基于雅各比显著图的单交叉口信号灯控制的交通状态对抗扰动生成方法
1.本发明属于智能交通与深度强化学习的交叉技术领域,具体涉及一种基于雅各比显著图的单交叉口信号灯控制的交通状态对抗扰动生成方法。
背景技术:
2.随着城镇化进程的加快和城市发展水平的飞速提高,交通状况越来越成为现代城市系统中的重要考虑因素。面对日趋严重的交通拥堵,可寄希望于设计智能化的交通系统,通过更高水平的自动化来实现更高效的交通管理,从而达到节省交通时间、节约交通能源、降低交通风险等目的。
3.智能交通系统对自动控制有着严格的要求,因此考虑借助基于学习模型的人工智能技术,实现对系统自适应的控制。强化学习(rl)作为机器学习中的分支,区别于传统的监督学习和无监督学习,其主要特点在于在交互中学习。即强化学习模型中的智能体会与周围环境进行互动,在输出动作的同时接收反馈。通过预设的奖励机制,智能体能够评估之前采取的动作并逐步学习到环境的信息,从而掌握能够获取最大奖励的行动策略,这也就是强化学习智能体的目标。与深度神经网络结合产生的深度强化学习(drl),由于其出色的决策和感知能力,目前具备极大的应用潜力。如在交通信号灯的控制优化问题中,drl就有希望成为新的解决方案。但同时,drl也被证实容易受到对抗性扰动的影响,可能会带来各种意想不到的潜在危害。
4.随着drl日益成为人工智能研究的热点并在图像、游戏、无人系统等领域得到越发广泛的应用,其对于攻击的鲁棒性也受到更多的关注。通过提出威胁模型和可能的攻击手段,研究人员能够建立更加完善的防御机制,以此提升drl模型面对攻击的抵抗能力。在本发明中,我们采用具有代表性的deep q network(dqn)算法,以单交叉口信号灯的控制为应用场景,并基于雅各比显著图法(jsma)进行攻击生成对抗样本。
技术实现要素:
5.为了拓展已有的技术,本发明提供一种基于雅各比显著图的单交叉口信号灯控制的交通状态对抗生成方法,可以在只添加少量扰动的前提下形成高效的对抗样本,使得信号灯的输出动作发生显著变化,对模型的性能和单交叉口路段的交通流畅度造成大幅影响。
6.本发明采用的技术方案是:
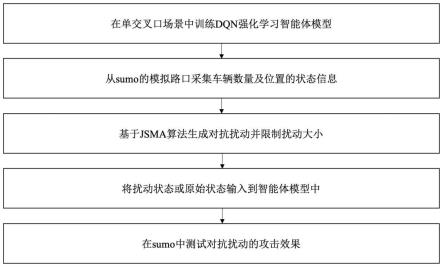
7.一种基于雅各比显著图的单交叉口信号灯控制的交通状态对抗扰动生成方法,包括以下步骤:
8.步骤1:在模拟的单交叉口路段对智能体模型进行训练,并使dqn网络保持训练后的w、b参数不变,模型具有一定的可迁移性;初始训练完成的智能体在模拟路段应表现出较好的交通流畅度,与对抗攻击施加后形成的流畅度形成对比;
9.步骤2:在单交叉口的各个路口获取道路状态作为模型的输入,即每条道路上的车辆数量与车辆位置,模型则会给出相应的动作输出,即信号灯的相位,然后基于jsma攻击算法添加扰动生成对抗样本;
10.步骤3:计算扰动的幅度,若扰动在限制的范围以内,则将上一步得到的对抗状态输入模型,否则输入原始的状态;
11.步骤4:扰动输入后,模型会输出相应的信号灯动作,来控制单交叉口的道路交通状况,通过对比经过交叉路口车辆的等待时间,可以分析对抗攻击的效果。
12.进一步的,所述步骤1的过程如下:
13.首先在sumo的单交叉口道路上训练强化学习智能体模型;
14.其次对环境中所有道路上的交通状态做离散化处理:设道路入口到停车线的距离为l,将道路上的车道k(k=1,2,3,4)等距离划分为c个单元;t时刻车道k上的车辆位置表示为矩阵sk(t),当车辆的头部位于某个离散单元上时,则sk(t)对应位置i(i=1,2,...,c)的值为0.5,否则为-0.5;将四个路口的sk(t)按行排列,即得到要输入到模型中的原始环境状态s
t
;
15.对于智能体模型,输入作为交通状况的环境状态,将得到特定的交通信号灯动作;将信号灯相位作为智能体的动作空间a={a1,a2,a3,a4},其中a1为南北方向直行绿灯,a2为南北方向左转绿灯,a3为东西方向直行绿灯,a4为东西方向左转绿灯;设置ai的初始绿灯相位持续时长为m,黄灯相位时长为n;将当前状态s
t
输入到模型中,智能体输出相应的ai(i=1,2,3,4)作为动作,ai的持续时间结束后,智能体继续从环境中采集下一时刻的状态s
t+1
,然后输出相位aj(j=1,2,3,4);若ai≠aj,ai的绿灯相位结束后执行n时长的黄灯相位,之后再执行aj相位;否则将ai的执行时间延长m时长;将强化学习的奖励r
t
设置为两个动作之间路口车辆总等待时间之差,公式表示如下:
16.r
t
=w
t-w
t+1
ꢀꢀꢀ
(1)
17.其中w
t
,w
t+1
分别表示t和t+1时刻进入单交叉口所有车辆的等待时间之和;使用dqn作为强化学习模型,初始化后神经网络的输出即为q值;深度神经网络的隐含层使用relu作为激活函数,输出的神经元个数设置为与交通信号灯的动作空间大小相等;公式表示如下:
18.q=h(ws
t
+b)
ꢀꢀꢀ
(2)
19.其中w表示神经网络的权重,s
t
为t时刻网络的输入,b为偏置,h(.)代表relu激活函数。dqn的损失函数表示为:
[0020][0021]
l
t
=(y
t-q(s
t
,ai;θ
′
))2ꢀꢀꢀ
(4)
[0022]
其中γ为学习率,θ和θ
′
分别代表目标网络和估计网络的参数w、b以及w’、b’;随着强化学习智能体的训练,目标网络的参数根据时间步长进行更新,更新方式为每隔时间t从估计网络中直接复制参数到目标网络中,公式表示如下:
[0023]
[0024][0025]
进一步的,所述步骤2的过程如下:
[0026]
2.1:获取原始的环境状态s
t
,将其输入已经训练好的dqn智能体模型中,选择出使q函数值最大的动作am(m=1,2,3,4),即为此时刻最优的信号灯动作,公式表示如下:
[0027][0028]
其中θ表示训练好的智能体的参数w、b,am表示交通信号灯接下来的动作。
[0029]
2.2:基于jsma攻击算法,沿梯度方向计算神经网络输出对于输入的雅各比矩阵,并表示出基于输入状态s
t
的显著图x,用来描述输入状态中哪些信息对于输出的影响最大;对于输入s
ti
(i=1,2,3,
…
,80)来说,显著图x的公式表示如下:
[0030][0031]
其中表示神经网络输出对于输入s
t
的前向导数;选择出使显著图x最大的输入特征s
ti
,修改特征使其+1,得到扰动状态;当扰动状态对应的扰动动作与最优动作am不同时,停止对输入状态s
ti
的修改。
[0032]
进一步的,所述步骤3的过程如下:
[0033]
扰动μ
t
为t时刻扰动状态s
t’与原始状态s
t
的差,评估扰动量是否在限制以内,以此来决定是否输入攻击后的扰动状态;计算t时刻扰动μt的大小,公式表示如下:
[0034][0035]
其中len(.)计算的是车辆状态集合中为0.5的个数,当μ≤δ时,将扰动状态s
t’输入模型中,否则将原始状态s
t
输入到模型中。
[0036]
进一步的,所述步骤4的过程如下:
[0037]
将扰动大小满足要求的扰动状态s
t’输入到模型中,得到对抗动作,计算前一时刻与此时单交叉口路段车辆等待时间之差,得到奖励r
t
。
[0038]
本发明的技术构思为:基于已由强化学习算法dqn训练好的交通信号灯控制模型,利用jsma攻击的前向导数雅各比矩阵和显著图制作对抗样本,将符合限制的对抗样本输入智能体模型中,最后在sumo上分析单交叉口路段的交通状况,以此检验对抗攻击的效果。
[0039]
与现有技术相比,本发明的有益效果主要表现在:利用jsma算法的显著图思想找到输入状态中最能影响输出的部分,在一定的扰动大小限制内,将其修改即可得到对抗样本;本发明可以在只修改一小部分原始状态的情况下,对最终的信号灯输出动作造成较大的影响,以此高效地影响单交叉口路段的道路交通状况,降低模型的性能。
附图说明
[0040]
图1是基于jsma生成对抗扰动的流程图。
[0041]
图2是单交叉口场景示意图。
[0042]
图3是车辆位置的离散状态示意图。
[0043]
图4是单交叉口车辆等待队列长度对比图。
[0044]
图5是单交叉口车辆等待时间对比图。
具体实施方式
[0045]
以下结合附图对本发明实施例的具体实施方式进行详细说明。应当理解的是,此处所描述的具体实施方式仅用于说明和解释本发明实施例,并不用于限制本发明实施例。
[0046]
需要说明的是,在不冲突的情况下,本发明中的实施例及实施例中的特征可以相互组合。
[0047]
下面将参考附图1-5并结合示例性实施例来详细说明本发明。
[0048]
实施例1
[0049]
步骤1:首先在sumo的单交叉口道路上训练强化学习智能体模型。对环境中所有道路上的交通状态做离散化处理:设道路入口到停车线的距离为l,将道路上的车道k(k=1,2,3,4)等距离划分成c个单元。t时刻车道k上的车辆位置表示为矩阵sk(t),当车辆的头部位于某个离散单元上时,则sk(t)对应位置i(i=1,2,...,c)的值为0.5,否则为-0.5。将四个路口的sk(t)按行排列,即得到要输入到模型中的原始环境状态s
t
。
[0050]
对于本发明中的智能体模型,输入作为交通状况的环境状态,将得到特定的交通信号灯动作。将信号灯相位作为智能体的动作空间a={a1,a2,a3,a4},其中a1为南北方向直行绿灯,a2为南北方向左转绿灯,a3为东西方向直行绿灯,a4为东西方向左转绿灯。设置ai的初始绿灯相位持续时长为m,黄灯相位时长为n。将当前状态s
t
输入到模型中,智能体输出相应的ai(i=1,2,3,4)作为动作,ai的持续时间结束后,智能体继续从环境中采集下一时刻的状态s
t+1
,然后输出相位aj(j=1,2,3,4)。若ai≠aj,ai的绿灯相位结束后执行n时长的黄灯相位,之后再执行aj相位;否则将ai的执行时间延长m时长。将强化学习的奖励r
t
设置为两个动作之间路口车辆总等待时间之差,公式表示如下:
[0051]rt
=w
t-w
t+1
ꢀꢀꢀ
(1)
[0052]
其中w
t
,w
t+1
分别表示t和t+1时刻进入单交叉口所有车辆的等待时间之和。使用dqn作为强化学习模型,初始化后神经网络的输出即为q值。深度神经网络的隐含层使用relu作为激活函数,输出的神经元个数设置为与交通信号灯的动作空间大小相等。公式表示如下:
[0053]
q=h(ws
t
+b)
ꢀꢀꢀ
(2)
[0054]
其中w表示神经网络的权重,s
t
为t时刻网络的输入,b为偏置,h(.)代表relu激活函数。dqn的损失函数表示为:
[0055][0056]
l
t
=(y
t-q(s
t
,ai;θ
′
))2ꢀꢀꢀ
(4)
[0057]
其中γ为学习率,θ和θ
′
分别代表目标网络和估计网络的参数w、b以及w’、b’。随着强化学习智能体的训练,目标网络的参数根据时间步长进行更新,更新方式为每隔时间t从估计网络中直接复制参数到目标网络中,公式表示如下:
[0058]
[0059][0060]
步骤2:在单交叉口路段获取车辆的位置及数量作为状态信息,将其输入到模型中得到相应的交通信号灯动作。基于jsma算法找到需要修改的输入特征,并以此制作对抗样本。具体过程如下:
[0061]
2.1:获取原始的环境状态s
t
,将其输入已经训练好的dqn智能体模型中,选择出使q函数值最大的动作am(m=1,2,3,4),即为此时刻最优的信号灯动作,公式表示如下:
[0062][0063]
其中θ表示训练好的智能体的参数w、b,am表示交通信号灯接下来的动作。
[0064]
2.2:基于jsma攻击算法,沿梯度方向计算神经网络输出对于输入的雅各比矩阵,并表示出基于输入状态s
t
的显著图x,用来描述输入状态中哪些信息对于输出的影响最大。对于输入s
ti
(i=1,2,3,
…
,80)来说,显著图x的公式表示如下:
[0065][0066]
其中表示神经网络输出对于输入s
t
的前向导数。选出使显著图x最大的输入特征s
ti
,修改特征使其为+1,得到扰动状态。当扰动状态对应的扰动动作与最优动作am不同时,停止对输入状态s
ti
的修改。
[0067]
步骤3:扰动μ
t
为t时刻扰动状态s
t’与原始状态s
t
的差,评估扰动量是否在限制以内,以此来决定是否输入攻击后形成的扰动状态。计算t时刻扰动μ
t
的大小,公式表示如下:
[0068][0069]
其中len(.)计算的是车辆状态集合中为0.5的个数,当μ≤δ时,将扰动状态s
t’输入模型中,否则将原始状态s
t
输入到模型中。
[0070]
步骤4:将扰动大小满足要求的扰动状态s
t’输入到模型中,得到对抗动作,计算前一时刻与此时刻单交叉口路段的车辆等待时间之差,得到奖励r
t
。
[0071]
实施例2:实际实验中的数据
[0072]
(1)选取实验数据
[0073]
实验数据由sumo上的单交叉路口中100辆随机生成的车辆产生,其中每辆车的车身长度、初始位置、行驶速度都是相同的。
[0074]
(2)参数确定
[0075]
交通信号灯的绿灯初始持续时长为10秒,黄灯为4秒。从路口到停车线的道路k(k=1,2,3,4)长度为700米,将其划分为长度为7米的100个单元。智能体模型中神经网络的学习率为0.001。扰动阈值δ=20%。
[0076]
(3)实验结果
[0077]
我们在sumo上的单交叉口路段进行实验,基于训练好的dqn强化学习智能体模型,使用基于雅各比显著图(jsma)的单交叉口信号控制的交通状态对抗生成方法,为各时刻输入模型中的车辆数量及位置的状态添加扰动,使得交通信号灯的动作输出发生改变。在有攻击和无攻击的两种情况下进行了对比实验,实验结果如图4,图5所示(在持续攻击情形
下,交通信号灯疏导路口车辆通行的效果降低,导致车辆拥堵越来越严重。但当车辆拥堵到一定程度时,较小的扰动不足以对交通状况继续造成影响,因此扰动会突破设置的阈值,最终导致输入系统的状态变为原始状态。此时车辆已经能够顺利流通,从而使得等待时间和处于等待中的车辆总数大幅下降)。
[0078]
尽管上面已经示出和描述了本发明的实施例,可以理解的是,上述实施例是示例性的,不能理解为对本发明的限制,本领域的普通技术人员在本发明的范围内可以对上述实施例进行变化、修改、替换和变型。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1