一种自适应麦克风阵列分离增强方法及系统与流程
1.本发明涉及阵列麦克风技术领域,具体涉及一种自适应麦克风阵列分离增强方法及系统。
背景技术:
2.目前,麦克风阵列技术在语音会话场景中被广泛应用,通常应用角度定位、语音增强和语音分离等阵列算法来对目标对话方向上的语音进行增强,以提高录音信噪比和语音识别准确率。
3.被麦克风信号拾取的语音信号增强方法一般使用阵列角度定位确定目标方向角度,再利用波束形成方法提高该角度下的信噪比,然而,实际使用的场景中,通常很难保持说话人始终保持在固定方向上,且一句对话中说话人很有可能会改变位置。同时,在进行单通道分离应用时,经常会因为复杂场景导致分离到模糊方向的语音。
技术实现要素:
4.本发明提供一种自适应麦克风阵列分离增强方法,采用cgmm自适应麦克风阵列算法,不仅能够在软件上完成增强的任务,同时设计了智能电子产品,实现了各类对话场景中增强目标对话的功能。
5.为了达到上述目的,本发明提供如下技术方案:一种自适应麦克风阵列分离增强方法,包括如下方案:
6.步骤一、多通道混合信号;通过全指向性麦克风组成的阵列及其电子器件组成的采集模块采集音频,并通过模拟数字转换器转换为m路时间为t的数字信号;
7.步骤二、分离和定位网络;通过空间协方差矩阵scms混合估计每个源的时频域的tf掩码和doas;
8.步骤三、深度贝叶斯源分离;利用多通道混合信号训练分离定位网络,并在统一的框架下解决了频率排列模糊问题。
9.优选的,所述步骤一中,还包括对两维数字信号进行fft快速傅里叶变换,变换为时频域信号,频域维度定义为f。
10.优选的,所述步骤二中目标函数被导出为具有tf掩码和doas作为潜变量的cgmm的证据下限elbo。
11.优选的,所述步骤三中训练基于潜在lda狄利克雷分布模型,该模型将源的tf掩码和doas作为潜在变量,目标函数是空间模型的elbo,由似然函数的期望和网络输出与其先验分布之间的kl散度组成。
12.优选的,联合估计潜在声源的tf掩码和doas,可观测的多通道频谱图xtf表示为k个声源频谱图stfk的和,即:
[0013][0014]
其中ztfk∈{0,1}是一个tf掩码,表示哪个声源在每个tf bin上相关,wkd∈{0,1}是一个doa变量,将声源k分配给一个doa候选d∈{1,
…
,d},afd是方向导向向量。
[0015]
优选的,elbo最大化对应于变分分布和真实后验分布之间的kl散度的最小化;elbo更新方法为:先预测每个混合录音的tf掩模和doas,再更新模型参数,最后利用随机梯度下降sgd方法计算并更新网络参数。
[0016]
优选的,训练好的网络通过网络输出初始化tf掩码来提高多通道em算法的性能,用于求解cgmm的期望最大化算法em交替迭代后续的e步和m步;e步更新tf掩码ztfk和doas wkd,使elbo l最大化;m步使用更新参数。
[0017]
优选的,利用分离网络gtfk的输出对tf掩码ztfk进行初始化,即:
[0018][0019]
优选的,一种自适应麦克风阵列分离增强系统,用于自适应麦克风阵列分离增强方法,其特征在于,包括:多通道会话信号采集器、多通道非监督训练模块和语音增强;所述多通道会话信号采集器、多通道非监督训练得到的分离语音和单通道增强,通过语音增强则可以将杂音完全去除成为正常单人说话语音。
[0020]
本发明有益效果为:不依赖角度定位,本发明进行语音增强只使用位置信息进行辅助,对话位置发生变化不会影响增强效果,因此解决了多说话人的场景中方位变动的问题;还有效利用多通道相关性,使用多通道自适应混合模型信息进行分离更加有效精确,解决多说话人同时说话的场景,丰富对话场景内容。解决了单通道分离之后出现的排列模糊性,不受噪声混响环境影响,能够有效增强复杂场景中的语音。
附图说明
[0021]
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
[0022]
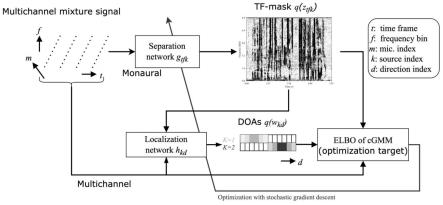
图1为本发明多通道非监督训练流程示意图;
[0023]
图2为本发明增强系统架构示意图。
具体实施方式
[0024]
下面将结合本发明的附图,对本发明的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0025]
传统的神经分离方法需要大量的监督数据才能获得良好的性能。尽管基于空间信
息的多通道方法可以在没有这些训练数据的情况下工作,但它们通常对参数初始化非常敏感,并且在源彼此靠近时降级。
[0026]
根据图1、图2所示,本发明提供一种自适应麦克风阵列分离增强方法,包括如下方案:
[0027]
步骤一、多通道混合信号(multichannel mixture signal):
[0028]
本发明中的混合信号为多通道麦克风语音时频域信号,首先使用各类一致性较好的全指向性麦克风组成的阵列及其电子器件组成的采集模块获得,经由模拟数字转换器转换为m路时间为t的数字信号。接着对两维数字信号进行fft(快速傅里叶变换)变换为时频域信号(本发明将频域维度定义为f)。
[0029]
步骤二、分离(separation network)和定位网络(localization network):
[0030]
本发明通过联合训练无监督神经源分离和定位网络,而不是使用掩码的相关性来解决频率排序模糊性。分离多通道混合信号的常用方法是掩码掩蔽每个时频点。这个掩码通常是通过在每个时频点中的手动特征聚类来估计的。由于这些模型是在频点上独立建立的,因此它们具有频率排列的模糊性。为了解决这个问题,通过使用预先测量的导向矢量来表征的潜在到达方向(doas,direction of arrivals),本发明通过在空间协方差矩阵(scms,spatial covariance matrices)混合估计每个源的时频域掩码(tf掩码,time-frequency mask)和doas。
[0031]
本发明目标函数被导出为具有tf掩码和doas作为潜变量的cgmm的证据下限(elbo,evidence lower bound)。本发明给定麦克风阵列的几何形状,训练这两个网络分别估计tf掩模和doas的后置概率。由于doas可以用于计算混合记录中的源的数量,我们的框架可以扩展到使用无参数贝叶斯模型处理包含未知数量源的训练数据。
[0032]
步骤三、深度贝叶斯源分离(dbss,deep bayesian source separation):
[0033]
本发明仅利用多通道混合信号训练分离定位网络,并在统一的框架下解决了频率排列模糊问题。该训练基于潜在狄利克雷分布(lda,latent dirichlet allocatio)模型,该模型将源的tf掩码和doas作为潜在变量。该目标函数是空间模型的elbo,由似然函数的期望和网络输出与其先验分布之间的kullback-leibler(kl)散度组成。
[0034]
为了联合估计潜在声源的tf掩码和doas,可观测的多通道频谱图xtf表示为k个声源频谱图stfk的和:
[0035][0036]
其中ztfk∈{0,1}是一个tf掩码,表示哪个声源在每个tf bin上相关,wkd∈{0,1}是一个doa变量,将声源k分配给一个doa候选d∈{1,
…
,d},afd是方向导向向量。在发明中,如假设潜在方向d为水平面上角间隔为5
°
的方向,则d=360/5=72。
[0037]
elbo最大化对应于变分分布和真实后验分布之间的kl散度的最小化。该框架迭代交替地更新参数,直到收敛。由于分析计算这些变量也很困难,我们使用elbo来更新它们,具体做法为:
[0038]
1)预测每个混合录音的tf掩模和doas;
[0039]
2)将更新模型参数;
[0040]
3)利用随机梯度下降(sgd,stochastic gradient descent,)方法计算并更新网络参数。
[0041]
虽然训练好的网络可用于从单声道混合信号中分离资源,但它也可以通过使用网络输出初始化tf掩码来提高多通道em算法的性能。用于求解cgmm的期望最大化算法(em,expectation maximization)交替迭代后续的e步和m步。e步更新tf掩码ztfk和doas wkd,使elbo l最大化;另一方面,m步使用更新参数。
[0042]
由于em算法在收敛前交替更新这些变量,因此本发明对于避免陷入局部最优采用谨慎的初始化。利用分离网络gtfk的输出对tf掩码ztfk进行初始化。由于定位网络gtfk可能会过拟合训练数据的空间偏差,通过本发明使用以下公式而不是定位网络hkd的输出来初始化doa wkd:
[0043][0044]
综上,该方法使用了基于复高斯混合模型(cgmm,complex gaussian mixture model)的空间模型的成本函数。该模型将源的时频掩码和到达方向作为潜在变量,用于训练分离和定位网络,分别对这些变量进行估计。
[0045]
这种联合训练在统一的深度贝叶斯框架下解决了空间模型的频率排列模糊性。此外,预训练的网络不仅可以用于进行单通道分离,还可以有效地初始化多通道分离算法。对模拟语音混合的实验结果表明,该方法优于传统的初始化方法。
[0046]
因此,该方法不依赖角度定位,本发明进行语音增强只使用位置信息进行辅助,对话位置发生变化不会影响增强效果,因此解决了多说话人的场景中方位变动的问题;还有效利用多通道相关性,使用多通道自适应混合模型信息进行分离更加有效精确,解决多说话人同时说话的场景,丰富对话场景内容。解决了单通道分离之后出现的排列模糊性,不受噪声混响环境影响,能够有效增强复杂场景中的语音。
[0047]
作为实施方案,一种多会话人增强系统,该系统包含了多通道会话信号采集器、多通道非监督训练得到的分离语音和单通道增强,分离的语音信号还会残留空间混响和噪声等污染源,通过语音增强则可以将杂音完全去除成为正常单人说话语音。
[0048]
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应所述以权利要求的保护范围为准。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1