一种多路视频流的AI异步检测并实时渲染方法及系统与流程
本发明涉及多路视频流处理,尤其涉及一种多路视频流的ai异步检测并实时渲染方法及系统。
背景技术:
1、现有的大多数实时视频流进行ai检测与渲染的方法一般都是通过opencv/ffmpeg从摄像头获取视频流进行视频解码抽帧,随后将获取的视频帧转成相应格式的图像(比如rgb),接着将一帧帧图像送入ai模型进行相关目标的检测、分类与识别,然后将ai模型输出的检测结果利用opencv绘制在每一帧图像上,最后利用ffmpeg将每一帧图像进行视频编码,输出h264/h265格式的视频流。
2、然而上述的ai检测与渲染存在一定的缺陷,主要在于:
3、1、上述方案每一步都是串行同步的,输出的fps依赖于ai模型的推理速度,渲染性能低下;
4、2、一个ai模型只能服务一路视频流,缺乏多路视频渲染能力,如果需要渲染多路视频就需要加载多个ai模型,资源占用会显著增加;
5、3、从摄像头获取的实时视频帧经历图像转码、ai检测、视频编码等步骤消耗了很多时间,会产生很大的延时,导致渲染终端看到的实时图像和真实场景中当前时刻的图像在时间上存在很大偏差。
技术实现思路
1、针对现有技术的不足,本发明提供了一种多路视频流的ai异步检测并实时渲染方法及系统,解决了现有技术中的串行同步处理存在渲染性能低、资源占用显著以及存在延迟的技术问题。
2、为解决上述技术问题,本发明提供了如下技术方案:一种多路视频流的ai异步检测并实时渲染方法,包括以下步骤:
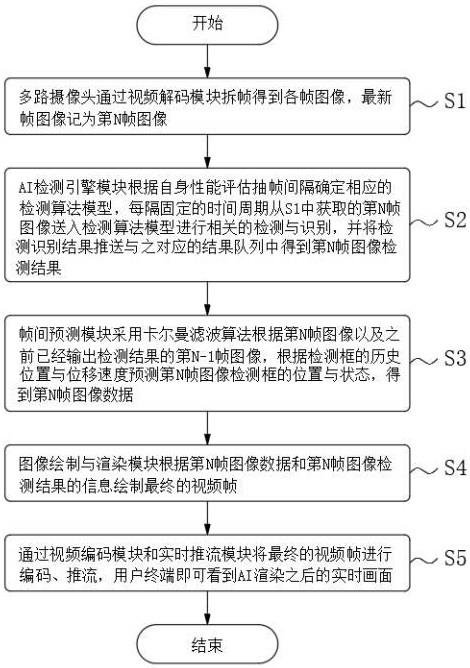
3、s1、多路摄像头通过视频解码模块拆帧得到各帧图像,最新帧图像记为第n帧图像;
4、s2、ai检测引擎模块根据自身性能评估抽帧间隔确定相应的检测算法模型,每隔固定的时间周期从s1中获取的第n帧图像送入检测算法模型进行相关的检测与识别,并将检测识别结果推送与之对应的结果队列中得到第n帧图像检测结果;
5、s3、帧间预测模块采用卡尔曼滤波算法根据第n帧图像以及之前已经输出检测结果的第n-1帧图像,根据检测框的历史位置与位移速度预测第n帧图像检测框的位置与状态,得到第n帧图像数据;
6、s4、图像绘制与渲染模块根据第n帧图像数据和第n帧图像检测结果的信息绘制最终的视频帧;
7、s5、通过视频编码模块和实时推流模块将最终的视频帧进行编码、推流,用户终端即可看到ai渲染之后的实时画面。
8、进一步地,在步骤s2中,ai检测引擎模块根据自身性能评估抽帧间隔确定相应的检测算法模型,具体过程包括以下步骤:
9、s21、ai检测引擎模块自动读取多路视频流的输出帧率记为r,多路视频流记为n;
10、s22、ai检测引擎模块根据已加载的检测算法模型,判断当前检测算法模型针对当前输入流的处理帧率fps是否足以应对n路视频流,即判断当前检测算法模型的处理帧率fps的值是否大于等于n*r;
11、若是,则判断当前检测算法模型的处理帧率fps的值是否大于等于2*n*r;
12、若处理帧率fps的值大于等于2*n*r,则卸载一半的当前检测算法模型,并停止相关线程,降低ai检测引擎模块的资源占用率;
13、若处理帧率fps的值小于2*n*r,则进入步骤s23;
14、若否,则采用当前检测算法模型并结束;
15、s23、判断ai检测引擎模块所剩资源是否能够加载新的检测算法模型;
16、若是,则启动新线程,加载新的检测算法模型共同处理n路视频流;
17、若否,则降低各路视频的输出帧率r,并降低当前检测算法模型针对每路视频流的抽帧间隔,直至能够应对n路视频流的输入。
18、进一步地,在步骤s3中,预测第n帧图像检测框的位置与状态,具体过程包括以下步骤:
19、s31、初始化状态向量x和状态协方差矩阵p;
20、s32、定义状态转移矩阵f、观测矩阵h、观测噪声协方差矩阵r以及过程噪声协方差矩阵q;
21、s33、预测目标检测框的位置;
22、s34、预测状态协方差矩阵;
23、s35、状态更新得到修正后的状态向量x和状态协方差矩阵p。
24、进一步地,在步骤s31中,
25、状态向量x表示目标的状态,包括位置和速度信息,初始时需要根据第一帧的检测结果来设置状态向量的初始值;
26、状态向量x的表达式为:
27、;
28、状态协方差矩阵p表示状态估计的不确定性,初始时可以定义为单位矩阵;
29、状态协方差矩阵p的表达式为:
30、;
31、上式中,代表检测框左上角的坐标,代表检测框右下角的坐标,分别表示左上角和右下角坐标的速度。
32、进一步地,在步骤s35中,状态更新得到修正后的状态向量x和状态协方差矩阵p,具体过程包括以下步骤:
33、s351、从目标检测算法得到新的观测值z以及新一帧中目标检测框的左上角坐标和右下角坐标;
34、s352、根据预测的状态向量和观测矩阵h计算观测残差y,观测残差y表示预测值与实际观测值之间的差异,预测的状态向量即步骤s33中的位置;
35、s353、根据预测的状态协方差矩阵、观测矩阵h和观测噪声协方差矩阵r计算卡尔曼增益k,卡尔曼增益k是一个权重矩阵,用于平衡预测值和观测值的不确定性;
36、s354、使用卡尔曼增益k和观测残差y修正预测的状态向量,得到更新后的状态向量x;
37、s355、使用卡尔曼增益k和观测矩阵h修正预测的状态协方差矩阵,得到更新后的状态协方差矩阵p;
38、s36、重复步骤s33-步骤s35。
39、该技术方案还提供了一种用于实现上述ai异步检测并实时渲染方法的系统,该系统包括:
40、视频解码模块,所述视频解码模块利用视频处理工具ffmpeg解码rtsp/rtmp流,得到各帧图像frame;
41、ai检测引擎模块,所述ai检测引擎模块根据接入的视频流路数、原始视频流的帧率以及配置检测算法模型的类别,自动根据当前ai检测引擎模块的负载动态评估、动态加载不同的检测算法模型;
42、帧间预测模块,所述帧间预测模块基于卡尔曼滤波算法实现根据第n-1帧图像的检测结果预测第n帧图像的位置与状态得到预测结果,并根据第n帧图像的检测结果矫正预测结果生成第n帧图像数据;
43、图像绘制与渲染模块,所述图像绘制与渲染模块采用ffmpeg filter模块将检测算法模型检测出的坐标信息以矩形框或者mask区域的方式渲染到视频帧上;
44、视频编码模块,所述视频编码模块用于将最终的视频帧进行编码;
45、实时推流模块,所述实时推流模块用于将最终的视频帧进行推流。
46、进一步地,若干个检测算法模型均封装成动态库的形式,ai检测引擎模块在运行时利用dlopen/dlclose动态加载/卸载相关的检测算法模型,检测算法模型包括目标检测模型、实例分割模型。
47、进一步地,目标检测模型用于实时检测某个目标,目标检测模型包括yolo系列以及faster rcnn,实例分割模型用于分割某个目标物体的边界,实例分割模型包括yolact以及mask rcnn。
48、进一步地,ai检测引擎模块包括:
49、图像编解码:用于将h264/h265的视频帧转换成rgb图像;
50、资源监控器:用于监控系统磁盘、内存、cpu、gpu资源的利用率;
51、算法调度器:用于根据系统资源占用、系统性能和相应的场景动态加载或者卸载相关的检测算法模型;
52、推理引擎:用于运行检测算法模型并得到输出;
53、算法模块:用于负责图像的预处理、ai检测以及后处理。
54、借由上述技术方案,本发明提供了一种多路视频流的ai异步检测并实时渲染方法及系统,至少具备以下有益效果:
55、1、本发明采用并行异步渲染方案对于实时视频流渲染延时大大降低,并且处理相同数量级的视频数据,加载同样的算法模型,本方案的资源占用率更低,极大提升了资源利用效率。
56、2、本发明将传统的串行处理流程拆解为图像编解码、ai检测引擎、帧间预测和图像绘制与渲染等多个模块,充分利用计算资源以及各模块的并行处理能力,在保证输出fps不变的前提下极大降低了视频延时、降低了系统资源占用。
- 还没有人留言评论。精彩留言会获得点赞!