一种基于ARIMA-LSTM估计的网络时钟同步方法
一种基于arima-lstm估计的网络时钟同步方法
技术领域
1.本发明涉及时钟同步技术领域,特别是一种基于arima-lstm估计的网络时钟同步方法。
背景技术:
2.在时钟同步技术领域,时延是指从主时钟节点到从时钟节点数据包所经历的时间,其中包括数据包的处理和传输时间,时延的测量由双向的报文传输时延取平均得到,因此其测量误差的存在将会导致时钟同步的精度无法得到保障。在工业现场环境中,数量庞大的节点制造的大量数据、恶劣的电磁环境等因素,导致网络链路产生不稳定时延抖动和通信路径不对称,对时钟同步精度造成很大的影响。时钟同步技术作为工业领域中的一项关键技术,尤其是在时间敏感网络系统中,它可以保证终端设备之间的实时通信。时钟同步的精度需要良好的网络情况来支持,对于时延偏大且抖动频繁的网络就无法实现特别高的精度,因此如何降低时延抖动对时钟同步造成的影响成为了一项挑战。在工业生产环境中,复杂恶劣的电磁环境以及数据流等的频繁转发,使得网络数据的传输容易产生网络阻塞和剧烈的时延抖动,对时钟同步精度产生很大的影响。
技术实现要素:
3.有鉴于此,本发明的目的在于提供一种基于arima-lstm估计的网络时钟同步方法,实现有效地消除由时延抖动引起的不可控误差,提高时钟同步精度。
4.为实现上述目的,本发明采用如下技术方案:一种基于arima-lstm估计的网络时钟同步方法,包括以下步骤:
5.步骤s1:首先由最佳主时钟算法确定域内主从层次关系,主时钟节点作为参考时间,其余时钟节点作为从时钟节点;
6.步骤s2:从时钟利用得到的时间戳t1,t2,t3,t4计算它和主时钟的时钟偏差,如式(1)所示:
[0007][0008]
步骤s3:根据统计原理计算时钟偏差的置信区间去确定阈值θ1和θ2;如公式(2)中,x是时钟偏差数据,p是时钟偏差x在区间(μ-kσ,μ+kσ)内的概率,μ是时钟偏差均值,σ是标准差,k为标准差系数;则确定的阈值为θ1=μ-kσ,θ2=μ+kσ;
[0009]
p={|x-μ|《kσ}
ꢀꢀꢀꢀꢀꢀ
(2)
[0010]
步骤s4:采集时钟偏差数据并进行预处理;具体包括一阶低通滤波和异常值处理,分别消除原始数据的高频干扰和离群值;根据步骤s3设定的阈值,对异常值采用取均值的方法,即前n个时钟偏差的均值去替代异常值,并将处理后的数据划分为训练集和测试集;
[0011]
步骤s5:构建自回归移动平均模型arima;
[0012]
步骤s6:构建长短期记忆估计模型lstm;
[0013]
步骤s7:构建arima-lstm组合估计模型;
[0014]
步骤s8:根据设定的阈值持续检测系统的网络状况;当从时钟计算出来的offset位于阈值范围内时,代表当前的网络没有发生时延抖动,此时根据式(1)计算的offset去更新本地时钟;当offset位于阈值范围外时,说明网络内发生时延抖动,此时计算出来的offset并不可信,及时调用arima-lstm模型进行估计,利用估计值更新本地时钟。
[0015]
在一较佳的实施例中,主从时钟交换数据包进行时钟同步,具体过程如下:
[0016]
步骤s1.1:主时钟周期性的向从时钟发送sync同步报文,同时会记录发送数据包的时间戳t1;如果采取的是两步式同步,主时钟会向从时钟发送一个follow_up报文,该数据包中包含时间戳t1;
[0017]
步骤s1.2:从时钟接收到sync报文并记录接收时间戳t2;从时钟向主时钟发送delay_req报文并记录发送的时间戳t3;
[0018]
步骤s1.3:主时钟接收到这个报文后会记录时间戳为t4;主时钟向从时钟发送delay_resp报文,该数据包中包含时间戳t4。
[0019]
在一较佳的实施例中,步骤s5包括以下步骤:
[0020]
步骤5.1:对时钟偏差时间序列平稳性进行检验;
[0021]
步骤5.2:利用aic和bic准则对模型进行定阶;
[0022]
步骤5.3:进行白噪声检验;
[0023]
利用arima模型拟合时钟偏差序列,其计算公式为:
[0024][0025]
其中,x
t
为当前t时刻的时钟偏差时间序列样本值,x
t-1
为t-1时刻的时钟偏差时间序列样本值;p和q分别为自回归项和移动平均项对应的阶数;和θj(j=1,2,
…
q)为模型参数;ε
t
和ε
t-j
为独立正态分布的白噪声。
[0026]
在一较佳的实施例中,步骤s6具体包括以下步骤:
[0027]
步骤6.1:对数据进行预处理;
[0028]
步骤6.2:设定网络参数;
[0029]
步骤6.3:模型训练;
[0030]
利用lstm预测拟合时钟偏差序列,其计算公式为:
[0031]it
=σ(wi*[h
t-1
,x
t
]+bi)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(4)
[0032]ft
=σ(wf*[h
t-1
,x
t
]+bf)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(5)
[0033]ot
=σ(wo*[h
t-1
,x
t
]+bo)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(6)
[0034]ct
=f
t
*c
t-1
+i
t
*tanh(wc*[h
t-1
,x
t
]+bc)
ꢀꢀꢀꢀꢀꢀꢀ
(7)
[0035]ht
=o
t
*tanh(c
t
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(8)
[0036]
式中,i
t
为输入门,f
t
为遗忘门,o
t
为输出门;c
t
为当前t时刻细胞的状态,c
t-1
为t-1时刻细胞的状态;h
t
为当前t时刻的输出数据,h
t-1
为t-1时刻的输出数据;wi为输入门的权重矩阵,wf为遗忘门的权重矩阵,wo为输出门的权重矩阵,wc为备选状态的权重矩阵;bi为输入门的偏移量,bf为遗忘门的偏移量,bo为输出门的偏移量,bc为输入单元状态的偏移量;σ()为激活函数;tanh()为双曲正切激活函数。
[0037]
在一较佳的实施例中,步骤s7具体包括以下步骤:
[0038]
步骤7.1:设定pso算法的初始参数;其中pso的具体计算公式为:
[0039][0040][0041]
其中,为第k次迭代时粒子的速度;为第k次迭代时粒子的位置;第k次迭代时粒子的局部最优位置;i代表粒子;c1和c2表示学习因素;r1和r2是0到1之间的随机数;ω为惯性重量;λ为速度系数;
[0042]
步骤7.2:建立目标函数,利用pso算法分别对arima和lstm的估计最终结果赋予合适的权重,得到组合模型的估计结果,具体表达式如下:
[0043]
c(i)=a(i)*w1+l(i)*w2
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(11)
[0044]
w1+w2=1
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(12)
[0045][0046]
其中a(i)和l(i)分别是arima和lstm模型的估计结果;c(i)为组合模型的估计结果;t(i)为时钟偏差真实数据;w1和w2分别代表arima和lstm估计结果的权重值;p为建立的目标函数;
[0047]
步骤7.3:对arima-lstm估计模型和单一模型估计精度进行比较;采用均方误差rmse和平均绝对误差mae作为评判各种模型估计效果的依据,两个指标的具体公式如下所示:
[0048][0049][0050]
其中,yi为真实的时钟偏差数据,为arima-lstm估计的时钟偏差数据。
[0051]
与现有技术相比,本发明具有以下有益效果:
[0052]
(1)针对网络较差的工业现场环境中,考虑时延抖动对时钟偏移造成的影响,根据时钟偏差的特性设置偏移阈值,可以感知网络中时延抖动的发生,减少其对时钟同步精度的影响。
[0053]
(2)本优化算法基于离线数据训练模型,可实现在线估计时钟偏差,很好的校正由于网络时延抖动对时钟同步过程造成的不可控误差,把时钟偏差控制在可允许的范围内。
附图说明
[0054]
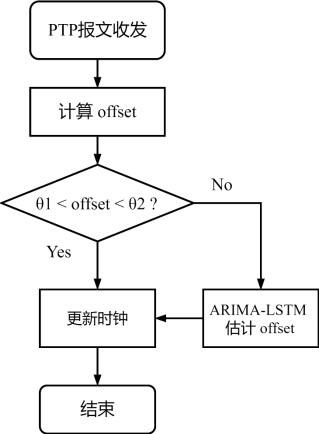
图1为本发明优选实施例的方法工作流程图;
[0055]
图2为本发明优选实施例的对某网络下的时钟偏差数据结果图;
[0056]
图3为本发明优选实施例的对某网络下的时钟偏差数据统计图;
[0057]
图4为本发明优选实施例的提出的arima-lstm估计模型示意图;
[0058]
图5为本发明优选实施例的提出的arima-lstm估计效果示意图;
[0059]
图6为本发明优选实施例的在某网络下提出的方法与原始ptp算法的同步效果对比图。
具体实施方式
[0060]
下面结合附图及实施例对本发明做进一步说明。
[0061]
应该指出,以下详细说明都是例示性的,旨在对本技术提供进一步的说明。除非另有指明,本文使用的所有技术和科学术语具有与本技术所属技术领域的普通技术人员通常理解的相同含义。
[0062]
需要注意的是,这里所使用的术语仅是为了描述具体实施方式,而非意图限制根据本技术的示例性实施方式;如在这里所使用的,除非上下文另外明确指出,否则单数形式也意图包括复数形式,此外,还应当理解的是,当在本说明书中使用术语“包含”和/或“包括”时,其指明存在特征、步骤、操作、器件、组件和/或它们的组合。
[0063]
一种基于arima-lstm估计的网络时钟同步方法,参考图1至6,包括以下步骤:
[0064]
步骤s1:首先由最佳主时钟算法确定域内主从层次关系,主时钟节点作为参考时间,其余时钟节点作为从时钟节点;
[0065]
主从时钟交换数据包进行时钟同步,具体过程如下:
[0066]
步骤s1.1:主时钟周期性的向从时钟发送sync同步报文,同时会记录发送数据包的时间戳t1;如果采取的是两步式同步,主时钟会向从时钟发送一个follow_up报文,该数据包中包含时间戳t1;
[0067]
步骤s1.2:从时钟接收到sync报文并记录接收时间戳t2;从时钟向主时钟发送delay_req报文并记录发送的时间戳t3;
[0068]
步骤s1.3:主时钟接收到这个报文后会记录时间戳为t4;主时钟向从时钟发送delay_resp报文,该数据包中包含时间戳t4。
[0069]
时钟系统启动后,主从时钟基于ieee1588协议进行同步。采集同步过程中的时钟偏差数据如图2所示,共有1600个采样点。可以看到由于网络系统中时延抖动的存在,时钟偏差很不稳定,尤其是在采样点781到1352,时钟偏差抖动达到了[-717.27,563.52]us,当去除抖动值后,时钟偏差大多数分布在[-70,70]us。
[0070]
步骤s2:从时钟利用得到的时间戳t1,t2,t3,t4计算它和主时钟的时钟偏差,如式(1)所示:
[0071][0072]
通过图3可知,时钟偏差数据的统计结果基本符合高斯分布,大部分的数据分布在区间[-30,30]us,占据总数据的91.8%。其中,大于210us和小于-210us的时钟偏差数据占总数据的3%,把此范围内的数据看作高度异常值处理。
[0073]
步骤s3:根据统计原理计算时钟偏差的置信区间去确定阈值θ1和θ2;如公式(2)中,x是时钟偏差数据,p是时钟偏差x在区间(μ-kσ,μ+kσ)内的概率,μ是时钟偏差均值,σ是标准差,k为标准差系数;则确定的阈值为θ1=μ-kσ,θ2=μ+kσ;
[0074]
p={|x-μ|《kσ}
ꢀꢀꢀꢀꢀꢀꢀ
(2)
[0075]
在移除了高度异常值后,时钟偏差的平均值为1.14us,标准差为30.96。由公式(2)可知,不同的k对应不同的置信区间,当k=1时,p=0.683,即有68.3%的时钟偏差数据位于该阈值范围内;当k=2时,p=0.954,即有95.4%的时钟偏差数据位于该阈值范围内;当k=3时,p=0.997,即有99.7%的时钟偏差数据位于该阈值范围内。在时钟网络系统中,采用k
为2,因此阈值=-60.78us,=63.06us。
[0076]
步骤s4:采集时钟偏差数据并进行预处理;具体包括一阶低通滤波和异常值处理,分别消除原始数据的高频干扰和离群值;根据步骤s3设定的阈值,对异常值采用取均值的方法,即前n个时钟偏差的均值去替代异常值,并将处理后的数据划分为训练集和测试集;直接采集的得到的时钟偏差数据已经经过了一阶低通滤波,但是还会存在有异常值,这里n取为4,采用均值处理异常值。将处理完后的前70%数据作为训练集,后30%数据作为测试集。
[0077]
步骤s5:构建自回归移动平均模型arima;
[0078]
步骤5.1:对时钟偏差时间序列平稳性进行检验;
[0079]
步骤5.2:利用aic和bic准则对模型进行定阶;
[0080]
步骤5.3:进行白噪声检验;
[0081]
利用arima模型拟合时钟偏差序列,其计算公式为:
[0082][0083]
其中,x
t
为当前t时刻的时钟偏差时间序列样本值,x
t-1
为t-1时刻的时钟偏差时间序列样本值;p和q分别为自回归项和移动平均项对应的阶数;和θj(j=1,2,
…
q)为模型参数;ε
t
和ε
t-j
为独立正态分布的白噪声。
[0084]
首先对时钟偏差数据进行平稳性检验检验,单位根结果小于0.05,显示数据是稳定的。然后通过aic和bic准则对模型进行定阶,确定为arima(3,0,0)。最后模型的残差显示是白噪声分布,这说明模型是合理的。
[0085]
步骤s6:构建长短期记忆估计模型lstm;
[0086]
步骤s6具体包括以下步骤:
[0087]
步骤6.1:对数据进行预处理;
[0088]
步骤6.2:设定网络参数;
[0089]
步骤6.3:模型训练;
[0090]
利用lstm预测拟合时钟偏差序列,其计算公式为:
[0091]it
=σ(wi*[h
t-1
,x
t
]+bi)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(4)
[0092]ft
=σ(wf*[h
t-1
,x
t
]+bf)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(5)
[0093]ot
=σ(wo*[h
t-1
,x
t
]+bo)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(6)
[0094]ct
=f
t
*c
t-1
+i
t
*tanh(wc*[h
t-1
,x
t
]+bc)
ꢀꢀꢀꢀꢀꢀꢀ
(7)
[0095]ht
=o
t
*tanh(c
t
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(8)
[0096]
式中,i
t
为输入门,f
t
为遗忘门,o
t
为输出门;c
t
为当前t时刻细胞的状态,c
t-1
为t-1时刻细胞的状态;h
t
为当前t时刻的输出数据,h
t-1
为t-1时刻的输出数据;wi为输入门的权重矩阵,wf为遗忘门的权重矩阵,wo为输出门的权重矩阵,wc为备选状态的权重矩阵;bi为输入门的偏移量,bf为遗忘门的偏移量,bo为输出门的偏移量,bc为输入单元状态的偏移量;σ()为激活函数;tanh()为双曲正切激活函数。
[0097]
本文建立了三层lstm层和全连接神经网络。其序列长度设置为60,输出序列长度为1,即用前60个时钟偏差数据去估计下一个时钟偏差数据;模型的epoch设置为60,batch_size设置为32,即迭代次数为60,一次训练导入的时钟偏差数据量为32。
[0098]
步骤s7:构建arima-lstm组合估计模型;
[0099]
步骤s7具体包括以下步骤:
[0100]
步骤7.1:设定pso算法的初始参数;其中pso的具体计算公式为:
[0101][0102][0103]
其中,为第k次迭代时粒子的速度;为第k次迭代时粒子的位置;第k次迭代时粒子的局部最优位置;i代表粒子;c1和c2表示学习因素;r1和r2是0到1之间的随机数;ω为惯性重量;λ为速度系数;
[0104]
步骤7.2:建立目标函数,利用pso算法分别对arima和lstm的估计最终结果赋予合适的权重,得到组合模型的估计结果,具体表达式如下:
[0105]
c(i)=a(i)*w1+l(i)*w2
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(11)
[0106]
w1+w2=1
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(12)
[0107][0108]
其中a(i)和l(i)分别是arima和lstm模型的估计结果;c(i)为组合模型的估计结果;t(i)为时钟偏差真实数据;w1和w2分别代表arima和lstm估计结果的权重值;p为建立的目标函数;
[0109]
步骤7.3:对arima-lstm估计模型和单一模型估计精度进行比较;采用均方误差rmse和平均绝对误差mae作为评判各种模型估计效果的依据,两个指标的具体公式如下所示:
[0110][0111][0112]
其中,yi为真实的时钟偏差数据,为arima-lstm估计的时钟偏差数据。
[0113]
基于步骤s5和s6建立的单一模型建立组合模型,利用pso确定单一模型估计结果的最优权重,如图4所示。其中pso算法的粒子数n=50;加速常数c1=2,c1=2;迭代次数设置为200。最终确定权重系数w1为0.83,w2为0.17。基于arima-lstm的时钟偏差估计结果如图5所示。计算出来的各模型指标rmse和mae如表格1所示,可以看到arima-lstm模型都要小于单一的模型,估计效果更好。
[0114]
表1各模型估计指标
[0115]
估计模型maermsearima2.333.05lstm3.124.0arima+lstm2.283.01
[0116]
步骤s8:根据设定的阈值持续检测系统的网络状况;当从时钟计算出来的offset位于阈值范围内时,代表当前的网络没有发生时延抖动,此时根据式(1)计算的offset去更
新本地时钟;当offset位于阈值范围外时,说明网络内发生时延抖动,此时计算出来的offset并不可信,及时调用arima-lstm模型进行估计,利用估计值更新本地时钟。根据所选阈值以及建立的arima-lstm模型进行验证并分析对比算法效果,结果如图6所示。蓝线表示原始ptp算法结果,红线表示本发明提出的目标优化算法结果。
[0117]
步骤s9:可以看到ptp协议计算的时钟偏差并不稳定,例如在采样点79~91之间存在抖动,抖动值分布在[-333.99,246.03]us。时钟偏移绝对值的平均值为19.25us,标准差为47.69,在采用了提出的方法后,时钟偏移绝对值的平均值为10.22us,标准差为13.58,相比于原始的ptp协议,提出的方法能够更好的消除抖动,提高时钟同步精度。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1