视频会议的字幕处理方法、装置、电子设备和存储介质与流程
本发明涉及视频会议,特别是涉及一种视频会议的字幕处理方法、一种视频会议的字幕处理装置、一种电子设备和一种计算机可读存储介质。
背景技术:
1、在传统的视联网会议中,通常有一个主席角色、一个发言人角色、以及众多的参会者,当主席或者发言人在发言时,其他参会者可以实时看到主席或者发言人的画面,以及听到主席或者发言人的声音。然而,由于发言者说话不标准,或者语速过快等问题,往往导致其他人无法听清楚其说话的内容。
技术实现思路
1、鉴于上述问题,提出了本发明实施例以便提供一种克服上述问题或者至少部分地解决上述问题的一种视频会议的字幕处理方法、一种视频会议的字幕处理装置、一种电子设备和一种计算机可读存储介质。
2、为了解决上述问题,本发明实施例公开了一种视频会议的字幕处理方法,应用于视频会议终端,所述视频会议终端与视频会议服务器通信连接,所述方法包括:
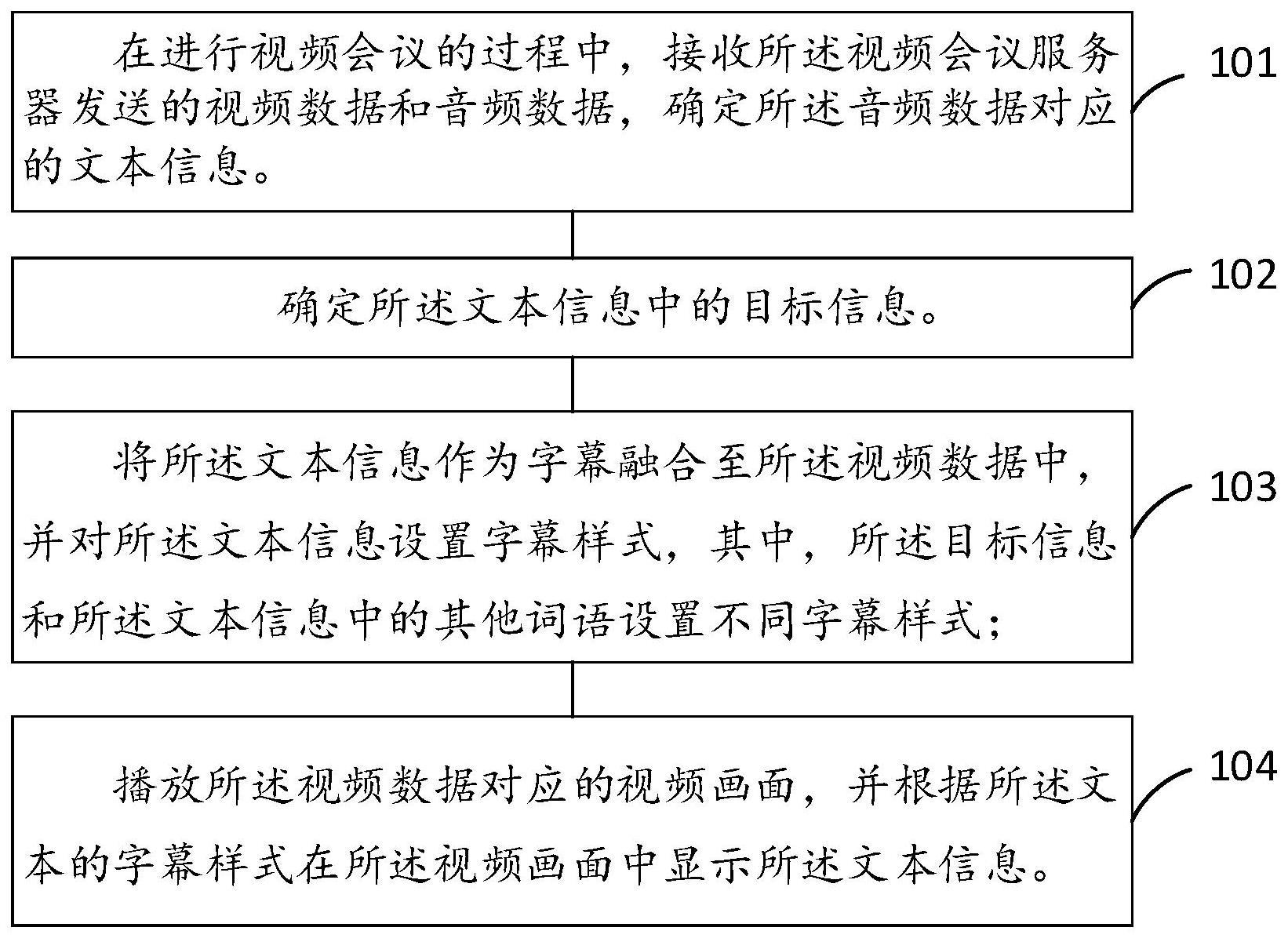
3、在进行视频会议的过程中,接收所述视频会议服务器发送的视频数据和音频数据,确定所述音频数据对应的文本信息;
4、确定所述文本信息中的目标信息;
5、将所述文本信息作为字幕融合至所述视频数据中,并对所述文本信息设置字幕样式,其中,所述目标信息和所述文本信息中的其他词语设置不同字幕样式;
6、播放所述视频数据对应的视频画面,并根据所述文本的字幕样式在所述视频画面中显示所述文本信息。
7、可选地,所述确定所述文本信息中的目标信息,包括:
8、从所述文本信息中提取目标词语或目标短语;
9、将所述目标词语或目标短语与预置关键词进行匹配;
10、若匹配成功,则确定所述目标词语或目标短语为目标信息。
11、可选地,还包括:
12、获取针对当前视频会议的预置关键词,所述预置关键词用于表征在文本信息作为字幕融合至所述视频数据中,提取所述目标信息以使所述目标信息区别于所述文本信息中的其他词语进行展示。
13、可选地,所述确定所述文本信息中的目标信息,包括:
14、统计所述文本信息重复出现的目标词语或目标短语;
15、若所述重复出现的目标词语或目标短语的出现频率大于所述预设频率阈值,则确定所述重复出现的目标词语或目标短语为高频词;
16、从所述文本信息中提取所述高频词,将所述高频词作为目标信息。
17、可选地,所述对所述文本信息设置字幕样式,包括:
18、按照音频数据不同的来源对所述文本信息设置不同的字幕样式;其中,所述字幕样式包括文字大小、字体格式、字体颜色。
19、可选地,所述对所述文本信息设置字幕样式,包括:
20、按照不同的所述目标信息对所述文本设置不同的字幕样式;其中,所述字幕样式包括文字大小、字体格式、字体颜色。
21、可选地,所述将所述文本信息作为字幕融合至所述视频数据中,包括:
22、将所述文本信息拆分为多个文本片段;
23、获取所述多个文本片段在所述音频数据中的时间戳,并根据所述时间戳设置所述多个文本片段的持续时长;
24、根据所述多个文本片段的持续时长段,将所述多个文本片段作为字幕融合至所述视频数据中。
25、本发明实施例还公开了一种视频会议的字幕处理装置,应用于视频会议终端,所述视频会议终端与视频会议服务器通信连接,所述装置包括:
26、接收模块,用于在进行视频会议的过程中,接收所述视频会议服务器发送的视频数据和音频数据,确定所述音频数据对应的文本信息;
27、确定模块,用于确定所述文本信息中的目标信息;
28、融合模块,用于将所述文本信息作为字幕融合至所述视频数据中,并对所述文本信息设置字幕样式,其中,所述目标信息和所述文本信息中的其他词语设置不同字幕样式;
29、播放模块,用于播放所述视频数据对应的视频画面,并根据所述文本的字幕样式在所述视频画面中显示所述文本信息。
30、可选地,所述确定模块,包括:
31、第一提取模块,用于从所述文本信息中提取目标词语或目标短语;
32、匹配模块,用于将所述目标词语或目标短语与预置关键词进行匹配;
33、第一确定子模块,用于若匹配成功,则确定所述目标词语或目标短语为目标信息。
34、可选地,还包括:
35、获取模块,用于获取针对当前视频会议的预置关键词,所述预置关键词用于表征在文本信息作为字幕融合至所述视频数据中,提取所述目标信息以使所述目标信息区别于所述文本信息中的其他词语进行展示。
36、可选地,所述确定模块,包括:
37、统计模块,用于统计所述文本信息重复出现的目标词语或目标短语;
38、第二确定子模块,用于若所述重复出现的目标词语或目标短语的出现频率大于所述预设频率阈值,则确定所述重复出现的目标词语或目标短语为高频词;
39、第二提取模块,用于从所述文本信息中提取所述高频词,将所述高频词作为目标信息。
40、可选地,所述融合模块,包括:
41、第一设置模块,用于按照音频数据不同的来源对所述文本信息设置不同的字幕样式;其中,所述字幕样式包括文字大小、字体格式、字体颜色。
42、可选地,所述融合模块,包括:
43、第二设置模块,用于按照不同的所述目标信息对所述文本设置不同的字幕样式;其中,所述字幕样式包括文字大小、字体格式、字体颜色。
44、可选地,所述所述融合模块,包括:
45、拆分模块,用于将所述文本信息拆分为多个文本片段;
46、第三设置模块,用于获取所述多个文本片段在所述音频数据中的时间戳,并根据所述时间戳设置所述多个文本片段的持续时长;
47、融合子模块,用于根据所述多个文本片段的持续时长段,将所述多个文本片段作为字幕融合至所述视频数据中。
48、本发明实施例还公开了一种电子设备,包括:处理器、存储器及存储在所述存储器上并能够在所述处理器上运行的计算机程序,所述计算机程序被所述处理器执行时实现如上述的视频会议的字幕处理方法的步骤。
49、本发明实施例还公开了一种计算机可读存储介质,所述计算机可读存储介质上存储计算机程序,所述计算机程序被处理器执行时实现如上述的视频会议的字幕处理方法的步骤。
50、本发明实施例包括以下优点:
51、在本发明实施例中,在进行视频会议的过程中,接收视频会议服务器发送的视频数据和音频数据,确定音频数据对应的文本信息;确定文本信息中的目标信息;将文本信息作为字幕融合至视频数据中,并对文本信息设置字幕样式,其中,目标信息和文本信息中的其他词语设置不同字幕样式;播放视频数据对应的视频画面,并根据文本的字幕样式在视频画面中显示文本信息。通过将音频自动识别为文字,叠加到视频画面上,并设置不同的字幕样式,使得会议中的用户不仅可以听到参会者的音频,还可以看到对应的字幕以及会议内容的重点词汇,不仅解决了由于发言者说话不标准,或者语速过快等导致其他人无法正确理解其表达内容的问题,还提升了会议质量。
- 还没有人留言评论。精彩留言会获得点赞!