一种视频处理方法及装置与流程
本技术涉及视频处理,特别涉及一种视频处理方法及装置。
背景技术:
1、自由视角是一种通过多视角视频系统同步拍摄、存储、传输、处理和生成视频的技术,生成的视频能够满足用户通过交互界面在任意时刻从任意角度观看被拍摄场景的体验需求。
2、目前的多视角视频系统在大场景下多采用以专业级摄像机为采集设备的多相机系统,系统复杂、硬件成本高,但依然面临大场景下的诸多挑战。采集图像时会受到复杂的环境干扰和噪声,雾、雨等复杂的天气,混乱的环境光照,复杂的舞台特效、灯光等影响。导致基于采集的图像进行6自由度自由视点漫游时,出现观看内容的质量不足。因此,目前没有一种可行的针对多视角视频系统采集的图像进行增强处理的方案。
技术实现思路
1、本技术实施例提供一种视频处理方法及装置,用以提供一种可行的多视角视频系统采集的图像进行增强处理的方案。
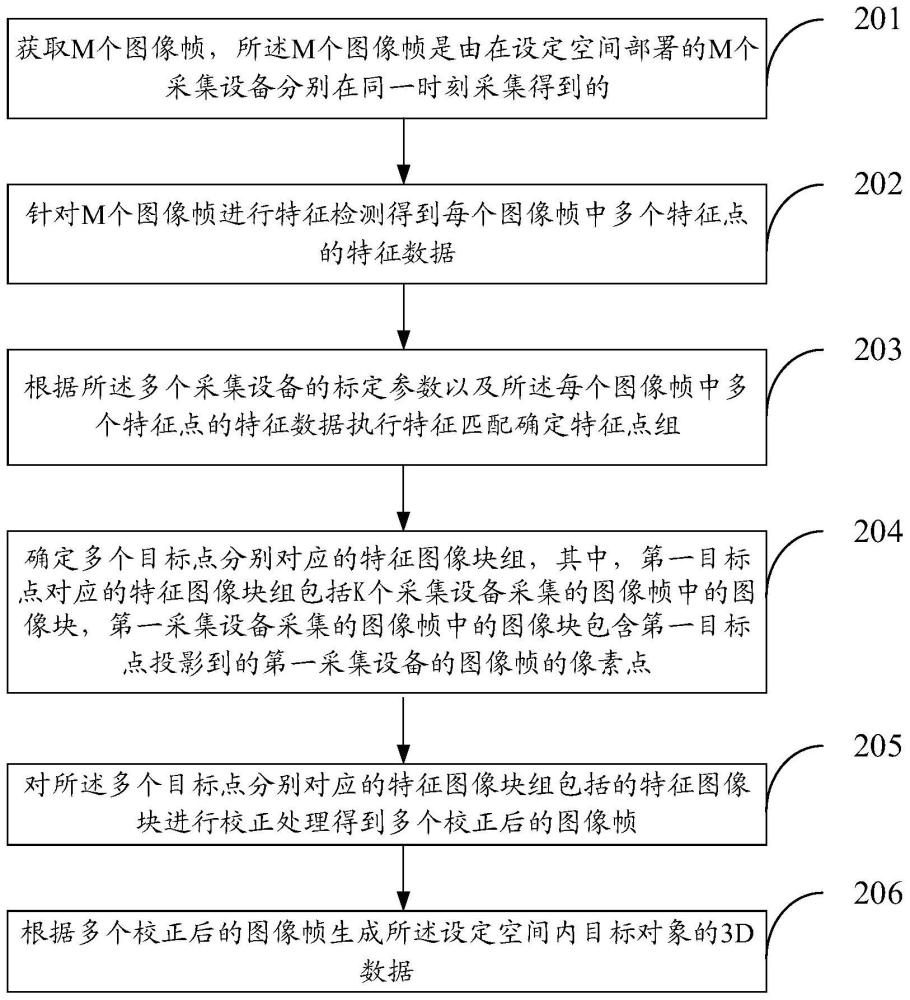
2、第一方面,本技术实施例提供一种视频处理方法,包括:获取m个图像帧,所述m个图像帧是由在设定空间部署的m个采集设备分别在同一时刻采集得到的,m为正整数,所述多个采集设备的视角分别为所述设定空间中不同设定子区域的范围;针对所述m个图像帧进行特征检测得到每个图像帧中多个特征点的特征数据;根据所述多个采集设备的标定参数以及所述每个图像帧中多个特征点的特征数据执行特征匹配确定特征点组;其中,所述特征点组中包括多个目标点,第一目标点对应于k个特征点,k为大于或者等于3的整数,所述第一目标点为所述多个目标点中任一目标点,所述k个特征点的特征数据表征k个采集设备所采集的所述设定空间中所述第一目标点的特征;确定所述多个目标点中每个目标点对应的特征图像块组,其中,所述第一目标点对应的特征图像块组包括所述k个采集设备采集的图像帧中的图像块,第一采集设备采集的图像帧中的图像块包含所述第一目标点投影到的第一采集设备的图像帧的像素点,所述第一采集设备为所述k个采集设备中任一采集设备;对所述多个目标点中每个目标点对应的特征图像块组包括的特征图像块进行校正处理得到多个校正后的图像帧;其中,第一特征图像块组中除锚定特征图像块以外的特征图像块的校正处理以第一特征图像块组中的锚定特征图像块为基准;所述第一特征图像块组为所述多个目标点分别对应的特征图像块组中任一特征图像块组,所述锚定特征图像块为所述第一特征图像块组的增益系数最大的特征图像块,特征图像块的增益系数用于表征所述特征图像块的暗通道强度的深度敏感性;根据多个校正后的图像帧生成所述设定空间内目标对象的3d数据。
3、本技术实施例中,通过以锚定特征图像块为基准为其它特征图像块进行校正,而通过深度敏感性来确定质量最好的锚定图像块,来实现对其它图像块校正,提高其它图像块的质量,并且能够保证各个采集设备采集的图像经过校正后保持一致性。
4、在一种可能的设计中,所述校正处理包括:噪声抑制、瑕疵去除、纹理增强、光照校正以及对比度调整中的一项或者多项。
5、在一种可能的设计中,所述特征图像块的增益系数满足如下公式所示的条件:
6、
7、
8、其中,cog表示所述特征图像块的增益系数,x_total表示所述特征图像块包括的像素数量,所述ic(x)表示像素x的强度,idc(x)表示像素x的暗通道强度。
9、上述设计中,通过像素的强度以及暗通道强度来确定增益系数,增益系数越大表达的图像的质量更优,以保证锚定特征图的质量更优。
10、在一种可能的设计中,对所述多个目标点中每个目标点对应的特征图像块组包括的特征图像块进行校正,包括:
11、确定所述多个目标点中每个目标点对应的特征图像块组包括的特征图像块的增益系数;
12、将所述多个目标点中每个目标点对应的特征图像块组包括的特征图像块以及每个图像特征块的增益系数作为第一神经网络模型的输入,通过所述第一神经网络模型对所述多个目标点中每个目标点对应的特征图像块组包括的特征图像块进行校正。
13、在一种可能的设计中,所述第一神经网络模型基于训练样本集进行多次迭代训练得到的;所述训练样本集包括n个样本数据以及n个真值数据,n个样本数据与n个真值数据一一对应,每个样本数据包括m个干扰图像,每个真值数据包括m个原始图像,第一样本数据包括的m个干扰图像与第一真值数据包括的m个原始图像一一对应,第一样本数据与第一真值数据对应,每个原始图像对应的干扰图像是在所述原始图像的基础上增加干扰得到的,第一真值数据包括的m个原始图像分别对应不同的视角,第一样本数据为所述n个样本数据中的任一样本数据。
14、在一种可能的设计中,对所述第一神经网络模型的第i次迭代训练,包括:
15、分别通过第一神经网络模型对第i次迭代训练使用的l个样本数据中每个样本数据中的特征图像块进行校正处理得到l个校正后的样本数据,l为正整数,l个校正后的样本数据中每个校正后的样本数据包括m个校正后的干扰图像;
16、确定每个校正后的样本数据中非锚定视角的增益系数,以及校正后的样本数据对应的真值数据中锚定视角的原始图像的增益系数确定互相关系数;
17、其中,校正后的干扰图像的增益系数根据校正后的干扰图像包括的多个特征图像块的增益系数确定,锚定视角的原始图像为包括锚定特征图像块数量最多的原始图像;锚定视角的增益系数为锚定视角的图像包括的特征图像块的增益系数平均值,非锚定视角的增益系数为非锚定视角的多个图像包括的特征图像块的增益系数的平均值;
18、根据所述互相关系数调整所述第一神经网络模型的网络参数。
19、上述设计中,通过用于表达图像之间的相关性的互相关系数来确定损失值,基于该确定的损失值调整网络参数,能够调整第一神经网络模型的输出的各个视角的增强图像的一致性。
20、在一种可能的设计中,所述互相关系数满足如下公式所示的条件:
21、
22、其中,mmj表示l个校正后的样本数据中第j个样本数据中m-1个非锚定视角的校正后的干扰图像中的特征图像块的增益系数平均值,amj表示l个校正后的样本数据中第j个样本数据对应的真值数据中锚定视角的原始图像中的特征图像块的增益系数平均值。
23、在一种可能的设计中,根据多个校正后的图像帧生成所述设定空间内目标对象的3d数据,包括:
24、根据多个校正后的图像帧中每个图像帧中包括的特征图像块的属性值对所述每个图像帧中的多个设定像素点的属性值进行调整,所述多个设定像素点为所述每个图像帧包括的特征图像块未覆盖的像素点;
25、根据经过属性值调整后的图像帧生成所述设定空间内目标对象的3d数据。
26、在一种可能的设计中,所述目标对象包括目标人物,所述方法还包括:
27、将所述目标对象的3d数据投影到所述多个采集设备的图像空间,以获得所述目标对象的设定部位在所述多个采集设备中至少两个采集设备的图像空间中的第一设定部位数据,所述设定部位包括面部和/或人体;获取正则空间的设定部位模板;将所述至少两个采集设备的图像空间的第一设定部位数据融合到所述设定部位模板得到所述目标人物的设定部位模型;根据所述目标人物的设定部位模型获得所述目标人物分别在所述至少两个采集设备的图像空间的第二设定部位数据;根据所述目标人物分别在所述至少两个采集设备的图像空间的第二设定部位数据更新所述目标对象的3d表达数据中的所述目标人物的设定部位数据。
28、需要说明的是,设定部位包括面部时,设定部位模板为面部模板。设定部位包括人体时,设定部位模板包括人体模板。设定部位包括面部和人体时,设定部位模板包括面部模板和人体模板。
29、在一种可能的设计中,根据所述目标人物的设定部位模型获得所述目标人物分别在所述至少两个采集设备的图像空间的第二设定部位数据,包括:对所述设定部位模型进行增强处理得到增强后的目标对象的设定部位模型;将所述增强后的目标对象的设定部位模型投影到所述至少两个采集设备的图像空间,以获得所述目标人物分别在所述至少两个采集设备的图像空间的第二设定部位数据。
30、一些场景中,自由视角采集系统所在的物理空间范围较大,比如赛场、舞台灯较大空间区域场景,导致采集设备采集的目标人物在图像中的占比较小,导致图像中目标人物的采样分辨率和纹理质量不足,存在较大差距。本技术通过面部或者人体模板对原有的数据进行融合,然后再对融合后的进行处理,可以提高目标人物的采样分辨率和纹理质量。
31、在一种可能的设计中,根据所述目标人物分别在所述至少两个采集设备的图像空间的第二设定部位数据更新所述目标对象的3d表达数据中的所述目标人物的设定部位数据,包括:
32、将所述目标人物在所述第一采集设备的图像空间的第二设定部位数据与所述第一采集设备的图像空间中除所述目标人物的设定部位数据以外的数据进行融合处理,所述第一采集设备为所述至少两个采集设备中的任一采集设备,以得到所述至少两个采集设备的图像空间的融合处理后的图像空间数据;
33、根据所述至少两个采集设备的图像空间的融合处理后的图像空间数据对所述目标对象的3d数据进行更新。
34、第二方面,本技术实施例提供一种视频处理装置,包括:
35、获取单元,用于获取m个图像帧,所述m个图像帧是由在设定空间部署的m个采集设备分别在同一时刻采集得到的,m为正整数,所述多个采集设备的视角分别为所述设定空间中不同设定子区域的范围;
36、处理单元,用于执行如下:
37、针对所述m个图像帧进行特征检测得到每个图像帧中多个特征点的特征数据;根据所述多个采集设备的标定参数以及所述每个图像帧中多个特征点的特征数据执行特征匹配确定特征点组;其中,所述特征点组中包括多个目标点,第一目标点对应于k个特征点,k为大于或者等于3的整数,所述第一目标点为所述多个目标点中任一目标点,所述k个特征点的特征数据表征k个采集设备所采集的所述设定空间中所述第一目标点的特征;
38、确定所述多个目标点中每个目标点对应的特征图像块组,其中,所述第一目标点对应的特征图像块组包括所述k个采集设备采集的图像帧中的图像块,第一采集设备采集的图像帧中的图像块包含所述第一目标点投影到的第一采集设备的图像帧的像素点,所述第一采集设备为所述k个采集设备中任一采集设备;
39、对所述多个目标点中每个目标点对应的特征图像块组包括的特征图像块进行校正处理得到多个校正后的图像帧;
40、其中,第一特征图像块组中除锚定特征图像块以外的特征图像块的校正处理以第一特征图像块组中的锚定特征图像块为基准;所述第一特征图像块组为所述多个目标点分别对应的特征图像块组中任一特征图像块组,所述锚定特征图像块为所述第一特征图像块组的增益系数最大的特征图像块,特征图像块的增益系数用于表征所述特征图像块的暗通道强度的深度敏感性;
41、根据多个校正后的图像帧生成所述设定空间内目标对象的3d数据。
42、在一种可能的设计中,所述校正处理包括:噪声抑制、瑕疵去除、纹理增强、光照校正以及对比度调整中的一项或者多项。
43、在一种可能的设计中,所述特征图像块的增益系数满足如下公式所示的条件:
44、
45、
46、其中,cog表示所述特征图像块的增益系数,x_total表示所述特征图像块包括的像素数量,所述ic(x)表示像素x的强度,idc(x)表示像素x的暗通道强度。
47、在一种可能的设计中,所述处理单元,具体用于:
48、确定所述多个目标点中每个目标点对应的特征图像块组包括的特征图像块的增益系数;
49、将所述多个目标点中每个目标点对应的特征图像块组包括的特征图像块以及每个图像特征块的增益系数作为第一神经网络模型的输入,通过所述第一神经网络模型对所述多个目标点分别对应的特征图像块组包括的特征图像块进行校正。
50、在一种可能的设计中,所述第一神经网络模型基于训练样本集进行多次迭代训练得到的;所述训练样本集包括n个样本数据以及n个真值数据,n个样本数据与n个真值数据一一对应,每个样本数据包括m个干扰图像,每个真值数据包括m个原始图像,第一样本数据包括的m个干扰图像与第一真值数据包括的m个原始图像一一对应,第一样本数据与第一真值数据对应,每个原始图像对应的干扰图像是在所述原始图像的基础上增加干扰得到的,第一真值数据包括的m个原始图像分别对应不同的视角,第一样本数据为所述n个样本数据中的任一样本数据。
51、在一种可能的设计中,所述处理单元,还用于:
52、分别通过第一神经网络模型对第i次迭代训练使用的l个样本数据中每个样本数据中的特征图像块进行校正处理得到l个校正后的样本数据,l为正整数,l个校正后的样本数据中每个校正后的样本数据包括m个校正后的干扰图像;
53、确定每个校正后的样本数据中非锚定视角的增益系数,以及校正后的样本数据对应的真值数据中锚定视角的原始图像的增益系数确定互相关系数;
54、其中,校正后的干扰图像的增益系数根据校正后的干扰图像包括的多个特征图像块的增益系数确定,锚定视角的原始图像为包括锚定特征图像块数量最多的原始图像;锚定视角的增益系数为锚定视角的图像包括的特征图像块的增益系数平均值,非锚定视角的增益系数为非锚定视角的多个图像包括的特征图像块的增益系数的平均值;
55、根据所述互相关系数调整所述第一神经网络模型的网络参数。
56、在一种可能的设计中,所述第一互相关系数满足如下公式所示的条件:
57、
58、其中,mmj表示l个校正后的样本数据中第j个样本数据中m-1个非锚定视角的校正后的干扰图像中的特征图像块的增益系数平均值,amj表示l个校正后的样本数据中第j个样本数据对应的真值数据中锚定视角的原始图像中的特征图像块的增益系数平均值。
59、在一种可能的设计中,所述处理单元,具体用于:
60、根据多个校正后的图像帧中每个图像帧中包括的特征图像块的属性值对所述每个图像帧中的多个设定像素点的属性值进行调整,所述多个设定像素点为所述每个图像帧包括的特征图像块未覆盖的像素点;
61、根据经过属性值调整后的图像帧生成所述设定空间内目标对象的3d数据。
62、在一种可能的设计中,所述目标对象包括目标人物,所述处理单元,还用于:
63、将所述目标对象的3d数据投影到所述多个采集设备的图像空间,以获得所述目标对象的设定部位在所述多个采集设备中至少两个采集设备的图像空间中的第一设定部位数据,所述设定部位包括面部和/或人体;
64、获取正则空间的设定部位模板;
65、将所述至少两个采集设备的图像空间的第一设定部位数据融合到所述设定部位模板得到所述目标人物的设定部位模型;
66、根据所述目标人物的设定部位模型获得所述目标人物分别在所述至少两个采集设备的图像空间的第二设定部位数据;
67、根据所述目标人物分别在所述至少两个采集设备的图像空间的第二设定部位数据更新所述目标对象的3d表达数据中的所述目标人物的设定部位数据。
68、在一种可能的设计中,所述处理单元,在根据所述目标人物的设定部位模型获得所述目标人物分别在所述至少两个采集设备的图像空间的第二设定部位数据时,具体用于:
69、对所述设定部位模型进行增强处理得到增强后的目标对象的设定部位模型;
70、将所述增强后的目标对象的设定部位模型投影到所述至少两个采集设备的图像空间,以获得所述目标人物分别在所述至少两个采集设备的图像空间的第二设定部位数据。
71、在一种可能的设计中,所述处理单元,在根据所述目标人物分别在所述至少两个采集设备的图像空间的第二设定部位数据更新所述目标对象的3d表达数据中的所述目标人物的设定部位数据时,具体用于:
72、将所述目标人物在所述第一采集设备的图像空间的第二设定部位数据与所述第一采集设备的图像空间中除所述目标人物的设定部位数据以外的数据进行融合处理,所述第一采集设备为所述至少两个采集设备中的任一采集设备,以得到所述至少两个采集设备的图像空间的融合处理后的图像空间数据;
73、根据所述至少两个采集设备的图像空间的融合处理后的图像空间数据对所述目标对象的3d数据进行更新。
74、第三方面,本技术实施例提供一种视频处理装置,包括存储器、处理器。所述存储器,用于存储程序或指令;所述处理器,用于调用所述程序或指令,以执行第一方面或者第一方面的任一设计所述的方法。
75、第四方面,本技术提供一种计算机可读存储介质,计算机可读存储介质中存储有计算机程序或指令,当计算机程序或指令被终端设备执行时,使得该处理器执行上述第一方面或第一方面的任意可能的设计中的方法。
76、第五方面,本技术提供一种计算机程序产品,该计算机程序产品包括计算机程序或指令,当该计算机程序或指令被处理器执行时,实现上述第一方面或第一方面的任意可能的实现方式中的方法。
77、上述第二方面至第五方面中任一方面可以达到的技术效果可以参照上述第一方面或者第二方面中有益效果的描述,此处不再重复赘述。
78、本技术在上述各方面提供的实现的基础上,还可以进行进一步组合以提供更多实现。
- 还没有人留言评论。精彩留言会获得点赞!