
2、池化步长为2;第2个卷积层的卷积核大小为3
×
3、卷积核深度为64、卷积步长为1;第2个最大池化层的池化窗大小为2
×
2、池化步长为2;第3个卷积层的卷积核大小为3
×
3、卷积核深度为128、卷积步长为1;第3个最大池化层的池化窗大小为2
×
2、池化步长为2;第1个全连接层的神经元个数为128,第2个全连接层的神经元个数为2;优化器采用的是adam优化器,学习率设置为0.0001,训练epoch设置为50,batch size设置为1500。
[0035]
图3给出了本发明方法(proposed)与现有的avellr(似然比检测法)方法、w-ed(加权能量法)方法、ed(能量检测)方法在信噪比为-10db并且μ=2ms时的roc曲线的对比。从图3中可以看出,本发明方法实现了优异的检测性能,以虚警概率(probability of false alarm,pf)pf=0.1为例,本发明方法比w-ed方法的检测概率(probability of detection,pd)高出了大约20%,比ed方法高出了大约35%。
[0036]
图4给出了本发明方法(proposed)与现有的avellr(似然比检测法)方法、w-ed(加权能量法)方法、ed(能量检测)方法在噪声不确定性存在(nu=0.5db)时的roc曲线的对比。从图4中可以看出,本发明方法只产生了轻微的性能衰减,以pf为0.1为例,本发明方法的pd只衰减了1%,而其余方法的衰减幅度均超过35%,由此可见,本发明方法对噪声不确定性具有极强的鲁棒性。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1