一种基于报文长度特性的APP流量分类算法的制作方法
本发明属于网络,具体涉及与app相关的网络报文流量分类。
背景技术:
1、随着app规模和移动用户数量的不断增加,如何在网络流量中对app进行准确高效地识别也成为了热点问题。app流量分类无论对专业的流量分析还是网络安全都起到了重要的作用,通过app流量分类能够洞悉整个企业内网或家中设备的运行情况,可以针对具体需求做用户行为的准确管控,在一定程度上保证业务流的高效运行;其次对恶意app进行精准识别可以及时拦截攻击,保证网络的安全性。
2、传统的app流量分类方法包括了基于端口号的识别方案和基于dpi(deep packetinspection)的app流量识别方案等。文献”m.finsterbusch,c.richter,e.rocha,j.-a.muller and k.hanssgen,"a survey of payload-based traffic classificationapproaches,"in ieee communications surveys&tutorials,vol.16,no.2,pp.1135-1156,second quarter 2014,doi:10.1109/surv.2013.100613.00161.”总结了基于dpi的app流量识别方案,对dpi模块进行了分析。上述方法通过匹配预定义的规则进行分类,局限性较大,已不适用于当今复杂的网络环境。
3、近年来,研究人员开始将机器学习算法应用于app流量分类。基于机器学习算法的app流量分类通过提取数据包中网络流量的相关特征,利用不同app之间的网络行为差异,构建流量分类模型。文献”v.f.taylor,r.spolaor,m.conti and i.martinovic,"robustsmartphone app identification via encrypted network traffic analysis,"in ieeetransactions on information forensics and security,vol.13,no.1,pp.63-78,jan.2018,doi:10.1109/tifs.2017.2737970.”通过提取网络流量的统计特性,归一化后输入机器学习分类器,分类结果也优于传统识别方法。而流量的统计特性一般都会涉及到报文长度、时间戳和包的数量等数值,计算每秒传输的报文数量和每秒传输的字节数等特征作为分类器的输入,首先该特征容易受到网络环境的影响,不同网络环境下报文的传输速率也会不同,其次一般app流量采用的数据集均在良好的网络状况下抓取,未考虑到重传、报文乱序的情况,这些干扰项对于一些网络服务是无用甚至是有害的,会影响对于网络流的精确识别。最终,上文所提到的统计特性均需要等到一条流结束后才能提取,意味着不能保证app识别的实时性。
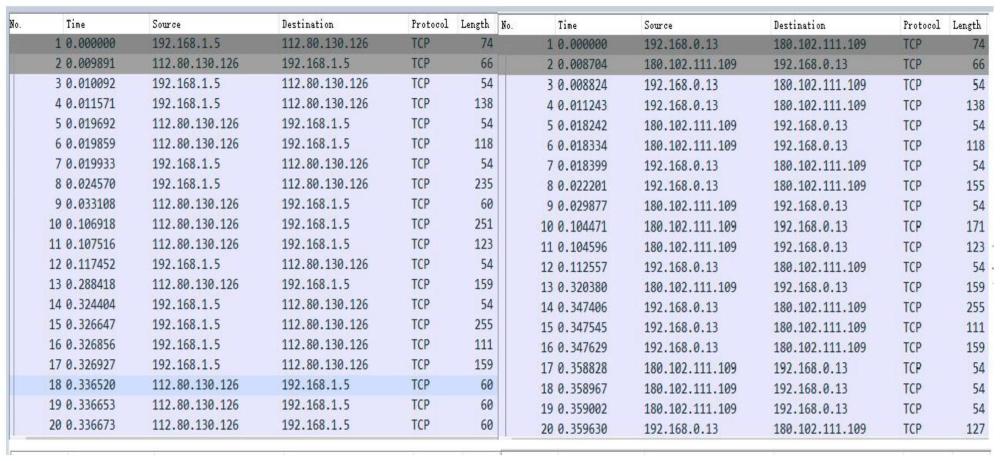
4、图1和图2展示了不同设备上使用同一app从开始建立tcp连接到数据传输阶段的报文长度,由图可见同一app在开始阶段的报文长度存在一定的规律性。
5、综上所述,本发明旨在研究从一个app开始使用时,对双向建立连接与传输数据阶段的报文长度特征生成特征向量,在app开始使用时就能够完成准确识别。
技术实现思路
1、本发明提出了一种基于报文长度特性的app流量分类算法,包括如下步骤:
2、步骤1:抓取使用app产生的网络流量,去除非主要ip子网对应的数据,根据app名称给网络流生成标签集合y;
3、步骤2:对每条网络流,去除重传和乱序的报文后,按顺序提取所有前2n个报文的长度(若某方向报文数量不足n,仍然只提取所有前2n个报文的长度),不足补零,按流的方向(接收或发送)分别提取前n个报文的长度(n的值无需设置过大,一般设置在10左右即可,即可在流开始的时候完成特征提取),不足补零,计算统计特性后构成该流的特征向量集合x;
4、步骤3:将x和y输入机器学习分类器进行训练,对分类器进行性能评估,优化分类器;
5、步骤4:对给定网络流,通过步骤2的处理后输入分类器得到识别结果。
6、进一步地,步骤1、步骤2和步骤4中所定义的网络流均由经过四元组{源ip地址,目的ip地址,源端口,目的端口}分流后的tcp报文组成;
7、进一步地,步骤2中所述的统计特性计算方法如下,计算提取的前2n个报文的长度的最大值、最小值、均值、方差和标准差得到特征向量组a1,按流的方向(接收或发送)分别计算报文长度的最大值、最小值、均值、方差和标准差得到特征组{a2,a3},{a1,a2,a3}合并得到该流的特征向量集合x;
8、进一步地,步骤3中所述的分类器,采用多模型训练,算法均为常用的有监督学习算法;
9、进一步地,步骤4中的决策过程,将给定网络流通过步骤2所述的预处理后输入步骤3中训练好的分类器组,若要输出分类结果,要求至少有50%或者以上的分类器都输出了同一类别,否则定义为新的类别,将该网络流判定为噪声。
技术特征:
1.一种基于报文长度特性的app流量分类算法,包括如下步骤:
2.如权利要求1所述的基于报文长度特性的app流量分类算法,步骤1、步骤2和步骤4中所定义的网络流均由经过四元组{源ip地址,目的ip地址,源端口,目的端口}分流后的tcp报文组成。
3.如权利要求1所述的基于报文长度特性的app流量分类算法,其特征在于,步骤2中所述的统计特性计算方法如下,计算提取的前2n个报文的长度的最大值、最小值、均值、方差和标准差得到特征向量组a1,按流的方向(接收或发送)分别计算报文长度的最大值、最小值、均值、方差和标准差得到特征组{a2,a3},{a1,a2,a3}合并得到该流的特征向量集合x。
4.如权利要求1所述的基于报文长度特性的app流量分类算法,其特征在于,步骤3中所述的分类器,采用多模型训练,算法均为常用的有监督学习算法。
5.如权利要求1所述的基于报文长度特性的app流量分类算法,其特征在于,步骤4中的决策过程,将给定网络流通过步骤2所述的预处理后输入步骤3中训练好的分类器组,若要输出分类结果,要求至少有50%或者以上的分类器都输出了同一类别,否则定义为新的类别,将该网络流判定为噪声。
技术总结
本发明提出一种基于报文长度特性的APP流量分类算法,对网络流中的流量分流后,去除重传、乱序的报文以减小网络环境对训练数据和实际环境下测试数据的影响,提取报文长度特征后输入多个分类器进行训练,采用多模型决策以过滤噪声。本发明与传统的规则匹配法相比,通用性强;与常用的基于网络流统计特性的APP流量分类算法相比,实现简单且实时性强,无需等待一条网络流结束即可完成精确识别。同时,本发明采用多模型的决策法能够很好地过滤掉网络中的噪声,对于暂不支持识别或未参与训练的APP流量,可以给出特定的分类结果,将网络流判定为噪声。
技术研发人员:请求不公布姓名
受保护的技术使用者:海优(南京)科技有限公司
技术研发日:
技术公布日:2024/5/20
- 还没有人留言评论。精彩留言会获得点赞!