一种基于遗传算法的语音攻击伪造方法
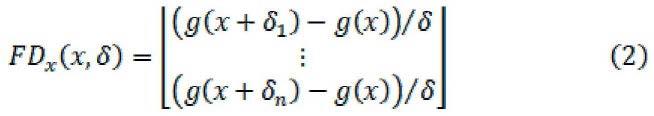
1.本发明属于人工智能安全中的语音攻击技术领域,具体涉及一种基于遗传算 法的语音攻击伪造方法。
背景技术:
2.深度神经网络在大多数机器学习任务,例如图像分类、字幕生成、语音识别 等各种应用中都取得了巨大的成功。虽然神经网络的准确性大大提高,能够基本 与人类的认知能力相匹配,但它们容易受到对抗样本的影响。即使是高度准确的 神经网络也具有该问题。一个很小的对抗性扰动可以欺骗深层神经网络,使其错 误地以高置信度预测特定目标。一个对抗样本是一个神经网络的输入,虽然最初 训练好的神经网络能够将原始音频样本正确识别,但向原始音频样本中添加一个 微小的扰动后,扰动后的音频对抗样本便被训练好的神经网络错误分类。通过设 计音频对抗样本可以对训练有素的基于深度神经网络的语音识别模型成功进行 攻击。
3.目前已经成功开发了一些白盒语音攻击技术,然而在白盒语音攻击技术中, 假设攻击者可以访问模型网络的所有参数在实践中是不现实的。在黑盒攻击方法 的设置中,攻击者只能访问网络的日志或输出,此种生成对抗样本攻击语音识别 模型的方法更加贴近现实情况。而现有的黑盒语音攻击方法计算语音对抗样本过 程中的收敛速度较慢,同时生成的语音对抗样本噪声较为明显。例如文献 1(alzantot m,balaji b,srivastava m.did you hear that adversarial examples againstautomatic speech recognition.arxiv preprint arxiv:1801.00554,2018.)提出了一种使 用标准遗传算法框架生成语音对抗样本的方法,但存在收敛速度较慢,且只能针 对单个英文单词生成对抗性音频样本的问题。
技术实现要素:
4.本发明解决的技术问题:提供一种将遗传算法、梯度估计方法与心理声学隐 藏思想相结合,计算最优的语音对抗样本,达到攻击语音识别模型的目标的基于 遗传算法的语音攻击伪造方法。
5.技术方案:为了解决上述技术问题,本发明采用的技术方案如下:
6.一种基于遗传算法的语音攻击伪造方法,包括以下步骤:
7.s1:针对待攻击的语音识别模型,使用遗传算法搜索音频对抗样本最优解;
8.s2:在使用遗传算法即将寻找出音频对抗样本最优解时,使用梯度估计方法 继续计算最优解;
9.s3:使用心理声学隐藏思想,对步骤s2得到的音频样本计算需要添加或修改 的扰动大小;
10.s4:重复步骤s1、s2和s3,直到计算出最优的音频对抗样本。
11.进一步地,步骤s1中,遗传算法接收一个音频样本输入集合,通过选择、 交叉、变异三个步骤反复迭代,对每次迭代过程中生成的音频样本进行改进并添 加噪声,使受到噪
声干扰的对抗性音频样本与原音频样本类似,但被解码为特定 的目标标签。
12.进一步地,在选择步骤中,对于每次迭代过程,计算音频集合中每个样本的 得分,以确定哪些音频样本是最好的;采用的适应度函数是连接主义时间分类损 失,然后通过从音频集合中选择具有最高评分的音频样本来形成精英群体。
13.进一步地,在交叉步骤中,从精英群体中选择两个音频样本作为亲代样本并 执行交叉,通过从两个亲代样本中分别提取大约一半的特征来创建一个子代音频 样本;选择音频样本作为亲代音频样本的依据是样本采用适应度函数的计算得 分。
14.进一步地,在变异步骤中,将以一定的概率对交叉步骤生成的子代音频样本 添加一个变异,采用动量突变方法计算变异概率,最后根据动量突变方法更新变 异概率,使新的突变概率在每次迭代中更新而变化,并进入下一次迭代;通过多 次迭代,音频种群得到持续改善,最终,算法将达到最大迭代次数并返回当前生 成的音频对抗样本,或者得到符合条件的音频对抗样本,该音频对抗样本将解码 为目标。
15.进一步地,新的突变概率p
new
在每次迭代中根据下式(1)的加权更新而变 化,并进入下一次迭代,
[0016][0017]
其中,p
old
为上一次迭代中计算的突变概率,currscore为当前计算的音频 种群中最高的适应度得分,prevscore为上一次迭代中所计算的音频种群中最高 的适应度得分,α和β为平衡突变概率与适应度得分权重的参数。
[0018]
进一步地,步骤s2中,使用的梯度估计方法计算最优解的方法如式(2)所 示:
[0019][0020]
其中,x指的是能够表示音频文件的输入向量,δi指的是一个值充分小的扰 动向量,g(
·
)表示评估函数,具体为ctc loss函数。
[0021]
进一步地,步骤s3中,使用心理声学隐藏思想计算音频样本需要添加或修 改的扰动大小的方法,具体包括以下步骤:
[0022]
s31:对于给定的音频输入,计算其掩蔽阈值;
[0023]
s32:扰动大小δ仅受掩蔽阈值约束,具体来说,在每次迭代中,对于遗传 算法和梯度估计产生的音频对抗样本,为对其添加的扰动进行优化,使用式(3) 更新扰动δ:
[0024][0025]
其中,lr2为学习速率,为l相对于δ的梯度,l(
·
)为损失函数,α为损失平 衡参数,初始时α为一个充分小的值,并根据攻击过程的变化自适应更新。 有益效果:与现有技术相比,本发明具有以下优点:
[0026]
(1)在遗传算法的变异步骤中使用动量突变方法,为突变概率增加了加速 度,当算法陷入局部最值时,相比在变异步骤仅使用常量突变概率,动量突变通 过保持较高的突变概率,允许突变累积并相互叠加。有助于算法跳出局部最大值, 同时收敛得比常量突变概率更快;
[0027]
(2)使用心理声学隐藏思想,通过优化音频样本所需的扰动,将对抗性扰 动添加到人类听觉频率范围之外,从而提高了生成的语音对抗样本的不易察觉 性。
附图说明
[0028]
图1是基于遗传算法的语音攻击伪造方法结构示意图。
具体实施方式
[0029]
下面结合具体实施例,进一步阐明本发明,实施例在以本发明技术方案为前 提下进行实施,应理解这些实施例仅用于说明本发明而不用于限制本发明的范 围。
[0030]
如图1所示,本发明中的基于遗传算法的黑盒语音攻击方法,将遗传算法、 梯度估计方法与心理声学隐藏思想相结合,计算最优的语音对抗样本,达到攻击 语音识别模型的目标。本发明能够有助于算法跳出局部最值,提高收敛速度,同 时提高了生成的语音对抗样本的不易察觉性。包括以下步骤:
[0031]
步骤s1:针对待攻击的语音识别模型,使用遗传算法搜索音频对抗样本最 优解。
[0032]
遗传算法接收一个音频样本输入集合,通过选择、交叉、变异三个步骤反复 迭代,对每次迭代过程中生成的音频样本进行改进并添加噪声,从而使受到噪声 干扰的对抗性音频样本与原音频样本类似,但被解码为特定的目标标签。
[0033]
选择:在该步骤中,对于每次迭代过程,计算音频集合中每个样本的得分, 以确定哪些音频样本是最好的。采用的适应度函数是连接主义时间分类损失 (ctc loss),它能够确定输入音频序列和给定目标短语之间的相似性。然后通过 从音频集合中选择具有最高评分的音频样本来形成精英群体。精英群体中含有希 望遗传给后代的具有理想特征的音频样本。
[0034]
交叉:在该步骤中,从精英群体中选择两个音频样本作为亲代样本并执行交 叉,通过从两个亲代样本中分别提取大约一半的特征来创建一个子代音频样本。 选择音频样本作为亲代音频样本的依据是样本采用适应度函数的计算得分。
[0035]
变异:在该步骤中,将以一定的概率对交叉步骤生成的子代音频样本添加一 个变异。计算该变异概率使用的是动量突变方法。最后根据动量突变方法更新变 异概率,使新的突变概率p
new
在每次迭代中根据式(1)的加权更新而变化,并进入 下一次迭代。
[0036][0037]
其中p
old
为上一次迭代中计算的突变概率,currscore为当前计算的音频种 群中最高的适应度得分,prevscore为上一次迭代中所计算的音频种群中最高的 适应度得分,α和β为平衡突变概率与适应度得分权重的参数。
[0038]
通过多次迭代,音频种群将得到持续改善,因为只有前几代的最佳性状以及 最佳突变将保留下来。最终,算法将达到最大迭代次数并返回当前生成的音频对 抗样本,或者得到符合条件的音频对抗样本,该音频对抗样本将解码为目标。
[0039]
步骤s2:在使用遗传算法即将寻找出音频对抗样本最优解时,使用梯度估 计方法继续计算最优解。具体来说,当当前解码与目标解码的编辑距离低于某个 阈值时,使用梯度估计方法来计算音频对抗样本。
[0040]
使用的梯度估计方法如式(2)所示:
[0041][0042]
其中,x指的是能够表示音频文件的输入向量,δi指的是一个值充分小的扰 动向量。g(
·
)表示评估函数,本方法中指的是ctc loss函数。方法本质上是在 向量的每个索引上添加一个小扰动,该方法中只对每一代的音频样本随机抽取 100个指标来添加扰动。并独立查看ctc loss的差异,以此计算关于输入向量x 的梯度估计。
[0043]
步骤s3:使用心理声学隐藏思想,对步骤s2得到的音频样本计算需要添加 或修改的扰动大小,使生成的语音对抗样本更加不容易被察觉。具体方法如下:
[0044]
步骤s31:对于给定的音频输入,计算其掩蔽阈值。
[0045]
步骤s32:在此步骤中,扰动大小δ仅受掩蔽阈值约束。具体来说,在每次 迭代中,对于遗传算法和梯度估计产生的音频对抗样本,为对其添加的扰动进行 优化,使用式(3)更新扰动δ:
[0046][0047]
其中lr2为学习速率,为l相对于δ的梯度,l(
·
)为损失函数,α为损失平衡 参数,初始时α为一个充分小的值,并根据攻击过程的变化自适应更新,具体来 说,在每20次迭代中,如果当前的对抗样本成功地欺骗了受害模型,那么α就 会适当增加,以试图使对抗样本更不易察觉,在每50次迭代中,如果当前的对 抗样本未能得到有目标的预测结果,那么适当减少α的值。
[0048]
步骤d:重复步骤s1、s2、s3,直到计算出最优的音频对抗样本。
[0049]
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技 术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些 改进和润饰也应视为本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1