声音输入装置的制作方法
1.本发明涉及一种声音输入装置。更具体地说明,本发明涉及一种颈挂型装置,其能佩戴于佩戴者的颈部且适于取得佩戴者及其对话者的声音。
背景技术:
2.近年来,可佩戴于用户的身体的任意处且感测用户的状态及其周围环境的状态的可穿戴设备备受瞩目。作为可穿戴设备,已知例如有能佩戴于用户的腕部、眼部、耳部、颈部或用户所穿着的衣服等的类型等各种形态。通过将这种可穿戴设备所收集的用户的信息进行解析,可取得对佩戴者或其他人有用的信息。
3.并且,作为可穿戴设备的一种,已知有可佩戴于用户的颈部并将佩戴者或其对话者所发出的声音进行录音的装置(专利文献1、专利文献2)。此专利文献1中公开了一种声音处理系统,其具备佩戴于用户的佩戴部,此佩戴部具有至少三个声音取得部(麦克风),所述声音取得部取得用于波束成形的声音数据。并且,专利文献1所记载的系统中在以夹着佩戴者的嘴的方式设置的左右的臂部的各个上设置声音取得部。尤其专利文献1中提案了一种优选的实施方式,是在左侧的臂部上配置三个声音取得部,且在右侧的臂部上配置一个声音取得部。进一步,专利文献1中为了抑制从地面方向而来的杂音(道路噪声),优选将四个声音取得部的其中一个配置成朝向佩戴者的脚侧。
4.并且,专利文献2记载了一种装置,其为佩戴于用户的颈部的可穿戴设备,且具有声音取得部(麦克风阵列),其在左右的臂部的各个上各设有两处(合计四处)。此专利文献2的装置中公开了通过麦克风阵列来取得从与佩戴者面对的对话者而来的嘴的声音。
5.现有技术文献
6.专利文献
7.专利文献1:日本特开2019-134441号公报
8.专利文献2:美国发明专利申请公开第2019/0138603号说明书
技术实现要素:
9.发明所欲解决的课题
10.不过,由于专利文献1的系统在佩戴者的嘴部的周围配置有多个麦克风,因此可通过波束成形处理来提取所述佩戴者所发出的声音。但是,由于此系统中一个臂部上设有三处麦克风,相对之下另一个臂部上仅设有一处麦克风,因此可适当地取得在佩戴者的周围发出的声音(环境音或对话者的声音等)的范围会偏向于佩戴者的左右某一个区域。亦即,为了通过波束成形处理来强调特定音(佩戴者或对话者的声音等),或者抑制其他杂音,特定音需要直线到达至少三个麦克风。此时,例如,在佩戴者的右侧产生特定音的情形下,特定音直线会到达设于右侧的臂部上的三处麦克风,但在佩戴者的左侧产生特定音的情形下,由于在左侧的臂部上仅设置了一处麦克风,因此会根据特定音的产生的位置而导致声音被佩戴者的头部等遮挡,特定音则难以直线到达三处以上的麦克风。此情形,很有可能无
法对在佩戴者的左侧产生的声音适当地进行波束成形处理。如此,专利文献1的系统是以将多个麦克风偏向配置为前提的系统,虽然能取得从佩戴者的嘴发出的声音,但并不是适合取得其他周围环境音的设计。
11.并且,专利文献2的装置被认为由于在左右的臂部的各个上各设有两处(合计四处)麦克风,因此相较于专利文献1的系统可更有效地对从佩戴者及对话者发出的声音进行波束成形处理。但是,专利文献2的装置中仅假设佩戴者与一名对话者进行对话。具体而言,对于佩戴者及两名对话者的合计三人中的对话,专利文献2的装置难以对每个人所发出的声音个别进行波束成形处理。亦即,为了适当地进行波束成形处理,对于一个音源,需要通过至少三处麦克风来取得声音,从各麦克风所取得的声音成分来确定该音源在空间上的位置,而强调来自该音源的声音成分,或者抑制除此之外的声音成分。在此,在假设与佩戴者面对的对话者有两名且此两名对话者同时发声的情形下,若如专利文献2的装置般地仅设置四处麦克风,则针对至少两处麦克风,只要未从由麦克风取得的声音成分中分离出从两名对话者发出的声音成分,就无法正确地确定两名对话者的音源位置。因此,在包括佩戴者及两名对话者的对话场景中,专利文献2的装置存在有时无法执行适当的波束成形处理的问题。并且,在假设对话者位于佩戴者的左后方或右后方的情形下,若如专利文献2的装置般地仅设置四处麦克风,则有时佩戴者的头部会成为障碍而对话者的声音不能直线到达三处麦克风。因此,也存在下述问题:在佩戴者的后方宽广地存在着无法进行波束成形的范围(不可听范围)。
12.因此,本发明的主要目的在于提供一种可适当地将包括佩戴者及两名对话者的对话的声音都取得的声音输入装置。
13.解决课题的技术方案
14.本发明的发明人等针对现有发明所存在的问题的解决方案进行深入研究的结果,得到如下见解:在配置于夹着对象音源的位置的两个臂部的各个上各配置三处以上(合计六处以上)的集音部(麦克风),借此可同时取得包括佩戴者及两名对话者的对话的声音。而且,本发明人等基于上述见解而想到可解决现有发明的问题,并使本发明完成。若具体地说明,则本发明具有以下的构成。
15.本发明涉及一种声音输入装置。本发明的声音输入装置具备两个臂部及多个集音部。两个臂部构成为能配置于夹着对象音源的位置。对象音源的例子为佩戴者的嘴。在两个臂部的各个上设有三处以上的集音部。具体而言,在一个臂部上设有三处以上的集音部,且在另一个臂部上设有32处以上的集音部。此外,也可在各臂部上各设置四处以上或各五处以上的集音部。本发明的声音输入装置的优选实施方式为佩戴于用户的颈部的颈挂型装置。但是,声音输入装置只要为具有能配置于夹着对象音源(佩戴者的嘴)的位置的臂部的装置,则也可采用眼镜型或耳挂型等其他形态。
16.如上述构成,通过在两个臂部上分别设置三处以上的集音部,不仅是从臂部所夹着的对象音源(例如佩戴者的嘴)发出的声音,亦能同时取得在对象音源的周围产生的声音。尤其,即使在与佩戴者面对的两名对话者同时发话的情形下,也能基于由一个臂部的三处集音部所取得的声音来强调第一对话者的声音成分,并基于由另一个臂部的三处集音部所取得的声音来强调第二对话者的声音成分。因此,即使在佩戴者及两名对话者的合计三人进行对话的情形下,也能对所有人的声音执行适当的声音处理。另外,通过在两个臂部上
预先各设置三处以上的集音部,由于可通过一个臂部上的集音部来取得对话者的声音,因此即使在对话者位于佩戴者的左后方或右后方的情形下,也可对所述对话者的声音进行波束成形处理。亦即,根据本发明的构成,能够缩小存在于佩戴者的后方的无法进行波束成形处理的范围(不可听范围)。
17.优选地,本发明的声音输入装置进一步具备声音解析部。声音解析部基于由各集音部所取得的声音来确定发出所述声音的音源在空间上的位置或方向。声音解析部也可求出由各集音部所取得的声音的取得时间的差,并基于所述取得时间的差来确定所述声音的音源的位置或方向。并且,声音解析部也可以参照机械学习后的习得模型来确定由各集音部所取得的声音的音源在空间上的位置或方向。由此,可根据由各集音部所取得的声音的音源的位置或方向,将所述声音进行强调或抑制等所谓波束成形处理。
18.优选地,本发明的声音输入装置为颈挂型装置,且以佩戴者的嘴作为对象音源。为了将佩戴者及其对话者的声音进行录音,优选利用颈挂型装置。
19.在本发明的声音输入装置中,优选地,声音解析部判断基于由设置于第一臂部上的三个以上的集音部所取得的声音而确定的音源与位于佩戴者的第一臂部侧的第一对话者的嘴是否一致,并且判断基于由设置于第二臂部上的三个以上的集音部所取得的声音而确定的音源与位于佩戴者的第二臂部侧的第二对话者的嘴是否一致。由此,针对第一对话者的声音,可通过第一臂部的三个以上的集音部来录音并进行声音强调,且针对第二对话者的声音,可通过第二臂部的三个以上的麦克风来录音并进行声音强调。如此,通过单独利用第一臂部上的集音部与第二臂部上的集音部,在第一对话者与第二对话者同时发话的情形下,能提高各说话者的声音成分的分离性能。
20.优选地,本发明的声音输入装置进一步具备声音处理部。声音处理部基于声音解析部所确定的音源的位置或方向,进行强调或抑制由集音部取得的声音数据中所包括的声音成分的处理。或者,声音处理部也可基于声音解析部所确定的音源的位置或方向,同时进行强调或抑制由集音部取得的声音数据中所包括的声音成分的处理。例如,对于由佩戴者的第一臂部上的集音部所取得的声音数据,基于由所述第一臂部上的集音部所取得的声音成分而强调第一对话者的声音成分,同时利用由第二臂部上的集音部所取得的声音成分抑制第一对话者的声音成分以外的成分(主要是第二对话者的声音成分)。同样地,对于由佩戴者的第二臂部上的集音部所取得的声音数据,基于由所述第二臂部上的集音部所取得的声音成分而强调第二对话者的声音成分,同时利用由第一臂部上的集音部所取得的声音成分抑制第二对话者的声音成分以外的成分(主要是第一对话者的声音成分)。如此,通过单独利用第一臂部上的集音部与第二臂部上的集音部,能够强调或抑制第一对话者及第二对话者的声音成分。
21.本发明的声音输入装置可为一种颈挂型装置,且可在与佩戴者的颈后相应的位置进一步具备一个或多个集音部。如此,通过预先将集音部设置于与佩戴者的颈后相应的位置,也可适当地收集佩戴者的背部侧的声音。尤其,预先在左右的臂部的各个上各设置三处集音部,并且预先将集音部进一步设置于佩戴者的颈后,由此,即使对于佩戴者的背部侧的音源也可进行波束成形。设置于佩戴者的颈后的追加集音部可为一个,也可为两个以上。并且,为了仅通过设置于佩戴者的颈后的追加集音部对佩戴者的背部侧的音源进行波束成形,也可将此集音部设置三个以上。
22.发明效果
23.根据本发明,可够提供一种能适当地将包括佩戴者及两名对话者的对话的声音都取得的声音输入装置。
附图说明
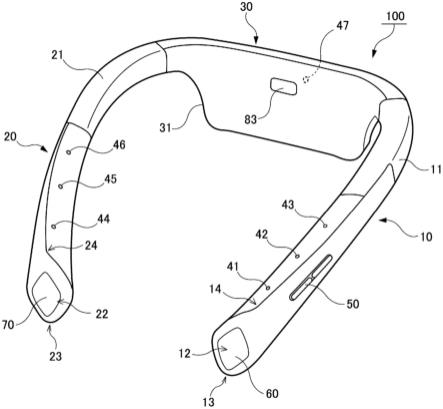
24.[图1]图1是表示颈挂型声音输入装置的一例的立体图;
[0025]
[图2]图2是示意性地表示佩戴声音输入装置的状态的侧视图;
[0026]
[图3]图3是表示声音输入装置的功能构成例的方框图;
[0027]
[图4]图4示意性地表示取得佩戴者及一名对话者的声音的波束成形处理;
[0028]
[图5]图5示意性地表示取得佩戴者及一名对话者的声音的波束成形处理;
[0029]
[图6]图6示意性地表示取得佩戴者及两名对话者的声音的波束成形处理;
[0030]
[图7]图7是表示取得佩戴者及两名对话者的声音的波束成形处理的例子的流程图。
具体实施方式
[0031]
以下使用附图说明本发明的具体实施方式。本发明并不限定于以下说明的方式,也包括在本领域技术人员显而易知的范围内从以下方式进行适当变更而成的方式。
[0032]
图1表示颈挂型装置100作为本发明的声音输入装置的一个实施方式。并且,图2表示佩戴颈挂型装置100的状态。如图1所示,构成颈挂型装置100的壳体具备左臂部10、右臂部20及主体部30。左臂部10与右臂部20分别从主体部30的左端与右端朝向前方延伸,在俯视时,颈挂型装置100成为装置整体大致呈u字的构造。在佩戴颈挂型装置100时,如图2所示,只要使主体部30接触佩戴者的颈后,并使左臂部10与右臂部20从佩戴者的颈侧朝向胸部侧垂下,将整个装置挂在颈部即可。在颈挂型装置100的壳体内容纳有各种电子零件。
[0033]
在左臂部10与右臂部20分别设有多个集音部(麦克风)41~46。集音部41~46主要是以取得佩戴者及其对话者的声音为目的而配置。如图1所示,在左臂部10设置第一集音部41、第二集音部42及第三集音部43,而右臂部20设置第四集音部44、第五集音部45及第六集音部46。此外,也可在左臂部10与右臂部20追加设置一个或多个集音部作为任意的要素。进一步,也可在位于左臂部10与右臂部20之间的主体部30设置第七集音部47作为任意追加要素。此第七集音部47设置于与佩戴者的颈后相应的位置,且以取得来自佩戴者的背部的声音为目的而配置。由这些集音部41~47所取得的声音信号被传递至设置于主体部30内的控制部80(参照图3)并进行预定的解析处理。此外,在主体部30中内置有包括此种控制部80的电子电路或电池等的控制系统电路。
[0034]
第一集音部41至第六集音部46分别设置于左臂部10与右臂部20的前方(佩戴者的胸部侧)。具体而言,在假设将颈挂型装置100佩戴于一般成人男性(颈围35cm~37cm)的颈部的情形下,优选设计成至少第一集音部41至第六集音部46位于比佩戴者的颈部更靠前方(胸部侧)。颈挂型装置100为假设会同时收集佩戴者及对话者的声音的装置,且通过将各集音部41~46配置于佩戴者的颈部的前方侧,不仅可取得佩戴者的声音,还可适当地取得其对话者的声音。并且,优选地,左臂部10上的第一集音部41至第三集音部43与右臂部20上的第四集音部44至第六集音部46以呈左右对称的方式配置。具体而言,第一集音部41与第四
集音部44、第二集音部42与第五集音部45、以及第三集音部43与第六集音部46分别配置于线对称位置。
[0035]
在左臂部10进一步设有摄像部60。具体而言,在左臂部10的前端面12设有摄像部60,可通过此摄像部60摄影佩戴者的正面侧的静止图像或动态图像。由摄像部60所取得的图像被传递至主体部30内的控制部80,并存储作为图像数据。并且,也可利用互联网将由摄像部60所取得的图像传送至服务器装置。也可从摄像部60所取得的图像确定对话者的嘴的位置,并进行强调从其嘴部发出的声音的处理(波束成形处理)。
[0036]
在右臂部20进一步设有非接触型的传感部70。传感部70主要以感测颈挂型装置100的正面侧的佩戴者的手部动作为目的,且配置于右臂部20的前端面22。传感部70的感测信息主要被利用于摄像部60的启动,摄影的开始、停止等。例如,传感部70可感测佩戴者的手等物体接近其传感部70而控制摄像部60,或者也可在传感部70的感测范围内感测佩戴者做出预定的手势而控制摄像部60。此外,在本实施方式中,虽然将摄像部60配置于左臂部10的前端面12,并将传感部70配置于右臂部20的前端面22,但也能将摄像部60与传感部70的位置进行交换。
[0037]
并且,也能将传感部70中的感测信息利用于启动摄像部60、集音部41~47和/或控制部80(主cpu)。例如,可在传感部70、集音部41~47及控制部80常时启动而摄像部60停止中的状态下,在以传感部70感测出特定的手势时使摄像部60启动(条件1)。此外,在此条件1中,也能在集音部41~47感测出特定音时使摄像部60启动。或者也可在传感部70及集音部41~47常时启动而控制部80及摄像部60停止中的状态下,在以传感部70感测出特定的手势时使控制部80及摄像部60之中的任意一者启动(条件2)。在此条件2中,也能在集音部41~47感测出特定音时使控制部80及摄像部60启动。或者,也可在仅传感部70常时启动而集音部41~47、控制部80及摄像部60停止中的状态下,在以传感部70感测出特定的手势时使集音部41~47、控制部80及摄像部60之中的任意一者启动(条件3)。上述条件1~条件3可以说消耗电力的削减效果大小按照条件3》条件2》条件1的顺序。
[0038]
上述左臂部10与右臂部20能配置于夹着颈部的位置。此左臂部10与右臂部20是由设置在抵接于佩戴者的颈后的位置的主体部30所连接。此主体部30中内置有处理器及电池等的电子零件(控制系统电路)。如图1所示,构成主体部30的壳体呈大致平坦的形状,且可容纳平面状(板状)的电路基板及电池。并且,主体部30具有比左臂部10及右臂部20更向下方延伸的下垂部31。通过在主体部30设置下垂部31,来确保用于内置控制系统电路的空间。并且,主体部30中集中装配控制系统电路。此控制系统电路包括有:电池;以及电路基板,其装配有从电池接收电力的供给而驱动的处理器等各种电子零件。因此,在将颈挂型装置100的总重量设为100%的情形下,主体部30的重量占40%~80%或50%~70%。通过将此种重量大的主体部30配置于佩戴者的颈后,来提升佩戴时的稳定性。并且,通过将重量大的主体部30配置于接近佩戴者的躯干的位置,可减轻装置整体的重量对佩戴者所造成的负担。
[0039]
并且,在主体部30的内侧(佩戴者侧)设有接近传感器83。接近传感器83只要预先装配于例如电路基板85内侧的面即可。接近传感器83为用于感测物体的接近,若颈挂型装置100被佩戴于佩戴者的颈部,则会感测出其颈部的接近。因此,在接近传感器83感测出物体的接近的状态时,将各集音部41~47、摄像部60及传感部70等设备开启(驱动状态),在接近传感器83未感测出物体接近的状态时,只要将这些设备设成关闭(休眠状态)、或设成无
法启动的状态即可。由此,可有效率地抑制电池90的电力消耗。并且,在接近传感器83未感测出物体接近的状态时,通过使摄像部60与集音部41~47无法启动,也可期待在不佩戴时防止蓄意或非蓄意地记录数据的效果。此外,作为接近传感器90,可使用公知的传感器,但在使用光学式传感器的情形下,为了使接近传感器90的感测光穿透,可在主体部壳体32设置用于使感测光穿透的穿透部32a。
[0040]
此外,也可分别控制第一集音部41至第六集音部46及作为任意追加性要素的第七集音部47。亦即,第七集音部47是以取得来自佩戴者的背部方向的声音为目的而设置的构件,不需要以此第七集音部47取得来自佩戴者的前方的声音。于是,在一般的场景下,若首先预先启动第一集音部41至第六集音部46,则不需要启动第七集音部47。另一方面,在通过第一集音部41至第六集音部46感测出来自佩戴者的背部方向的声音的情形,或者通过这些集音部41~46感测出无法适当地进行波束成形的声音的情形下,使第七集音部47启动。如此,针对第七集音部47,通过与第一集音部41至第六集音部46独立控制开启/关闭,能够抑制消耗电力,且有效率地利用此第七集音部47。
[0041]
并且,在主体部30的外侧(佩戴者的相反侧)设有放音部84(扬声器)。只要预先将放音部84装配于例如电路基板85外侧的面即可。如图2所示,在本实施方式中,放音部84配置成朝向主体部30的外侧输出声音。如此,通过从佩戴者的颈后朝向正后方放出声音,从此放音部84输出的声音变得不易直接传至存在于佩戴者的正面前方的对话者。由此,可防止对话者将佩戴者自身所发出的声音与从颈挂型装置的放音部发出的声音混淆的状况。并且,在本实施方式中,在左臂部10与右臂部20设有第一集音部41至第六集音部46,但通过预先将放音部84设置于与佩戴者的颈后相应的位置,可最大限度地隔开放音部84与集音部41~46的物理距离。亦即,在以各集音部41~46收集佩戴者或对话者的声音的状态下,若从放音部84输出某些声音,则会有来自放音部84的声音(自我输出音)混入所收录的佩戴者等的声音的情形。若自我输出音混入收录声音,则会妨碍声音识别,因此必须通过回声消除处理等来将此自我输出音去除。然而,实际上受到壳体振动等的影响,即使进行了回声消除处理,也难以完全去除自我输出音。因此,为了将混入佩戴者等的声音中的自我输出音的音量最小化,优选如同上述将放音部84设置于与佩戴者的颈后相应的位置,而隔开与集音部的物理距离。
[0042]
并且,放音部84优选设置于偏向左右任一边的位置,而不设置于与佩戴者的颈后方的中央相应的位置。其理由是因为相较于位于颈后中央的情形,放音部84变得更接近左右任一耳。如此,通过将放音部84配置于偏向左右任一边的位置而非主体部30的大致中央,即使在降低输出音的音量的情形下,佩戴者也可利用左右任一耳清楚地听到输出音。并且,若输出音的音量变小,则此输出音不易传至对话者,因此对话者也可避免将佩戴者的声音与放音部84的输出音混淆。
[0043]
并且,作为颈挂型装置100的构造特征,左臂部10与右臂部20在与主体部30的连结部位附近具有柔性部11、21。柔性部11、21是由橡胶或硅树脂等可挠性材料所形成。因此,在佩戴颈挂型装置100时,左臂部10及右臂部20变得容易贴合于佩戴者的颈部或肩上。此外,柔性部11、21中也插通有将第一集音部41至第六集音部46与操作部50连接于控制部80的配线。
[0044]
图3是表示颈挂型装置100的功能构成的框图。如图3所示,颈挂型装置100具有第
一集音部41至第七集音部47、操作部50、摄像部60、传感部70、控制部80、存储部81、通信部82、接近传感器83、放音部84及电池90。在本实施方式中,在左臂部10配置有第一集音部41、第二集音部42、第三集音部43、操作部50及摄像部60。并且,在右臂部20配置有第四集音部44、第五集音部45、第六集音部46及传感部70。并且,在主体部30配置有控制部80、存储部81、通信部82、接近传感器83、放音部84、第七集音部47及电池90。此外,颈挂型装置100除了图3所示的功能构成,还可适当装配陀螺仪传感器、加速度传感器、地磁传感器或gps传感器等传感类等的装配于一般便携型信息终端的模块设备。
[0045]
作为各集音部41~47,只要采用动态麦克风、电容式麦克风、mems(micro-electrical-mechanical systems,微机电系统)麦克风等公知的麦克风即可。集音部41~47将声音转换成电信号,通过放大电路来增强其电信号后,通过a/d转换电路转换成数字信息并输出至控制部80。本发明的颈挂型装置100的目的之一在于不仅取得佩戴者的声音,还取得存在于其周围的一名或多名对话者的声音。因此,为了可广泛收集在佩戴者周围所产生的声音,作为各集音部41~47,优选采用全指向性(无指向性)的麦克风。
[0046]
操作部50接收由佩戴者所进行的操作的输入。作为操作部50,可采用公知的开关电路或触控面板等。操作部50例如接收下述操作:指示声音输入的开始或停止的操作、指示装置电源的开或关的操作、指示扬声器的音量的提高或降低的操作、或其他实现颈挂型装置100的功能所需的操作。通过操作部50而输入的信息被传输至控制部80。
[0047]
摄像部60取得静止图像或动态图像的图像数据。作为摄像部60,只要采用一般的数字摄像机即可。摄像部60例如由下述所构成:摄像镜头、机械快门、快门驱动器、ccd图像传感单元等光电转换元件、从光电转换元件读取电荷量并生成图像数据的数字信号处理器(dsp),以及ic存储器。并且,摄像部60优选为具备:自动聚焦传感器(af传感器),其测量从摄像镜头至被摄体的距离;以及调整机构,其用于根据此af传感器所感测出的距离来调整摄像镜头的焦点距离。af传感器的种类并无特别限定,只要使用相位差传感器或对比度传感器之类的公知的被动式的传感器即可。并且,作为af传感器,也可使用主动式的传感器,所述主动式的传感器将红外线或超声波朝向被摄体并接收其反射光或反射波。由摄像部60所取得的图像数据被供给至控制部80并存储于存储部81,进行预定的图像解析处理或通过通信部82经由互联网传送至服务器装置。
[0048]
并且,摄像部60优选具备所谓的广角镜头。具体而言,摄像部60的垂直方向视角优选为100度~180度,特别优选为110度~160度或120度~150度。如此,通过将摄像部60的垂直方向视角设成广角,可广泛摄影至少从对话者的头部至胸部,视情形也能摄影对话者的全身。并且,摄像部60的水平方向视角并无特别限制,但优选采用100度~160度左右的广角。
[0049]
并且,摄像部60由于一般消耗电力较大,因此优选仅在需要的情形下启动,此外的情形则成为休眠状态。具体而言,虽然基于传感部70或接近传感器83的感测信息来控制摄像部60的启动以及摄影的开始或停止,但亦可在摄影停止后经过一定时间的情形下,将摄像部60再次设为休眠状态。
[0050]
传感部70是用于感测佩戴者的手指等物体的动作的非接触型的感测装置。传感部70的例子为接近传感器或手势传感器。接近传感器例如感测佩戴者的手指接近预定的范围。作为接近传感器,可采用光学式、超声波式、磁式、静电容式或温感式等公知的传感器。
手势传感器例如感测佩戴者的手指的动作或形状。手势传感器的例子为光学式传感器,通过从红外发光led朝向对象物照射光并以受光元件捕捉其反射光的变化,来感测出对象物的动作或形状。由传感部70所得的感测信息被传递至控制部80,主要利用于控制摄像部60。并且,也能基于由传感部70所得的感测信息来对各集音部41~47进行控制。由于传感部70一般消耗电力较小,因此优选在颈挂型装置100的电源开启期间常时启动。并且,也可在通过接近传感器83感测出颈挂型装置100的佩戴时使传感部70启动。
[0051]
控制部80进行控制颈挂型装置100所具备的其他要素的运算处理。作为控制部80,可利用cpu等处理器。控制部80基本上是读取存储于存储部81的程序,遵循此程序来执行预定的运算处理。并且,控制部80可将遵循程序而得的运算结果适当写入存储部81或从存储部81读取。详细内容后述,但控制部80主要具有用于进行摄像部60的控制处理或波束成形处理的声音解析部80a、声音处理部80b、输入解析部80c、摄像控制部80d及图像解析部80e。这些要素80a~80e基本上是以软件上的功能来实现。但是,这些要素也能以硬件的电路来实现。
[0052]
存储部81是用于存储控制部80中的运算处理等所使用的信息及其运算结果的要素。若具体而言,存储部81存储一程序,使通用的便携型的信息通信终端发挥作为本发明的声音输入装置的功能。若根据来自用户的指示而启动此程序,则通过控制部80来执行遵循程序的处理。存储部81的存储功能可通过例如hdd及sdd之类的非挥发性存储器来实现。并且,存储部81也可具有作为存储器的功能,所述存储器用于写入或读取控制部80所进行的运算处理的中间过程等。存储部81的存储器功能可通过ram或dram之类的挥发性存储器来实现。并且,也可在存储部81存储既有用户的固有的id信息。并且,也可在存储部81存储ip地址,所述ip地址是颈挂型装置100在网络上的识别信息。
[0053]
并且,也可在存储部81存储控制部80所进行的波束成形处理中利用的习得模型。习得模型例如是通过在云端上的服务器装置中进行深度学习或强化学习等机械学习而得到的推论模型。若具体说明,在波束成形处理中,将由多个集音部所取得的声音数据进行解析,来确定产生所述声音的音源的位置或方向。此时,例如,将服务器装置所具有的音源的位置信息与以多个集音部取得从所述音源产生的声音的数据的数据组(教师数据)大量累积,实施使用这些教师数据的机械学习而预先建立习得模型。然后,在个别的颈挂型装置100通过多个集音部取得声音数据时,可通过参照此习得模型而有效地确定音源的位置或方向。并且,颈挂型装置100也可通过与服务器装置通信而随时更新此习得模型。
[0054]
通信部82是用于与云端上的服务器装置或其他颈挂型装置进行无线通信的要素。为了通过互联网与服务器装置或其他颈挂型装置进行通信,通信部82例如只要采用用于以3g(w-cdma)、4g(lte/lte-advanced)、5g之类的公知的移动通信规格或wi-fi(注册商标)等无线lan方式进行无线通信的通信模块即可。并且,为了与其他颈挂型装置直接进行通信,通信部82也可采用bluetooth(注册商标)或nfc等方式的近距离无线通信用的通信模块。
[0055]
接近传感器83主要用于感测颈挂型装置100(特别是主体部30)与佩戴者的接近。作为接近传感器83,如前述可采用光学式、超声波式、磁式、静电容式或温感式等公知的传感器。接近传感器83被配置于主体部30的内侧,感测佩戴者的颈部已接近预定的范围内。在通过接近传感器83感测出佩戴者的颈部接近的情形下,可启动各集音部41~47、摄像部60、传感部70和/或放音部84。此外,如同前述,也能在通过接近传感器83感测出佩戴者的颈部
接近的情形下,首先仅使第一集音部41至第六集音部46启动並预先将第七集音部47设成关闭的状态,直到感测出来自佩戴者的背部方向的声音。
[0056]
放音部84是将电信号转换成物理性振动(亦即声音)的音响装置。放音部84的例子为通过空气振动将声音传递至佩戴者的一般扬声器。此情形下,如前述般,优选构成为:将放音部84设置于主体部30的外侧(佩戴者的相反侧),朝向远离佩戴者的颈后的方向(水平方向后方)或沿着颈后的方向(铅直方向上方)放出声音。并且,作为放音部84,也可为通过使佩戴者的骨骼振动而将声音传递至佩戴者的骨传导扬声器。此情形下,只要构成为下述即可:将放音部84设置于主体部30内侧(佩戴者侧),使骨传导扬声器接触佩戴者的颈后的骨骼(颈椎)。
[0057]
电池90是对颈挂型装置100所包括的各种电子零件供给电力的电池。作为电池90,可使用能充电的蓄电池。电池90只要采用锂离子电池、锂聚合物电池、碱性蓄电池、镍镉电池、镍氢电池或铅蓄电池等公知的电池即可。电池90配置成在主体部30的壳体内,并使电路基板介于电池90与佩戴者的颈后之间。
[0058]
接着,参照图4至图6具体说明波束成形处理的基本概念。若用户佩戴图1所示的实施方式的颈挂型装置100,如图4(a)及图4(b)所示,六个集音部41~46位于佩戴者的颈部的胸部侧。第一集音部41至第六集音部46皆为全指向性的麦克风,且常时主要收集从佩戴者的嘴发出的声音,并收集其他的佩戴者周围的环境音。环境音包括位于佩戴者的周围的对话者的声音。若佩戴者和/或对话者发出声音,则通过各集音部41~46取得声音数据。各集音部41~46将各自的声音数据输出至控制部80。
[0059]
控制部80的声音解析部80a进行解析由各集音部41~46所取得的声音数据的处理。具体而言,声音解析部80a基于各集音部41~46的声音数据来确定发出所述声音的音源在空间上的位置或方向。例如,在将完成机械学习的习得模型安装于颈挂型装置100的情形下,声音解析部80a可参照其习得模型,从各集音部41~46的声音数据来确定音源的位置或方向。或者,由于各集音部41~46之间的距离为已知,因此声音解析部80a也可基于声音到达各集音部41~46的时间差来求出从各集音部41~46至音源的距离,并通过三角测量法从其距离来确定音源的空间位置或方向。根据三角测量法,只要可确定从至少三处集音部至音源的距离,则可确定所述音源的空间位置或方向。因此,即使仅从左臂部10上的第一集音部41至第三集音部43所取得的声音数据也可确定音源的位置等,同样地,即使仅从右臂部20上的第四集音部44至第六集音部46所取得的声音数据也可确定音源的位置等。
[0060]
并且,声音解析部80a判断通过上述处理而确定的音源的位置或方向与被推测为佩戴者的嘴或对话者的嘴的位置或方向是否一致。例如,由于颈挂型装置100与佩戴者的嘴的位置关系或颈挂型装置100与对话者的嘴的位置关系能预料,因此在音源位于其预料范围内的情形下,只要将所述音源判断为佩戴者或对话者的嘴即可。并且,在音源相对于颈挂型装置100明显位于下方、上方或后方的情形下,可判断所述音源并非佩戴者或对话者的嘴。
[0061]
接着,控制部80的声音处理部80b基于声音解析部80a所确定的音源的位置或方向,进行强调或抑制声音数据所包括的声音成分的处理。具体而言,在音源的位置或方向与被推测为佩戴者或对话者的嘴的位置或方向一致的情形下,强调从所述音源发出的声音成分。另一方面,在音源的位置或方向与佩戴者或对话者的嘴不一致的情形下,只要将从所述
音源发出的声音成分视为杂音,而抑制其声音成分即可。如此,在本发明中,使用多个全指向性的麦克风来取得全方位的声音数据,并进行波束成形处理,所述波束形成处理是通过控制部80在软件上的声音处理而强调或抑制特定的音成分。由此,能同时取得佩戴者的声音与对话者的声音,并根据需要来强调其声音的声音成分。
[0062]
接着,参照图5说明来能适当地将对话者的声音进行波束成形的范。如图5(a)所示,在对话者位于佩戴者的正面侧的情形下,对话者所发出的声音直线到达装配于颈挂型装置100上的六个集音部41~46的全部。此情形下,如同前述,可进行强调对话者所发出的声音的波束成形处理。并且,如图5(a)所示,例如在对话者位于佩戴者的右侧的情形下,只要至少能以设置于颈挂型装置100的右臂部20的三个集音部44~46对此右侧的对话者所发出的声音取得声音,就能进行波束成形处理。在对话者位于佩戴者的左侧的情形下也是同样。如此,在本发明中,由于在左臂部10及右臂部20分别各设有三处集音部41~46,因此针对存在于佩戴者左右的对话者的声音,即使仅以左臂部10上的集音部41~43或右臂部20上的集音部44~46也能应对。
[0063]
并且,如图5(b)所示,即使在对话者位于佩戴者的左右后方的情形下,只要可通过左臂部10上的集音部41~43或右臂部20上的集音部44~46之中的三个以上的集音部来取得其对话者的声音,就能进行波束成形处理。再者,在本发明的优选实施方式中,在与佩戴者的颈后相应的位置设有第七集音部47。因此,即使在对话者位于佩戴者的大致正后方的情形下,只要对话者所发出的声音直线到达第一集音部41至第六集音部46之中的至少两个集音部(例如第三集音部43、第六集音部46)与第七集音部47,就能通过此三个以上的集音部进行波束成形处理。因此,在左臂部10与右臂部20的各个上各设有三处集音部41~46,且进一步在主体部30设置第七集音部47的方式中,能对佩戴者的周围全方向(约360度)进行波束成形。此情形下,不存在无法进行波束成形的死角区域。
[0064]
如此,为了适当地进行波束成形处理,需要使对话者的声音直线到达三个以上的集音部。若考虑到这种限制,只要设成在颈挂型装置100的左右的臂部10、20的各个上各设置三处(合计六处)集音部的构成,就将可听范围扩大到除了佩戴者的后方以外的广大范围,所述可听范围是可将对话者的声音适当地进行波束成形的范围。具体而言,通过在左右的臂部10、20的各个上各设置三处集音部41~46,能将可进行波束成形的可听范围从佩戴者的眼前扩大到约260度以上,且优选到320度以上。如此,可够将佩戴者的左右两侧几乎完全地设为可听范围。因此,不仅可适当地取得与佩戴者面对对话的对话者的声音,还可适当地取得与佩戴者横向排列对话的对话者的声音。并且,除了上述集音部41~46以外,还在主体部30设置第七集音部47,由此即使对于仅以左右的臂部10、20的集音部41~46无法应对的区域(特别是佩戴者的背部)也可进行波束成形。
[0065]
接着,参照图6来说明颈挂型装置100的佩戴者与未佩戴颈挂型装置的两名对话者的共计三人进行对话的情形。在图6所示的例子中,为了方便起见,设定为在俯视图中参与对话的三人位于正三角形的各顶点,且三人的相对位置未变化。但是,即使在随着时间的经过三人的相对位置会发生变化的情形下,只要定期地从各说话者的声音来确定位置并追踪各说话者的变化后位置即可。并且,在图6中,将从“佩戴者”来看位于左臂部10侧的对话者设为“第一对话者”,并将位于右臂部20侧的对话者设为“第二对话者”。
[0066]
如此,假设在三者进行对话的情形下,第一对话者与第二对话者同时发声。将此情
形的波束成形处理的一例表示于图7。亦即,在本发明的颈挂型装置100中,首先,声音解析部80a利用由左臂部10上的第一集音部41至第三集音部43所取得的第一声音数据来确定第一对话者的声音的音源位置或方向(s1)。并且,声音处理部80b对第一声音数据进行强调经确定的第一对话者的声音成分的处理(s2)。同样地,声音解析部80a利用由右臂部20上的第四集音部44至第六集音部46所取得的第二声音数据来确定第二对话者的声音的音源位置或方向(s1)。并且,声音处理部80b对第二声音数据进行强调经确定的第二对话者的声音成分的处理(s2)。如此,在三者进行对话的情形下,优选地,独立利用左臂部10上的三个集音部41~43与右臂部20上的三个集音部44~46,将由左臂部10上的集音部41~43所取得的第一声音数据与由右臂部20上的集音部44~46所取得的第二声音数据分离后,对各声音数据进行声音处理。
[0067]
再者,在本发明的颈挂型装置100中,可将各自交叉的声音成分的抑制处理与上述的声音强调处理一起进行。亦即,由左臂部10上的集音部41~43所取得的第一声音数据如同上述被强调为第一对话者的声音成分,但此外还包括第二对话者的声音成分等。另一方面,第二对话者的声音成分在由右臂部20上的集音部4~43所取得的第二声音数据中已完成了强调处理。因此,如图7所示,声音处理部80b利用在第二声音数据中被强调后的第二对话者的声音成分来抑制第一声音数据中的第二对话者的声音成分(s3)。同样地,声音处理部80b利用在第一声音数据中被强调后的第一对话者的声音成分来抑制第二声音数据中的第一对话者的声音成分(s3)。由此,由左臂部10上的集音部41~43所取得的第一声音数据中,强调第一对话者的声音成分,并且抑制第二对话者的声音成分。并且,由右臂部20上的集音部44~46所取得的第二声音数据中,强调第二对话者的声音成分,并且抑制第一对话者的声音成分。如此,通过单独利用左臂部10的集音部41~43与右臂部20的集音部44~46,即使在第一对话者与第二对话者同时发声的情形下,也可提高各话者的声音成分的分离性能。
[0068]
此外,抑制声音成分的信号处理可利用适当公知的处理方法,但最简单的是进行频谱的减法处理即可。例如,在时间频率区域中从第一对话者的被强调的声音减去第二对话者的被强调的声音,并将该减法结果作为最终结果。但是,在简单的频谱减法处理的情形下,已知有被称为音乐杂音的副作用,也能合并使用可降低此副作用的其他处理。音乐杂音的降低处理,一般是被称为附参考信号的杂音抑制处理的领域的处理,已知例如mmse(minimum mean-square-error,最小均方误差)法或map(maximum a posteriori,最大后验)法等。此外,也能利用使用所谓回声消除处理所包括的“自适应滤波”的处理。例如,在利用mmse法或map法的情形下,分别对由左臂部10的集音部41~43所取得的3ch的第一声音数据与由右臂部30的集音部44~46所取得的3ch的第二声音数据进行声音强调处理,并从各个声音数据取得1ch的参考信号后,进行参考信号间的抑制处理,而得到第一对话者与第二对话者的声音成分被分离的最终结果。并且,在利用使用“自适应滤波”的处理的情形下,分别对由左臂部10的集音部41~43所取得的3ch的第一声音数据与由右臂部30的集音部44~46所取得的3ch的第二声音数据进行声音强调处理,并从各个声音数据取得1ch的参考信号。然后,对原始的3ch的声音数据施加各信道的自适应滤波,而生成从原始的3ch的声音数据除去来自不同的对话者的声音成分的新的3ch的声音数据。然后,对此新的声音数据进行声音强调处理,得到第一对话者与第二对话者的声音成分被分离的1ch的最终结果即可。
[0069]
并且,优选在取得对话者的声音的情形使摄像部60启动并摄影对话者。若具体说明,佩戴者在非接触型的传感部70的感测范围内通过自身的手指进行预定的手势。手势包括以手指进行预定的动作或以手指做出预定的形状。若传感部70感测出手指的动作,则控制部80的输入解析部80c将传感部70的感测信息进行解析,判断佩戴者的手指的手势是否与预先设定的手势一致。例如,由于预先设定用于预先使摄像部60启动的手势、用于通过摄像部60开始摄影的手势、用于使摄影停止的手势等等关于控制摄像部60的预定的手势,因此输入解析部80c会基于传感部70的感测信息来判断佩戴者的手势是否与上述的预定的手势是否一致。
[0070]
接着,控制部80的摄像控制部80d基于输入解析部80c的解析结果来控制摄像部60。例如,在输入解析部80c判断佩戴者的手势与启动摄像部60用的手势一致的情形下,摄像控制部80d使摄像部60启动。并且,启动摄像部60后,在输入解析部80c判断佩戴者的手势与开始摄影用的手势一致的情形下,摄像控制部80d控制摄像部60以开始摄影图像。再者,开始摄影后,在输入解析部80c判断佩戴者的手势与停止摄影用的手势一致的情形下,摄像控制部80d控制摄像部60以停止摄影图像。此外,摄像控制部80d也可在摄影停止后经过一定时间的阶段将摄像部60再次设为休眠状态。
[0071]
控制部80的图像解析部80e将由摄像部60所取得的静止图像或动态图像的图像数据进行解析。例如,图像解析部80e可通过将图像数据进行解析,来确定从颈挂型装置100至对话者的嘴的距离或两者的位置关系。并且,图像解析部80e通过基于图像数据来解析对话者的嘴是否打开或对话者的嘴是否开阖,由此也能确定对话者是否正在发声。由图像解析部80e所得的解析结果被利用于上述的波束成形处理。具体而言,除了由各集音部41~47所收集的声音数据的解析结果以外,若还利用由摄像部60所得的图像数据的解析结果,则可提高确定对话者的嘴在空间上的位置或方向的处理的精确度。并且,将图像数据所包括的对话者的嘴的动作进行解析来确定所述对话者正在发声,由此可够提高强调从所述对话者的嘴发出的声音的处理的精确度。
[0072]
由声音处理部80b处理后的声音数据与由摄像部60所取得的图像数据被存储于存储部81。并且,控制部80也可将处理后的声音数据与图像数据通过通信部82而传送至云端上的服务器装置或其他颈挂型装置100。服务器装置也可基于从颈挂型装置100接收的声音数据,来进行声音的文本化处理、翻译处理、统计处理、其他任意的语言处理。并且,也可利用由摄像部60所取得的图像数据来提高上述语言处理的精确度。并且,服务器装置也能将从颈挂型装置100接收的声音数据与图像数据利用作为机械学习用的教师数据,而使习得模型的精确度提升。并且,也可通过在颈挂型装置100间互相收发声音数据而在佩戴者间进行远距通话。此时,可在颈挂型装置100彼此间通过近距离无线通信直接收发声音数据,也可通过服务器装置经由互联网在颈挂型装置100彼此间收发声音数据。
[0073]
在本技术案说明书中,主要说明了颈挂型装置100具备声音解析部80a、声音处理部80b及图像解析部80e作为功能构成,且在本地执行波束成形处理的实施方式。但是,也可使以互联网连接至颈挂型装置100的云端上的服务器装置分担声音解析部80a、声音处理部80b及图像解析部80e中的任一者或全部的功能。此情形下,例如,颈挂型装置100可将由各集音部41~47所取得的声音数据传送至服务器装置,服务器装置确定音源的位置或方向,或进行强调佩戴者或对话者的声音并抑制其以外的杂音的声音处理。并且,也可将由摄像
部60所取得的图像数据从颈挂型装置100传送至服务器装置,在服务器装置进行该图像数据的解析处理。此情形下,会由颈挂型装置100与服务器装置构成声音处理系统。
[0074]
以上,在本技术案说明书中,为了表现本发明的内容,一边参照附图一边进行了本发明的实施方式的说明。但是,本发明并不限定于上述实施方式,而包括本领域技术人员基于本技术案说明书所记载的事项而显而易见的变更方式或改良方式。
[0075]
并且,也能基于由传感部70所得的感测信息来控制由摄像部60所进行的摄影方法。具体而言,作为摄像部60的摄影方法,可举例如:静止图的摄影、视频的摄影、慢动作摄影、全景摄影、缩时摄影、定时摄影等。若传感部70感测出手指的动作,则控制部80的输入解析部80c将传感部70的感测信息进行解析,判断佩戴者的手指的手势是否与预先设定的手势一致。例如,对摄像部60的摄影方法分别设定有固有的手势,输入解析部80c会基于传感部70的感测信息来判断佩戴者的手势是否与预先设定的手势一致。摄像控制部80d基于输入解析部80c的解析结果来控制由摄像部60所进行的摄影方法。例如,在输入解析部80c判断佩戴者的手势与摄影静止图用的手势一致的情形下,摄像控制部80d控制摄像部60来进行静止图的摄影。或者在输入解析部80c判断佩戴者的手势与动态图像摄影用的手势一致的情形下,摄像控制部80d控制摄像部60来进行视频的拍摄。如此,可根据佩戴者的手势来指定由摄像部60所进行的摄影方法。
[0076]
并且,在上述的实施方式中,虽然主要基于由传感部70所得的感测信息来控制摄像部60,但也能基于由传感部70所得的感测信息来控制各集音部41~47。例如,预先设定与开始或停止由集音部41~47所进行的集音相关的固有手势,输入解析部80c基于传感部70的感测信息来判断佩戴者的手势是否与预先设定的手势一致。然后,在感测出与开始或停止集音相关的手势的情形下,只要根据该手势的感测信息而开始或停止通过各集音部41~47的集音即可。
[0077]
并且,在前述的实施方式中,虽然主要基于由传感部70所得的感测信息来控制摄像部60,但也能基于输入至各集音部41~47的声音信息来控制摄像部60。具体而言,声音解析部80a将集音部41~47所取得的声音进行解析。亦即,进行佩戴者或对话者的声音识别,判断其声音是否与摄像部60的控制相关。然后,摄像控制部80d基于其声音的解析结果来控制摄像部60。例如,在与开始摄影相关的预定的声音输入集音部41~47的情形下,摄像控制部80d使摄像部60启动并开始摄影。并且,在指定由摄像部60所进行的摄影方法的预定的声音输入集音部41~47的情形下,摄像控制部80d控制摄像部60来执行所指定的摄影方法。并且,也能在基于由传感部70所得的感测信息而使集音部41~47启动后,基于输入集音部41~47的声音信息来控制摄像部60。
[0078]
并且,也能根据由摄像部60所拍摄到的图像,使基于传感部70的输入信息的控制命令的内容变化。若具体说明,首先,图像解析部80e将由摄像部60所取得的图像进行解析。例如,基于图像中所包括的特征点,图像解析部80a确定其是否拍到人物的图像、是否拍到特定的被摄体(人工物或自然物等)的图像,或者所述图像被拍摄到的状况(摄影场所或摄影时间、气候等)。此外,针对图像中所包括的人物,可将其性别或年龄进行分类,也可特定个人。
[0079]
接着,根据图像的种类(人物、被摄体、状况的类别),将基于由人的手指所做出的手势的控制命令的图案存储到存储部81。此时,即使是相同的手势,也可根据图像的种类而
使控制命令不同。具体而言,即使是某个同样的手势,在图像中拍到人物的情形下,则成为聚焦所述人物的脸部的控制命令,而在图像中拍到特征性自然物的情形下,则成为全景摄影该自然物的周围的控制命令。并且,也可从图像感测出图像中拍到的人物的性别或年龄、被摄体为人工物或自然物、或是图像的摄影场所、时间、气候等,而使手势的定义内容不同。然后,输入解析部80c参照图像解析部80e的图像解析结果,针对由传感部70所感测出的手势,确定与所述图像解析结果对应的定义内容,并生成输入颈挂型装置100的控制命令。如此,通过根据图像的内容而使手势的定义内容变化,能根据图像的摄影状况或目的,而通过手势将各种变化的控制命令输入装置。
[0080]
附图标记说明
[0081]
10:左臂部(第一臂部)
[0082]
11:柔性部
[0083]
12:前端面
[0084]
13:下表面
[0085]
14:上表面
[0086]
20:右臂部(第二臂部)
[0087]
21:柔性部
[0088]
22:前端面
[0089]
23:下表面
[0090]
24:上表面
[0091]
30:主体部
[0092]
31:下垂部
[0093]
32:主体部壳体
[0094]
32a:穿透部
[0095]
32b:格栅
[0096]
41:第一集音部
[0097]
42:第二集音部
[0098]
43:第三集音部
[0099]
44:第四集音部
[0100]
45:第五集音部
[0101]
46:第六集音部
[0102]
47:第七集音部
[0103]
50:操作部
[0104]
60:摄像部
[0105]
70:传感部
[0106]
80:控制部
[0107]
80a:声音解析部
[0108]
80b:声音处理部
[0109]
80c:输入解析部
[0110]
80d:摄像控制部
[0111]
80e:图像解析部
[0112]
81:存储部
[0113]
82:通信部
[0114]
83:接近传感器
[0115]
84:放音部
[0116]
90:电池
[0117]
100:颈挂型装置(声音输入装置)
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1