一种基于深度强化学习的无人机多跳SPMA网络智能退避方法
本发明属于移动自组网领域。
背景技术:
1、基于统计优先级的多址接入(spma)协议,如航空自组织网络(aanet)或美国军事战术目标网络技术(ttnt)。与载波侦听多址(csma)、时分多址(tdma)等传统的媒体接入控制(mac)协议相比,基于多优先级业务的spma可以通过对不同优先级的业务设置不同的发送阈值,保证高优先级业务的低延迟和高可靠性。因此,spma在战术网络通信领域得到了越来越多的关注。
2、在spma中,通过优先级对数据包进行分类,每个优先级队列的阈值通常设置为一个固定的值,使得高优先级的流量占用大量带宽资源以满足其qos(quality of service)要求,与之相应的低优先级流量会损失一定的宽带资源。
3、基于信道占用率统计的spma的回退条件与传统的mac协议有所不同。传统的回退算法,如二进制指数回退(ber)和乘法递增线性下降(mild)算法,是基于实际碰撞设计的,因此传统的回退算法不适合spma。
4、另外,现有的spma退避算法都是在全通网络的条件下进行计算的,没有考虑多跳传输网络下存在数据包转发的情况。相比于全通传输网络下,多跳传输网络的数据包需经过多次转发才能送达目的节点,转发数据包的退避时间应尽量缩短来保证数据包从源节点到达目的节点的时延,而现有的spma退避算法并未将转发数据包比例作为退避时长计算的参数。因此基于全通网络下的spma退避算法不再适用于多跳的网络环境。
5、本发明研究多跳传输网络下退避时间的设置,使用了dqn算法根据信道占用率及其历史值和队列中转发数据包的数目来生成更加合理的退避时长,保证退避后各节点发送数据包的成功率,尤其保证数据包转发的成功率和时延,提升了网络吞吐量。
技术实现思路
1、本发明旨在至少在一定程度上解决相关技术中的技术问题之一。
2、为此,本发明的目的在于提出一种基于深度强化学习的无人机多跳spma网络智能退避方法,用于提升多跳spma数据包的发送成功率,降低数据包传输时延和提高网络总吞吐量。
3、为达上述目的,本发明第一方面实施例提出了一种基于深度强化学习的无人机多跳spma网络智能退避方法,包括:
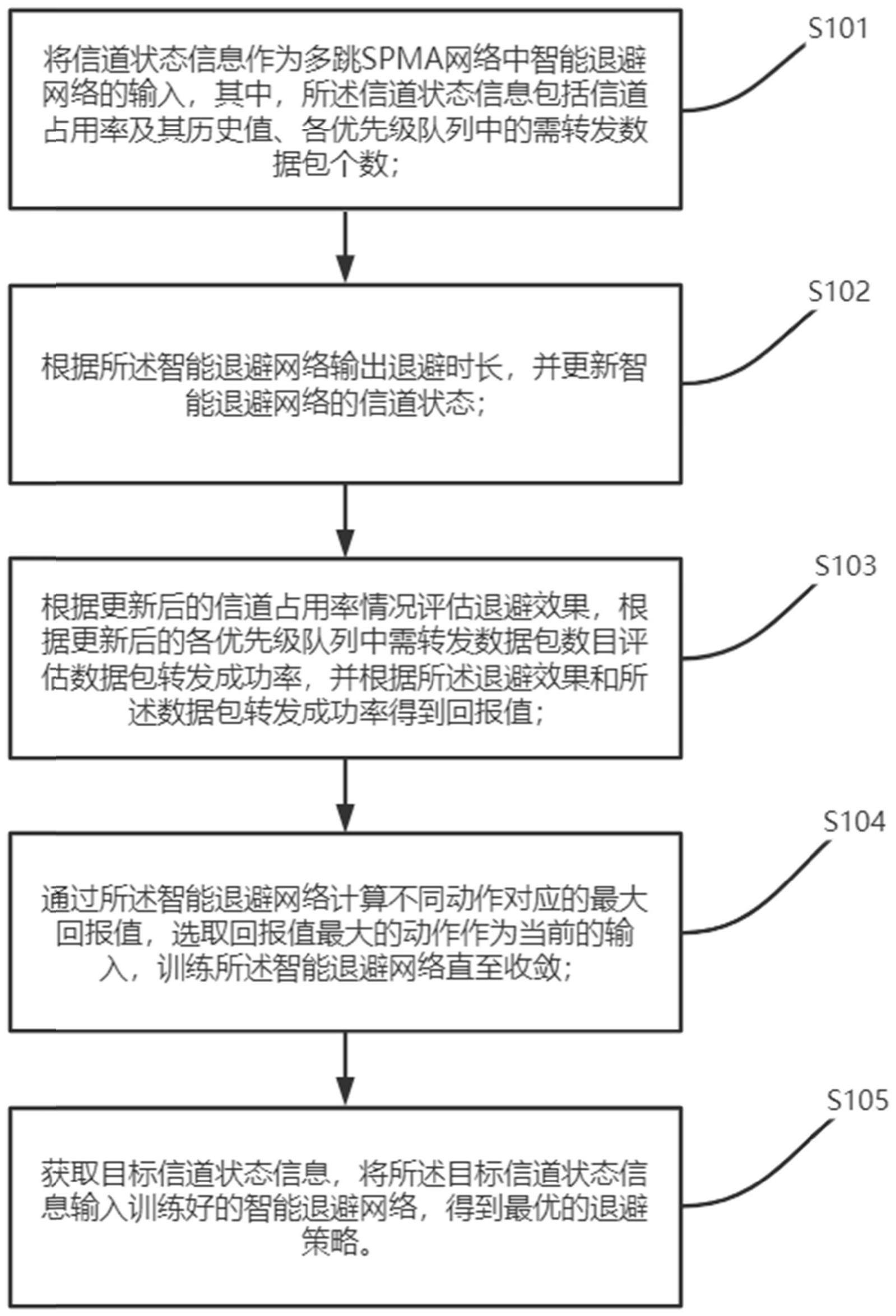
4、将信道状态信息作为多跳spma网络中智能退避网络的输入,其中,所述信道状态信息包括信道占用率及其历史值、各优先级队列中的需转发数据包个数;
5、根据所述智能退避网络输出退避时长,并更新智能退避网络的信道状态;
6、根据更新后的信道占用率情况评估退避效果,根据更新后的各优先级队列中需转发数据包数目评估数据包转发成功率,并根据所述退避效果和所述数据包转发成功率得到回报值;
7、通过所述智能退避网络计算不同动作对应的最大回报值,选取回报值最大的动作作为当前的输入,训练所述智能退避网络直至收敛;
8、获取目标信道状态信息,将所述目标信道状态信息输入训练好的智能退避网络,得到最优的退避策略。
9、另外,根据本发明上述实施例的一种基于深度强化学习的无人机多跳spma网络智能退避方法还可以具有以下附加的技术特征:
10、进一步地,在本发明的一个实施例中,所述将信道状态信息作为多跳spma网络中智能退避网络的输入,包括:
11、通过智能退避网络将发送节点先前若干个时隙的信道占用率和各优先级队列中的需转发数据包个数作为所述智能退避网络的dqn模型的输入,输入状态为st={ct,ct-1,...,ct-5,k0,k1,…,km-1},其中,t为当前时刻,t-j为当前时刻的前j个时隙;ct为t时刻的信道占用率;kj为j优先级数队列中需转发的数据包的数目。
12、进一步地,在本发明的一个实施例中,所述根据所述智能退避网络输出退避时长,并更新智能退避网络的信道状态,包括:
13、通过所述智能退避网络与环境交互以获得状态st={ct,ct-1,...,ct-5,k0,k1,…,km-1},然后采取动作at∈{0,1,2,…,m-1}来生成退避时间,m表示动作的数量,退避时间表达式如下:
14、
15、其中,t是一个时隙的时间长度。
16、进一步地,在本发明的一个实施例中,所述智能退避网络的奖励函数定义为:
17、
18、其中,c为退避开始时优先级队列中所有数据包的数目;δn为退避前后转发数据包的数目变化;b表示退避之后数据包是否可以发送,1表示可以发送,0表示不可以发送;t表示退避完成时刻;ts表示退避开始时刻;tth表示获得上限奖励的退避时间阈值;ρ为衰减系数。
19、进一步地,在本发明的一个实施例中,所述回报值的更新公式定义为:其中q(st,at)是在给定状态st下执行动作at所获取的q值,即回报值;α是学习率;rt是t时刻的回报;γ是衰减因子;表示st状态下执行动作之后所能到达的下一状态的最大q值;所述dqn模型选择当前状态q值最大的动作作为输出,公式为
20、为达上述目的,本发明第二方面实施例提出了一种深度强化学习的无人机多跳spma网络智能退避装置,包括以下模块:
21、输入模块,用于将信道状态信息作为多跳spma网络中智能退避网络的输入,其中,所述信道状态信息包括信道占用率及其历史值、各优先级队列中的需转发数据包个数;
22、更新模块,用于根据所述智能退避网络输出退避时长,并更新智能退避网络的信道状态;
23、评估模块,用于根据更新后的信道占用率情况评估退避效果,根据更新后的各优先级队列中需转发数据包数目评估数据包转发成功率,并根据所述退避效果和所述数据包转发成功率得到回报值;
24、训练模块,用于通过所述智能退避网络计算不同动作对应的最大回报值,选取回报值最大的动作作为当前的输入,训练所述智能退避网络直至收敛;
25、生成模块,用于获取目标信道状态信息,将所述目标信道状态信息输入训练好的智能退避网络,得到最优的退避策略。
26、进一步地,在本发明的一个实施例中,所述输入模块,还用于:
27、通过智能退避网络将发送节点先前若干个时隙的信道占用率和各优先级队列中的需转发数据包个数作为所述智能退避网络的dqn模型的输入,输入状态为st={ct,ct-1,...,ct-5,k0,k1,…,km-1},其中,t为当前时刻,t-j为当前时刻的前j个时隙;ct为t时刻的信道占用率;kj为j优先级数队列中需转发的数据包的数目。
28、进一步地,在本发明的一个实施例中,所述更新模块,还用于:
29、通过所述智能退避网络与环境交互以获得状态st={ct,ct-1,...,ct-5,k0,k1,…,km-1},然后采取动作at∈{0,1,2,…,m-1}来生成退避时间,m表示动作的数量,退避时间表达式如下:
30、
31、其中,t是一个时隙的时间长度。
32、为达上述目的,本发明第三方面实施例提出了一种计算机设备,其特征在于,包括存储器、处理器及存储在所述存储器上并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时,实现如上所述的一种基于深度强化学习的无人机多跳spma网络智能退避方法。
33、为达上述目的,本发明第四方面实施例提出了一种计算机可读存储介质,其上存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现如上所述的一种基于深度强化学习的无人机多跳spma网络智能退避方法。
34、本发明实施例提出的多跳传输网络下无人机统计优先级多址接入(spma)中的智能退避方法,在多跳传输存在大量转发数据包时,spma在信道占用率高于优先级阈值时刻进入退避阶段,利用深度强化学习(deep reinforcement learning,drl)中的dqn(deep q-network)算法来指导节点产生退避时长,从而提升多跳spma数据包的发送成功率,降低数据包传输时延和提高网络总吞吐量。
- 还没有人留言评论。精彩留言会获得点赞!