声音处理方法、拾音系统及电子设备与流程
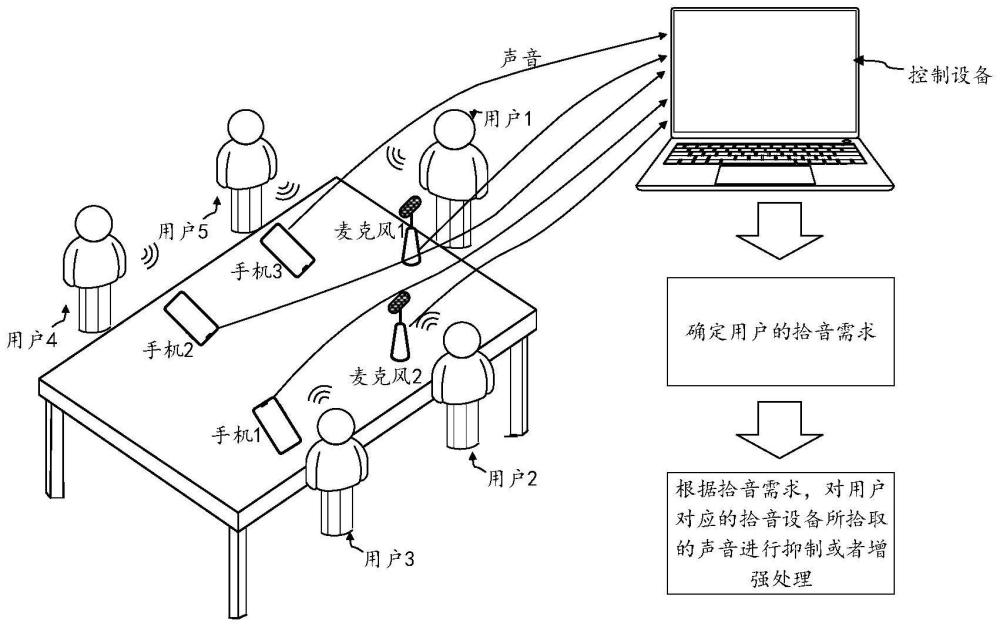
本技术涉及终端,尤其涉及一种声音处理方法、拾音系统及电子设备。
背景技术:
1、在多人会议的互动场景中,如果与会人员不想要发言或者讨论的内容不想被其他与会人员听到,那么可以对该与会人员的声音进行抑制。目前,对不想发言的目标与会人员的声音进行抑制的方式大致包括两种,一种是控制目标与会人员附近的麦克风等拾音设备静音,另一种是对目标与会人员所在区域的声音进行抑制。
2、然而,不论采用哪种方式对目标与会人员的声音进行抑制,都需要目标与会人员根据自己的发言、静音需求等手动地去控制麦克风等拾音设备的拾音状态,这样的操作过程比较繁琐,会影响参与会议的人员和主持人等的参会体验等。
技术实现思路
1、本技术实施例提供一种声音处理方法、拾音系统及电子设备,能够自动识别用户的拾音需求模式,例如静音模式、发言模式等,并且根据用户的拾音需求模式对拾取到的用户的声音进行抑制或者增强处理,从而减少用户手动改变拾音设备的拾音状态的操作,保证用户的体验。
2、为达到上述目的,本技术的实施例采用如下技术方案:
3、第一方面,提供一种声音处理方法,应用于拾音系统中的控制设备,该拾音系统还包括第一设备和可拾取到第一设备所在位置声音的第二设备。控制设备可以根据第一设备拾取的第一声音,确定第一设备对应的第一用户的拾音需求模式,以及根据第二设备拾取的第二声音,确定第二设备对应的第二用户的拾音需求模式。之后,在第一用户的拾音需求模式为静音以及第二用户的拾音需求模式为非静音的情况下,控制设备在第一声音和第二声音混合后的混音中,去除或者削弱第一用户的声音。其中,去除或者削弱第一用户的声音后的混音可以被第一设备和/或第二设备播放,并且该混音被播放时,收听的用户无法听到或者听清楚第一用户说话的内容。
4、上述方案可以应用于多人互动场景中,并且多人互动场景中包括用于拾音的拾音设备和用于控制拾音设备的控制设备等。各个拾音设备可以主动拾取至少一个用户在多人互动过程中的声音,并且,控制设备根据拾音设备拾取到的声音可以自动地识别出拾音设备对应的用户在多人互动过程中的拾音需求模式。之后,控制设备再根据用户的拾音需求模式,对用户对应的拾音设备拾取的声音进行处理。例如,用户有静音需求时,对拾音设备拾取的声音进行抑制处理等。无论用户在什么位置上,这种声音处理方法,都能自动识别用户的拾音需求模式,并且在用户的拾音需求模式发生变化时,也可以实时地根据用户的拾音需求模式对拾取到的用户的声音进行处理,从而满足参与多人互动中不同位置的不同用户的需求,减少用户手动改变拾音设备的拾音状态的操作,保证用户的体验,也提高声音处理的准确性和质量。
5、在第一方面的一种可实现方式中,控制设备还可以在第一用户的拾音需求模式为发言以及第二用户的拾音需求模式为非发言的情况下,在第一声音和第二声音混合后的混音中,增强第一用户的声音。其中,增强第一用户的声音后的混音用于被第一设备和/或第二设备播放,并且该混音被播放时,收听的用户可以主要听到第一用户的声音或者只能听到第一用户的声音。可见,控制设备不仅能根据第一用户的静音需求将第一用户的声音进行抑制,还可以根据第一用户的发言需求将第一用户的声音进行增强,从而满足用户的不用的需求,保证用户的体验。
6、在第一方面的一种可实现方式中,控制设备可以根据第一声音确定第一设备对应的声源数量,从而确定第一用户的拾音需求模式。其中,若第一设备对应的声源数量为1,则可以确定第一用户的拾音需求模式为发言;若第一设备对应的声源数据量大于1,则可以确定第一用户的拾音需求模式为非发言。这种实现方式中,控制设备可以根据各个拾音设备对应的声源数量确定各个拾音设备对应的用户中是否有用户在说话,以及说话的用户有几个,进而确定出是否需要对各个拾音设备拾取的声音(例如拾音设备对应的用户的声音)进行处理。如果拾音设备对应的声源数量大于1个,则说明拾音设备对应的用户中当前有多个用户在说话,控制设备无法确定出是哪一个用户在发言,此时控制设备可以不对用户的声音进行抑制或者增强处理;如果拾音设备对应的声源数量只有1个,则说明拾音设备对应的用户中当前只有一个用户在说话,控制设备可以确定出这个用户在发言,从而增强这个用户的声音。
7、在第一方面的一种可实现方式中,控制设备可以根据第一声音确定第一设备对应的声音信噪比,从而确定第一用户的拾音需求模式。其中,若第一设备对应的声音信噪比小于第一预设信噪比,则可以确定第一用户的拾音需求模式为静音;若第一设备对应的声音信噪比大于或者等于第一预设信噪比,则可以确定第一用户的拾音需求模式为非静音。这种实现方式中,控制设备可以根据各个拾音设备的声音信噪比确定各个拾音设备对应的用户所处的声音环境,进而确定出是否需要对各个拾音设备拾取的声音(例如拾音设备对应的用户的声音)进行处理。如果控制设备确定出拾音设备的信噪比较低,那么可以认为拾音设备拾取的声音质量较差、拾音设备对应的用户所处的环境比较嘈杂、拾音设备对应的用户可能有多个并且多个用户都在同时说话等,控制设备可以将拾音设备拾取的声音(例如拾音设备对应的用户的声音)进行抑制处理,从而减少拾音设备拾取的声音对于其他拾音设备拾取的声音的干扰。而如果控制设备确定出拾音设备的声音信噪比比较高,那么可以认为拾音设备拾取的声音质量较好、拾音设备对应的用户所处的环境比较安静、拾音设备对应的用户可能有一个并且该用户正在发言等。这种情况下,控制设备可以将拾音设备拾取的声音(例如拾音设备对应的用户的声音)进行增强处理,这样,拾音设备拾取的声音被播放时可以被用户听清楚,同时听清楚拾音设备对应的用户的发言内容。
8、在第一方面的一种可实现方式中,控制设备可以获取第一声音的语义内容,并根据语义内容确定第一用户的拾音需求模式。其中,若第一声音的语义内容与预设内容的相似度小于预设相似度,则可以确定第一用户的拾音需求模式为静音;若第一声音的语义内容与预设内容的相似度大于或者等于预设相似度,则可以确定第一用户的拾音需求模式为非静音。这种实现方式中,控制设备可以根据各个拾音设备拾取的声音内容的语义确定各个拾音设备对应的用户是否在发言,进而确定出是否需要对各个拾音设备拾取的声音(例如拾音设备对应的用户的声音)进行处理。如果控制设备确定出拾音设备拾取的声音的语义内容与当前的会议内容无关,那么可以认为拾音设备对应的用户在说其他的内容,而并没有讨论会议。这种情况下,控制设备可以将拾音设备拾取的声音(例如拾音设备对应的用户的声音)进行抑制处理,从而减少这个拾音设备拾取的声音对于其他拾音设备拾取的声音的干扰。而如果控制设备确定出拾音设备拾取的声音的语义内容与当前的会议内容有关,那么可以认为拾音设备对应的用户在讨论会议或者在发言。这种情况下,控制设备可以将这个拾音设备拾取的声音进行增强处理,这样,这个拾音设备拾取的声音被播放时可以被用户听清楚,同时听清楚这个拾音设备对应的用户的讨论内容。
9、在第一方面的一种可实现方式中,上述控制设备可以是拾音系统中的第一设备或第二设备,即可以由拾音系统中的第一设备或者第二设备进行用户的拾音需求模式的识别,以及对声音进行抑制或者增强的处理。或者,上述控制设备也可以是云端设备,即拾音系统中的第一设备和第二设备也可以与云端设备通信。
10、在第一方面的一种可实现方式中,控制设备在去除或者削弱第一用户的声音的过程中,可以先对第一声音进行对象化处理,获得第一用户的声音。之后,在第一声音和第二声音的混音中,去除或者削弱第一用户的声音。这种实现方式中,控制设备可以将第一声音进行对象化处理,从而根据对象化处理的结果确定出第一声音中包括几个用户的声音。控制设备再将一个或者多个用户的声音从其他拾音设备拾取的混音中去除或者削弱。从而混音被播放时,收听的用户无法听到或者听不清清楚一个或者多个用户的声音。
11、在第一方面的一种可实现方式中,控制设备在增强第一用户的声音的过程中,可以先对第一声音进行对象化处理,获得第一用户的声音,之后,在第一声音和第二声音的混音中,增强第一用户的声音或者去除第一用户以外的其他用户的声音。这种实现方式中,控制设备也可以将第一声音进行对象化处理,从而根据对象化处理的结果确定出第一声音中包括几个用户的声音。控制设备再将一个或者多个用户的声音进行增强处理。从而混音被播放时,收听的用户只能听到或者主要听到一个或者多个用户的声音。
12、在第一方面的一种可实现方式中,控制设备在去除或者削弱第一用户的声音的过程中,还可以对第一声音进行对象化处理,并根据对象化处理获得的结果,确定出第一声音中满足第一预设音质条件的第一用户的声音,其中,第一用户包括一个或者多个用户。之后,控制设备在第一声音和第二声音的混音中,去除或者削弱满足预设音质条件的第一用户的声音。这种实现方式中,如果第一用户包括多个用户,那么控制设备从多个用户的声音中确定出音质较高的声音,并确定该声音对应的用户为需要静音的用户,从而只对一个用户的声音进行抑制处理。
13、其中,第一预设音质条件可以表示用户的声音信噪比是否大于或者等于第二预设信噪比、响度是否大于或者等于预设响度等。
14、在第一方面的一种可实现方式中,控制设备在增强第一用户的声音的过程中,还可以对第一声音进行对象化处理,并根据对象化处理获得的结果,确定出第一声音中满足第二预设音质条件的第一用户的声音,其中,第一用户包括一个或者多个用户。之后,控制设备在第一声音和第二声音的混音中,增强满足预设音质条件的第一用户的声音。这种实现方式中,如果第一用户包括多个用户,那么控制设备从多个用户的声音中确定出音质较高的声音,并确定该声音对应的用户为需要发言的用户,从而只对一个用户的声音进行增强处理。
15、其中,第二预设音质条件也可以表示用户的声音信噪比是否大于或者等于第二预设信噪比、响度是否大于或者等于预设响度等。
16、在一方面的其他可实现方式中,控制设备还可以根据第二声音确定第二设备对应的声源数量,从而确定第二用户的拾音需求模式;根据第二声音确定第二设备对应的声音信噪比,从而确定第二用户的拾音需求模式;以及,获取第二声音的语义内容,并根据语义内容确定第二用户的拾音需求模式。并且具体的确定方式可以参见前述各个实现方式,此处不再赘述。
17、第二方面,提供另一种声音处理方法,该方法应用于拾音系统,拾音系统包括控制设备、第一设备和可拾取到第一设备所在位置声音的第二设备。该声音处理方法中,第一设备拾取第一声音。第二设备拾取第二声音。控制设备根据第一声音,确定第一设备对应的第一用户的拾音需求模式,以及根据第二声音,确定第二设备对应的第二用户的拾音需求模式。并且,控制设备在第一用户的拾音需求模式为静音以及第二用户的拾音需求模式为非静音的情况下,在第一声音和第二声音混合后的混音中,去除或者削弱第一用户的声音。
18、以及,第一设备还可以播放去除或者削弱第一用户的声音后的混音,第二设备也可以播放去除或者削弱第一用户的声音后的混音。并且该混音被播放时,收听的用户无法听到或者听清楚第一用户说话的内容。
19、上述方案可以应用于多人互动场景中,并且多人互动场景中包括用于拾音的拾音设备和用于控制拾音设备的控制设备等。各个拾音设备可以主动拾取至少一个用户在多人互动过程中的声音,并且,控制设备根据拾音设备拾取到的声音可以自动地识别出拾音设备对应的用户在多人互动过程中的拾音需求模式。之后,控制设备再根据用户的拾音需求模式,对用户对应的拾音设备拾取的声音进行处理。例如,用户有静音需求时,对拾音设备拾取的声音进行抑制处理等。无论用户在什么位置上,这种声音处理方法,都能自动识别用户的拾音需求模式,并且在用户的拾音需求模式发生变化时,也可以实时地根据用户的拾音需求模式对拾取到的用户的声音进行处理,从而满足参与多人互动中不同位置的不同用户的需求,减少用户手动改变拾音设备的拾音状态的操作,保证用户的体验,也提高声音处理的准确性和质量。
20、在第二方面的一种可实现方式中,控制设备还在第一用户的拾音需求模式为发言以及第二用户的拾音需求模式为非发言的情况下,在第一声音和第二声音混合后的混音中,增强第一用户的声音。以及,第一设备还可以播放增强第一用户的声音后的混音,第二设备也可以播放增强第一用户的声音后的混音。并且该混音被播放时,收听的用户可以主要听到第一用户的声音或者只能听到第一用户的声音。可见,控制设备不仅能根据第一用户的静音需求将第一用户的声音进行抑制,还可以根据第一用户的发言需求将第一用户的声音进行增强,从而满足用户的不用的需求,保证用户的体验。
21、在第二方面的一种可实现方式中,控制设备可以根据第一声音确定第一设备对应的声源数量。若第一设备对应的声源数量为1,则可以确定第一用户的拾音需求模式为发言;若第一设备对应的声源数据量大于1,则可以确定第一用户的拾音需求模式为非发言。这种实现方式中,控制设备可以根据各个拾音设备对应的声源数量确定各个拾音设备对应的用户中是否有用户在说话,以及说话的用户有几个,进而确定出是否需要对各个拾音设备拾取的声音(例如拾音设备对应的用户的声音)进行处理。
22、在第二方面的一种可实现方式中,控制设备可以根据第一声音确定第一设备对应的声音信噪比。若第一设备对应的声音信噪比小于第一预设信噪比,则可以确定第一用户的拾音需求模式为静音;若第一设备对应的声音信噪比大于或者等于第一预设信噪比,则可以确定第一用户的拾音需求模式为非静音。这种实现方式中,控制设备可以根据各个拾音设备的声音信噪比确定各个拾音设备对应的用户所处的声音环境,进而确定出是否需要对各个拾音设备拾取的声音(例如拾音设备对应的用户的声音)进行处理。
23、在第二方面的一种可实现方式中,控制设备可以获取第一声音的语义内容。若第一声音的语义内容与预设内容的相似度小于预设相似度,则可以确定第一用户的拾音需求模式为静音;若第一声音的语义内容与预设内容的相似度大于或者等于预设相似度,则可以确定第一用户的拾音需求模式为非静音。这种实现方式中,控制设备可以根据各个拾音设备拾取的声音内容的语义确定各个拾音设备对应的用户是否在发言,进而确定出是否需要对各个拾音设备拾取的声音(例如拾音设备对应的用户的声音)进行处理。
24、在第二方面的一种可实现方式中,上述控制设备可以是拾音系统中的第一设备或第二设备,即可以由拾音系统中的第一设备或者第二设备进行用户的拾音需求模式的识别,以及对声音进行抑制或者增强的处理。或者,上述控制设备也可以是云端设备,即拾音系统中的第一设备和第二设备也可以与云端设备通信。
25、在第二方面的一种可实现方式中,控制设备在第一声音和第二声音混合后的混音中,去除或者削弱第一用户的声音时,可以对第一声音进行对象化处理,获得第一用户的声音。之后,控制设备在第一声音和第二声音的混音中,去除或者削弱第一用户的声音。这种实现方式中,控制设备可以将第一声音进行对象化处理,从而根据对象化处理的结果确定出第一声音中包括几个用户的声音。控制设备再将一个或者多个用户的声音从其他拾音设备拾取的混音中去除或者削弱。从而混音被播放时,收听的用户无法听到或者听不清清楚一个或者多个用户的声音。
26、在第二方面的一种可实现方式中,控制设备在第一声音和第二声音混合后的混音中,增强第一用户的声音时,可以对第一声音进行对象化处理,获得第一用户的声音。控制设备在第一声音和第二声音的混音中,增强第一用户的声音或者去除第一用户以外的其他用户的声音。这种实现方式中,控制设备也可以将第一声音进行对象化处理,从而根据对象化处理的结果确定出第一声音中包括几个用户的声音。控制设备再将一个或者多个用户的声音进行增强处理。从而混音被播放时,收听的用户只能听到或者主要听到一个或者多个用户的声音。
27、在第二方面的一种可实现方式中,控制设备在第一声音和第二声音混合后的混音中,去除或者削弱第一用户的声音时,可以对第一声音进行对象化处理,并根据对象化处理获得的结果,确定出第一声音中满足第一预设音质条件的第一用户的声音;其中,第一用户包括一个或者多个用户。控制设备在第一声音和第二声音的混音中,去除或者削弱满足预设音质条件的第一用户的声音。这种实现方式中,如果第一用户包括多个用户,那么控制设备从多个用户的声音中确定出音质较高的声音,并确定该声音对应的用户为需要静音的用户,从而只对一个用户的声音进行抑制处理。
28、其中,第一预设音质条件可以表示用户的声音信噪比是否大于或者等于第二预设信噪比、响度是否大于或者等于预设响度等。
29、在第二方面的一种可实现方式中,控制设备在第一声音和第二声音混合后的混音中,增强第一用户的声音时,可以对第一声音进行对象化处理,并根据对象化处理获得的结果,确定出第一声音中满足第二预设音质条件的第一用户的声音;其中,第一用户包括一个或者多个用户。控制设备在第一声音和第二声音的混音中,增强满足预设音质条件的第一用户的声音。这种实现方式中,如果第一用户包括多个用户,那么控制设备从多个用户的声音中确定出音质较高的声音,并确定该声音对应的用户为需要发言的用户,从而只对一个用户的声音进行增强处理。
30、其中,第二预设音质条件也可以表示用户的声音信噪比是否大于或者等于第二预设信噪比、响度是否大于或者等于预设响度等。
31、在二方面的其他可实现方式中,控制设备还可以根据第二声音确定第二设备对应的声源数量,从而确定第二用户的拾音需求模式;根据第二声音确定第二设备对应的声音信噪比,从而确定第二用户的拾音需求模式;以及,获取第二声音的语义内容,并根据语义内容确定第二用户的拾音需求模式。并且具体的确定方式可以参见前述各个实现方式,此处不再赘述。
32、第三方面,提供一种拾音系统,包括控制设备、第一设备和可拾取到第一设备所在位置声音的第二设备。其中,第一设备用于拾取第一声音;第二设备用于拾取第二声音;控制设备用于根据第一声音,确定第一设备对应的第一用户的拾音需求模式,以及根据第二声音,确定第二设备对应的第二用户的拾音需求模式;在第一用户的拾音需求模式为静音以及第二用户的拾音需求模式为非静音的情况下,在第一声音和第二声音混合后的混音中,去除或者削弱第一用户的声音。以及,第一设备还用于播放去除或者削弱第一用户的声音后的混音。第二设备还用于播放去除或者削弱第一用户的声音后的混音。
33、在第三方面的一种可实现方式中,控制设备还可以在第一用户的拾音需求模式为发言以及第二用户的拾音需求模式为非发言的情况下,在第一声音和第二声音混合后的混音中,增强第一用户的声音。其中,增强第一用户的声音后的混音用于被第一设备和/或第二设备播放,并且该混音被播放时,收听的用户可以主要听到第一用户的声音或者只能听到第一用户的声音。
34、在第三方面的一种可实现方式中,控制设备可以根据第一声音确定第一设备对应的声源数量,从而确定第一用户的拾音需求模式。其中,若第一设备对应的声源数量为1,则可以确定第一用户的拾音需求模式为发言;若第一设备对应的声源数据量大于1,则可以确定第一用户的拾音需求模式为非发言。
35、在第三方面的一种可实现方式中,控制设备可以根据第一声音确定第一设备对应的声音信噪比,从而确定第一用户的拾音需求模式。其中,若第一设备对应的声音信噪比小于第一预设信噪比,则可以确定第一用户的拾音需求模式为静音;若第一设备对应的声音信噪比大于或者等于第一预设信噪比,则可以确定第一用户的拾音需求模式为非静音。
36、在第三方面的一种可实现方式中,控制设备可以获取第一声音的语义内容,并根据语义内容确定第一用户的拾音需求模式。其中,若第一声音的语义内容与预设内容的相似度小于预设相似度,则可以确定第一用户的拾音需求模式为静音;若第一声音的语义内容与预设内容的相似度大于或者等于预设相似度,则可以确定第一用户的拾音需求模式为非静音。
37、在第三方面的一种可实现方式中,上述控制设备可以是拾音系统中的第一设备或第二设备,即可以由拾音系统中的第一设备或者第二设备进行用户的拾音需求模式的识别,以及对声音进行抑制或者增强的处理。或者,上述控制设备也可以是云端设备,即拾音系统中的第一设备和第二设备也可以与云端设备通信。
38、在第三方面的一种可实现方式中,控制设备在去除或者削弱第一用户的声音的过程中,可以先对第一声音进行对象化处理,获得第一用户的声音。之后,在第一声音和第二声音的混音中,去除或者削弱第一用户的声音。
39、在第三方面的一种可实现方式中,控制设备在增强第一用户的声音的过程中,可以先对第一声音进行对象化处理,获得第一用户的声音,之后,在第一声音和第二声音的混音中,增强第一用户的声音或者去除第一用户以外的其他用户的声音。
40、在第三方面的一种可实现方式中,控制设备在去除或者削弱第一用户的声音的过程中,还可以对第一声音进行对象化处理,并根据对象化处理获得的结果,确定出第一声音中满足第一预设音质条件的第一用户的声音,其中,第一用户包括一个或者多个用户。之后,控制设备在第一声音和第二声音的混音中,去除或者削弱满足预设音质条件的第一用户的声音。
41、其中,第一预设音质条件可以表示用户的声音信噪比是否大于或者等于第二预设信噪比、响度是否大于或者等于预设响度等。
42、在第三方面的一种可实现方式中,控制设备在增强第一用户的声音的过程中,还可以对第一声音进行对象化处理,并根据对象化处理获得的结果,确定出第一声音中满足第二预设音质条件的第一用户的声音,其中,第一用户包括一个或者多个用户。之后,控制设备在第一声音和第二声音的混音中,增强满足预设音质条件的第一用户的声音。
43、其中,第二预设音质条件也可以表示用户的声音信噪比是否大于或者等于第二预设信噪比、响度是否大于或者等于预设响度等。
44、在三方面的其他可实现方式中,控制设备还可以根据第二声音确定第二设备对应的声源数量,从而确定第二用户的拾音需求模式;根据第二声音确定第二设备对应的声音信噪比,从而确定第二用户的拾音需求模式;以及,获取第二声音的语义内容,并根据语义内容确定第二用户的拾音需求模式。并且具体的确定方式可以参见前述各个实现方式,此处不再赘述。
45、第四方面,提供一种电子设备,电子设备包括存储器、一个或多个处理器;存储器与处理器耦合;其中,存储器中存储有计算机程序代码,计算机程序代码包括计算机指令,当计算机指令被处理器执行时,使得电子设备执行如第一方面任一实现方式中的声音处理方法,或者执行如第二方面任一实现方式中的声音处理方法。
46、其中,当电子设备执行如第二方面任一实现方式中的声音处理方法时,电子设备可以是上述拾音系统中的控制设备、第一设备和/或第二设备。
47、第五方面,提供一种计算机可读存储介质,包括计算机指令,当计算机指令在电子设备上运行时,使得电子设备执行第一方面任一实现方式中的声音处理方法,或者执行如第二方面任一实现方式中的声音处理方法。
48、第六方面,提供一种计算机程序产品,当计算机程序产品在计算机上运行时,使得计算机执行如第一方面任一实现方式中的声音处理方法,或者执行如第二方面中任一实现方式中的声音处理方法。
49、可以理解地,上述提供的第二方面所述的声音处理方法,第三方面所述的拾音系统,第四方面所述的电子设备,第五方面所述的计算机可读存储介质,第六方面所述的计算机程序产品所能达到的有益效果,可参考第一方面及其任一种可能的设计方式中的有益效果,此处不再赘述。
- 还没有人留言评论。精彩留言会获得点赞!