一种基于深度强化学习的多充电器载体分离充电方法
1.本发明属于无线能量传输技术延长无线传感器网络生命周期技术领域,具体涉及一种基于深度强化学习的多充电器载体分离充电方法。
背景技术:
2.能量约束问题一直是限制无线传感器网络(wireless sensor network,wsn)发展的重要因素之一。因为传感器携带的能量有限,使得wsn不能实现长久的工作,制约了wsn的发展,也限制了其应用范围。随着无线充电技术的发展,在受能量约束的无线传感器网络中部署移动充电车(mobile charging vehicle,mcv)为传感器充电,有效地延长了网络的生存时间,无线可充电传感器网络(wireless rechargeable sensor network,wrsn)也因此应运而生。如今,wrsn已广泛应用于军事、农业生产、森林防火、生态监测等多个领域。然而,如何有效地规划mcv的充电路径进而延长wrsn的生存时间成为了wrsn的关键性研究问题。
3.无线可充电传感器网络在wsn的基础上配备了一个mcv,mcv携带多个便携式无线充电器,同时传感器节点配备有射频电路,使它们能够从无线充电器接收能量。在充电-回收算法的调度过程中,mcv移动到请求充电的传感器节点处放置无线充电器为其进行充电,或者移动到完成充电任务的无线充电器节点处回收充电器,使wrsn能够实现长久的运行。
4.tao zou等学者于2017年在ad hoc networks发表的“improving charging capacity for wireless sensor networks by deploying one vehicle with multiple removable chargers”提出了一种带有多个可拆卸无线充电器的无线可充电传感器网络。在每一轮的充电周期中,mcv携带若干个充电器从基站出发,沿着事先规划好的路径依次把充电器放置在请求充电的传感器节点位置处为其充电。待充电器完成充电任务后,沿着原路径回收所有充电器。与传统的wrsn相比,传统的wrsn中mcv需要停下来给传感器充电,而充电的这段时间有可能忽略了一些重要的充电机会从而导致传感器节点死亡。而本发明中的mcv通过携带多个无线充电器的方法解决了这一问题。
5.网络中的传感器能量实时动态变化,mcv通过事先规划好的路径给传感器充电,可能存在不能及时给能量消耗率高的传感器充电的情况。而且,先充电再回收的这种充电模式,使mcv的行驶路程大大增加,降低了能量利用率。
6.现有技术中,没有利用深度强化学习技术解决wrsn中一个mcv携带多个可分离充电器的动态充电-回收调度策略的优化。在动态充电-回收策略中,现有技术大多只考虑了mcv的充电路径和回收路径的分开进行,即在一轮充电调度中,先进行传感器的充电然后进行充电器的回收,而没有考虑到充电过程中的充电和回收动作的联合交叉进行,即充电动作与回收动作没有先后顺序,可以交叉进行。这种策略可以有效减少传感器节点的死亡率和mcv的移动距离。
技术实现要素:
7.为了解决上述技术问题,本发明提供了一种基于深度强化学习的多充电器载体分
离充电方法,在提高能量利用率的同时还可以有效减少网络中传感器节点的死亡率,提高传感器网络的生存时间。
8.为了达到上述技术目的,本发明是通过以下技术方案实现的:
9.一种基于深度强化学习的多充电器载体分离充电方法,包括以下步骤:
10.s1:在一个二维平面上,构建无线可充电传感器模型;该模型包括:具有远距离通信功能的基站(base station,bs);携带m个便携式无线充电器,具有装载-卸载功能、通信功能和计算功能的mcv;服务站(service station,ss),其能够为mcv和无线充电器补充能量;n个同质化传感器节点;
11.s2:以最小化死亡节点数和mcv的移动距离为目标,建立目标优化模型,并设计基于深度强化学习的多充电器载体分离充电方案(csmcsdrl);
12.s3:mcv通过csmcsdrl算法选择移动到目标网络中的传感器节点处放置无线充电器为其充电,或选择移动到完成充电任务的无线充电器节点处回收充电器;
13.s4:当mcv的剩余能量不足以支持其进行下一步动作后回收所有无线充电器回到服务站或所有无线充电器的剩余能量达到阈值时,mcv回收所有无线充电器返回服务站进行能量补充,为下一轮充电调度做准备;否则,执行步骤s3。
14.优选的,所述s1中基站部署在二维平面中间;
15.优选的,所述s1中传感器节点电池最大容量为es,节点i在时隙t时的能耗模型为:
[0016][0017]
式中,f
k,i
(f
i,j
)(1《i《n)kbps为从传感器节点k(i)传输到传感器节点i(j)的数据流;f
i,b
kbps为从传感器节点i传输到基站的数据流;ρ是接收1kb/s数据的能耗;c
i,j
(c
i,b
)为传感器节点i向传感器节点j(bs)传输1kb/s数据时的功耗,且其中β为能量消耗因子,d
i,j
为传感器节点i,j之间的距离;γ为信号衰减因子,其值的取值与很多因素有关,例如传感器节点部署贴近地面时,障碍物多、干扰大,γ的取值就越大,这里取γ的值为3;e
p
和es分别为传感器节点中处理器模块和传感器模块的能耗;那么,在时隙t,传感器节点i的剩余能量为:
[0018][0019]
则在时隙t,传感器节点i的能量需求为:
[0020][0021]
上式中,λ(0<λ≤1)为充电系数,λes为传感器节点的充电上限;
[0022]
当传感器节点的剩余能量小于阈值se
th
时,其向基站发出充电请求其中xi和yi分别为传感器节点的横坐标和纵坐标,为其剩余能量;当传感器节点的能量被充满时,其向基站发送回收请求其中xi和yi分别为为传感器充电的无线充电器的横坐标和纵坐标,为该充电器的剩余能量;当传感器节点的剩余能量为零时,其被标记为死亡状态,不再接受充电器的能量补充行为。
[0023]
优选的,所述s1中mcv初始能量为emj,速度为vm/s,移动过程中的能耗为qmj/m,其
初始位置从服务站出发,在第k步时,mcv的剩余能量为:
[0024][0025]
式中dk为mcv在第k步时的移动距离;
[0026]
优选的,所述s1中mcv携带的m个相同的无线充电器,其初始能量为ecj,充电功率为qcw,在时隙t时,无线充电器j的剩余能为:
[0027][0028]
上式为无线充电器j给传感器i充电的剩余能量模型;若无线充电器没有给任何传感器充电,则其剩余能量不变;
[0029]
当mcv在执行下一步动作后并回收所有的无线充电器后的剩余能量不足以支撑其回到服务站时,或者所有的无线充电器剩余能量达到阈值ce
th
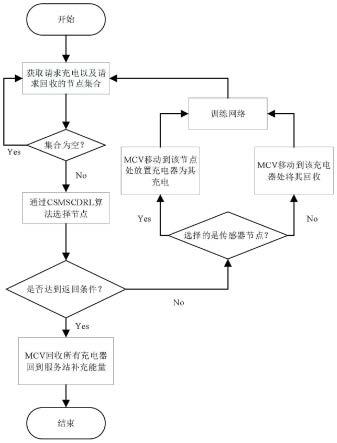
时,mcv回收所有的无线充电器返回服务站进行能量补充,为下一轮充电做准备;
[0030]
优选的,所述s1服务站的坐标为(xs,ys)为:
[0031][0032][0033]
上式中wi表示传感器节点i的充电频率,因为wi与节点的功耗正相关,因此将其表示为其中,pi为传感器节点在一个周期内的平均功耗,将其表示为其中t为网络生命周期内充电序列的长度,为传感器节点i在时隙t时的功耗;则
[0034]
优选的,所述s2基于深度强化学习的多充电器载体分离充电方案是:当传感器节点的剩余能量达到阈值时或无线充电器完成充电时,传感器会通过多跳的方式给基站发送充电请求或回收请求,基站再将请求信息发送给mcv,mcv将接收到的请求加入到请求队列中,然后基于深度强化学习根据请求队列中的节点信息选择充电或回收动作,最后执行充电或回收任务;
[0035]
优选的,所述s2的目标优化模型为:
[0036][0037]
其中,n
dead
为每一步死亡传感器节点的数量,d为每一步mcv的移动距离,k为充电
序列的长度;且以最小化死亡传感器的数量为主要目标;
[0038]
优选的,所述s3中的csmcsdrl算法的具体步骤为:
[0039]
智能体mcv在当前状态s
t
以概率ε根据当前网络选择最优动作或者以概率1-ε随机选择一个动作a
t
,其中a为动作空间且a
t
∈a;mcv在与环境交互的的过程获得奖励r
t
并且达到新的状态s
t+1
;然后将mcv与环境交互过程中获得的经验元组(s
t
,a
t
,r
t
,s
t+1
)存入经验回放池中;当经验回放池满了之后,从其中随机抽取一批样本训练当前q网络,并且在每一个c步,将当前q网络的参数θ赋值给目标q网络的参数θ';
[0040]
在csmcsdrl算法中,把传感器以及无线充电器都看成可选择节点;mcv的动作可以是运输无线充电器到请求充电的传感器节点处给其充电,或者回收网络中完成充电任务的无线充电器节点;
[0041]
优选的,所述奖励函数定义为:
[0042]
r=e-αd
+βn
dead
ꢀꢀ
(9)
[0043]
上式中α为距离系数;β为传感器节点死亡的惩罚因子,其为一个负数;
[0044]
因此,一轮充电调度的总的奖励为:
[0045][0046]
mcv在网络中通过不断的学习来获得更高的奖励值r
total
,进而学习到更优的策略来接近最优解。
[0047]
本发明的有益效果是:
[0048]
本发明通过使用深度强化学习算法来优化mcv的充电-回收调度,该算法把传感器和无线充电器都视为可选择节点,使mcv在关注当前奖励的同时还考虑到未来奖励,合理选择充电动作或回收动作,不仅可以避免传感器节点因为等待时间过长而死亡,也可以有效减少充电成本。该方法在提高能量利用率的同时还可以有效减少网络中传感器节点的死亡率,提高传感器网络的生存时间。
附图说明
[0049]
图1:基于深度强化学习的多充电器载体分离充电方法原理图;
[0050]
图2:无线可充电传感器网络模型图;
[0051]
图3:csmscdrl网络结构图;
[0052]
图4:本发明的充电-回收调度方案示意图。
具体实施方式
[0053]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。
[0054]
实施例1
[0055]
如图1所示为本发明方法的算法流程图,本发明提出的这种基于深度强化学习的
多充电器载体分离充电方案,具体步骤如下:
[0056]
s1:如图2所示构建无线可充电传感器模型:基站部署在二维平面区域正中间;n个同质化的传感器节点随机分布在网络中,其电池最大容量为es;当传感器节点的剩余能量小于阈值se
th
时,其向基站发出充电请求;当传感器的能量被充满时,其向基站发出回收请求;当传感器节点的剩余能量为零时,其被标记为死亡状态,不再接受充电器的能量补充行为;mcv初始能量为emj,速度为vm/s,移动过程中的能耗为qmj/m,其初始位置从服务站出发;mcv携带m个相同的无线充电器,其初始能量为ecj,充电功率为qcw;服务站则部署在网络中平均能耗高的地方;
[0057]
在无线可充电传感器网络中,各个传感器节点之间通过自组织的方式与基站节点共同组成传感器网络,主要负责监测区域内数据的采集、转发、存储以及处理;基站则负责接收来自传感器节点的数据并对数据做进一步的分析和处理,除此之外,基站还负责与mcv进行远距离通信完成充电任务的下达;服务站、mcv以及无线充电器组成充电系统,主要负责为传感器网络提供能量,其中,mcv通过运输无线充电器为传感器节点提供能量,服务站则为mcv和无线充电器提供能量补充。
[0058]
s2:以最小化死亡节点数和mcv的移动距离为目标,建立目标优化模型,并设计基于深度强化学习的多充电器载体分离充电方案(carrier separation with multi-charger charging scheme based on deep reinforcement learning,简称csmcsdrl),该方案的工作过程是:当传感器节点的剩余能量达到阈值时或无线充电器完成充电时,传感器会通过多跳的方式给基站发送充电请求或回收请求,基站再将请求信息发送给mcv,mcv将接收到的请求加入到请求队列中,然后基于深度强化学习根据请求队列中的节点信息选择充电或回收动作,最后执行充电或回收任务;
[0059]
s3:mcv通过csmcsdrl算法选择移动到目标网络中的传感器节点处放置无线充电器为其充电,或选择移动到完成充电任务的无线充电器节点处回收充电器;当所有的无线充电器能量达到阈值或mcv的剩余能量不足以支持其进行下一步动作后回收所有的无线充电器返回服务站时,mcv回收所有的无线充电器回到服务站补充能量,为下次充电调度做准备;
[0060]
具体地,传感器节点在时隙t时的能耗模型为:
[0061][0062]
式中,f
k,i
(f
i,j
)(1《i《n)kbps为从传感器节点k(i)传输到传感器节点i(j)的数据流;f
i,b
kbps为从传感器节点i传输到基站的数据流;ρ是接收1kb/s数据的能耗;c
i,j
(c
i,b
)为传感器节点i向传感器节点j(bs)传输1kb/s数据时的功耗,且其中β为能量消耗因子,d
i,j
为传感器节点i,j之间的距离;γ为信号衰减因子,其值的取值与很多因素有关,例如传感器节点部署贴近地面时,障碍物多、干扰大,γ的取值就越大,这里取γ的值为3;e
p
和es分别为传感器节点中处理器模块和传感器模块的能耗;那么,在时隙t,传感器节点i的剩余能量为:
[0063][0064]
则在时隙t,传感器节点i的能量需求为:
[0065][0066]
上式中,λ(0<λ≤1)为充电系数,λes为传感器节点的充电上限。
[0067]
当传感器节点的剩余能量小于阈值se
th
时,其向基站发出充电请求其中xi和yi分别为传感器节点的横坐标和纵坐标,为其剩余能量;当传感器节点的能量被充满时,其向基站发送回收请求其中xi和yi分别为为传感器充电的无线充电器的横坐标和纵坐标,为该充电器的剩余能量;当传感器节点的剩余能量为零时,其被标记为死亡状态,不再接受充电器的能量补充行为。
[0068]
具体的,在第k步时,mcv的剩余能量为:
[0069][0070]
式中dk为mcv在第k步时的移动距离;
[0071]
在时隙t时,无线充电器j的剩余能为:
[0072][0073]
上式为无线充电器j给传感器i充电的剩余能量模型;
[0074]
当所有的无线充电器能量达到阈值或mcv的剩余能量不足以支持其进行下一步动作后回收所有的无线充电器返回服务站时,mcv回收所有的无线充电器回到服务站补充能量,为下次充电调度做准备。
[0075]
具体的,服务站的坐标为(xs,ys)为:
[0076][0077][0078]
上式中wi表示传感器节点i的充电频率,因为wi与节点的功耗正相关,因此将其表示为其中,pi为传感器节点在一个周期内的平均功耗,将其表示为其中t为网络生命周期内充电序列的长度,为传感器节点i在时隙t时的功耗;则
[0079]
具体地,本发明的目标优化模型为:
[0080][0081]
其中,n
dead
为每一步死亡传感器节点的数量,d为每一步mcv的移动距离,k为充电序列的长度;且以最小化死亡传感器的数量为主要目标;
[0082]
如图3所示,csmcsdrl中的网络模型为两个神经网络:一个是参数为θ的q网络,另一个是参数为θ
‘
的目标q网络。智能体mcv在当前状态s
t
以概率ε根据当前网络选择最优动作或者以概率1-ε随机选择一个动作a
t
,其中a为动作空间且a
t
∈a;mcv在与环境交互的的过程获得奖励r
t
并且达到新的状态s
t+1
;然后将mcv与环境交互过程中获得的经验元组(s
t
,a
t
,r
t
,s
t+1
)存入经验回放池中;当经验回放池满了之后,从其中随机抽取一批样本训练当前q网络,并且在每一个c步,将当前q网络的参数θ赋值给目标q网络的参数θ
‘
。
[0083]
在csmcsdrl算法中,把传感器以及无线充电器都看成可选择节点;mcv的动作可以是运输无线充电器到请求充电的传感器节点处给其充电,或者回收网络中完成充电任务的无线充电器节点;
[0084]
为了使智能体学习到更好的策略,把奖励函数定义为:
[0085]
r=e-αd
+βn
dead
ꢀꢀ
(9)
[0086]
上式中α为距离系数;β为传感器节点死亡的惩罚因子,其为一个负数;d为mcv每一步的移动距离;n
dead
为每一步死亡传感器的数量;
[0087]
因此,一轮充电调度的总的奖励为:
[0088][0089]
mcv在网络中通过不断的学习来获得更高的奖励值r
total
,进而学习到更优的策略来接近最优解。
[0090]
s4:当mcv的剩余能量不足以支持其进行下一步动作后回收所有的无线充电器返回服务站或所有无线充电器的剩余能达到阈值时,mcv回收所有无线充电器返回服务站进行能量补充,从而完成一轮充电调度;
[0091]
具体地,在第k+1步时,当或时,mcv回收所有无线充电器返回服务站进行能量补充,其中l
hamilton
为mcv回收所有无线充电器后返回服务站的最短哈密顿路径长度。
[0092]
实施例2
[0093]
如图4所示,例如在一段时间内,两个传感器节点n2和n3在其剩余能量低于阈值se
th
时分别发送充电请求两个传感器节点n1和n4在其电量被充满后发送
回收请求基站将这些请求发送给mcv后并构成集合d(t1)=(s2,s3,c1,c4),csmcsdrl算法根据请求集合中的位置信息和剩余能量信息规划充电序列,生成序列c1→
n2→
n3→
c4,即mcv先回收无线充电器c1,然后分别移动到传感器节点n2和n3处放置无线充电器为其充电,最后回收充电器c4。该序列能够保证传感器节点n2和n3不死亡的情况下使mcv的移动路径最短。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1